【神经网络】2021-IJCAI-从概念中学习:迈向 Few-shot Learning 的纯净记忆
2021-IJCAI-Learn from Concepts: Towards the Purified Memory for Few-shot Learning
- 从概念中学习:迈向 Few-shot Learning 的纯净记忆
-
- 摘要
- 1. 引言
- 2. 方法
-
- 2.1. 框架概述
- 2.2. 精细记忆更新
- 2.3. 图扩充模块
- 2.4. 预测与优化
- 3. 实验
-
- 3.1. 实验设置
- 3.2. 实施细节
- 3.3. 主要结果
- 3.4. 消融研究
- 4. 结论
- 参考文献
从概念中学习:迈向 Few-shot Learning 的纯净记忆
论文地址
摘要
人类具有很强的泛化能力,可以通过只看到少量样本来识别一个新类别。这是因为人类拥有从我们脑海中已经存在的概念中学习的能力。然而,许多现有的 few-shot 方法未能解决这样一个基本问题,即如何利用过去学到的知识来改进对新任务的预测。在本文中,我们提出了一种模拟人类识别过程的新型净化记忆机制。这种新的记忆更新方案使模型能够从语义标签中净化信息,并在逐集训练时逐步学习一致、稳定和表达性强的概念。在此基础上,引入了图增强模块(Graph Augmentation Module,GAM),通过图神经网络聚合这些从新任务中学到的概念和知识,使预测更加准确。通常,我们的方法与模型无关,计算效率高,内存成本可忽略不计。在几个基准上进行的大量实验表明,所提出的方法可以始终优于大量最先进的小样本学习方法。
1. 引言
深度学习的成功源于大量的标记数据 [Noh et al, 2017; Bertinetto et al, 2016; Long et al, 2015],而人类通过只看到少数样本就具有良好的泛化能力。这两个事实之间的差距给小样本学习的研究带来了极大的关注 [Vinyals et al, 2016; Finn et al, 2017; Sung et al, 2018]。与传统的深度学习场景不同,few-shot learning 不是对未见过的样本进行分类,而是将元知识快速适应新的任务,其中只给出很少的标记数据和从以前的经验中获得的知识。
最近,显着优势 [Vinyals et al, 2016; Finn et al, 2017; Snell et al, 2017; Sung et al, 2018] 已经通过使用元学习的思想结合情景训练 [Vinyals et al, 2016] 来解决这个问题。直觉是使用情景采样策略,这是一种将知识从已知类别(即具有足够训练示例的已知类别)转移到新类别(即具有少量示例的新类别)的有前途的趋势,模拟人类学习过程。在此框架中,基于度量的方法 [Vinyals et al, 2016; Snell et al, 2017] 和基于图的方法 [Garcia and Bruna, 2017; Liu et al, 2018; Kim et al, 2019; Yang et al, 2020] 是两种主要利用可迁移元知识的代表性方法。由于能够有效地从图数据中学习,基于图的方法通常优于基于度量的方法,后者将成对查询支持关系扩展到图结构。
尽管基于图的方法很有效 [Kim et al, 2019; Yang et al, 2020],他们中的大多数人都忽略了一个关键问题,即当一个接一个地训练情景时,过去学到的知识如何对新任务有用。作为一种直觉,对于未见过的任务,人类不会使用全部知识,而是使用一些信息丰富的相关概念来提高对新任务的预测能力。例如,如果一个人已经了解了马、老虎和熊猫的概念,那么只要发现斑马的轮廓像马,条纹像老虎,黑白相间的颜色像熊猫,就很容易认出斑马。受这种简单直觉的启发,我们提出了一个假设,即小样本学习模型应该明确地建立情景之间的关系,并充分利用现有的学习知识。
然而,它提出了两个阻碍现有基于图的方法的基本问题:1)如何在情景快速到来时学习稳定和一致的概念;2)学习到的概念在适应新任务时如何进一步帮助预测。在本文中,我们提出了一个净化记忆框架来解决这两个问题。我们的基本思路很简单,就是模拟人类的识别过程。为了保持稳定和一致的概念,我们在情景训练期间持有一个记忆库,它从信息瓶颈原则的角度为每个类别学习最佳原型表示 [Tishby and Zaslavsky, 2015]。通过逐步从语义标签中纯化信息,存储的知识应该具有普遍的表达性、一致性和稳定性。
为了充分利用净化后的记忆,我们提出了图增强模块(GAM)作为挖掘元知识和建立不同情景之间相关性的一种方式。当处理一个新任务时,GAM 首先通过以当前任务的类中心作为查询来检索 k-最近邻的概念。然后将检索到的概念和情景训练样本转发到具有自适应加权方案的图神经网络(GNN)。因此,过去学到的概念和从新任务中学到的知识被聚合在一起,这使我们的模型能够做出准确的预测。值得注意的是,我们的方法是一种与模型无关的方法,可以灵活地集成到任何高级 GNN 方法中,而计算成本可以忽略不计。
我们的主要贡献有三方面:(1)我们提出了一种新的记忆净化机制,具有高效、一致性和强大的表达能力;(2)所提出的 GAM 能够挖掘元知识并捕获不同事件之间的相关性;(3)我们的方法产生了最先进的小样本结果,我们有趣的发现强调需要重新思考我们使用元知识的方式。
2. 方法
本文旨在解决少样本分类问题。问题定义与传统分类有根本不同,我们的目标不是对看不见的样本进行分类,而是使元知识快速适应新任务。具体来说,提供了一个带有来自基类 C b a s e C^{base} Cbase 的足够训练样本的标记数据集,目标是使用从一组新颖的类 C n o v e l C^{novel} Cnovel 收集的非常有限的数据来学习概念,其中 C b a s e ∩ C n o v e l = ∅ C^{base}\cap C^{novel}=\emptyset Cbase∩Cnovel=∅。解决 few-shot 问题的一个有效方法是使用情景采样策略。在这个框架中,元训练和元测试中的样本不是样本而是情景 { T } \left\{\mathcal{T}\right\} {T},每个情景包含 N N N 个类(ways)和每个类 K K K 个镜头(shots)。特别地,对于 N − w a y K − s h o t N-way\ K-shot N−way K−shot 任务,支持集 S = { ( x i , y i ) } i = 1 N × K S=\left\{\left(x_i,\ y_i\right)\right\}_{i=1}^{N\times K} S={(xi, yi)}i=1N×K 和查询集 Q = { ( x i , y i ) } i = N × K + 1 N × K + T Q=\left\{\left(x_i,\ y_i\right)\right\}_{i=N\times K+1}^{N\times K+T} Q={(xi, yi)}i=N×K+1N×K+T 个样本。这里, x i x_i xi 和 y i ∈ { C 1 , . . . , C N } y_i\in\left\{C_1,\ ...,\ C_N\right\} yi∈{C1, ..., CN} 是第 i i i 个输入数据,来自 C b a s e C^{base} Cbase。在元测试中,测试任务也从未见过的 C n o v e l C^{novel} Cnovel 中抽取相同大小的情节。目的是将查询集中的 T T T 个未标记样本正确分类为 N N N 个类。
2.1. 框架概述
所提出方法的框架如图 1 所示。它主要由三个部分组成,即用于判别特征提取的编码器、用于表达元知识存储的记忆模块、用于综合推理的图扩充模块。一般来说,我们的方法可以概括为 3 个阶段(即预训练、元训练、元测试)。
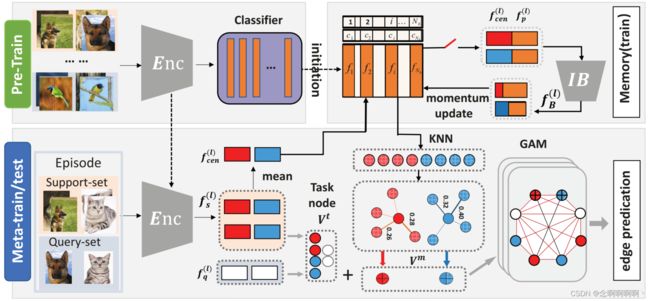
第一阶段预训练。我们遵循一个简单的基线 [Chen et al, 2020]:在元训练集 C b a s e C^{base} Cbase 上学习监督表示,然后在此表示之上使用线性分类器。已经表明,这个预训练阶段有利于下游的小样本任务 [Tian et al, 2020],然后经过训练的特征提取器(例如 ResNet-12 [He et al, 2016])和分类器分别用作编码器和记忆库(memory bank)的初始化。
第二阶段元训练。我们首先提取支持样本和查询样本的特征作为与任务相关的嵌入 V t V^t Vt。然后为了促进快速适应,我们的方法拥有一个记忆库来存储支持集的表达表示。该记忆库使用新的更新方案进行了优化,以逐步净化判别信息(在第 2.2 节中介绍)。此外,净化后的记忆与用于稳健预测的图扩充模块相结合(在第 2.3 节中介绍)。在这个模块中,我们挖掘相关原型 V m V^m Vm,在本文中称为元知识,以通过图神经网络传播 V t V^t Vt 和 V m V^m Vm 之间的相似性。因此,我们的模型能够以可忽略的内存成本方便地泛化到新任务。
第三阶段元测试。Meta-Test 的流程与 Meta-Train 类似,同样采用 episodic sampling 策略。但与 Phase-II 不同的是,记忆库和其他模块在整个过程中不会更新。换句话说,开关将闭合,如图 1 所示。
2.2. 精细记忆更新
元知识在从未知样本中学习新概念方面发挥着重要作用,最近的 FSL 进展 [Ramalho and Garnelo, 2019] 经常利用记忆机制来存储这种元知识。在其典型设置中,记忆会尝试保留尽可能多的信息(例如,存储全部特征)。然而,我们认为这种策略既无效又低效。在 FSL 的上下文中,episodic sampling 使特征提取器可以用很少的样本快速学习新概念,这会导致当特征提取器处于非常不同的任务上下文时更新记忆中的特征的问题。从这个角度来看,从不同任务中学习到的表示需要一个净化过程才能成为一个稳定的概念。
为了缓解上述问题,我们建议通过学习每个类别的最佳原型来优化记忆。具体来说,考虑 FSL 中的 N − w a y K − s h o t N-way K-shot N−wayK−shot 任务,我们使用 f s u p l ∈ R [ N × K , d ] f_{sup}^l\in\mathbb{R}^{\left[N\times K,\ d\right]} fsupl∈R[N×K, d] 来表示第 l l l 集中支持集的特征表示, M ∈ R [ C , d ] \mathbb{M}\in\mathbb{R}^{[C,d]} M∈R[C,d] 表示记忆库,其中 C C C 和 d d d 分别表示类别总数和原型的维度。
为了逐步从标签中纯化语义信息,我们首先对 f s u p l f_{sup}^l fsupl 进行类别平均,以获得质心 f c e n l ∈ R [ c , d ] f_{cen}^l\in\mathbb{R}^{[c,d]} fcenl∈R[c,d],然后将每个质心与原型 f p l ∈ R [ c , d ] f_p^l\in\mathbb{R}^{[c,d]} fpl∈R[c,d](存储在记忆中)属于同一类别。我们将连接 f c a t l ∈ R [ c , 2 × d ] f_{cat}^l\in\mathbb{R}^{[c,2×d]} fcatl∈R[c,2×d] 转发到全连接层以降低维度,并利用输出来改进记忆。这里我们建议用信息瓶颈原理来提纯这个概念。以下约束用于确保 IB 正常工作,即保留语义标签信息,同时避免与任务无关的麻烦。
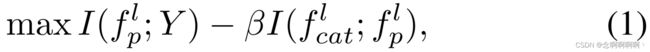
其中 I ( . ; . ) I\left(.;\ .\right) I(.; .) 表示互信息, Y Y Y 表示标签, β \beta β 分别是拉格朗日系数。
具体来说,公式(1)旨在学习关于目标 Y Y Y 的最大信息量同时对 f c a t l f_{cat}^l fcatl 具有最大压缩性的原型 f p l f_p^l fpl。然而,公式(1)需要估计高维的互信息,这在这样的高维空间中是很棘手的。幸运的是,由于我们的目标是净化这个概念,我们证明了自我知识蒸馏损失可以与方程式(1)严格一致。其中数学推导显示在补充材料中。
在实践中,强制执行以下约束来净化判别信息并进一步细化记忆:
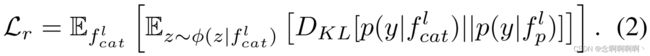
这里, θ \theta θ 和 φ \varphi φ 表示编码器和 FC 层的参数, D K L [ . ∣ ∣ . ] D_{KL}[.||.] DKL[.∣∣.] 表示 KL-divergence, y y y 表示标签。请注意, p ( y ∣ f c a t l ) p\left(y|f_{cat}^l\right) p(y∣fcatl) 和 p ( y ∣ f p l ) p\left(y|f_p^l\right) p(y∣fpl) 都表示条件分布,并且在实践中,它们是额外线性 linear 的输出(详细说明见补充材料)。
M \mathbb{M} M 的细化本质上是迭代地聚合判别信息并稀释与任务无关的干扰。一个天真的解决方案是将 IB 的输出附加到 M \mathbb{M} M 的每一集(episode)。但这种解决方案会导致巨大的空间和时间成本,并产生较差的性能(参见第 3.4 节)。综上所述,我们建议通过动量更新来细化记忆库。形式上, M \mathbb{M} M 通过以下方式更新:
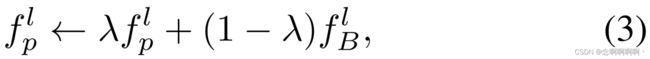
其中 λ ∈ [ 0 , 1 ) \lambda\in[0,\ 1) λ∈[0, 1) 是一个动量系数, f B l ∈ R d f_B^l\in\mathbb{R}^d fBl∈Rd 表示 IB 在当前 episode 的输出。
通过这种方式,记忆通常应该是富有表现力的、一致的并且效率更高。改进的原型表示进一步结合和聚合元知识挖掘,并用于促进 FSL 的推理,如下所述。
2.3. 图扩充模块
对于一个看不见的任务,人类不会使用全部知识,而是使用一些信息丰富的相关概念来抽象新任务。受此启发,我们提出了一种元知识挖掘方法来模拟这种行为。我们的方法背后的核心思想是聚合相似的特征,而不是整个记忆库,以帮助我们的模型学习新概念以应对未见过的任务。特别是,我们使用图形增强模块(GAM)来捕获特定任务上下文与相关概念之间的关系。然后通过图神经网络传播它们的相似性 [Kim et al, 2019],其中每一层执行节点特征和边特征更新,以实现快速和全面的推理。
元知识挖掘。对于第 l l l 集中的每个类质心 f c e n l [ i ] f_{cen}^l[i] fcenl[i],我们首先计算 f c e n l [ i ] f_{cen}^l[i] fcenl[i] 与内存 M \mathbb{M} M 中每个原型之间的余弦相似度。然后我们选择 f c e n l [ i ] f_{cen}^l[i] fcenl[i] 的 k k k 个最近邻,表示为 M K = { m 1 , m 2 , . . . , m k } MK=\left\{m_1,\ m_2,\ ...,\ m_k\right\} MK={m1, m2, ..., mk}。为了执行聚合,我们使用由质心 f c e n l [ i ] f_{cen}^l[i] fcenl[i] 和选定的嵌入 m j m_j mj 计算的注意力系数:

其中 ⟨ ⋅ , ⋅ ⟩ \left\langle⋅, ⋅\right\rangle ⟨⋅,⋅⟩ 表示两个向量之间的余弦相似度, τ \tau τ 是标量参数。最后计算每个类的元知识节点为:
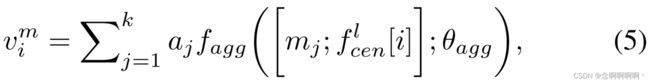
其中 [ ⋅ ; ⋅ ] [\cdot;\ \cdot] [⋅; ⋅] 是拼接操作, f a g g ( ⋅ ; θ a g g ) f_{agg}\left(\cdot;\theta_{agg}\right) fagg(⋅;θagg) 对由全连接层组成的拼接特征进行变换: R 2 d → R d \mathbb{R}^{2d}\rightarrow\mathbb{R}^d R2d→Rd,参数集为 θ a g g \theta_{agg} θagg。
增强图初始化。对于 N − w a y K − S h o t N-way\ K-Shot N−way K−Shot 任务,给定从编码器提取的特征和挖掘的元知识,构建一个全连接图 G = ( V , E ) G=\left(V,\ E\right) G=(V, E),其中 V = { v i t } i = 1 N × K + T ∪ { v i m } i = 1 N = { v i } i = 1 N × ( K + 1 ) V=\left\{v_i^t\right\}_{i=1}^{N\times K+T}\cup\left\{v_i^m\right\}_{i=1}^N=\left\{v_i\right\}_{i=1}^{N\times\left(K+1\right)} V={vit}i=1N×K+T∪{vim}i=1N={vi}i=1N×(K+1) 且 E = { e i j } i , j = 1 , . . . , ∣ V ∣ E=\left\{e_{ij}\right\}_{i,\ j=1,...,\ |V|} E={eij}i, j=1,..., ∣V∣ 分别表示节点和边的集合。该节点包含两种类型的点,即任务相关节点 V t V^t Vt 和元知识节点 V m V^m Vm。边表示两个节点之间的相似度,初始化为:

其中 S ^ = S ∪ V m \hat{S}=S\cup V^m S^=S∪Vm 表示支持集和增强元知识的联合。因此,元知识被扩充到现有的推理任务中,并允许模型通过利用学习到的概念来适应新任务。
节点特征更新。给定来自层 ℓ − 1 \ell-1 ℓ−1 的 v i ℓ − 1 v_i^{\ell-1} viℓ−1 和 e i j ℓ − 1 \mathbf{e}_{ij}^{\ell-1} eijℓ−1,层 ℓ \ell ℓ 的特征节点 v i ℓ v_i^\ell viℓ 通过邻域聚合过程更新。该聚合由两个邻居之间的边缘相似性加权。还进行了特征变换以对特征进行归一化。在数学上,节点特征更新定义为:
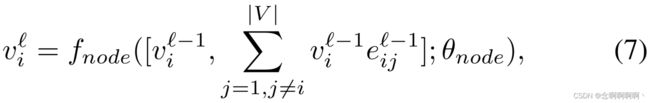
其中 [ ⋅ ; ⋅ ] [·; ·] [⋅;⋅] 是串联操作, f n o d e ( ⋅ ; θ n o d e ) f_{node}\left(\cdot;\ \theta_{node}\right) fnode(⋅; θnode) 是由两个卷积层组成的变换块 [Glorot et al, 2011; Ioffe and Szegedy, 2015],LeakyReLU 激活和 dropout 层。
边特征更新。边特征更新是根据新更新的节点特征 v i ℓ v_i^\ell viℓ 完成的。重新计算每对节点之间的相似度,结合前一条边的特征值 e i j ℓ e_{ij}^\ell eijℓ 和更新后的相似度,更新每条边 e i j ℓ − 1 \mathbf{e}_{ij}^{\ell-1} eijℓ−1 的特征为:
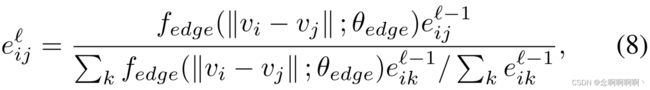
其中 f e d g e ( ⋅ ; θ e d g e ) f_{edge}\left(\cdot;\ \theta_{edge}\right) fedge(⋅; θedge) 是由 θ e d g e \theta_{edge} θedge 参数化的度量网络,它包括四个卷积块、一个批量归一化层、一个 LeakyReLu 激活层和一个 dropout 层。值得注意的是,我们的 GAM 可以与任何其他 GNN 一起实施,并显着提高它们的性能。
2.4. 预测与优化
当优化复杂时,节点 v i v_i vi 属于 C k C_k Ck 的预测概率可以表示为:
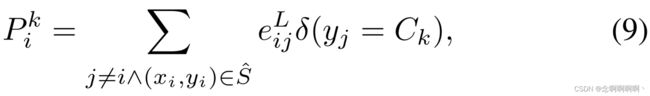
其中 δ ( y j = C k ) \delta\left(y_j=C_k\right) δ(yj=Ck) 是 Kronecker delta 函数,当 y j = C k y_j=C_k yj=Ck 时等于 1,否则为零, e i j e_{ij} eij 表示两个节点 v i v_i vi 和 v j v_j vj 之间的边特征。然后使用 softmax 层对该概率进行归一化。
在元训练阶段,我们的模型通过最小化二元交叉熵损失(BCE)来优化:

其中 e i e_i ei 和 y ^ i ℓ {\hat{y}}_i^\ell y^iℓ 分别是查询节点边缘标签和查询边缘预测的基本事实, λ ℓ \lambda_\ell λℓ 是第 ℓ \ell ℓ 层的系数。为了使元知识节点与预测标签一致,我们还引入了另一种二元交叉熵损失(BCE) L m \mathcal{L}_m Lm 来估计元知识节点边缘标签的真值和预测之间的差异。
最后,总损失 L \mathcal{L} L 可以定义为:
![]()
其中 α \alpha α 是平衡 L q \mathcal{L}_q Lq 和 L m \mathcal{L}_m Lm 的系数。在我们的实验中,我们固定 α = 0.2 \alpha=0.2 α=0.2 和 β = 0.01 \beta=0.01 β=0.01。
3. 实验
3.1. 实验设置
数据集。我们根据 [Yang et al, 2020] 之后的四个 few-shot 学习基准评估我们的方法:miniImageNet [Vinyals et al, 2016]、tieredImageNet [Ren et al, 2018]、CUB-200-2011 [Wah et al, 2011] 和 CIFAR-FS [Bertinetto et al, 2018]。其中,miniImageNet 和 tieredImageNet 是从 ImageNet 收集而来的,CIFAR-FS 是 CIFAR-100 的一个子集。与这些数据集不同,CUB-200-2011 是一个细粒度的鸟类分类数据集。
评估。为了进行评估,所有结果都是在标准的少镜头分类协议下获得的: 5 − w a y 1 − s h o t 5-way\ 1-shot 5−way 1−shot 和 5 − s h o t 5-shot 5−shot 任务。无论在 1 次还是 5 次拍摄设置中,每个类只使用 1 个查询样本来测试准确性。我们报告了 10K 个随机生成的事件的平均准确度(%)以及测试集上的 95% 间隔。请注意,所有超参数都是根据验证集确定的。
3.2. 实施细节
网络架构。我们利用两个网络作为我们的编码器主干(即 ConvNet 和 Resnet12 [Kim et al, 2019; Lee et al, 2019])。ConvNet 包含四个块,每个块包括一个 3x3 卷积层、一个批量归一化层和一个 LeakyReLU 激活层。同样,ResNet12 由四个残差块组成。全面了解请参考 [He et al, 2016]。在主干网络之后,有一个全局平均池化层和一个全连接层来产生 128 维的实例嵌入。
训练。在预训练阶段,通过最小化基类的标准交叉熵损失,以 128 的批大小从头开始训练之前工作 [Chen et al, 2020] 之后的基线。之后,我们每次迭代随机选择 40 集用于在元训练阶段训练 ConvNet。这种采样策略与 ResNet12 略有不同,其中 5 路 5 次任务,由于内存成本,我们每次迭代仅采样 20 集。Adam 优化器用于所有实验,初始学习率为 10−3 。我们每 8000 次迭代将学习率衰减 0.1,并将权重衰减设置为 10−5。我们总共训练了 50,000 个 epoch,编码器在前 25000 次迭代中被冻结。
3.3. 主要结果
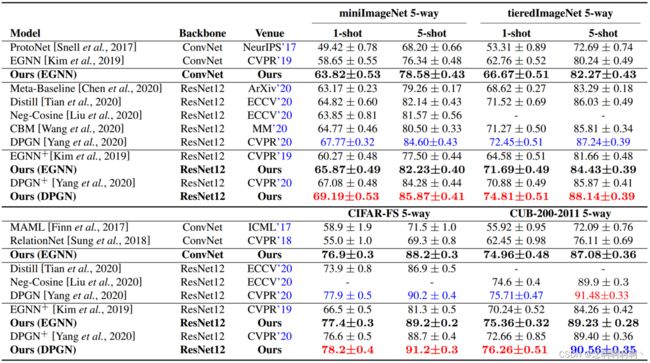
在本节中,我们展示了我们的方法相对于最先进方法的有效性。为了公平比较,我们采用两个具有代表性的少样本图神经网络,即 EGNN 和 DPGN 作为我们的 GAM 模块。此外,通过使用两种主干 ConvNet 和 ResNet12,我们报告了所有基准数据集在 5 − w a y 1 − s h o t 5-way\ 1-shot 5−way 1−shot 和 5 − w a y 1 − s h o t 5-way\ 1-shot 5−way 1−shot 设置下的结果,以进行综合评估。
通用对象识别的结果。对于通用对象分类,我们在 miniImageNet、tieredImageNet 和 CIFAR-FS 上评估了我们的方法,并在表 1 中报告了结果。主要观察结果如下:1)所提出的方法优于所有竞争对手,证明了我们方法的有效性。此外,由于更好的表示能力,使用 ResNet12 获得的性能优于使用 ConvNet 的性能。2)无论使用哪种图神经网络,所提出的方法都明显优于基线,并且有明显的优势。3)在 1 − s h o t 1-shot 1−shot 或 5 − s h o t 5-shot 5−shot 设置中,我们的方法在最佳性能上基本稳定。由于内存的净化,在 1 − s h o t 1-shot 1−shot 设置下改进更为显着。因此,当面对样本较少的新任务时,我们的方法似乎会更有效。
细粒度分类的结果。对于细粒度鸟类分类问题,表 1 报告了 CUB-200-2011 的结果。特别是,我们的方法也大大优于其他竞争对手。请注意,在此数据集上,不同的图神经网络和骨干网对性能的影响较小。
讨论。由于所提出的方法基于 GNNs 框架,我们的方法可以灵活地集成到任何高级 GNNs 方法中。我们的结果表明,使用纯化的内存和 GAM 模块,GNN 的性能将得到显着提升。
3.4. 消融研究
我们提供实验来证实我们的主要主张:1)净化记忆可以促进快速适应。2)元知识与 GAM 能够促进现有的 GNNs 模型。所有实验均在 tieredImageNet 上进行,采用 ResNet12 的 5 − w a y 1 − s h o t 5-way\ 1-shot 5−way 1−shot 设置。补充材料中还显示了 5 − s h o t 5-shot 5−shot 的定量结果。
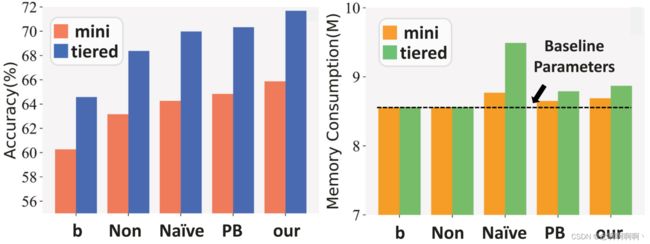
净化记忆的影响。我们比较了四个不同的记忆库,结果如图 2 所示。请注意,当没有内存时,基线退化为 EGNN。我们可以得出以下结论:1)在没有记忆的帮助下,GAM 可以提高 GNN 模型的性能,甚至可以与当前集中的类中心结合。2)三个不同的记忆库明显优于非记忆基线,显示元知识的重要性。3)基于原型的记忆更有效,这证实了我们的假设,即存储整个特征是一个次优的解决方案。4)实验结果支持我们为每个类别获得最佳原型表示的动机。同时,与基线相比,所提出方法的内存成本似乎保持在同一水平。
GAM 的影响。为了证明我们的图形增强模块的有效性,我们首先可视化图 3 中的嵌入空间。特别是,我们随机选择 5 个类,每个类包含来自 tieredImageNet 的 200 个样本。我们通过 t-SNE 将 EGNN 和配备 GAM 的 EGNN 训练的特征投影到二维平面中。结果表明,EGNN 中的嵌入空间是混合的,因此学习模型的判别能力自然受到限制。相反,我们的模型能够区分具有较大类间边缘的不同类别,因此我们得到了实质性的改进。这表明在纯化的元知识的帮助下,可以通过 GAM 进一步突出区分信息。
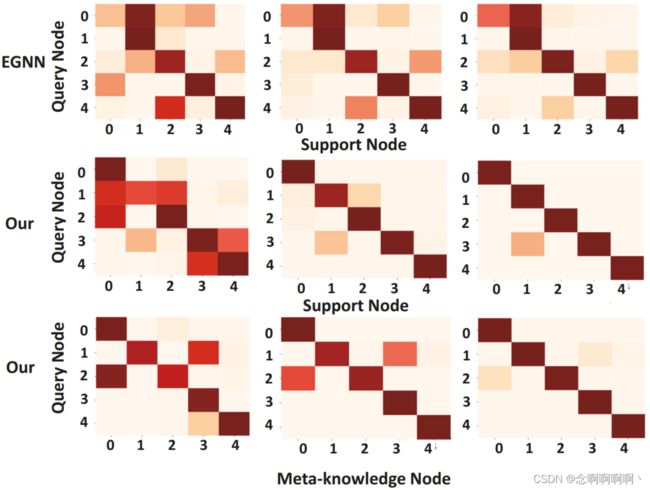
此外,为了可视化元知识如何帮助预测过程,我们选择了一个测试场景,其中五个查询图像的地面真实类别不重叠(即, 5 − w a y 1 − s h o t 5-way\ 1-shot 5−way 1−shot)并可视化实例级相似性,如图所示 在图 5 中。具体来说,我们选择两种实例级相似性来证明我们的方法的有效性。值得注意的是,热图显示 GAM 在几层之后改进了实例级相似度矩阵,并与 EGNN 相比对最后一层中的五个查询样本做出了正确的预测。我们还可以发现这种改进是由于元知识节点的增加。由于纯化的概念,热图本质上是干净的,因此元知识提供了辅助的强监督。然后,这些相似性通过图神经网络进一步传播,使模型能够利用记忆的概念和从新任务中学到的知识。这个实验结果令人信服地支持了我们的假设。
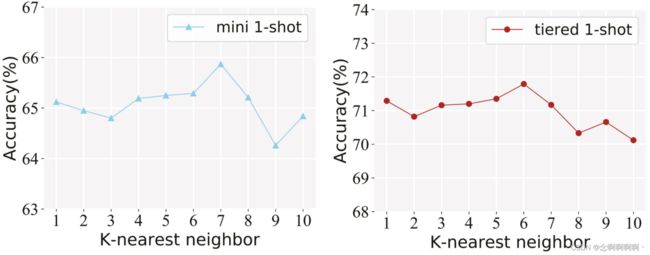
k-最近邻的影响。在元知识挖掘阶段,我们从内存中检索最相似的 k k k 个样本来扩充图。在这里,我们讨论当 k k k 变化时它的影响。如图 4 所示,当 k k k 增加时,few-shot 识别性能不断提高,当 k k k 增加到一定值时,准确率在两个数据集上都开始下降。因此,建议根据经验将此值设置为 6。

4. 结论
在这项工作中,我们提出了一种新的小样本学习记忆更新方案,从信息论的角度逐步净化语义标签信息。Purified memory 通常具有表现力、一致性、高效性,然后自然地与图增强模块配合使用。GAM 进一步利用元知识和从新任务中学到的知识来进行精确预测。该方案是一个与模型无关的模块,可以灵活地集成到任何高级 GNN 方法中。
参考文献
[Bertinetto et al, 2016] Luca Bertinetto, Jack Valmadre, Joao F Henriques, Andrea Vedaldi, and Philip HS Torr. Fully-convolutional siamese networks for object tracking. In European conference on computer vision, pages 850– 865. Springer, 2016.
[Bertinetto et al, 2018] Luca Bertinetto, Joao F Henriques, Philip HS Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers. arXiv preprint arXiv:1805.08136, 2018.
[Chen et al, 2020] Yinbo Chen, Xiaolong Wang, Zhuang Liu, Huijuan Xu, and Trevor Darrell. A new meta-baseline for few-shot learning. arXiv preprint arXiv:2003.04390, 2020.
[Finn et al, 2017] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1126– 1135. JMLR. org, 2017.
[Garcia and Bruna, 2017] Victor Garcia and Joan Bruna. Few-shot learning with graph neural networks. arXiv preprint arXiv:1711.04043, 2017.
[Glorot et al, 2011] Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 315–323, 2011.
[He et al, 2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[Ioffe and Szegedy, 2015] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
[Kim et al, 2019] Jongmin Kim, Taesup Kim, Sungwoong Kim, and Chang D Yoo. Edge-labeling graph neural network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11–20, 2019.
[Lee et al, 2019] Kwonjoon Lee, Subhransu Maji, Avinash Ravichandran, and Stefano Soatto. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10657–10665, 2019.
[Liu et al, 2018] Yanbin Liu, Juho Lee, Minseop Park, Saehoon Kim, Eunho Yang, Sung Ju Hwang, and Yi Yang. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv preprint arXiv:1805.10002, 2018.
[Liu et al, 2020] Bin Liu, Yue Cao, Yutong Lin, Qi Li, Zheng Zhang, Mingsheng Long, and Han Hu. Negative margin matters: Understanding margin in few-shot classification. arXiv preprint arXiv:2003.12060, 2020.
[Long et al, 2015] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431– 3440, 2015.
[Noh et al, 2017] Hyeonwoo Noh, Andre Araujo, Jack Sim, Tobias Weyand, and Bohyung Han. Large-scale image retrieval with attentive deep local features. In Proceedings of the IEEE international conference on computer vision, pages 3456–3465, 2017.
[Ramalho and Garnelo, 2019] Tiago Ramalho and Marta Garnelo. Adaptive posterior learning: few-shot learning with a surprise-based memory module. arXiv preprint arXiv:1902.02527, 2019.
[Ren et al, 2018] Mengye Ren, Eleni Triantafillou, Sachin Ravi, Jake Snell, Kevin Swersky, Joshua B Tenenbaum, Hugo Larochelle, and Richard S Zemel. Meta-learning for semi-supervised few-shot classification. arXiv preprint arXiv:1803.00676, 2018.
[Snell et al, 2017] Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. In Advances in neural information processing systems, pages 4077–4087, 2017.
[Sung et al, 2018] Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip HS Torr, and Timothy M Hospedales. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1199–1208, 2018.
[Tian et al, 2020] Yonglong Tian, Yue Wang, Dilip Krishnan, Joshua B Tenenbaum, and Phillip Isola. Rethinking few-shot image classification: a good embedding is all you need? arXiv preprint arXiv:2003.11539, 2020.
[Tishby and Zaslavsky, 2015] Naftali Tishby and Noga Zaslavsky. Deep learning and the information bottleneck principle. In 2015 IEEE Information Theory Workshop (ITW), pages 1–5. IEEE, 2015.
[Vinyals et al, 2016] Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al Matching networks for one shot learning. In Advances in neural information processing systems, pages 3630–3638, 2016.
[Wah et al, 2011] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The Caltech-UCSD Birds-200-2011 Dataset. Technical report, 2011.
[Wang et al, 2020] Zeyuan Wang, Yifan Zhao, Jia Li, and Yonghong Tian. Cooperative bi-path metric for few-shot learning. In Proceedings of the 28th ACM International Conference on Multimedia, pages 1524–1532, 2020.
[Yang et al, 2020] Ling Yang, Liangliang Li, Zilun Zhang, Xinyu Zhou, Erjin Zhou, and Yu Liu. Dpgn: Distribution propagation graph network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13390–13399, 2020.