elasticsearch-倒排索引原理
倒排索引
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
es使用称为倒排索引的结构达到快速全文搜索的目的。
一个倒排索引包含一系列不同的单词,这些单词出现在任何一个文档,对于每个单词,对应着所有它出现的文档。
倒排索引建立的分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
倒排索引
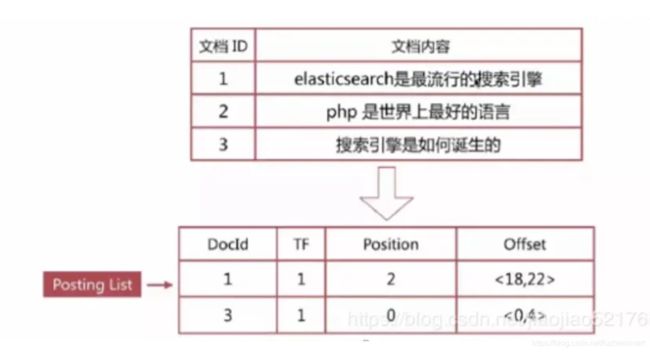
根据字面意思可以知道他和正序索引是反的。在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(文档要除去一些无用的词,比如’的’这些,剩下的词就是关键词,每个关键词都有自己的ID)。例如“文档1”经过分词,提取了3个关键词,每个关键词都会记录它所在在文档中的出现频率及出现位置。
那么上面的文档及内容构建的倒排索引结果会如下图(注:这个图里没有记录展示该词在出现在哪个文档的具体位置):
| 单词 | 文档ID列表 |
| elasticsearch | 1 |
| 流行 | 1 |
| 搜索引擎 | 1,3 |
| php | 2 |
| 世界 | 2 |
| 最好 | 2 |
| 语言 | 2 |
| 诞生 | 3 |
如何来查询呢?
比如我们要查询‘搜索引擎’这个关键词在哪些文档中出现过。首先我们通过倒排索引可以查询到该关键词出现的文档位置是在1和3中;然后再通过正排索引查询到文档1和3的内容并返回结果。
倒排索引组成
倒排索引主要由单词词典(Term Dictionary)和倒排列表(Posting List)及倒排文件(Inverted File)组成。
他们三者的关系如下图:

单词词典(Term Dictionary):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息及频率(作关联性算分),每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
以查找搜索引擎查找为例:
单词词典查询定位问题
对于一些规模很大的文档集合来讲,他里面可能包括了上百万的关键单词(term),能否快速定位到具体单词(term),这会直接影响到响应速度。
假设我们有很多个 term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的 term 一定很慢,因为 term 没有排序,需要全部过滤一遍才能找出特定的 term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的 term。这个就是 term dictionary。有了 term dictionary 之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次 random access 大概需要 10ms 的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。于是就有了 term index。term index 有点像一本字典的大的章节表。
目前常用的方式是通过hash加链表结构和树型结构(b树或者b+)。
hash加链表:

这是很常用的一种数据结构。这种方式就可以快速计算单词的hash值从而定位到他所有在的hash表中,如果该表是又是一个链表结构(两个单词的hash值可能会一样),那么就需要遍历这个链表然后再对比返回结果。这种方式最大的缺点就是如果有范围查询的时候就很难做到。
树型结构:
B树(或者B+树)是另外一种高效查找结构,下图是一个 B树结构示意图。B树与哈希方式查找不同,需要字典项能够按照大小排序(数字或者字符序),而哈希方式则无须数据满足此项要求。
B树形成了层级查找结构,中间节点用于指出一定顺序范围的词典项目存储在哪个子树中,起到根据词典项比较大小进行导航的作用,最底层的叶子节点存储单词的地址信息,根据这个地址就可以提取出单词字符串。
