LinkedHashMap实现LRU算法
LinkedHashMap 概述
笔者曾提到,HashMap 是 Java Collection Framework 的重要成员,也是Map族(如下图所示)中我们最为常用的一种。不过遗憾的是,HashMap是无序的,也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。
HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个可以保持插入顺序的Map。庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个子类 —— LinkedHashMap。虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。
特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap和保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。

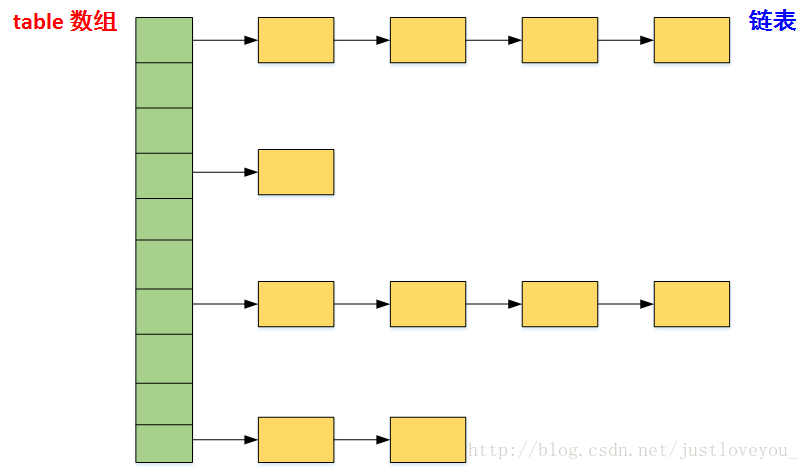
在LinkedHashMapMap中,所有put进来的Entry都保存在如下面第一个图所示的哈希表中,但由于它又额外定义了一个以head为头结点的双向链表(如下面第二个图所示),因此对于每次put进来Entry,除了将其保存到哈希表中对应的位置上之外,还会将其插入到双向链表的尾部。
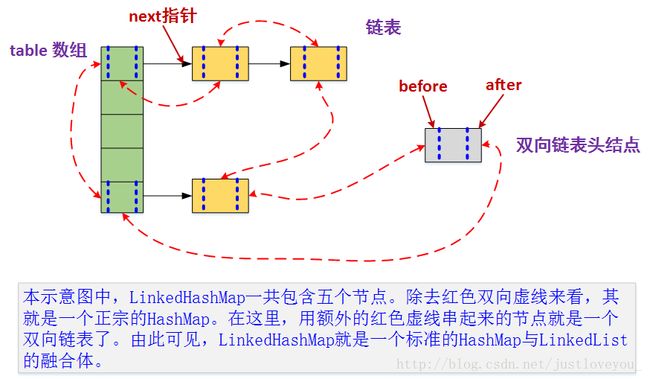
更直观地,下图很好地还原了LinkedHashMap的原貌:HashMap和双向链表的密切配合和分工合作造就了LinkedHashMap。特别需要注意的是,next用于维护HashMap各个桶中的Entry链,before、after用于维护LinkedHashMap的双向链表,虽然它们的作用对象都是Entry,但是各自分离,是两码事儿。
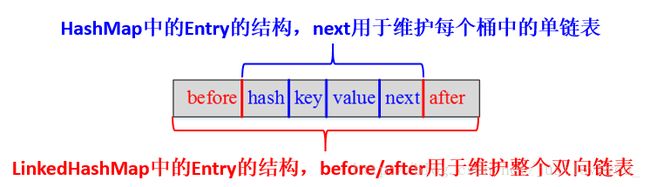
其中,HashMap与LinkedHashMap的Entry结构示意图如下图所示:
LinkedHashMap 存取小结
LinkedHashMap的存取过程基本与HashMap基本类似,只是在细节实现上稍有不同,这是由LinkedHashMap本身的特性所决定的,因为它要额外维护一个双向链表用于保持迭代顺序。
在put操作上,虽然LinkedHashMap完全继承了HashMap的put操作,但是在细节上还是做了一定的调整,比如,在LinkedHashMap中向哈希表中插入新Entry的同时,还会通过Entry的addBefore方法将其链入到双向链表中。
在扩容操作上,虽然LinkedHashMap完全继承了HashMap的resize操作,但是鉴于性能和LinkedHashMap自身特点的考量,LinkedHashMap对其中的重哈希过程(transfer方法)进行了重写。在读取操作上,LinkedHashMap中重写了HashMap中的get方法,通过HashMap中的getEntry方法获取Entry对象。在此基础上,进一步获取指定键对应的值。
LinkedHashMap 与 LRU(Least recently used,最近最少使用)算法
到此为止,我们已经分析完了LinkedHashMap的存取实现,这与HashMap大体相同。LinkedHashMap区别于HashMap最大的一个不同点是,前者是有序的,而后者是无序的。为此,LinkedHashMap增加了两个属性用于保证顺序,分别是双向链表头结点header和标志位accessOrder。
我们知道,header是LinkedHashMap所维护的双向链表的头结点,而accessOrder用于决定具体的迭代顺序。实际上,accessOrder标志位的作用可不像我们描述的这样简单,我们接下来仔细分析一波~
我们知道,当accessOrder标志位为true时,表示双向链表中的元素按照访问的先后顺序排列,可以看到,虽然Entry插入链表的顺序依然是按照其put到LinkedHashMap中的顺序,但put和get方法均有调用recordAccess方法(put方法在key相同时会调用)。
recordAccess方法判断accessOrder是否为true,如果是,则将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不相同时,put新Entry时,会调用addEntry,它会调用createEntry,该方法同样将新插入的元素放入到双向链表的尾部,既符合插入的先后顺序,又符合访问的先后顺序,因为这时该Entry也被访问了);
当标志位accessOrder的值为false时,表示双向链表中的元素按照Entry插入LinkedHashMap到中的先后顺序排序,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部,这样遍历双向链表时,Entry的输出顺序便和插入的顺序一致,这也是默认的双向链表的存储顺序。
因此,当标志位accessOrder的值为false时,虽然也会调用recordAccess方法,但不做任何操作。
get操作与标志位accessOrder
public V get(Object key) {
// 根据key获取对应的Entry,若没有这样的Entry,则返回null
Entry e = (Entry)getEntry(key);
if (e == null) // 若不存在这样的Entry,直接返回
return null;
e.recordAccess(this);
return e.value;
}
使用LinkedHashMap实现LRU算法
如下所示,笔者使用LinkedHashMap实现一个符合LRU算法的数据结构,该结构最多可以缓存6个元素,但元素多余六个时,会自动删除最近最久没有被使用的元素,如下所示:
public class LRU extends LinkedHashMap implements Map{
private static final long serialVersionUID = 1L;
public LRU(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
/**
* @description 重写LinkedHashMap中的removeEldestEntry方法,当LRU中元素多余6个时,
* 删除最不经常使用的元素
* @author rico
* @created 2017年5月12日 上午11:32:51
* @param eldest
* @return
* @see java.util.LinkedHashMap#removeEldestEntry(java.util.Map.Entry)
*/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry eldest) {
// TODO Auto-generated method stub
if(size() > 6){
return true;
}
return false;
}
public static void main(String[] args) {
LRU lru = new LRU(
16, 0.75f, true);
String s = "abcdefghijkl";
for (int i = 0; i < s.length(); i++) {
lru.put(s.charAt(i), i);
}
System.out.println("LRU中key为h的Entry的值为: " + lru.get('h'));
System.out.println("LRU的大小 :" + lru.size());
System.out.println("LRU :" + lru);
}
}