YOLOv5— Fruit Detection
本文为[365天深度学习训练营学习记录博客
参考文章:365天深度学习训练营-第7周:咖啡豆识别(训练营内部成员可读)
原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)
文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)
一、 数据集详情:
数据集来源方式一:
Fruit Detection | Kaggle200 images belonging to 4 classes https://www.kaggle.com/datasets/andrewmvd/fruit-detection/数据集来源方式二:
https://www.kaggle.com/datasets/andrewmvd/fruit-detection/数据集来源方式二:
链接:https://pan.baidu.com/s/1XAjw6EkViD8WntscrYscYw?pwd=idfi
提取码:idfi

二、前期准备:
安装Git
下载地址为 git-scm.com或者gitforwindows.org,或者阿里镜像

一直Next就可以
配置环境变量
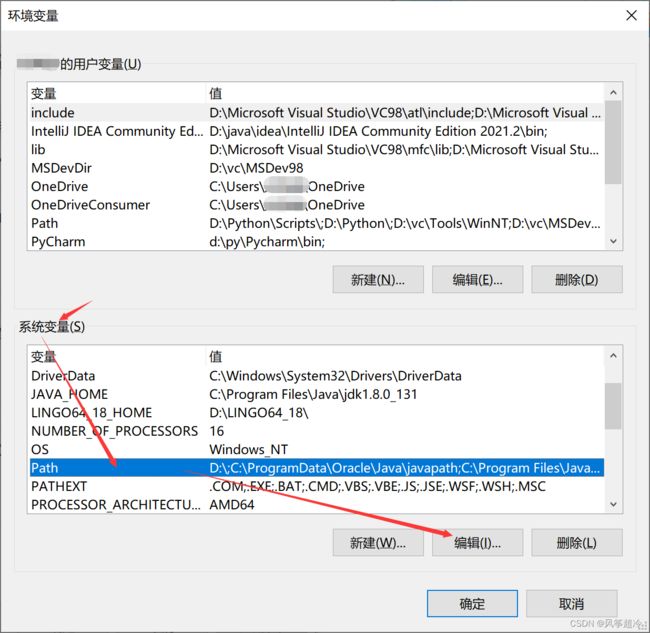

最后一步根据自己Git的bin目录路径设置
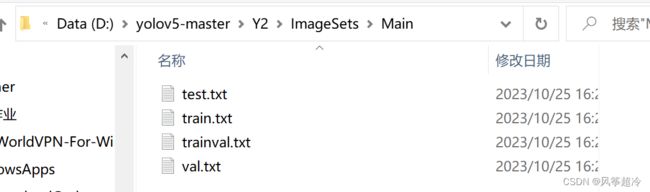
数据集位置

ImageSets文件下Main文件夹 及下图所示文本文件需自行创建,文本文件内容运行代码后得到
voc_label.py代码内容:
# 划分train、test、val文件
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='D:/yolov5-master/Y2/annotations', type=str, help='input txt label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='D:/yolov5-master/Y2/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 8/9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
voc_label.py代码内容:
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["banana", "snake fruit", "dragon fruit", "pineapple"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('D:/yolov5-master/Y2/annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/yolov5-master/Y2/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
filename = root.find('filename').text
filenameFormat = filename.split(".")[1]
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
return filenameFormat
wd = getcwd()
for image_set in sets:
if not os.path.exists('D:/yolov5-master/Y2/labels/'):
os.makedirs('D:/yolov5-master/Y2/labels/')
image_ids = open('D:/yolov5-master/Y2/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('D:/yolov5-master/Y2/%s.txt' % (image_set),'w')
for image_id in image_ids:
filenameFormat = convert_annotation(image_id)
list_file.write( ' D:/yolov5-master/Y2/images/%s.%s\n' % (image_id,filenameFormat))
list_file.close()
三、模型训练:
1.打开命令窗
2.命令窗中输入:
python D:/yolov5-master/train.py --img 900 --batch 2 --epoch 100 --data D:/yolov5-master/data/ab.yaml --cfg D:/yolov5-master/models/yolov5s.yaml --weights D:/yolov5-master/yolov5s.pt3.运行结果:
D:\yolov5-master>python D:/yolov5-master/train.py --img 900 --batch 2 --epoch 100 --data D:/yolov5-master/data/ab.yaml --cfg D:/yolov5-master/models/yolov5s.yaml --weights D:/yolov5-master/yolov5s.pt
train: weights=D:/yolov5-master/yolov5s.pt, cfg=D:/yolov5-master/models/yolov5s.yaml, data=D:/yolov5-master/data/ab.yaml, hyp=data\hyps\hyp.scratch-low.yaml, epochs=100, batch_size=2, imgsz=900, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs\train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
YOLOv5 2023-10-15 Python-3.10.7 torch-2.0.1+cpu CPU
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=4
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 24273 models.yolo.Detect [4, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5s summary: 214 layers, 7030417 parameters, 7030417 gradients, 16.0 GFLOPs
Transferred 342/349 items from D:\yolov5-master\yolov5s.pt
WARNING --img-size 900 must be multiple of max stride 32, updating to 928
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
train: Scanning D:\yolov5-master\Y2\train... 1 images, 0 backgrounds, 159 corrupt: 100%|██████████| 160/160 [00:15<00:0
AutoAnchor: 4.33 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset
Plotting labels to runs\train\exp10\labels.jpg...
Image sizes 928 train, 928 val
Using 0 dataloader workers
Logging results to runs\train\exp10
Starting training for 100 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/99 0G 0.1304 0.06978 0.0441 7 928: 0%| | 0/1 [00:01训练结果保存在Results saved to runs\train\exp10文件中。