c++编译器是如何工作的
如果用文本写c++,它就是一些text。我们要把它变为应用从而在计算机中运行。从文本到binary基本需要两个过程。一个是compiling一个是linking。
在c++编译器中需要将文本变为中继格式obj。
然后obj们会传入linker,linker会做所有linking的事。
编译器中会有如下几个过程
预处理,预处理后会进入tokenizing(标记解释)和parsing(解析)阶段。
这基本就奔c++文本处理成编译器能懂和处理的语言。基本结果就是创建abstract syntax tree(抽象语言树),也就是我们代码的表达,但以抽象语言书的形式。
说到底,编译器的工作也就是把代码转变成constant data(常数资料)和instructions(指令)
这里可以用一个hello world程序来解释c++的工作原理
hello world 案例
建立两个文件分别为main.cpp和log.cpp
main.cpp
#includelog.cpp
#include
在debug文件夹下可发现生成了log.obj和main.obj。也就是编译器给每个cpp,也就是translation unit(编译单元),生成了obj。
在c++中不关心文件,举例来书java里,你的clas名必须和文件名一样,你的文件夹结构也得跟package一样。因此文件必须存在。在c++中没有文件这种东西,文件只给编译器提供源码的某种方法。你需要告诉编译器文件类型和编译器该如何处理它。
在cpp文件中include其他cpp有时候是很常见的做法。基本上创建一个大的cpp里面有很多cpp文件。然后你只编译那个cpp文件,也就只有一个编译单元,也就只有一个obj,这就是为啥编译单元和cpp文件是两个术语。
这是因为一个cpp不等于一个编译单元,但如果项目里都是独立的cpp文件,从不include的话,那么每个cpp就是一个translation unit,每个也会产生一个obj。
这个两个文件一个有144k一个131k很大主要是由于include了iostream。
简单文件
现在创建个简单文件
int multiply(int a, int b)
{
int result= a*b;
return result;
}
![]()
可以发现只有3k
预处理
编译第一阶段是预处理,在这期间,编译器就是检查素有pre-processing语句并评估,常见有include,define,if和ifdef,首先来看#include是如何工作的。
#include其实很简单,只要你include哪个文件,然后preprocessor就会打开该文件,读取所有内容,然后粘贴进你include的文档。
回到这里,我们创建一个header文档,记作endbrace.h并只打如下一个}
include “endbrace”
}
回到math.cpp就能看到我们为Multiply函数减去一个“}”,并加入#include endbrace.h如下
int multiply(int a, int b)
{
int result= a*b;
return result;
#include"endbrace.h"
也可以运行,这是因为直接复制过来了。其实有办法让编译器输出一个文档,里面包含所有这些preprocessor的评估结果
如果我们恢复#include"endbrace.h"
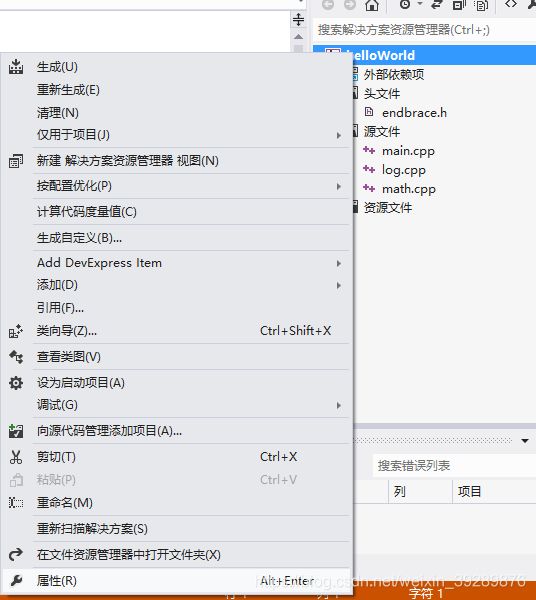
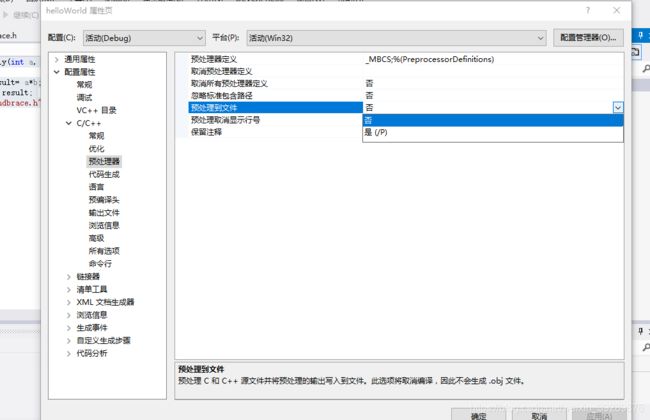
将预处理到文件选为是,确保改的是目前所应用的configuration和platform,以免改动不生效。然后重新生成,打开math.i并编辑。
![]()
#line 1 "e:\\c++\\helloworld\\helloworld\\math.cpp"
int multiply(int a, int b)
{
int result= a*b;
return result;
#line 1 "e:\\c++\\helloworld\\helloworld\\endbrace.h"
}
#line 6 "e:\\c++\\helloworld\\helloworld\\math.cpp"
preprocessor只是将h里的}插了进来。
define
修改math文件
#define integer int
integer multiply(int a, int b)
{
integer result= a*b;
return result;
}
此时.i文件为
#line 1 "e:\\c++\\helloworld\\helloworld\\math.cpp"
int multiply(int a, int b)
{
int result= a*b;
return result;
}
if
恢复int 删除define,加入if,if特点语句可以让我们依据特定条件包含或者剔除代码。
#if 1
int multiply(int a, int b)
{
int result= a*b;
return result;
}
#endif
代码改为如下,并ctrl+F7生成
#line 1 "e:\\c++\\helloworld\\helloworld\\math.cpp"
int multiply(int a, int b)
{
int result= a*b;
return result;
}
#line 8 "e:\\c++\\helloworld\\helloworld\\math.cpp"
和之前一样没有变化
如果改为if 0
#if 0
int multiply(int a, int b)
{
int result= a*b;
return result;
}
#endif
生成的为
#line 1 "e:\\c++\\helloworld\\helloworld\\math.cpp"
#line 8 "e:\\c++\\helloworld\\helloworld\\math.cpp"
include
删掉if 0,我们写include iostream,巨大巨大的iostream
#include
是一个有85000多行的文件
这就是preprocessor,当它结束,我们就可以将c++代码编译成机器码了。此时去属性关闭预处理到文件,使用这个选项就没有目标文件了。
目标文件

目标文件都是二进制文件,这其中一部分就是multiply被调用时,cpu运行的机器码。但也可以让他变得可读
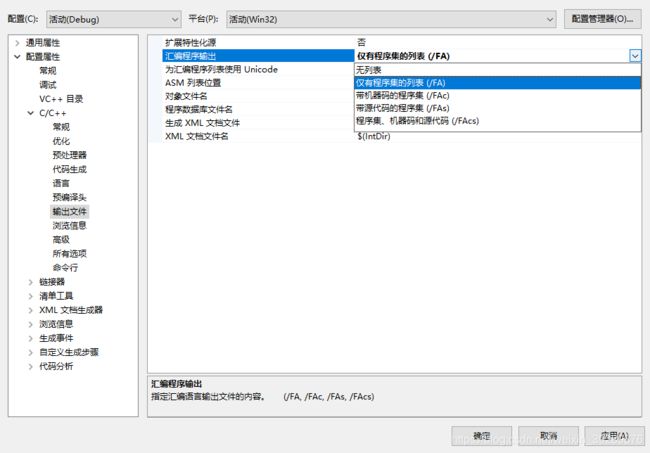
将无列表改为仅有程序列表,此时生成math.asm文件,汇编代码。
![]()
用文本编辑器打开,就基本是obj所包含的一个可读版本
; Listing generated by Microsoft (R) Optimizing Compiler Version 17.00.50727.1
TITLE E:\c++\helloWorld\helloWorld\math.cpp
.686P
.XMM
include listing.inc
.model flat
INCLUDELIB MSVCRTD
INCLUDELIB OLDNAMES
PUBLIC ?multiply@@YAHHH@Z ; multiply
EXTRN __RTC_InitBase:PROC
EXTRN __RTC_Shutdown:PROC
; COMDAT rtc$TMZ
rtc$TMZ SEGMENT
__RTC_Shutdown.rtc$TMZ DD FLAT:__RTC_Shutdown
rtc$TMZ ENDS
; COMDAT rtc$IMZ
rtc$IMZ SEGMENT
__RTC_InitBase.rtc$IMZ DD FLAT:__RTC_InitBase
rtc$IMZ ENDS
; Function compile flags: /Odtp /RTCsu /ZI
; COMDAT ?multiply@@YAHHH@Z
_TEXT SEGMENT
_result$ = -8 ; size = 4
_a$ = 8 ; size = 4
_b$ = 12 ; size = 4
?multiply@@YAHHH@Z PROC ; multiply, COMDAT
; File e:\c++\helloworld\helloworld\math.cpp
; Line 3
push ebp
mov ebp, esp
sub esp, 204 ; 000000ccH
push ebx
push esi
push edi
lea edi, DWORD PTR [ebp-204]
mov ecx, 51 ; 00000033H
mov eax, -858993460 ; ccccccccH
rep stosd
; Line 4
mov eax, DWORD PTR _a$[ebp]
imul eax, DWORD PTR _b$[ebp]
mov DWORD PTR _result$[ebp], eax
; Line 5
mov eax, DWORD PTR _result$[ebp]
; Line 6
pop edi
pop esi
pop ebx
mov esp, ebp
pop ebp
ret 0
?multiply@@YAHHH@Z ENDP ; multiply
_TEXT ENDS
END
基本上就是载入变量a到eax寄存器,然后b和a执行一个imul指令也就是乘法指令。然后把结果存在一个result变量,并把它move会eax并返回它。
之所以两次move是因为我创造一个result变量并返回它,不是直接返回a * b。
这样效率不高,如果直接返回a* b这样效率高