Hadoop+Zookeeper+Spark+Hbase集群式部署
前期准备
hadoop-2.7.6.tar.gz
hbase-1.2.6-bin.tar.gz
jdk-8u161-linux-x64.tar.gz
zookeeper-3.4.10.tar.gz
sqoop-1.99.7.tar.gz
spark-2.2.1-bin-hadoop2.7.tgz
kafka_2.11-1.1.0.tgz
修改hostname
在root用户下的主界面运行一下命令:
$ vim /etc/hostname
将localhost修改为姓名缩写和学号后四位然后:wq保存退出。
在每个节点/etc/hosts中加入本机ip和其他节点ip
在root用户下的主界面运行一下命令:
$ vim /etc/hosts
添加以下内容:
127.0.0.1 localhost
10.19.2.197 ljy0326
10.19.2.209 pxc0305
10.19.1.242 huwei0303
必须保证hosts内每个ip对应的主机名与hostname一致
配置免密登录
代码如下:
$ sudo apt-get install ssh
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ sudo gedit authorized_keys
$ ssh huwei0303
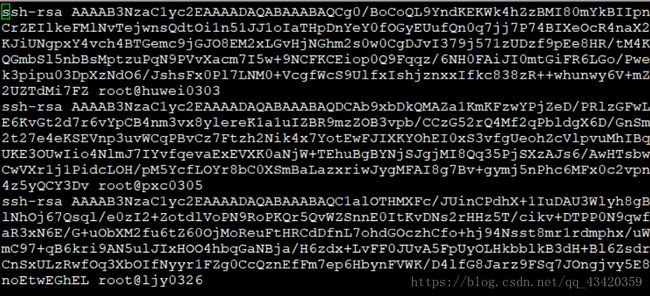
添加完成,效果如图:
下载资源
- 下载JDK
请登录如下网站,下载你想要的版本http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html
- 下载Hadoop等其他安装包
https://mirrors.tuna.tsinghua.edu.cn/apache/
需要下载 Hadoop、HBase、Spark、Scala、Sqoop、kafka、Zookeeper
- 解压文件
解压命令:
tar -zxvf ****.gz -C /opt/文件夹名
将jdk1.8.0_144文件夹更名为java
将hadoop-2.6.7 文件夹更名为hadoop
其余文件夹同上。
在每个节点配置环境变量
执行以下命令:
$ vim /etc/profile
在文件最后输入以下内容:
export JAVA_HOME=/opt/java
export HADOOP_HOME=/opt/hadoop
export ZOOKEEPER_HOME=/opt/zookeeper
export HBASE_HOME=/opt/hbase
export SPARK_HOME=/opt/spark
export SCALA_HOME=/opt/scala
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$HBASE_HOME/bin:$SPARK_HOME/bin:$SCALA_HOME/bin:$SQOOP_HOME/bin
配置如图:

保存退出后需使环境变量生效,执行以下命令:
$ source /etc/profile
然后生效后运行java -version查看jdk配置是否成功
在每个节点创建文件夹并改权限
该文件夹为Hadoop相关文件夹
创建命令:
$ mkdir -p /opt/hadoop
将主节点设置为NTP服务器
一个Hadoop集群就是一个小型局域网,我们需要设定一台NTP服务器作为整个网络的标准时间参考,使用网络(集群)内的所有机器保持时间一致!以下是详细的操作步骤:
- 安装ntp软件
执行命令:
$ apt-get install ntp
- 修改配置文件
打开文件需要修改的配置文件,执行以下命令:
$ vim /etc/ntp.conf
# Specify one or more NTP servers
server 127.127.1.0
因为是内网,所以用本地时间做为服务器时间,注意这里不是127.0.0.1
在配置文件里找到以下4条并注释掉:
#server 0.ubuntu.pool.ntp.org
#server 1.ubuntu.pool.ntp.org
#server 2.ubuntu.pool.ntp.org
#server 3.ubuntu.pool.ntp.org
增加了NTP服务器自身到时间服务器的同步
fudge 127.127.1.0 stratum 8
增加了一些需要同步的客户端的ip
restrict -4 default kod notrap nomodify nopeer noquery limited
restrict -6 default kod notrap nomodify nopeer noquery limited
restrict 10.19.2.209
restrict 10.19.1.242
配置完成如图:

配置Hadoop
- 配置 hadoop-env.sh
# The java implementation to use.
修改为自己的JAVA_HOME路径
export JAVA_HOME=/opt/java/jdk-8u171-linux-x64
- 配置hdfs-site.xml
配置如图:

- 配置core-site.xml
配置如图:

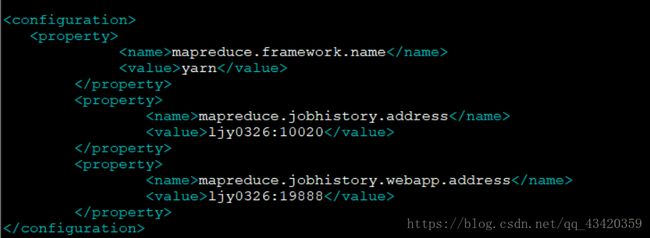
- 配置mapred-site.xml
配置如图:
- 配置slaves
添加节点的主机名:
ljy0326
pxc0305
huwei0303
添加完毕后保存退出。
- 配置 yarn-site.xml
如图:

- 配置JournalNode
JournalNode的配置是在hdfs-site.xml文件中,
打开文件:
$ vim hdfs-site.xml
在原有的配置下面添加一下内容,需保证所有的内容均在
dfs.nameservices
ljy0326
dfs.ha.namenodes.ljy0326
nn1,nn2
dfs.namenode.rpc-address.ljy0326.nn1
ljy0326:9000
dfs.namenode.http-address.ljy0326.nn1
ljy0326:50070
dfs.namenode.rpc-address.ljy0326.nn2
pxc0305:9000
dfs.namenode.http-address.ljy0326.nn2
pxc0305:50070
dfs.namenode.shared.edits.dir
qjournal://ljy0326:8485;pxc0305:8485;huwei0303:8485/ljy0326
dfs.journalnode.edits.dir
/opt/hadoop/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ljy0326
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyPrivider
dfs.ha.fencing.methods
sshfence(ljy0326:22)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
将配置好的文件发送到其他节点:
运行shell命令:
$ scp –r /opt/java/jdk root@huwei0303:/opt/java
$ scp –r /opt/java/jdk root@pxc0305:/opt
$ scp –r /opt/hadoop/hadoop-2.6.7 root@huwei0303:/opt/hadoop
$ scp –r /opt/hadoop/hadoop-2.6.7 root@pxc0305:/opt/hadoop
格式化namenode
在master节点运行shell命令:
$ hadoop namenode –format
提示0,则格式化正常
启动hadoop集群
运行命令:
$ /sbin/start-all.sh
输入命令jps,hadoop启动成功如图:

配置ZooKeeper
- 创建相关文件
$ sudo mkdir -p /usr/local/zkData //该文件夹为Zookeeper数据文件夹
$ mkdir -p /opt/zookeeper/logs //该文件夹存放Zookeeper 日志文件
在ljy0326节点运行shell命令:
$ echo 1 >> /usr/local/zkData/myid
在pxc0305 节点运行shell命令
$ echo 2 >> /usr/local/zkData/myid
在huwei0303 节点运行shell命令
$ echo 3 >> /usr/local/zkData/myid
- 配置/opt/zookeeper/conf/zoo.cfg
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 将此处改为原先创建好的目录
dataDir=/usr/local/zkData
# the port at which the clients will connect
clientPort=2181
server.1=0.0.0.0:2888:3888
server.2=pxc0305:2888:3888
server.3=huwei0303:2888:3888
配置完成如图:

注意此处(3个虚拟机要分别配置)
- 在pxc0305节点,将此处配置为
server.1=ljy0326:2888:3888
server.2=0.0.0.0:2888:3888
server.3=huwei0303:2888:3888
- 在huwei0303节点,将此处配置为
server.1=ljy0326:2888:3888
server.2=pxc0305:2888:3888
server.3=0.0.0.0:2888:3888
- 配置/opt/zookeeper/bin/zkEnv.sh
找到
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="."
fi
将.改为/opt/zookeeper/logs
- 将配置文件发送到其他节点
运行shell命令:
$ scp –r /opt/zookeeper/ root@pxc0305:/opt
$ scp –r /opt/zookeeper/ root@huwei0303:/opt
- 启动Zookeeper集群
在每个节点运行shell命令:
$ zkServer.sh start
配置HBase
- 配置hbase-env.sh
export JAVA_HOME=/opt/java/jdk //更改Java环境变量
- 配置hbase-site.xml
//集群中所有RegionServer共享目录
hbase.rootdir
hdfs://ljy0326:9000/hbase
//集群的模式
hbase.cluster.distributed
true
// zookeeper集群的URL配置
hbase.zookeeper.quorum
ljy0326,pxc0305,huwei0303
//指定ljy0326
hbase.master
ljy0326
//客户端与zookeeper的连接端口
hbase.zookeeper.property.clientPort
2181
//客户端与zookeeper的通讯超时时间
zookeeper.session.timeout.ms
1800000
// RegionServer处理IO请求的线程数
hbase.regionserver.handler.count
100
//RegionServer发生Split的阔值
hbase.hregion.max.filesize
2147483648
- 配置regionservers
pxc0305
huwei0303
- 将配置文件发送到其他节点
$ scp –r /opt/hbase/ root@pxc0305:/opt
$ scp –r /opt/hbase/ root@huwei0303:/opt
- 在master节点启动HBase
$ start-hbase.sh
输入命令jps,Hbase启动成功如图:

搭建spark
- 在每个节点创建Spark相关目录:
$ sudo mkdir –p /usr/local/spark //该目录用于存放worker信息和日志
- 配置spark-env.sh文件
配置如图:

#在配置slave节点时,将SPARK_LOCAL_IP改为对应的IP地址或者Hostname
- 配置spark-defaults.conf
配置如图:

- 配置slaves
#在文件中加入配置信息
pxc0305
huwei0303
- 将配置文件发送到其他节点
运行shell命令:
$ scp –r /opt/spark/ root@pxc0305:/opt
$ scp –r /opt/spark/ root@huwei0303:/opt
$ scp –r /opt/scala/ root@pxc0305:/opt
$ scp –r /opt/scala/ root@huwei0303:/opt
- 启动Spark集群
#在Hadoop集群启动的情况下运行以下命令:
$ /opt/spark/spark-2.2.1/sbin/start-all.sh
搭建kafka
- 创建kafka相关目录
$ mkdir /opt/kafka/logs //存放kafka消息的目录,也可以使用默认的目录
- 修改配置文件
$ vim /opt/kafka/ kafka_2.11-1.1.0 /config/server.properties
需要修改的部分:
broker.id=1 //当前机器在kafka机器里唯一标识,与zookeeper的myid相匹配
log.dirs=/opt/kafka/logs //存储消息的目录位置
- 将配置文件发送到其他节点
运行shell命令:
scp –r /opt/spark/ root@pxc0305:/opt
scp –r /opt/spark/ root@huwei0303:/opt
切换到pxc0305和huwei0303上修改配置文件:
[root@pxc0305]# vim server.properties
broker.id=2
[root@ huwei0303]# vim server.properties
broker.id=3
- 启动kafka集群
保证先启动zookeeper集群
然后在每个节点的、kafka/sbin目录下运行
$ cd /opt/kafka/ kafka_2.11-1.1.0/sbin
$ ./kafka-server-start.sh -daemon ../config/server.properties
若成功启动,输入jps可以看到 kafka
搭建sqoop1.99.7
- 配置第三方jar引用路径
$ vim /etc/profile
$ export SQOOP_SERVER_EXTRA_LIB=$SQOOP_HOME/extra
最后把mysql的驱动jar文件复制到这个目录下。
- 配置sqoop.properties文件
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/opt/hadoop/etc/hadoop
org.apache.sqoop.security.authentication.type=SIMPLE
org.apache.sqoop.security.authentication.handler=org.apache.sqoop.security.authentication.SimpleAuthenticationHandler
org.apache.sqoop.security.authentication.anonymous=true
- 验证配置是否有效
使用bin中的sqoop2-tool工具进行验证:
$ bin/sqoop2-tool verify
这个工具也可用于软件升级。若没有什么问题,往下走。
- 启动sqoop
$ bin/sqoop2-server start
安装mysql
在ljy0326上运行命令
$ apt-get install mysql-server-5.6
会提示设置root密码,设置完成则运行查看是否成功
检测搭建是否完成
搭建成功后每个节点jps运行截图:

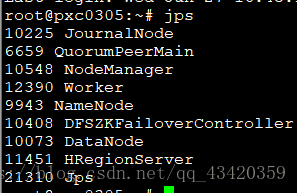
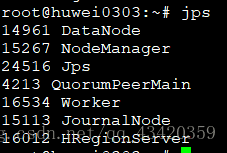
结果如上图,大功告成!