LinkedHashMap为何能够实现LRU缓存
前言
Jdk中HashMap作为高频使用的数据结构能够满足大多数业务场景,但要HashMap实现LRU缓存功能那就需要额外增加很多代码才能实现。如果想要按照插入顺序遍历HashMap同样需要额外的代码编写才能实现。本文重点讨论LinkedHashMap原理及其应用场景。
由于LinkedHashMap继承自HashMap,很多方法直接调用HashMap类中,因此阅读本前最好了解HashMap内部基本原理可以参考之前HashMap源码分析相关文章。
HashMap构造方法与内存空间分配
HashMap扩容之二进制方法妙用
LRU 介绍
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
在应用开发中使用缓存时同样用LRU来淘汰最久未被使用的缓存。实现LRU缓存时还要保留Map的特性 那么LinkedHashMap绝对是不错的选择。如果还需要定时清除过期缓存那么可以考虑Google提供的guava工具包里面包含了很多缓存功能的数据结构
LinkedHashMap 类分析
通过类图可以看到LinkedHashMap继承HashMap类实现Map接口。意味着LinkedHashMap对HashMap做了进一步的增强。
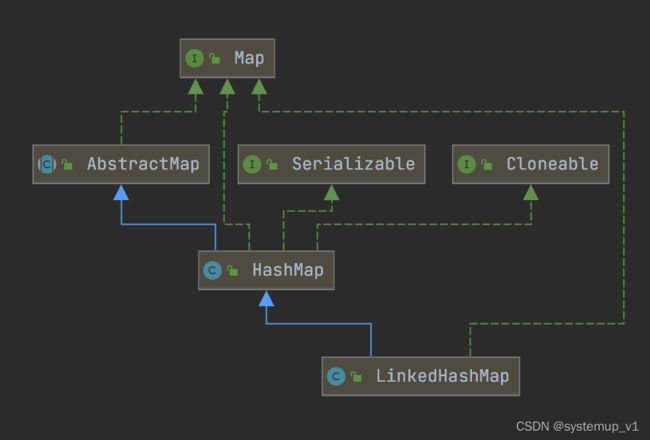
最主要变化为哈希节点的变化,LinkedHashMap的Node节点增加了两个指针分别指向前驱节点与后继节点,同时声明了双向链表的头节点与尾节点。
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
transient LinkedHashMap.Entry head;
transient LinkedHashMap.Entry tail; LinkedHashMap中还有一个很重要变量为accessOrder,该变量控制插入元素后整个链表地排序方式。
- true 表示按照访问顺序排列
- false 表示按照插入顺序排列
head 与tail指针指向可以随意调整来满足使用是遍历顺序。

重要方法分析
LinkedHashMap构造方中无一例外都调用了父类HashMap中的构造方法,并设置accessOrder值,只有最后一个构造函数可以设置accessOrder其余都为默认值。
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}此时跟HashMap其实没有区别,真正区别在插入数据与访问数据时会操作链表,在HashMap中专门提供了三个回调方法供LinkedHashMap使用。

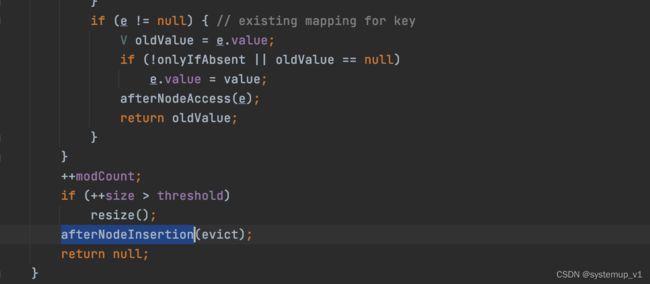
LinkedHashMap直接使用HashMap的put方法插入元素但override了get方法。通过调用HashMap的put方法然后进行回到 afterNodeAccess与afterNodeInsertion方法。在HashMap中这些回调方法默认都是空方法因此HashMap本身没有任何逻辑执行
public static void main (String []args){
LinkedHashMap map = new LinkedHashMap();
map.put("1",2);
} 下图为HashMap中putVal方法中回调执行逻辑。真正的逻辑交由子类实现。也可以自定义Map来扩展这些方法实现更多功能。
由于LinkedHashMap Node 类中加入了链表指针,因此LinkedHashMap override了HashMap中创建Node方法。
- newNode 创建拉链类Node,并设置节点指针指向
- replacementNode 替换节点 调整指针指向
- newTreeNode 创建树形节点,设置指针指向
- replacementTreeNode 替换树节点调整指针指向
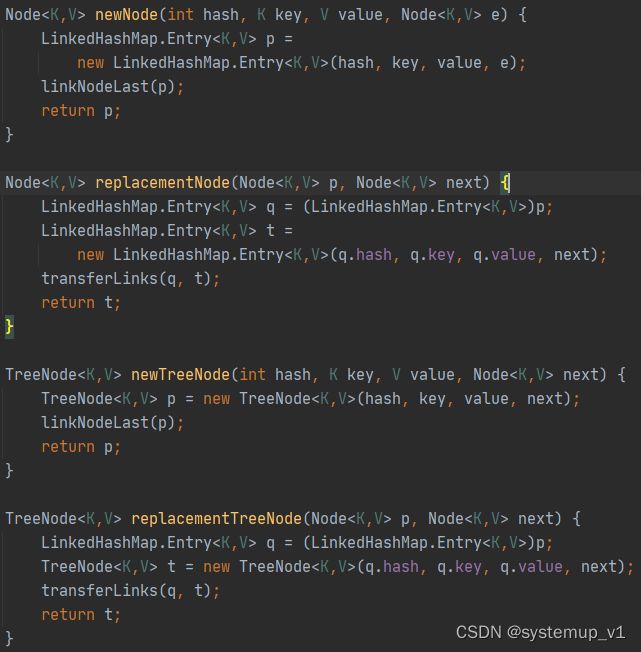
在HashMap 中 newNode存在默认实现,因此调用LinkedHashMap时由于子类覆写了该方法默认实现被覆盖。通过多态实现扩展性 
LinkedHashMap中newNode方法增加了处理链表指向的方法linkNodeLast,该方法把节点放到双向链表的末尾。
由于HashMap中插入元素是无序存放的,但通过链表可以很容易记录插入顺序因此LinkedHashMap可以按照插入顺序遍历整个Map
private void linkNodeLast(LinkedHashMap.Entry p) {
LinkedHashMap.Entry last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
} HashMap 插入数据后回调 afterNodeAccess方法。该方法可以调整链表中节点顺序为访问顺序
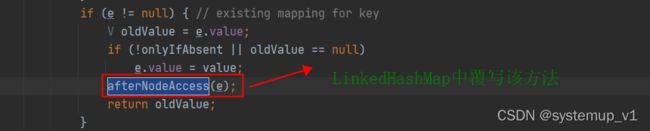
LinkedHashMap 调用get方法查询元素后同样会调用该方法调整元素顺序。
public V get(Object key) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
} afterNodeAccess方法通过调整指定节点指针将该节点调整至头结点,这符合LRU算法最近被访问到的一定是热数据其顺序应该在前面,尾节点数据代表最近最久未被使用的数据应该被剔除。
void afterNodeAccess(Node e) { // move node to last
LinkedHashMap.Entry last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry p =(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
} 总结
LinkedHashMap作为HashMap的扩展提供了很多优秀的特性,其底层数据结构设计值得学习。在特殊的业务逻辑中LinkedHashMap是不错的选择