人工智能:CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的知识梳理
卷积神经网络(CNN)
卷积神经网络(CNN),也被称为ConvNets或Convolutional Neural Networks,是一种深度学习神经网络架构,主要用于处理和分析具有网格状结构的数据,特别是图像和视频数据。CNN 在计算机视觉任务中表现出色,因为它们能够有效地捕获和识别图像中的特征,具有平移不变性(translation invariance)。
CNN的关键特征包括:
-
卷积层(Convolutional Layers):这些层使用卷积操作来扫描输入图像,从中提取局部特征。卷积操作是通过在输入数据上滑动一个小窗口(称为卷积核)来实现的,窗口的权重在整个输入上共享,这有助于减少网络的参数数量。
-
池化层(Pooling Layers):池化层用于减小特征图的尺寸,减少计算负担,并提高网络的平移不变性。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。
-
激活函数:通常,CNN中的每个神经元都会应用一个激活函数,如ReLU(Rectified Linear Unit),以引入非线性特性,使网络能够学习更复杂的模式。
ReLU(Rectified Linear Unit)激活函数:
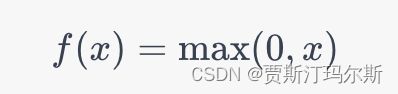
ReLU函数在正数范围内返回输入值,对于负数则返回零。它是目前最常用的激活函数,因为它简单并且在许多情况下能够提供很好的性能。ReLU的一个主要优点是它在前向传播过程中不会引起梯度消失问题。
Sigmoid激活函数:

Sigmoid函数将输入映射到0到1的范围内。它在二分类问题的输出层上常常被使用,因为它可以把输出解释为概率值。但是,在深度网络中,它容易引起梯度消失问题,因此在深层网络中使用相对较少。
Tanh激活函数:

Tanh函数将输入映射到-1到1的范围内。与Sigmoid相比,Tanh的输出范围更大,均值接近于零,有时在某些网络层中会有所用。
Leaky ReLU激活函数:
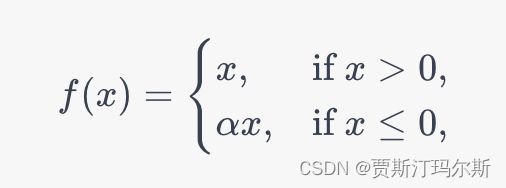
其中,α 是一个小的正数,通常取0.01。Leaky ReLU允许小于零的输入值有一个小的梯度,从而避免了ReLU中可能出现的“神经元死亡”问题。
Softmax激活函数:
Softmax函数通常用于多分类问题的输出层。它将一组数值映射到一个概率分布。给定一个具有 K个输出的向量,Softmax函数将每个输出变换为介于0到1之间的概率值,所有输出的和为1。 -
全连接层(Fully Connected Layers):通常在CNN的顶部添加全连接层,用于将高级特征映射到输出类别或标签。这些层的输出通常经过softmax函数,以生成类别概率分布。
-
权重共享:CNN的卷积层中采用权重共享,这意味着卷积核在整个输入上是共享的。这减少了参数数量,使网络更容易训练,并能够捕获输入数据的局部特征。
CNN广泛应用于图像分类、物体检测、人脸识别、语义分割、图像生成等计算机视觉任务。通过堆叠多个卷积层和池化层,可以构建深层的CNN模型,如VGG、ResNet和Inception,这些模型在各种图像处理任务中取得了卓越的性能。
示例
要构建一个卷积神经网络(CNN)来识别猫的图像,你需要使用深度学习框架,如TensorFlow或PyTorch,并准备一个包含猫图像的数据集。
以下是一个简化的Python示例代码,演示了如何使用TensorFlow来构建一个CNN模型,用于猫图像的分类任务。在实际项目中,你需要更大规模的数据集和更复杂的模型来实现更好的性能。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 构建卷积神经网络模型
model = keras.Sequential([
# 卷积层1
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
# 卷积层2
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 卷积层3
layers.Conv2D(128, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 全连接层
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid') # 二分类,输出一个0到1的概率值
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy', # 二分类交叉熵损失函数
metrics=['accuracy'])
# 加载猫图像数据集并进行预处理
# 在这里,你需要准备一个训练集和一个测试集,并进行数据预处理,包括图像大小调整、归一化等操作
# 训练模型
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
# 评估模型性能
test_loss, test_acc = model.evaluate(test_images, test_labels)
print("Test accuracy:", test_acc)
# 使用模型进行预测
predictions = model.predict(new_images)
上述代码是一个简化的示例,实际项目中需要更多的数据预处理、数据增强、超参数调整等步骤来提高模型性能。另外,你需要提供一个包含猫和非猫图像的数据集,并在代码中加载和使用这个数据集。
循环神经网络 (RNN)
循环神经网络(Recurrent Neural Network,简称RNN)是一种神经网络架构,用于处理序列数据和具有时间相关性的数据。RNN的关键特点是在网络中引入循环连接,允许信息在不同时间步之间传递,从而使其能够捕捉到时间依赖关系。
RNN中的主要组件和概念包括:
-
循环结构:RNN的核心特征是其循环结构。在每个时间步,RNN接收输入和前一个时间步的隐藏状态,然后产生新的隐藏状态。这个新的隐藏状态包含了前一个时间步的信息,使网络能够保持对序列中的先前信息的记忆。
-
隐藏状态:RNN的隐藏状态是网络在不同时间步之间的内部表示,它包含了过去时间步的信息。隐藏状态在网络的不同层次中传递,允许网络捕捉到时间相关性。
-
输入序列:RNN可以处理变长的输入序列,这使其非常适合自然语言处理(NLP)任务,例如文本生成、文本分类、语言建模等。输入序列可以是单词、字符或任何其他离散的标记。
-
输出序列:根据任务的不同,RNN可以生成输出序列,例如生成翻译的句子、音乐序列或时间序列预测。
-
门控循环单元 (GRU) 和 长短时记忆网络 (LSTM):传统的RNN容易受到梯度消失和梯度爆炸的问题。为了解决这个问题,引入了带有门控机制的改进型RNN,如GRU和LSTM。它们能够更好地处理长序列数据,学习长期依赖关系。
RNN广泛应用于各种序列建模任务,包括文本生成、语音识别、机器翻译、时间序列预测、手写识别等领域。然而,传统的RNN在处理长序列时仍然存在一些限制,如梯度问题和难以捕获长期依赖关系的问题。因此,近年来,更高级的模型,如Transformer模型,已经取代了RNN在某些任务中的地位。
循环神经网络(RNN)在许多领域和任务中都有广泛的应用,因为它们能够处理序列数据和具有时间相关性的数据。以下是一些使用RNN的处理案例示例:
-
自然语言处理 (NLP):
- 文本分类:RNN可用于将文本分类为不同的类别,如垃圾邮件检测、情感分析、新闻分类等。
- 语言建模:RNN可以用于训练语言模型,以生成连贯的文本或预测下一个词。
- 机器翻译:RNN的变体,如序列到序列模型,用于将一种语言翻译成另一种语言。
- 命名实体识别:用于从文本中识别出人名、地名、组织名等信息。
-
语音识别:
- RNN用于将语音信号转化为文本,通常是在自动语音识别(ASR)任务中。
- 音乐生成:RNN可以用于生成音乐序列,包括音符和节奏。
-
时间序列分析:
- 股票价格预测:RNN可用于分析历史股票价格数据,以预测未来价格趋势。
- 天气预测:RNN可以处理气象数据,以进行天气预测。
- 生态学研究:用于分析环境数据,如气温、湿度、降雨等。
-
推荐系统:
- RNN可以用于构建个性化推荐系统,根据用户历史行为和兴趣,推荐产品、电影、音乐等。
-
图像描述生成:
- RNN与卷积神经网络(CNN)结合使用,用于生成图像描述,给出一张图片生成描述性文本。
-
手写识别:
- RNN可用于将手写文本转换成机器可读的文本,如手写数字识别或手写汉字识别。
-
情感分析:
- RNN可用于分析文本、评论或社交媒体帖子中的情感,以判断用户的情感状态。
随着时间的推移,深度学习模型的发展,如长短时记忆网络(LSTM)和门控循环单元(GRU),以及更先进的模型,如Transformer,已经在某些任务中取代了传统的RNN。
示例
以下是一个使用Python和TensorFlow库构建简单RNN模型的示例代码,该模型用于时序数据预测。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 创建一个简单的时间序列数据
data = np.array([i for i in range(100)], dtype=np.float32)
target = data + 5 # 假设我们要预测时间序列上的线性增长
# 数据预处理
sequence_length = 10 # 每个输入序列的长度
X, y = [], []
for i in range(len(data) - sequence_length):
X.append(data[i:i+sequence_length])
y.append(target[i+sequence_length])
X = np.array(X)
y = np.array(y)
# 划分训练集和测试集
train_size = int(len(data) * 0.80)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# 创建RNN模型
model = keras.Sequential([
layers.SimpleRNN(units=64, activation='relu', input_shape=(sequence_length, 1)),
layers.Dense(1) # 输出层
])
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=16)
# 评估模型
test_loss = model.evaluate(X_test, y_test)
print("Test loss:", test_loss)
# 使用模型进行预测
predictions = model.predict(X_test)
# 打印预测结果
print("Predictions:", predictions)
上述代码演示了一个简单的RNN模型,用于预测一个时间序列的下一个值。在实际应用中,你需要更复杂的数据和模型,但这个示例可以帮助你理解如何构建和训练RNN模型。
深度神经网络 (DNN)
区别
卷积神经网络 (CNN),循环神经网络 (RNN),和深度神经网络 (DNN) 都是深度学习领域中的神经网络架构,它们各自有不同的特点和应用。以下是它们的主要区别:
- 拓扑结构:
- CNN:卷积神经网络主要用于处理图像数据,其核心组件是卷积层,用于检测图像中的特征,例如边缘、纹理和形状。
- RNN:循环神经网络主要用于序列数据,例如文本或时间序列数据。RNN具有循环结构,可以捕捉序列中的上下文信息。
- DNN:深度神经网络通常是多层的前深度神经网络(Deep Neural Network,DNN)是一种人工神经网络(Artificial Neural Network,ANN)的变体,其主要特点是具有多个隐藏层,允许网络学习多层次的特征表示。DNN通常由输入层、多个隐藏层和输出层组成,每个隐藏层包含多个神经元或节点。这些隐藏层的存在使得网络能够处理复杂的非线性关系,从而在各种任务中取得出色的性能。
以下是关于DNN的核心概念:
-
多层结构:DNN包括多个隐藏层,通常由前向连接构成。每个隐藏层都学习不同层次的特征表示,逐渐从低级特征到高级特征。
-
前向传播:数据从输入层开始,经过每个隐藏层传播到输出层。在前向传播过程中,每个神经元将输入进行加权求和,并应用一个激活函数,生成神经元的输出。
-
权重和偏差:每个连接都有一个相关联的权重,用于调整输入的影响程度。此外,每个神经元都有一个偏差(bias),用于调整激活函数的输出。
-
非线性激活函数:每个神经元通常都应用一个非线性激活函数,如ReLU(Rectified Linear Unit)或Sigmoid,以引入非线性特性,使网络能够建模更复杂的函数。
-
反向传播:DNN通过反向传播算法来学习权重和偏差的参数,以最小化损失函数。反向传播计算损失函数的梯度,并使用梯度下降或其变种来更新权重和偏差,使预测结果逼近真实标签。
-
深度学习框架:构建和训练DNN通常需要使用深度学习框架,如TensorFlow、PyTorch、Keras等。这些框架提供了高级API,简化了模型构建、训练和部署的过程。
DNN广泛应用于各种机器学习和深度学习任务,包括图像分类、物体检测、语音识别、自然语言处理、推荐系统、游戏AI等。DNN的成功部分来自于其深层结构,允许它们学习到多层次的特征表示,从而在大规模数据集上取得卓越的性能。馈神经网络,适用于各种任务,包括图像分类、语音识别和自然语言处理。
-
数据类型:
- CNN:适用于处理二维图像数据,但也可以用于处理三维数据,如视频。
- RNN:适用于处理序列数据,可以处理可变长度的序列。
- DNN:可以处理各种类型的数据,通常用于结构化数据和非序列性数据。
-
参数共享:
- CNN:卷积层具有参数共享机制,这有助于减少模型的参数数量,同时保留对图像中相同特征的位置不变性。
- RNN:RNN层在时间步之间共享权重,用于处理序列数据中的先后关系。
- DNN:DNN层没有参数共享,每个神经元都有独立的权重。
-
应用领域:
- CNN:主要用于计算机视觉任务,如图像分类、目标检测和图像分割。
- RNN:常用于自然语言处理 (NLP)、语音识别和时间序列分析。
- DNN:适用于各种任务,包括传统的机器学习问题和深度学习任务。
-
层次结构:
- CNN 和 RNN 可以被组合成深度神经网络 (DNN) 的一部分,用于构建复杂的深度学习模型。
CNN 主要用于处理图像数据,RNN 用于处理序列数据,而 DNN 是一个通用的深度神经网络架构,可以应用于各种不同类型的数据。这些神经网络架构也可以结合使用,以解决复杂的多模态问题。