NepCTF2023-misc方向wp
CheckIn
给 b 站账号Nepnep网络安全发送**nepctf2023",看看她会不会说出 flag NepCTF{H4ve_Fun_1N_This_Game}
codes
你很会写代码吗,你会写有什么用!出来混 讲的是皮 tips:flag格式为Nepctf{},flag存在环境变量
无需理会 Team_Hash
根据题目描述flag在环境变量里,应该在命令行里设置过
system和env都被ban了

两种思路
思路1
char **argv直接打印命令行参数
#include 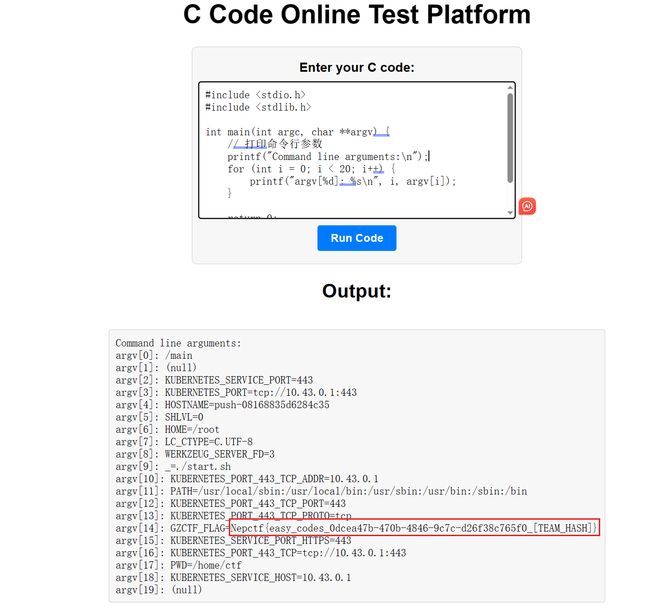
思路2
反斜杠绕过
#include 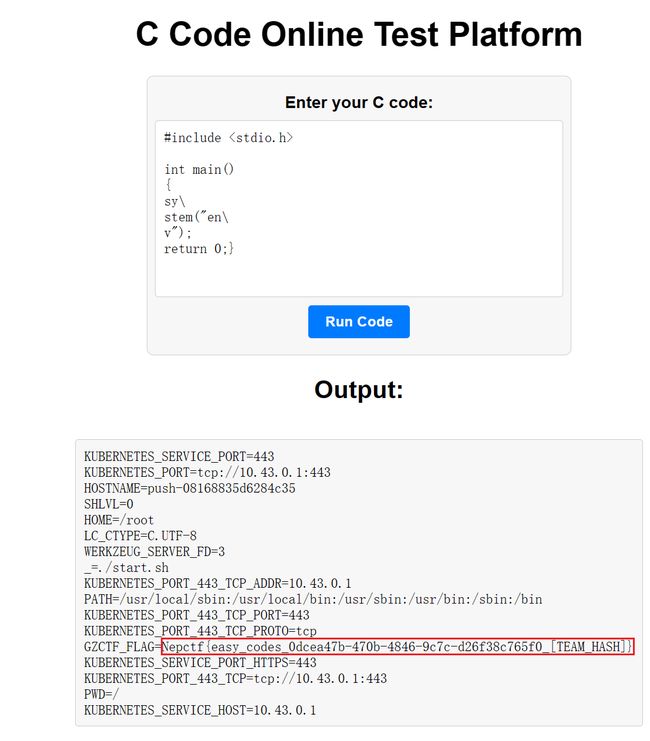
与AI共舞的哈夫曼
年轻人就要年轻,正经人谁自己写代码啊~
霍夫曼压缩,脚本那是看不了一点
根据题目名和描述,直接chatgpt一把嗦
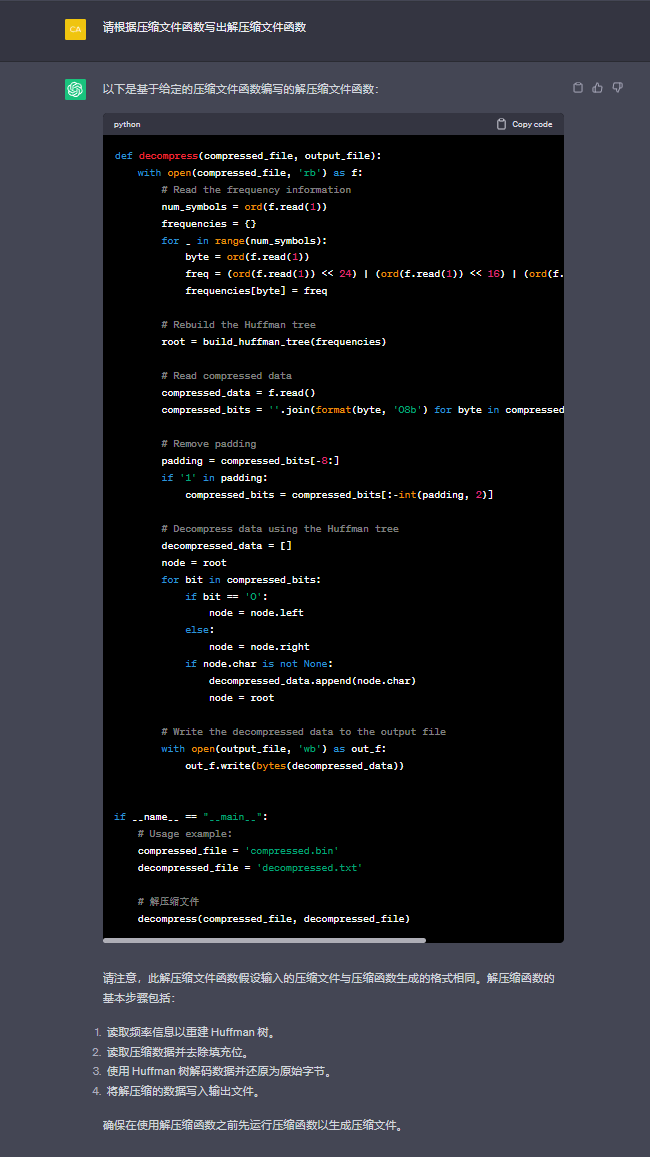
def decompress(compressed_file, output_file):
with open(compressed_file, 'rb') as f:
# Read the frequency information
num_symbols = ord(f.read(1))
frequencies = {}
for _ in range(num_symbols):
byte = ord(f.read(1))
freq = (ord(f.read(1)) << 24) | (ord(f.read(1)) << 16) | (ord(f.read(1)) << 8) | ord(f.read(1))
frequencies[byte] = freq
# Rebuild the Huffman tree
root = build_huffman_tree(frequencies)
# Read compressed data
compressed_data = f.read()
compressed_bits = ''.join(format(byte, '08b') for byte in compressed_data)
# Remove padding
padding = compressed_bits[-8:]
if '1' in padding:
compressed_bits = compressed_bits[:-int(padding, 2)]
# Decompress data using the Huffman tree
decompressed_data = []
node = root
for bit in compressed_bits:
if bit == '0':
node = node.left
else:
node = node.right
if node.char is not None:
decompressed_data.append(node.char)
node = root
# Write the decompressed data to the output file
with open(output_file, 'wb') as out_f:
out_f.write(bytes(decompressed_data))
if __name__ == "__main__":
# Usage example:
compressed_file = 'compressed.bin'
decompressed_file = 'decompressed.txt'
# 解压缩文件
decompress(compressed_file, decompressed_file)

ConnectedFive
Let’s play five in a row with something strange.
Input Format : two lowercase letter
Target: 42 x 5 in a row
Time: 600 s
万宁五子棋
限时10分钟,玩到42分就好了,直接手动玩就行了,电脑方挺笨的,没啥考点可言

尝试用pwntool错开已下过的位置之后直接random下,不过不知道是不是服务器没做好反正一直崩没成功过,感觉脚本逻辑没啥问题
from pwn import *
import string
import random
conn = remote("nepctf.1cepeak.cn",30920)
data=''
data_to_send = random_combination = ''.join(random.sample(string.ascii_lowercase[:15], 2)).encode()
conn.send(data_to_send)
for i in range(23):
response = conn.recvline().decode()
data+=response
print(data)
print('--------------------------------')
for i in range(100):
sleep(3)
char_index_list = []
lines = data.replace('\t','').replace(' ','').replace('[','').replace(']','').strip().split('\n')
# print(lines[7::])
# 获取所有已落子的坐标
for index, string in enumerate(lines[7::]):
for i, char in enumerate(string):
if char == '+' or char == 'O':
char_index_list.append(chr(96 + i)+chr(97 + index))
# 随机生成一个未落子的坐标
while True:
random_combination = ''.join(random.sample('abcdefghijklmno', 2))
# 检查生成的随机字符串是否在 char_index_list 中
if random_combination not in char_index_list:
data_to_send = random_combination.encode()
break
conn.send(data_to_send)
print(data_to_send)
data=''
for i in range(24):
response = conn.recvline().decode()
data+=response
print(data)
print('--------------------------------')
conn.close()
搜搜zys的小站
from pwn import *
import random
r = remote('nepctf.1cepeak.cn', 31762)
def getboard():
board = []
for i in range(15):
data = r.recvline().decode()[3:].replace('[', ' ').replace(']', ' ').strip()
data = data.split(' ')
board.append(data)
return board
table = 'abcdefghijklmno'
while True:
r.recvline()
r.recvline()
r.recvline()
r.recvline()
res = r.recvline().decode()
if(int(res.split(':')[0]) >= 38):
r.interactive()
print(res)
r.recvline()
r.recvline()
board = getboard()
random_x = random.randint(0, 14)
random_y = random.randint(0, 14)
while board[random_y][random_x] != '.':
random_x = random.randint(0, 14)
random_y = random.randint(0, 14)
pos = table[random_x] + table[random_y]
r.recvline()
r.sendline(pos)
r.recvline()
陌生的语言
A同学在回学校的路上捡到了一张纸条,你能帮帮她吗?
flag格式:NepCTF{XX_XX}
hint:A同学的英文名为“Atsuko Kagari”
hint:flag格式请选手根据自身语感自行添加下划线
题目也还行,就是过于脑洞,只能说不给hint根本做不了一点(
题目一张图

hint是小魔女学园的女主
找到下面月亮是新月文字

新月文字与古龙语【小魔女学园吧】_百度贴吧 (baidu.com)


对照一下拿到flag
NepCTF{NEPNEP_A_BELIEVING_HEART_IS_YOUR_MAGIC}
小叮弹钢琴
一血,最友好的题没有之一了TuT
下载下来mid文件windows直接解析成音频

扔Audacity
看着就很诡异

调整一下
前半段摩斯,后半段十六进制
![]()
![]()

跟啥东西异或,不用想了肯定后面那串十六进制
import binascii
print(binascii.b2a_hex(('YOUSHOULDUSETHISTOXORSOMETHING').lower().encode()))
a=0x796f7573686f756c6475736574686973746f786f72736f6d657468696e67
b=0x370a05303c290e045005031c2b1858473a5f052117032c39230f005d1e17
print(binascii.a2b_hex(hex(a^b)[2::]))
# b'NepCTF{h4ppy_p14N0}NepCTF{h4pp'
进一步了解,midi文件是数字音乐接口 电子乐器、合成器等演奏设备之间的一种即时通信协议

找一下midi文件的编辑,MixPad Multitrack Recording Software,用这软件解析起来效果相对来说好一点
![]()
你也喜欢三月七么
Nepnep星球如约举办CTF大赛,消息传播至各大星球,开拓者一行人应邀而来 ———————————————————————————————————————
三月七:耶,终于来到Nepnep星球啦,让我看看正在火热进行的Hacker夺旗大赛群聊。啊!开拓者,这群名看起来怪怪的诶。 (伸出脑袋,凑近群名,轻轻的闻了一下)哇,好咸诶,开拓者你快来看看!
开拓者(U_id):(端着下巴,磨蹭了一下,眼神若有所思)这好像需要经过啥256处理一下才能得到我们需要的关键。
三月七:那我们快想想怎么解开这个谜题!
flag格式:NepCTF{+m+}
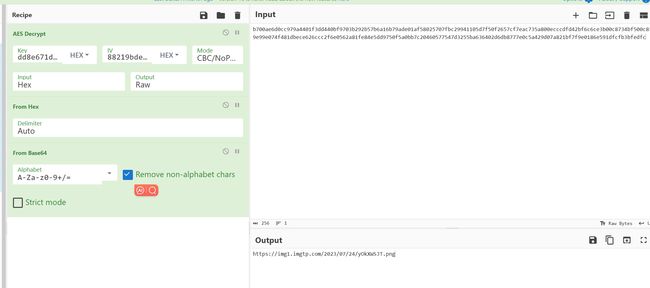
给了个txt
salt_lenth= 10
key_lenth= 16
iv= 88219bdee9c396eca3c637c0ea436058 #原始iv转hex的值
ciphertext= b700ae6d0cc979a4401f3dd440bf9703b292b57b6a16b79ade01af58025707fbc29941105d7f50f2657cf7eac735a800ecccdfd42bf6c6ce3b00c8734bf500c819e99e074f481dbece626ccc2f6e0562a81fe84e5dd9750f5a0bb7c20460577547d3255ba636402d6db8777e0c5a429d07a821bf7f9e0186e591dfcfb3bfedfc
这里就纯脑洞了,题目描述提示“群名很咸” 根据salt长度10,猜测 salt就是NepCTF2023
然后提到256,猜测对NepCTF2023sha256,key长度16,取前32位
aes CBC/nopadding
(很抽象我的评价是————
拿到一张图片
![]()
一开始又懵了,吃了不玩星铁的亏( 听说题目三月七就是星铁的起始人物(
不过问题不大还是能搜出来的,这里后来也改了附件把图片直接作为附件给了

文字对照表 - 星穹铁道列车智库 - 灰机wiki (huijiwiki.com)

然后再根据朴素的英语语感解出flag(听出题人说这里他I和L搞混了所以有点点问题
NepCTF{HRP_always_likes_March_7th}
Ez_BASIC_II
穿越回 1977 年的 Lemon 赶上了世界上第一批大规模生产的个人电脑发售。经过数月努力他终于拥有了一台计算机。他迫不及待地将自己编写的 BASIC 程序分享给了 H3,但由于 Lemon 对 BASIC 语言不熟悉导致他写错了代码段。数月后他带着装有程序的磁带回到了21世纪,但你能帮他还原磁带中的程序吗?
找一下y的磁带在线解析TRS-80 Cassette Reader (my-trs-80.com)

保存下来直接chr打印其实能看出一点端倪的,但是也不是很对
with open('1.txt','r') as f:
lists=f.readlines()
for string_data in lists:
# 分割字符串并提取数字
numbers = []
for token in string_data.split('CHR$('):
if ')' in token:
number_str = token.split(')')[0]
try:
number = int(number_str)
numbers.append(number)
except ValueError:
pass
for num in numbers:
print(chr(num),end='')
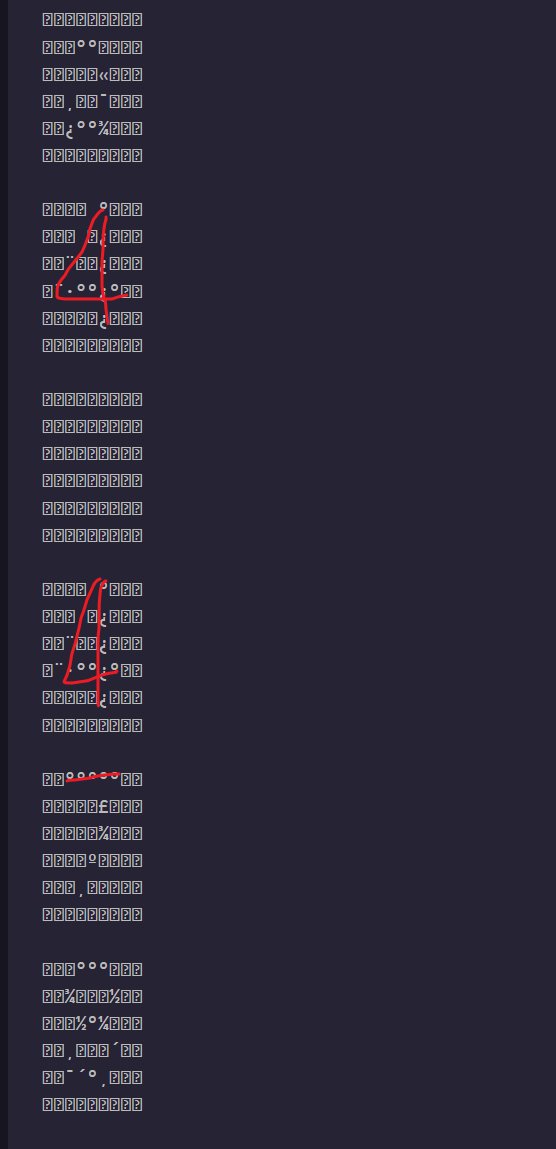 y
y
简单做个替换,其实可以看出不少东西了
for num in numbers:
if num == 128:
print(' ',end='')
elif num == 13:
print('')
else:
print('*',end='')
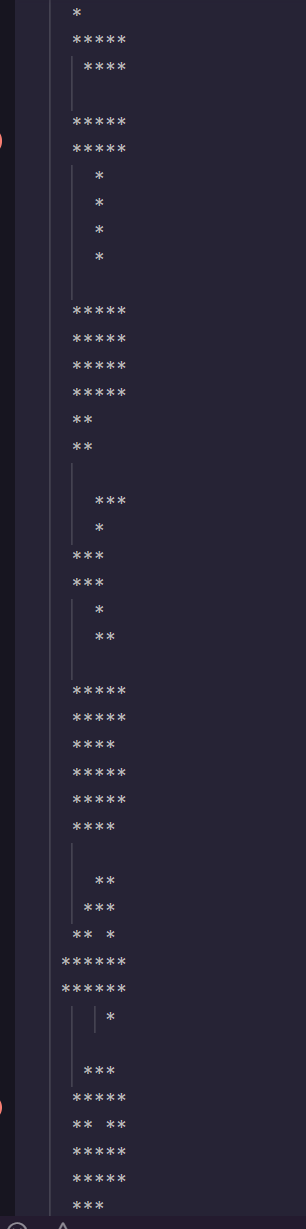
尝试把所有的字符都替换成不同的字符基本上就可以看出来了

预期做法是回到题目本身,用TRS80的点阵字符集
asciis = {"128": "⠀", "129": "⠁", "130": "⠈", "131": "⠉", "132": "⠂", "133": "⠃", "134": "⠊", "135": "⠋", "136": "⠐", "137": "⠑", "138": "⠘", "139": "⠙", "140": "⠒", "141": "⠓", "142": "⠚", "143": "⠛", "144": "⠄", "145": "⠅", "146": "⠌", "147": "⠍", "148": "⠆", "149": "⠇", "150": "⠎", "151": "⠏", "152": "⠔", "153": "⠕", "154": "⠜", "155": "⠝", "156": "⠖", "157": "⠗", "158": "⠞", "159": "⠟",
"160": "⠠", "161": "⠡", "162": "⠨", "163": "⠩", "164": "⠢", "165": "⠣", "166": "⠪", "167": "⠫", "168": "⠰", "169": "⠱", "170": "⠸", "171": "⠹", "172": "⠲", "173": "⠳", "174": "⠺", "175": "⠻", "176": "⠤", "177": "⠥", "178": "⠬", "179": "⠭", "180": "⠦", "181": "⠧", "182": "⠮", "183": "⠯", "184": "⠴", "185": "⠵", "186": "⠼", "187": "⠽", "188": "⠶", "189": "⠷", "190": "⠾", "191": "⠿"}
with open('1.txt','r') as f:
lists=f.readlines()
for string_data in lists:
# 分割字符串并提取数字
numbers = []
for token in string_data.split('CHR$('):
if ')' in token:
number_str = token.split(')')[0]
try:
number = int(number_str)
numbers.append(number)
except ValueError:
pass
print(numbers)
# 打印提取出的数字
for num in numbers:
# print(chr(num),end='')
if num == 13:
print()
else:
print(asciis[str(num)],end='')
print("")
这个效果就满分了,读出来就是flag
 lic
lic
lic
不会,要学联考没时间细看了,搜索zys的小站,抄抄
拖进audacity放大简单观察一手,发现大概有这三种序列分别是长度为57的、长度为22的和长度为44的
其中57的只在开头出现另外两种随机出现
小溜一手gpt
import wave
import numpy as np
def demodulate_pcm(filename):
# 打开WAV文件
with wave.open(filename, 'rb') as wav_file:
# 获取音频参数
channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
sample_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
# 读取音频数据
audio_data = wav_file.readframes(num_frames)
# 将二进制数据转换为numpy数组
audio_np = np.frombuffer(audio_data, dtype=np.int16)
# 解调PCM数据
demodulated_data = audio_np.flatten()
# 缩放解调数据
demodulated_data = demodulated_data / (2 ** (sample_width * 8 - 1))
return demodulated_data, sample_rate
filename = 'lic.wav' # 替换为您的WAV文件路径
demodulated_data, sample_rate = demodulate_pcm(filename)
for i in demodulated_data:
print(round(i),end='')
简单手动处理一下,把-1换2
然后把很多个0换成1个0,并且以这个0为界限分出前后两部分
然后对前一部分进行手动替换
222222222222222222222222222211111111111111111111111111111 --> 6
22222222222222222222221111111111111111111111 --> 0
222222222211111111111 --> 3
3 --> 1
然后手动把多余的2去了
然后16个一组画图,这时候画出来的图有一定的偏移,开头再添加5个6画的就很好了
f = open('3.txt').read()
for i in range(0, len(f), 16):
print(f[i:i+16][::-1])
大概这样