Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition学习笔记
Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
Abstract
While dynamic Neural Radiance Fields (NeRF) have shown success in high-fidelity 3D modeling of talking portraits, the slow training and inference speed severely obstruct their potential usage. In this paper, we propose an efficient NeRF-based framework that enables real-time synthesizing of talking portraits and faster convergence by leveraging the recent success of grid-based NeRF. Our key insight is to decompose the inherently high-dimensional talking portrait representation into three low-dimensional feature grids. Specifically, a Decomposed Audio-spatial Encoding Module models the dynamic head with a 3D spatial grid and a 2D audio grid. The torso is handled with another 2D grid in a lightweight Pseudo-3D Deformable Module. Both modules focus on efficiency under the premise of good rendering quality. Extensive experiments demonstrate that our method can generate realistic and audio-lips synchronized talking portrait videos, while also being highly efficient compared to previous methods.
(虽然动态神经辐射场 (NeRF) 在谈话肖像的高保真 3D 建模方面取得了成功,但缓慢的训练和推理速度严重阻碍了它们的潜在用途。 在本文中,我们提出了一种基于 NeRF 的高效框架,该框架可以利用最近成功的基于网格的 NeRF 来实时合成会说话的肖像并加快收敛速度。 我们的关键见解是将固有的高维谈话肖像表示分解为三个低维特征网格。 具体来说,分解的音频空间编码模块使用 3D 空间网格和 2D 音频网格对动态头部进行建模。 躯干由轻量级伪 3D 可变形模块中的另一个 2D 网格处理。 两个模块都注重在渲染质量好的前提下提高效率。 大量实验表明,我们的方法可以生成逼真的和有声同步的说话肖像视频,同时与以前的方法相比也非常高效。 请参见:)
Summary
挑战:
- 如何用基于网格的NeRF有效地表示空间和音频信息仍然没有解决。通常,音频被编码为64维向量并被馈送到具有3D空间坐标的MLP中。然而,在用于线性插值的基于网格的设置中涉及音频的附加维度将导致指数计算复杂度增长。
- 对不太复杂但同样重要的躯干部分进行有效建模对于逼真的肖像来说并非微不足道。先前的实践要么涉及另一个完整的3D辐射场[22],要么学习纠缠的3D变形场[32],这是过度和昂贵的。
工作:
我们提出一个分解Audio-spatial编码模块分解的音频和空间表示为两个网格。当我们保持静态的三维空间坐标,音频动态编码的低维“坐标”。此外,而不是查询音频和在一个高维特征空间坐标网格,我们表明,他们可以分为两个独立的低维特征网格,这进一步降低了插值的成本。这种分解audio-spatial编码使一个有效的动态的头部特写建模。
至于躯干部分,我们研究其运动模式,以追求更低的计算成本。鉴于观察到拓扑结构的变化较少涉及躯干运动,我们提出了一个轻量级的伪三维变形模块模型的躯干与二维特征网格。将这两个模块与进一步的肖像特定NeRF加速设计相结合,我们的方法可以使用现代GPU实现实时推理速度。
贡献归纳:
- ·我们提出了一个分解的音频空间编码模块,以有效地建模固有的高维音频驱动的面部动态与两个低维特征网格。
- ·我们提出了一个轻量级的伪3D可变形模块,以进一步提高合成与头部运动同步的自然躯干运动的效率。
- ·我们的框架可以比以前的作品运行速度快500倍,渲染质量更好,并且还支持各种显式控制的说话肖像,如头部姿势,眨眼和背景图像。
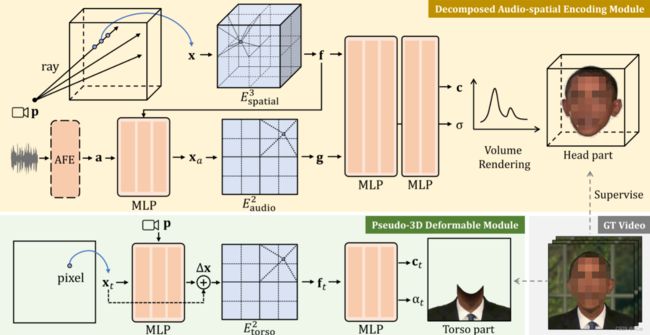
图1所示。网络体系结构。头部与Audio-spatial分解编码模块建模。输入音频信号首先处理音频特征提取器(AFE)[22],然后压缩到一个低维spatial-dependent音频协调 x a \mathbf{x}_a xa。分开两个分解网格编码器 E s p a t i a l 3 , E a u d i o 2 E_{\mathrm{spatial}}^{3},E_{\mathrm{audio}}^{2} Espatial3,Eaudio2的空间坐标 x \mathbf{x} x和音频坐标 x a \mathbf{x}_a xa。空间特性 f f f和 g g g音频特性融合在一个延时产生头颜色 c c c和密度 σ \sigma σ体绘制。Pseudo-3D变形的躯干建模模块。我们只有样品一个躯干每像素坐标 x t x_t xt,和学习的躯干动力学模型的变形场依赖头部姿势 p \mathcal{p} p。另一个网格编码器 E t o s o r 2 E_{\mathrm{tosor}}^{2} Etosor2躯干特性学习英国《金融时报》,这是美联储的躯干颜色ct和ααt延时。
损失函数:
Color : L color = ∑ C ∈ I ∣ ∣ C − C gt ∣ ∣ 2 2 Pixel Transparency : L entropy = − ∑ α ∈ I ( α log α + ( 1 − α ) log ( 1 − α ) ) Facial Region : L d y n a m i c = ∑ x a ∈ I ˉ f a c e ∣ x a ∣ Fine-tuning of the Lips : L fine-tune = ∑ C ∈ P ∣ ∣ C − C g l ∣ ∣ 2 2 + λ L P I P S ( P , P g t ) \text{Color}:\mathcal{L}_{\text{color}}=\sum_{\mathbf{C}\in\mathcal{I}}||\mathbf{C}-\mathbf{C}_{\text{gt}}||_2^2\\ \text{Pixel Transparency}:\mathcal{L}_{\text{entropy}}=-\sum_{\alpha\in\mathcal{I}}(\alpha\log\alpha+(1-\alpha)\log(1-\alpha))\\ \text{Facial Region}:\mathcal{L}_{\mathrm{dynamic}}=\sum_{\mathbf{x}_a\in\bar{\mathcal{I}}_{\mathrm{face}}}|\mathbf{x}_a|\\ \text{Fine-tuning of the Lips}:\mathcal{L}_{\text{fine-tune}}=\sum_{\mathbf{C}\in\mathcal{P}}||\mathbf{C}-\mathbf{C}_{\mathbb{gl}}||_2^2+\lambda\mathbf{LPIPS}(\mathcal{P},\mathcal{P}_{\mathbb{gt}}) Color:Lcolor=C∈I∑∣∣C−Cgt∣∣22Pixel Transparency:Lentropy=−α∈I∑(αlogα+(1−α)log(1−α))Facial Region:Ldynamic=xa∈Iˉface∑∣xa∣Fine-tuning of the Lips:Lfine-tune=C∈P∑∣∣C−Cgl∣∣22+λLPIPS(P,Pgt)
我们使用每个像素的颜色 C C C上的MSE损失来训练我们的网络;
熵正则化项用于促使像素透明度为0或1,其中 α \alpha α是图像 I \mathcal{I} I中每个像素的透明度;
音频条件应当仅影响面部区域。为了稳定动态建模,我们还提出了音频坐标上的 L 1 L1 L1正则化项,该项鼓励音频坐标 x a \mathbf{x}_a xa在非面部区域“ I f a c e \mathcal{I}_{\mathrm{face}} Iface”处接近0,这有助于避免面部区域(如头发和耳朵)之外的意外颤动;
高质量的嘴唇对于使合成的肖像自然至关重要。实验发现,嘴唇的复杂结构信息仅通过逐像素MSE损失难以学习。因此,我们提出用贴片式结构损失来微调唇部区域,文章基于面部标志对嘴唇所在的图像块 P \mathcal{P} P进行采样。然后,我们可以应用LPIPS损失与通过 λ \lambda λ平衡的MSE损失的组合来微调嘴唇区域;
Related Work
Audio-driven Talking Portrait Synthesis:
- 音频驱动的说话肖像合成旨在再现给定任意输入语音音频的特定人。已经提出了各种方法来实现逼真且良好同步的讲话肖像视频。
- 方法[6,7]定义了一组音素-嘴部对应规则,并使用基于缝合的技术来修改嘴部形状。深度学习通过合成与音频输入对应的图像来实现基于图像的方法。这些方法的一个限制是它们只能以固定分辨率生成图像,并且不能控制头部姿势。
- 另一个研究方向是基于模型的方法,其中使用面部地标和3D变形面部模型等结构表示来辅助说话肖像合成。然而,这些中间表示的估计可能引入额外的误差。
最近,一些工作[19,22,32,46]利用NeRF [36]来合成说话的肖像。基于NeRF的方法可以用较少的训练数据实现任意分辨率的真实感绘制,但目前音频驱动的说话人像合成的工作仍然受到缓慢的训练和推理速度。
Dynamic Modeling:
- 由于vanilla NeRF仅能够对静态场景进行建模,因此已经提出了许多不同的方法来对动态场景进行建模。
- 基于变形的方法旨在通过学习变形场沿着辐射场来将所有观察映射回正则空间。基于调制的方法直接在潜在代码上调节NeRF,该潜在代码可以表示时间或音频。这些方法更适合于涉及拓扑变化的复杂动力学建模,更适合于人脸动力学建模。
Efficiency:
- 为了加速渲染,最近的作品提出减小MLP的大小或完全去除它,并将3D场景特征存储在显式3D特征网格结构中。例如,DVGO [49]直接使用密集特征网格进行加速。Instant-NGP [37]采用多分辨率哈希表来控制模型大小。TensoRF [10]将密集的3D特征网格分解为紧凑的低秩张量分量。然而,这些基于网格的NeRF仅适用于静态场景。
- 作品[Fast dynamic radiance fields with time-aware neural voxels,Neural deformable voxel
grid for fast optimization of dynamic view synthesis,Devrf: Fast deformable
voxel radiance fields for dynamic scenes,Fourier plenoctrees for dynamic radiance field ren-
dering in real-time.]将这些加速技术应用于动态NeRF,但基于变形或仅支持时间相关动态,这不适合音频驱动的说话肖像合成。相比之下,我们的方法是专为音频驱动的设置在说话的肖像合成。
Method
Preliminaries
Dynamic NeRF
在动态场景新视图合成方面,附加条件(即,需要当前时间t)。先前的方法通常经由两种方法来执行动态场景建模:
- 基于变形的方法在每个位置和时间步长学习变形 Δ x \Delta\mathbf{x} Δx: G : x , t → Δ x , \mathcal{G}:\mathbf{x},t\rightarrow\Delta\mathbf{x}, G:x,t→Δx,其随后被添加到原始位置 x \mathbf{x} x。
- 基于调制的方法直接在时间上调节全光函数: F : x , d , t → σ , c . \mathcal{F}:\mathbf{x},\mathbf{d},t\rightarrow\sigma,\mathbf{c}. F:x,d,t→σ,c.。
由于基于变形的方法不擅长对拓扑变化(例如,嘴的张开和闭合),由于变形场的内在连续性[39],我们选择基于调制的策略来对头部进行建模,并且选择基于变形的策略来对具有更简单的运动模式的躯干部分进行建模。
训练数据通常是由静态摄像机记录的具有同步音轨的3-5分钟特定场景视频。每个图像帧有三个主要的预处理步骤:(1)头部、颈部、躯干和背景部分的语义解析;(2)提取2D面部标志,包括眼睛和嘴唇;(3)面部跟踪以估计头部姿势参数。。对于音频处理,应用自动语音识别(ASR)模型以从音轨提取音频特征。基于头部姿势和音频条件,NeRF可以用于学习合成头部部分。由于躯干部分不在与头部部分相同的坐标系中,因此需要单独建模。
Grid-based NeRF
最近的基于网格的NeRF使用3D特征网格编码器 E s p a t i a l 3 : f = E s p a t i a l 3 ( x ) E_{\mathrm{spatial}}^{3}\colon\mathbf{f}=E_{\mathrm{spatial}}^{3}(\mathbf{x}) Espatial3:f=Espatial3(x),其中 x ∈ R 3 \mathbf{x} \in R^3 x∈R3是空间坐标,并且 f f f是编码的空间特征。这种特征网格编码器用更便宜的线性插值来查询空间特征,从而显著提高训练和推理的效率。这使得可以实现静态3D场景的实时渲染速度。我们接受这个灵感,并将其扩展到编码动态说话人像合成所需的高维音频空间信息。
Decomposed Audio-spatial Encoding Module
Audio-spatial Decomposition
以前的隐式NeRF方法通常将音频信号编码为高维音频特征并将它们与空间特征连接。然而,将高维特征与基于网格的NeRF集成并不简单,因为线性插值的复杂性随着输入维度的增加而呈指数级增长。如果我们在网格编码器中直接使用高维级联的音频空间特征,那么它很快就变得计算上无法负担。因此,我们提出了两个设计,以减轻灾难的维度建模音频空间信息。
首先,我们将高维音频特征a压缩到低维音频坐标 x a ∈ R D \mathbf{x}_a ∈ R^D xa∈RD中,其中维度 D ∈ [ 1 , 2 , 3 ] D \in [1,2,3] D∈[1,2,3]很小。这是通过MLP以空间相关的方式实现的: x a = M L P ( a , f ) \mathbf{x}_a = MLP(a,f) xa=MLP(a,f)。我们在这里连接空间特征 f f f,使得音频坐标显式地取决于空间位置。该操作使音频特征免于隐式地学习空间信息,这使得更紧凑的音频坐标成为可能。音频坐标受到HyperNeRF中环境坐标的可变形切片表面类型的启发,但与特征网格编码器集成以实现高效率。
第二,代替使用具有较高维度 g = E 3 + D ( x , x a ) \mathbf{g} = E^{3+D}(\mathbf{x},\mathbf{x}_a) g=E3+D(x,xa)的合成音频空间网格编码器,我们将其分解成具有较低维度的两个网格编码器以分别编码音频和空间坐标: f = E s p a t i a l 3 ( x ) , g = E a u d i o D ( x a ) \mathbf{f}=E_{\mathrm{spatial}}^{3}(\mathbf{x}),\mathbf{g}=E_{\mathrm{audio}}^{D}({\mathbf{x}}_{a}) f=Espatial3(x),g=EaudioD(xa)。这进一步将插值成本从 2 3 + D 2^{3+D} 23+D降低到 2 3 + 2 D ( D ≥ 1 ) 2^3 + 2^D(D ≥ 1) 23+2D(D≥1)。空间特征 f f f和音频特征 g g g可以在执行插值之后被级联。
Explicit Eye Control
眼球运动也是自然说话肖像合成的关键因素。然而,由于眨眼和音频信号之间没有强相关性,因此先前的方法经常忽略眼睛的控制,这导致像太快或半眨眼的伪影。我们提供了一种方法来显式地控制眨眼。如图2所示,我们基于2D面部标志计算整个图像中眼睛区域的百分比,并使用该比率(通常范围为0%至0.5%)作为一维眼睛特征e。我们在这个眼睛特征上调节NeRF网络,并表明这种简单的修改足以让模型通过普通的RGB损失来学习眼睛动态。在测试时,我们可以很容易地调整眼睛的百分比来控制眼睛眨眼。

图2.地标信息的示例。基于预测的2D面部标志,我们提取三个特征来辅助训练:用于动态正则化的面部区域 I f a c e \mathcal{I}_{\mathrm{face}} Iface、用于眼睛控制的眼睛比率 e e e以及用于嘴唇微调的嘴唇贴片 P \mathcal{P} P。
Overall Head Representation
连接空间特征 f f f、音频特征 g g g、眼睛特征 e e e沿着潜在外观嵌入 i i i ,使用小的MLP来产生密度和颜色:
c , σ = M L P ( f , g , e , i ) \mathbf{c},\sigma=\mathbf{M}\mathbf{LP}(\mathbf{f},\mathbf{g},e,\mathbf{i}) c,σ=MLP(f,g,e,i)
Pseudo-3D Deformable Module
与头部相比,躯干部分几乎是静态的,仅包含轻微的运动而没有拓扑变化。以前的方法要么使用另一个全动态NeRF来建模躯干[22],要么与头部一起学习纠缠变形场[32]。我们认为这些方法是多余的,并提出了一个更有效的伪3D可变形模块,如图1的下半部分所示。
我们的方法可以被视为基于变形的动态NeRF的2D版本。代替沿着每个相机射线对一系列点进行采样,我们仅需要从图像空间对一个像素坐标 X t ∈ R 2 X_t \in R^2 Xt∈R2进行采样。变形以头部姿势 p \mathcal{p} p为条件,使得躯干运动与头部运动同步。我们采用MLP来预测变形: Δ x = M L P ( X t , P ) \Delta \mathbf{x}=MLP(X_t,P) Δx=MLP(Xt,P)。变形坐标被馈送到2D特征网格编码器以获得躯干功能: f t = E t o r s o 2 ( x t + Δ x ) . \mathbf{f}_{t}=E_{\mathrm{torso}}^{2}(\mathbf{x}_{t}+\Delta\mathbf{x}). ft=Etorso2(xt+Δx).。另一个MLP用于生成躯干RGB颜色和Alpha值:
c t , α t = M L P ( f t , i t ) \mathbf{c}_t,\alpha_t=\mathbf{MLP}(\mathbf{f}_t,\mathbf{i}_t) ct,αt=MLP(ft,it)
其中 i t i_t it是引入更多模型容量的潜在外观嵌入。我们表明,这种基于变形的模块可以成功地模拟躯干动力学和合成自然躯干图像匹配的头部。更重要的是,通过2D特征网格的伪3D表示是非常轻量级和高效的。单独渲染的头部和躯干图像可以与任何提供的背景图像进行阿尔法合成,以获得最终的输出肖像图像。
Experiment

表1.自驱动设置下的定量比较。我们在同一个身份的测试集上进行自驱动合成,并比较人脸重建的质量。MakeItTalk [67]无法生成与地面实况视频相同的头部姿势,因此未报告PSNR和LPIPS。培训时间仅针对人员特定方法报告。