【网安大模型专题10.25】论文7:引入会话式 APR 范例+利用验证反馈+LLM 的长期上下文窗口:更智能的`反馈机制`、更有效的`信息合并策略`、更复杂的`模型结构`、鼓励生成多样性
Conversational Automated Program Repair
- 写在最前面
-
- 论文主要贡献
- 自己研究方向的一些启发
- 课堂讨论
-
- 不能对话
- 最大长度的实验结果
- 模型大小
- 背景介绍
-
- APR(Automated Program Repair)
- G&V 范式(Generate and Validate)
- Emplate-based 和 Learning-based 工具
- 存在的问题
- LLM for APR 创新点
-
- 直接应用LLM于APR
- 解决G&V范式问题
- Conversational APR 对话式APR
- Turn 1:
- Turn 2:
- Turn 3:
- 设计决策
-
- Prompt engineering
- Maximum chain length
- 实验和评估
-
- Evaluation metrics评估指标
- Implementation实现
- 评估
-
- RQ1: What is the effectiveness of applying conversational APR?
- RQ2: How do different components of conversational APR effect performance?
-
- Maximum chain length对话链的长度
- Feedback prompting style反馈提示风格的效果
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
饶鸿洲同学: @weixin_42161680 分享了Conversational Automated Program Repair《对话式自动程序修复》.CoRR abs/2301.13246(2023)
分享时的PPT简洁大方,重点突出
对流程图介绍清晰,没看论文也能理解
论文:https://arxiv.org/abs/2301.13246
代码:https://github.com/ASSERT-KTH/RapidCapr
论文主要贡献
-
引入会话式 APR 范例:引入了一种新的程序修复方法——会话式 APR。与以前的 LLM for APR 方法不同,它采用交互式的生成和验证过程,以提高修复效率和准确性。
-
利用验证反馈:会话式 APR 利用
验证反馈,将先前生成的补丁与测试集进行验证,以改善模型的生成补丁。这种方法有助于模型理解先前错误补丁的问题,并避免重复生成相同的错误补丁。 -
LLM 的长期上下文窗口:会话式 APR 允许利用 LLM 的长期上下文窗口,以更好地理解被测程序的语义含义,而
不仅仅是代码片段的信息。 -
广泛的模型评估:作者对包括新开发的 ChatGPT 模型在内的 10 种不同 LLM 进行了广泛评估,证明了会话式 APR 方法相对于以前的 LLM for APR 方法的改进。
自己研究方向的一些启发
-
改进模型框架:包括更智能的
反馈机制、更有效的信息合并策略以及更复杂的模型结构。这篇论文进一步改进和细化对话式 APR 框架,探索更有效的补丁生成和验证策略。 -
生成多样性:
鼓励生成多样性,以提高最终修复的鲁棒性。多样性生成可以降低生成相同错误补丁的风险。 -
APR 框架扩展:这个框架可能不仅适用于代码修复,感觉还适用于其他代码驱动的任务?
代码重构、性能优化和缺陷预测。
还有其他与代码相关的任务,如代码生成、自动文档生成等。
课堂讨论
这篇论文做的实验比较浅、比较模糊
不能对话
能读懂函数风格提示的模型,
自然语言chatgpt能读懂
最大长度的实验结果
增加长度,效果下降了很多
论文给出的解释:冗余的信息让模型误判,改正确的代码改错了
所以有上限
(或许可以)增加实验:成功率
模型大小
16B的模型
(或许可以)尝试增加大模型
背景介绍
APR(Automated Program Repair)
- APR是自动程序修复的缩写,用于自动化程序bug的修复,以减少开发人员的手动修复工作。
- APR根据buggy code和测试用例,来生成修复补丁。
Buggy code:有漏洞、错误或缺陷的程序代码。
G&V 范式(Generate and Validate)
G&V是一种常见的APR范式,它包括生成和验证两个主要步骤:
- 在生成阶段,候选补丁被生成,通常使用
预定义的prompt或prefix来引导生成。
prefix:前缀或起始标记,用来引导模型的生成过程。这个前缀是一段文本或编码序列,通常作为模型输入的一部分,以指定模型应该生成什么类型的文本或信息,帮助模型理解生成任务的上下文和要求。 - 在验证阶段,生成的每个候选补丁都会按顺序验证,直到找到一个通过所有测试用例的有效补丁。
Emplate-based 和 Learning-based 工具
- APR工具通常分为Emplate-based和Learning-based两种类型:
- Emplate-based工具使用预定义模板来匹配buggy和fix code。
- Learning-based工具通过训练将错误代码和补丁代码成对进行匹配,构建Neural Machine Translation(NMT)模型。
存在的问题
- 学习型APR工具通常只能修复与训练数据中的bug类型相关的问题,
缺乏多样性。 - 构建bug修复数据集需要抓取开源bug fix commits,但这些commits中可能
包含了大量误报,导致数据集质量低下,构建困难。
Bug fix commits:软件开发项目中的提交记录,这些记录包含了对已知缺陷或错误的修复。
在版本控制系统(如Git、Subversion等)中,每个提交通常都有一个关联的提交消息,其中包含有关所做更改的信息,包括修复的问题或缺陷的描述。
这些 “bug fix commits” 是软件维护的一部分,用于跟踪和记录开发团队如何修复软件中的问题。这些提交通常包括所做的更改,可能包括源代码文件、配置文件或文档的修改,以解决已知的问题。通过查看 “bug fix commits”,开发人员可以了解在项目的不同阶段修复了哪些问题,以及如何解决它们。
LLM for APR 创新点
直接应用LLM于APR
- LLM可以直接用于APR,无需经过复杂的微调。可以使用通用的prompt或prefix来引导LLM生成修复补丁。
解决G&V范式问题
- LLM应用于APR的方法通常需要多次采样以获得候选补丁,但这存在问题。
- 由于采样具有概率性质,多次从相同的prompt/prefix采样可能导致生成重复的补丁,浪费计算和时间。
- 现有方法通常只提供APR prompt,缺少功能性信息,如测试用例。
Conversational APR 对话式APR
Conversational APR是一种新的APR范式,通过交互式的补丁生成和验证过程提高了程序修复的效率和准确性。
过程:
- 修复生成和验证交错进行,每个回合提供新的输入,包括以前的错误补丁和测试反馈。
- 通过多轮顺序回合(对话链)生成候选修复补丁,直到找到通过所有测试用例的有效补丁或达到最大迭代次数。
好处:
- 反馈的多样性:对话式APR可以应用多种可能的反馈信息,例如人类对补丁的评估。
- 效果改善:与之前只使用buggy code片段作为输入的LLM工具相比,对话式APR通过补丁验证形式的验证反馈来帮助模型理解先前生成的补丁为什么是错误的。通过这种方式,LLM可以识别先前的生成内容,避免重复生成已经验证过的错误补丁。
- 性能提升:通过使用10个流行的LLM进行评估,发现这种方法不仅提高了修复bug的数量,而且与基于采样的基线相比,可以更快地找到正确的补丁。

通过使用先前生成的补丁/验证结果作为反馈,从 LLM 迭代获取新的候选补丁,此过程称为轮次。每个轮次包括三个不同的步骤:
(1)根据先前的反馈构建新的提示;
(2)对模型采样以产生样本输出函数;
(3)根据测试用例验证样本输出函数来获取验证反馈。多个按顺序排列执行的轮次称为链。
终止条件是样本输出补丁能够通过所有测试用例(即获得合理的补丁)或达到最大轮数(即链达到最长的长度)。
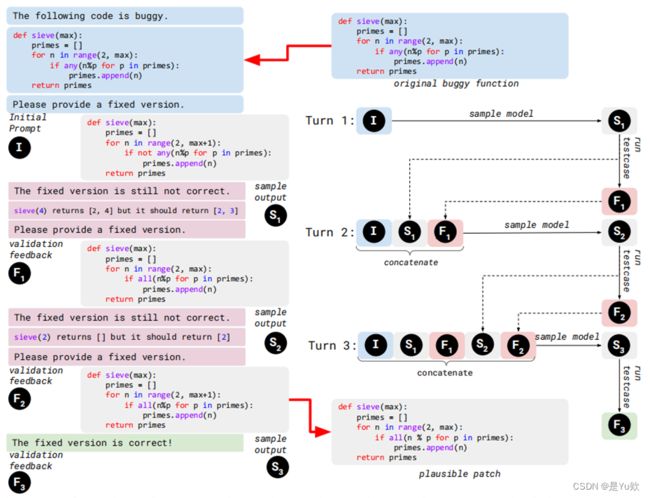
Turn 1:
首先使用原始buggy function创建一个初始提示I,这个提示使用自然语言来表明该函数有缺陷(e.g. The following code is buggy)以及希望LLM解决的任务(e.g. Please provide a fixed version)。
然后,使用初始提示 I 对模型进行采样,获得第一个样本输出函数 S1 。 对第 4 行进行了更改: S1 中的函数否定了原始 if 条件。
然后,根据测试列表验证 S1:新补丁能够成功通过先前失败的 sieve(2) = [2] 测试,但是无法 通过sieve(4) 测试。 该验证信息 F1 被收集作为反馈,在下一个对话轮次期间使用。
Turn 2:
使用Turn 1中失败的测试用例构建验证反馈 F1,并向模型表明之前的样本 S1 仍然不正确(The fixed version is still not correct)和新任务(Please provide another fixed version)。
然后将初始提示、第一个样本输出函数和验证反馈 { I , S1 , F1 } 连接在一起作为 LLM 的输入。
该模型不仅能够使用原始的buggy function,还能够使用先前生成的样本及其测试用例反馈来生成新的修补函数。
与Turn 1一样,本轮结果获得 S2 和 F2,在保证第4行是正确的前提下,候选补丁函数将 for 循环的上限范围减小了 1。
Turn 3:
首先根据之前失败的测试用例构建新的验证反馈 F2。
然后按顺序连接所有先前采样的输出及其验证反馈,生成 { I , S1 , F1 , S2 , F2 } 。
使用此输入再次对 LLM 进行采样以生成下一个候选补丁 S3 。
这时候选补丁修复了bug,并且能够通过所有测试用例,即S3是本次的plausible 补丁至此,程序修复过程终止。
设计决策
Prompt engineering
Prompt是在各种downstream任务中利用LLM的有效方法,并且不需要任何明确的微调。
在会话式 APR 中,本文提供的任务提示遵循Xia et al.[1]的风格。本文还遵循先前的指导方针,保证prompt是开放式的,避免generation被限制。
[1]. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022
Maximum chain length
最大链长度是终止条件之一。所使用的 LLM 具有最大上下文窗口并且不能采用任意长度输入。 一旦达到最大链长度,会话 APR 将从头开始(即通过再次制作initial prompt)并使用新的链会话。 最大链长度是控制 LLM 可以接收多少历史记录的参数。 较小的最大链长度意味着模型生成的不正确补丁较少,对最终的结果的正确性有影响。 较大的最大链长度意味着模型可以看到多个先前失败的补丁,但这也可能没有好处,因为它可能导致 LLM 重复一些早期的补丁或卡在函数的特定实现上。
实验和评估
注:本文的评估标准与QuixBugs Lin et al. [1]中的一致。
Evaluation metrics评估指标
评估指标包括:
- 用于评估 APR 工具的标准指标:合理补丁的数量。
- Tries:为获得合理/正确补丁所需的样本数量。 在比较修复错误数量相似的两种方法/模型时,tries次数较少的方法/模型是首选。
Implementation实现
使用 CODEGEN 的 Hugging Face HuggingFace ,在 Python 中实现 LLM 的生成流程。
通过 OpenAI API 通过查询 code-davinci-002 引擎来访问 Codex。 由于 ChatGPT 不是开源的,并且不提供官方 API (如 Codex),因此本文手动输入提示并提取输出。
对于除 ChatGPT 之外的所有模型,使用核采样的默认生成设置,top p = 0.95,temperature= 1,每个 bug 50 个样本,最大链长度为 3。
计算机部分参数: 32核workstation,每个workstation:AMD Ryzen Threadripper PRO 5975WX CPU、256 GB RAM 和 3 个 NVIDIA GeForce RTX 3090 GPU,运行 Ubuntu 22.04.1 LTS。
评估
RQ1: What is the effectiveness of applying conversational APR?
本文首先将会话式 APR 的性能与之前 LLM 中用于 APR 工作的baseline approach进行比较,其中所有APR的patches是通过从相同的initial prompt中连续采样生成的。本文进一步评估了随着模型规模的增加LLM 的扩展效果,并研究了不同预训练策略(例如 ChatGPT 与 Codex)的性能差异。

表 2 显示了 QuixBugs-Python 和 QuixBugs-Java 上的结果:
对话式 APR能够提高所有模型的所有无监督训练的 LLM 的plausible补丁数量。
对话式 APR 能够减少获得第一个plausible补丁之前所需的tries次数(样本数量)。
与传统的生成补丁的采样方法相比,会话式 APR 能够利用模型对自然语言的理解来表明补丁错误的原因。
对话式 APR 有助于减少使用相同的提示进行采样而产生的重复补丁的数量

表 3 中,与以无监督方式训练的 Codex 相比,ChatGPT在使用Human Feedback强化学习 (RLHF) 后,表现得更好。这种改善部分归因于模型参数的增加以及ChatGPT 中使用的基于对话的微调数据集。 对话式 APR 依赖于验证反馈来调节下一代生成的能通过测试用例的补丁,面向对话模型(例如ChatGPT )的训练数据和算法都包含反馈驱动循环,因此非常适合此任务。
RQ2: How do different components of conversational APR effect performance?
本文研究了会话式 APR 的不同参数:对话链的长度和不同的验证反馈提示是如何影响性能的。
Maximum chain length对话链的长度
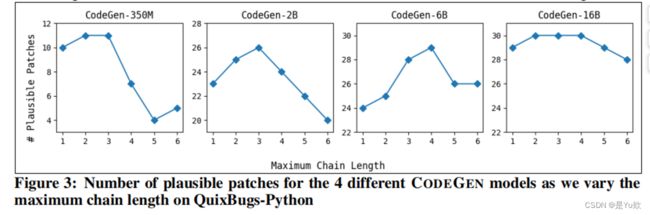
图 3 显示了将 4 个 CODEGEN 模型的最大链长度从 1 更改为 6 时的补丁数量。随着链长度的增加,模型必定会获得越来越多之前迭代的上下文信息。
当链初始长度较小时,随链的长度增加,性能会提高,并在 3 或 4 左右达到最大值,然后随着链长度的继续增加而降低。
一旦达到较高的链长度,plausible补丁数量就会减少,因为上下文信息过多,模型可能无法处理。
这种下降在参数较小的模型中更为显著,但是参数较大的模型受较长链长度的影响较小,其原因可能是参数较大的模型能够更好地捕获长期的上下文依赖性。
总结:用于对话式 APR 的最佳链长度可能取决于所使用的各个 LLM。
Feedback prompting style反馈提示风格的效果

表 4 显示了 QuixBugs-Python 中使用不同验证提示的合理补丁数量。
no testcase列不包含任何测试用例反馈(仅说明补丁不正确),natural language描述失败的测试用例(e.g.当输入为2时,补丁错误地返回[],但它应该返回[2]),functional提示风格是默认的提示风格。
不同的提示风格对会话 APR 的最终表现的影响:从 no testcase开始,可以通过在告诉 LLM 补丁不正确的基础上添加特定的测试用例反馈信息来提高性能。
使用 buggy/patch 函数名称和传递参数的functional提示风格表现最好,因为 functional提示风格通过将测试用例的输入和预期输出关系表述为函数调用,以更简洁、自然的方式传达失败的测试用例信息。