数据结构——堆、堆排序和优先级队列(代码为Java版本)
目录
1. 二叉树的顺序存储
1.1 存储方式
1.2 下标关系
2. 堆(heap)
2.1 概念
2.2 操作 - 向下调整
2.3 操作 - 向上调整
2.4 操作 - 弹出堆顶元素
2.5 操作 - 向下调整实现堆排序
2.6 向下调整和向上调整的时间复杂度和空间复杂度对比
3. 堆的应用 - 优先级队列
3.1 概念
3.2 内部原理
3.3 操作-入队列
3.4 操作-出队列(优先级最高)
3.5 返回队首元素(优先级最高)
3.6 总结
4. java 中的优先级队列(PriorityQueue)
4.1 PriorityQueue的常用构造方法
4.2 PriorityQueue的扩容方法
4.3 Top-k问题
4.4 PriorityQueue中同一个类的对象之间的比较
4.5 分析PriorityQueue的offer方法
1. 二叉树的顺序存储
1.1 存储方式
使用数组保存二叉树结构,方式即将二叉树用层序遍历方式放入数组中。一般只适合表示完全二叉树,因为非完全二叉树会有空间的浪费。这种方式的主要用法就是堆的表示。
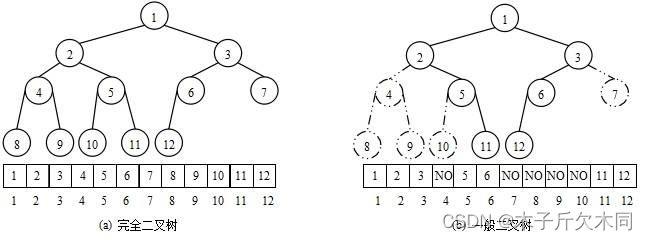
1.2 下标关系
前提:根结点从0开始算起
已知双亲(parent)的下标,则:左孩子(left)下标 = 2 * parent + 1;右孩子(right)下标 = 2 * parent + 2;
已知孩子(不区分左右)(child)下标,则:双亲(parent)下标 = (child - 1) / 2;
2. 堆(heap)
接下来的所有代码根结点都是从0开始算起!!!
2.1 概念
(1)堆逻辑上是一棵完全二叉树
(2)堆物理上是保存在数组中
(3)满足任意结点的值都大于树中结点的值,叫做大堆,或者大根堆,或者最大堆
(4)反之,则是小堆,或者小根堆,或者最小堆
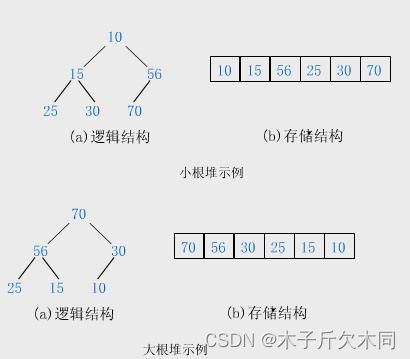
(5)堆的基本作用是,快速找集合中的最值
2.2 操作 - 向下调整
前提:左右子树必须已经是一个堆,才能调整。
说明:
- elem 代表存储堆的数组
- usedSize 代表数组中被视为堆数据的个数
- child 代表孩子的下标
- parent 代表父节点的下标
如何建堆:

具体的建堆代码和解析:

将向下调整单独封装成一个方法:
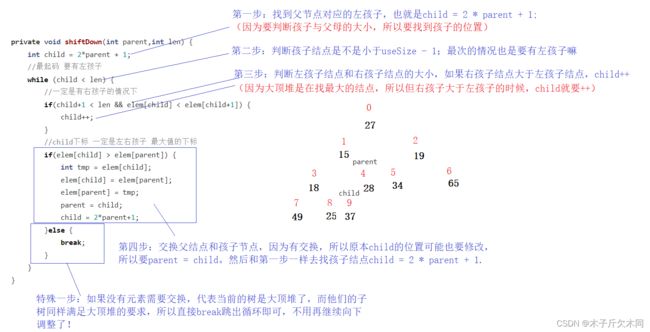
就是找父结点下标,再找孩子的下标!
public class TestHeap {
public int[] elem;
public int usedSize;//已被使用的长度
//做一个约定:初始化给个10个大小的int类型的数组,这里传进去的数组大小一定要一样大
public TestHeap(){
elem = new int[10];
}
//初始化数组
//array数组的大小一定要为40个字节,做一个约定
public void initElem(int[] array){
for(int i = 0;i < array.length;i++){
elem[i] = array[i];
usedSize++;
}
}
public void createHeap(){
for(int parent = (usedSize - 1 -1) / 2;parent >= 0;parent--){
shiftDown(parent,usedSize);
}
}
/**
*@Description:向下调整的代码
*@Author:lxt
*@Date:2023/10/24 15:08
*/
private void shiftDown(int parent,int len){
//找到左孩子结点的下标
int child = 2 * parent + 1;
while(child < len){//至少存在左孩子
//比较左右孩子的大小
//child + 1 < len是为了防止找右孩子的过程中越界
if(child + 1 < len && elem[child] < elem[child + 1])
child++;
//父子结点的比较
if(elem[child] > elem[parent]){
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
//如果有交换就要判断左子树或者右子树是不是也满足堆的要求
parent = child;
child = parent * 2 + 1;//找到左孩子的下标
}else {
break;
}
}
}
}2.3 操作 - 向上调整
就是找孩子下标,再找父结点的下标!

/**
*@Description:向上调整的算法
*@Author:lxt
*@Date:2023/10/24 15:47
*/
public void shiftUp(int child){
//找到父结点
int parent = (child - 1) / 2;
while (child > 0){
//如果孩子结点大于父结点,就交换
if(elem[child] > elem[parent]){
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
//父子结点的标记往上走
child = parent;
parent = (child - 1);
}else {
//如果没进入上面if,证明这个不用调整,是一个堆
break;
}
}
}
//向堆插入元素
public void offer(int val){
if(isFull()){
//扩容
elem = Arrays.copyOf(elem,2*elem.length);
}
//插到堆尾
elem[usedSize++] = val;
//开始向上调整
shiftUp(usedSize - 1);
}
//判断是不是为满了
public boolean isFull(){
return usedSize == elem.length;
}
//写一个交换方法
private void swap(int[] array,int i,int j){
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}2.4 操作 - 弹出堆顶元素
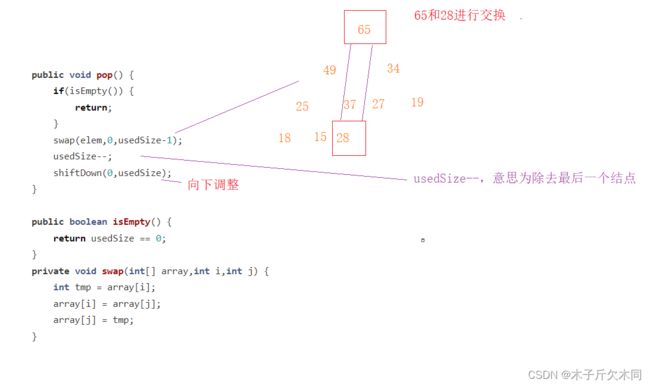
//写一个交换方法
private void swap(int[] array,int i,int j){
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
//模拟优先队列,弹出堆顶元素后,重新再进行向下调整
public void pop(){
//先判断是否为空
if(isEmpty()){
return;
}
//如果不会空,代表要交换堆顶和最后一个结点
swap(elem,0,usedSize - 1);
usedSize--;
//交换完后,进行向下调整
shiftDown(0,usedSize);
}
/**
*@Description:向下调整的代码
*@Author:lxt
*@Date:2023/10/24 15:08
*/
private void shiftDown(int parent,int len){
//找到左孩子结点的下标
int child = 2 * parent + 1;
while(child < len){//至少存在左孩子
//比较左右孩子的大小
//child + 1 < len是为了防止找右孩子的过程中越界
if(child + 1 < len && elem[child] < elem[child + 1])
child++;
//父子结点的比较
if(elem[child] > elem[parent]){
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
//如果有交换就要判断左子树或者右子树是不是也满足堆的要求
parent = child;
child = parent * 2 + 1;//找到左孩子的下标
}else {
break;
}
}
}2.5 操作 - 向下调整实现堆排序
思路和弹出堆顶元素相似!!!
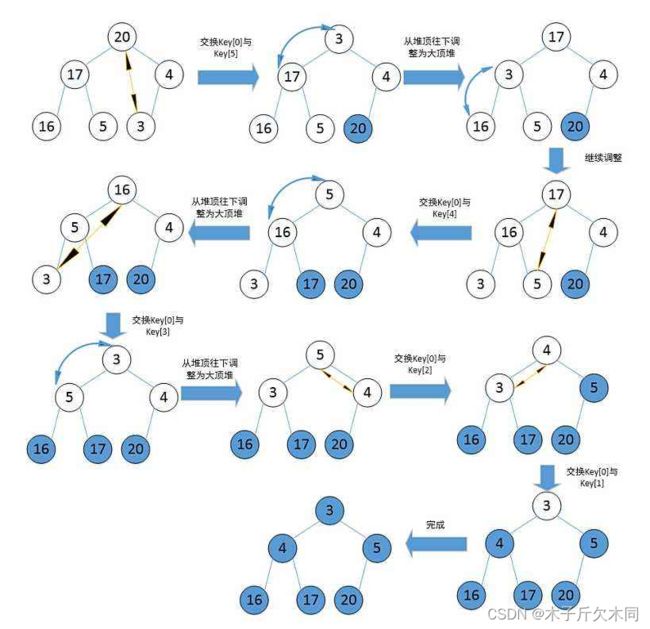
//堆排序:不断让堆顶和最后一个结点交换,然后向下调整
public void heapSort(){
int end = usedSize - 1;
while(end > 0){//下标为0的结点已经没有元素与之交换
swap(elem,0,end);
shiftDown(0,end);
end--;
}
}
/**
*@Description:向下调整的代码
*@Author:lxt
*@Date:2023/10/24 15:08
*/
private void shiftDown(int parent,int len){
//找到左孩子结点的下标
int child = 2 * parent + 1;
while(child < len){//至少存在左孩子
//比较左右孩子的大小
//child + 1 < len是为了防止找右孩子的过程中越界
if(child + 1 < len && elem[child] < elem[child + 1])
child++;
//父子结点的比较
if(elem[child] > elem[parent]){
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
//如果有交换就要判断左子树或者右子树是不是也满足堆的要求
parent = child;
child = parent * 2 + 1;//找到左孩子的下标
}else {
break;
}
}
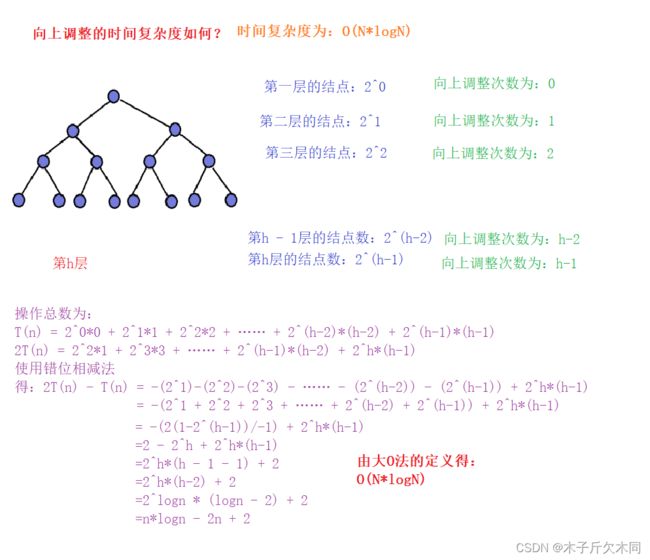
}2.6 向下调整和向上调整的时间复杂度和空间复杂度对比
这个时间复杂度是指建堆整个过程的时间复杂度,不是单指一个向下调整或者向上调整的时间复杂度!
| 向下调整 | 向上调整 | |
| 时间复杂度 | O(N) | O(N*logN) |
| 空间复杂度 | O(1) | O(1) |
(1)向下调整

(2)向上调整
3. 堆的应用 - 优先级队列
3.1 概念
在很多应用中,我们通常需要按照优先级情况对待处理对象进行处理,比如首先处理优先级最高的对象,然后处理次高的对象。最简单的一个例子就是,在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话。
在这种情况下,我们的数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)
3.2 内部原理
优先级队列的实现方式有很多,但最常见的是使用堆来构建。
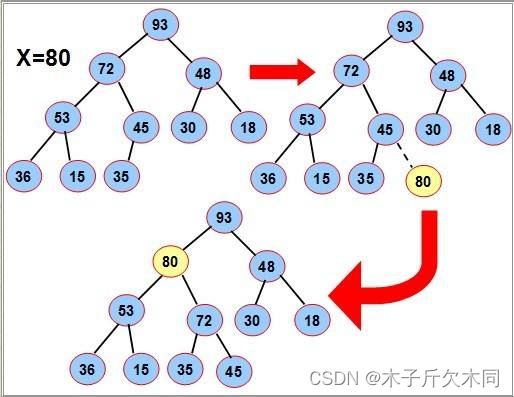
3.3 操作-入队列
过程(以大堆为例):
(1) 首先按尾插方式放入数组
(2)比较其和其双亲的值的大小,如果双亲的值大,则满足堆的性质,插入结束(其实就是向上调整)
(3)否则,交换其和双亲位置的值,重新进行 (2)、(3) 步骤
(4)直到根结点
图示:
/**
*@Description:向上调整的算法
*@Author:lxt
*@Date:2023/10/24 15:47
*/
public void shiftUp(int child){
//找到父结点
int parent = (child - 1) / 2;
while (child > 0){
//如果孩子结点大于父结点,就交换
if(elem[child] > elem[parent]){
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
//父子结点的标记往上走
child = parent;
parent = (child - 1);
}else {
//如果没进入上面if,证明这个不用调整,是一个堆
break;
}
}
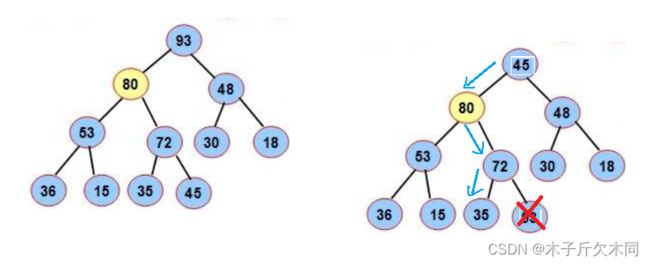
}3.4 操作-出队列(优先级最高)
为了防止破坏堆的结构,删除时并不是直接将堆顶元素删除,而是用数组的最后一个元素替换堆顶元素,然后通过向下调整方式重新调整成堆。
3.5 返回队首元素(优先级最高)
返回堆顶元素即可
3.6 总结
| 向上调整 | 向下调整 | |
| 入队列 | √ | × |
| 出队列 | × | √ |
4. java 中的优先级队列(PriorityQueue)
关于PriorityQueue的使用注意:
(1)使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue;(2)PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出ClassCastException一次。
(3)不能插入null对象,否则会抛出NullPointerException。
(4)没有容量限制,可以插入任意多个元素,其内部可以自动扩容。
(5)插入和删除元素的时间复杂度为O(logN),也就是树的高度。
(6)PriorityQueue底层使用了堆数据结构。
(7)PriorityQueue默认情况下是小堆——即每次获取到的元素都是最小元素。
PriorityQueue implements Queue
| 错误处理 | 抛出异常 | 返回特殊值 |
| 入队列 | add(e) | offer(e) |
| 出队列 | remove() | poll() |
| 队首元素 | element() | peek() |
4.1 PriorityQueue的常用构造方法
| 构造器 | 功能介绍 |
| PriorityQueue() | 创建一个空的优先级队列,默认容量是11 |
| PriorityQueue(int initialCapacity) | 创建一个初始容量为initialCapacity的优先级队列,注意:initialCapacity不能小于1,否则会抛出illegalArgumentException异常 |
| PriorityQueue(Collection c) | 用一个集合来创建优先级队列 |
| PriorityQueue(Comparator comparator) | 传入一个比较器,可以以实现同一个类不同对象的比较 |
4.2 PriorityQueue的扩容方法
在集合中找扩容方法,就去找grow方法。
jdk1.8的源码:
/**
* Increases the capacity of the array.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}优先级队列的扩容说明:
- 如果容量小于64时,是按照oldCapacity的2倍方式扩容的
- 如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
- 如果容量超过MAX_ARRA_SIZE,按照MAX_ARRAY_SIZE来进行扩容的
4.3 Top-k问题
Top-k问题:即求数据集合中前k个最大元素或者最小元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100位活跃玩家等。
对于Top-k问题,能想到的最简单最直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了,最佳方式就是用堆来解决,基本思路如下:
(1)用数据集合中的前k个元素来建堆
- 前k个最大的元素,则建小堆
- 前k个最小的元素,则建大堆
(2)用剩余的N-K个元素依次与堆顶元素比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比较完成之后,堆中剩余的k个元素就是所求的前k个最小或者最大的元素。
代码如下所示:
public static int[] maxK(int[] arr,int k){
int[] ret = new int[k];
if(arr == null || k == 0){
return ret;
}
Queue minHeap = new PriorityQueue<>(k);
//1.遍历数组的前k个放到堆当中。时间复杂度:K*logK
for (int i = 0; i < k; i++) {
minHeap.offer(arr[i]);
}
//2.遍历剩下的k-1个,每次和堆顶元素进行比较
//堆顶元素小的时候,就出堆。时间复杂度:(N-k)*logk
for (int i = k; i < arr.length; i++) {
int val = minHeap.peek();
if(val < arr[i]){
minHeap.poll();
minHeap.offer(arr[i]);
}
}
//3.将堆内的三个元素依次交给ret数组
for (int i = 0; i < k; i++) {
ret[i] = minHeap.poll();
}
return ret;
} 4.4 PriorityQueue中同一个类的对象之间的比较
类去实现Comparable接口或者创建一个Compartor的实现类。
注意:
- equals方法是比较是否相同,返回值是true或者fals。
- compareTo方法是比较大小,返回值是正数、0或者负数。
| 方法 | 说明 |
| Object.equals | 因为所有类都是继承Object的,所以直接重写即可,不过只能比较相等与否 |
| Comparable.compareTo | 需要手动实现接口,侵入性比较强,但一旦实现,每次用该类都有顺序,属于内部顺序 |
| Comparator.compare | 需要实现一个比较器对象,对待类的侵入性弱,但对算法代码实现侵入性强 |
(1)类实现Comparable接口
public class Student implements Comparable{
public int age;
public String name;
public Student() {}
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
} (2)创建一个Compartor的实现类
public static void main(String[] args) {
Queue m = new PriorityQueue(new Comparator() {
@Override
public int compare(Student o1, Student o2) {
return o1.age - o2.age;
}
});
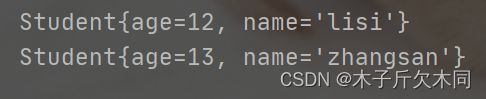
Student lisi = new Student(12, "lisi");
Student zhangsan = new Student(13, "zhangsan");
m.offer(lisi);
m.offer(zhangsan);
System.out.println(m.poll());
System.out.println(m.poll());
} 
4.5 分析PriorityQueue的offer方法
为什么说PriorityQueue默认是小根堆呢?那我们就要去看下源码了!
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
private void siftUpComparable(int k, E x) {
Comparable key = (Comparable) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
由源码和上面的图片,我们可知,PriorityQueue默认就是小根堆!
我们又该如何将PriorityQueue改变为大根堆呢?
很简单!只要我们自己手动传入一个比较器,把比较器的内容改变和PriorityQueue默认的比较结果相反即可!
public static void main(String[] args) {
Queue m = new PriorityQueue<>(new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
m.offer(10);
m.offer(1000);
System.out.println(m.poll());
System.out.println(m.poll());
} 