技术解读:实时数仓Hologres如何支持超大规模部署与运维
简介:在本次评测中,Hologres是目前通过中国信通院大数据产品分布式分析型数据库大规模性能评测的规模最大的MPP数据仓库产品。通过该评测,证明了阿里云实时数仓Hologres能够作为数据仓库和大数据平台的基础设施,可以满足用户建设大规模数据仓库和数据平台的需求,具备支撑关键行业核心业务数据平台的能力。

作者 | 欧文
来源 | 阿里技术公众号
2021年11月23日至12月3日,中国信息通信研究院(以下简称“中国信通院”)对第13批分布式分析型数据库共计27款产品进行了大数据产品能力评测。阿里云实时数仓Hologres(原阿里云交互式分析)在报表任务、交互式查询、压力测试、稳定性等方面通过了中国信通院分布式分析型数据库性能评测(大规模),并以8192个节点刷新了通过该评测现有参评的规模记录。
在本次评测中,Hologres是目前通过中国信通院大数据产品分布式分析型数据库大规模性能评测的规模最大的MPP数据仓库产品。通过该评测,证明了阿里云实时数仓Hologres能够作为数据仓库和大数据平台的基础设施,可以满足用户建设大规模数据仓库和数据平台的需求,具备支撑关键行业核心业务数据平台的能力。
在Hologres实例的云原生调度和运维体系建设上,团队也联合阿里云云原生等团队,解决了在超大规模集群;在运维能力建设上,团队通过自动化、智能化的运维体系建设,解决了实例部署和稳定性保障的问题。
一 超大规模部署面临的挑战
随着互联网的发展,数据量出现了指数型的增长,单机的数据库已经不能满足业务的需求。特别是在分析领域,一个查询就可能需要处理很大一部分甚至全量数据,海量数据带来的压力变得尤为迫切。同时,随着企业数字化转型进程的加速,数据的时效性变得越来越重要,如何利用数据更好的赋能业务成为企业数字化转型的关键。
大数据实时数仓场景相比数据库的规模往往是成倍增加:数据量增加(TB级、PB级甚至是EB级)、数据处理的复杂度更高、性能要更快、服务和分析要同时满足等等。
而使用过开源OLAP系统的用户,尤其是通过开源OLAP自建集群的用户,都有一些比较深刻的体会,就是部署和运维困难,包括ClickHouse、Druid等,都面临了如下难题:
- 如何满足集群的快速交付和弹性伸缩
- 如何定义服务的可用性指标和SLA体系
- 存储计算一体,机型选择和容量规划困难
- 监控能力弱,故障恢复慢,自愈能力缺失
同时,随着规模的增加,规模优势和高性能吞吐下的压力,实时数仓的部署和运维难度呈指数级增加,系统面临了诸多调度、部署和运维上的各种挑战:
- 如何解决调度能力满足在单集群万台规模下服务实例的秒级拉起和弹性伸缩能力的要求;
- 如何解决大规模集群自身的容量规划、稳定性保障、机器自愈,提升相关的运维效率;
- 如何实现实例和集群的监控时效和准确性的双重要求,包括怎么在分钟内完成问题发现和分钟级的问题解决
得益于阿里云强大的云原生基础服务研发能力,实时数仓Hologres通过优秀的架构设计和阿里云大数据智能运维中台的能力等多个核心能力的建设,解决这些挑战,为用户提供了一个性能强大、扩展能力优秀、高可靠、免运维的实时数仓产品。
本文将会从超大规模部署与运维体系建设出发,分析超大规模实时数仓面临的挑战和针对性的设计及解决方案,实现在高负载高吞吐的同时支持高性能,并做到生产级别的高可用。
二 基于云原生的大规模调度架构设计
随着云技术的兴起,原来越多的系统刚开始利用Kubernetes作为容器应用集群化管理系统,为容器化应用提供了自动化的资源调度,容器部署,动态扩容、滚动升级、负载均衡,服务发现等功能。
Hologres在设计架构之初就提前做了优化,采用云原生容器化部署的方式,基于Kubernetes作为资源调度系统,满足了实时数仓场景上的超大规模节点和调度能力。Hologres依赖的云原生集群可以支持超过1万台服务器,单实例可以达到8192个节点甚至更大的规模。
1 Kubernetes万台调度
Kubernetes官方公布集群最大规模为5000台,而在阿里云场景下,为了满足业务规模需求、资源利用率提升等要求,云原生集群规模要达万台。众所周知Kubernetes是中心节点式服务,强依赖ETCD与kube-apiserver,该块是性能瓶颈的所在,突破万台规模需要对相关组件做深度优化。同时要解决单点Failover速度问题,提升云原生集群的可用率。
通过压测,模拟在万台node和百万pod下的压力,发现了比较严重的响应延迟问题,包括:
- etcd大量的读写延迟,并且产生了拒绝服务的情形,同时因其空间的限制也无法承载 Kubernetes 存储大量的对象;
- API Server 查询延迟非常高,并发查询请求可能导致后端 etcd oom;
- Controller 处理延时高,异常恢复时间久,当发生异常重启时,服务的恢复时间需要几分钟;
- Scheduler 延迟高、吞吐低,无法适应业务日常运维的需求,更无法支持大促态的极端场景
为了突破k8s集群规模的瓶颈,相关团队做了详细调研,找到了造成处理瓶颈的原因:
- 发现性能瓶颈在kubelet,每10s上报一次自身全量信息作为心跳同步给k8s,该数据量小则几KB大则10KB+,当节点到达5000时,会对kube-apiserver和ETCD造成写压力。
- etcd 推荐的存储能力只有2G,而万台规模下k8s集群的对象存储要求远远超过这个要求,同时要求性能不能下降;
- 用于支持集群高可用能力的多API Server部署中,会出现负载不均衡的情况,影响整体吞吐能力;
- 原生的scheduler 性能较差,能力弱,无法满足针对混部、大促等场景下的能力。
针对该情况,做了如下优化,从而达到万台规模调度:
- etcd设计新的内存空闲页管理算法,大幅优化etcd性能;
- 通过落地 Kubernetes 轻量级心跳、改进 HA 集群下多个 API Server 节点的负载均衡,解决了APIServer的性能瓶颈;
- 通过热备的方式大幅缩短了 controller/scheduler 在主备切换时的服务中断时间,提高了整个集群的可用性;
- 通过支持等价类处理以及随机松弛算法的引入,提升了Scheduler的调度性能
三 Hologres运维体系建设
1 Hologres运维体系总览
针对OLAP体系碰到的问题和痛点,以及在超大规模部署压力下的运维挑战,同时依托阿里云大数据运维中台,我们设计了Hologres的运维体系,解决资源和集群交付等自动化问题、集群和实例级别的实时可观测性问题和智能化的自愈体系,提升Hologres的SLA到生产可用级别。

2 集群自动化交付
Hologres 是完全基于云原生的方式设计和实现的,通过存储计算分离的方式,解耦了计算资源和存储资源;其中计算节点的部署通过K8s集群进行部署和拉起。通过自研的运维管理系统ABM,在集群交付上,我们对集群进行抽象设计,分离出资源集群和业务集群的概念;资源集群的交付,ABM和底层平台进行打通,进行资源集群的创建和容量维持;在业务集群上,ABM提供基于K8s 概念的部署模板,将管控等节点在资源集群上快速拉起,完成交付。
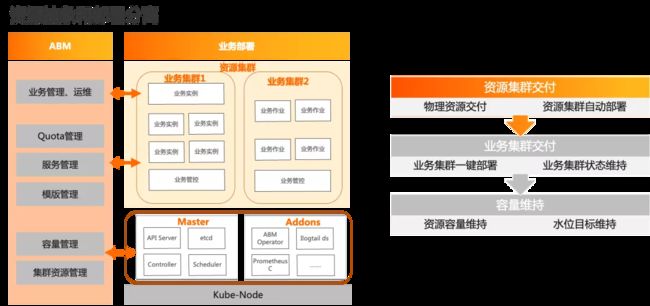
3 可观测性体系
系统的可观测性能帮助业务更好的管理集群水位和问题排查等,从而提升企业级管控能力。在可观测性上,不仅需要透出更加简单易懂的监控指标,还需要有成熟的日志采集系统,从而实现更简单的运维,只需要为业务问题负责。基于阿里云的监控产品和Hologres的可观测性需求,我们设计了Hologres的实时监控能力。

Metric监控体系
为了支持详细的系统能力观察、性能监控、快速的问题定位和debug,Hologres 支持了非常丰富的Metric监控体系,这也对整个Metric链路的采集、存储和查询提出了非常高的要求。在监控链路上,Hologres 选择了阿里巴巴自研的Emon平台,除了支持亿级Metric每秒的写入,Emon还支持自动downsample、聚合优化等能力;同时在后端我们通过实时链路,可以把核心Metric吐到云监控,方便用户自助的对实例进行监控观察和问题定位。
日志采集和监控
在日志采集上,Hologres采用了成熟的云产品SLS,可以支持中心式的日志排查和过滤 ;同时考虑到Hologres的日志量也非常庞大,在采集上采用了分模块和分级的机制,在控制成本的同时,能很好的解决问题排查和审计的需要。同时,SLS也提供了基于关键字等方式的监控方案,可以对关键错误进行告警,以方便及时处理问题。
基于元仓的可用性监控
在Metric和日志的采集及告警上,更多的是体现某一个模块上的问题,上面的手段还无法完整的回答某一个实例的可用性。基于此,我们构建了一个Hologres运维数仓,通过多维度的事件、状态进行综合判断实例是否工作正常。
在元仓中会收集和维护多维度数据,包括实例的meta数据、Hologres中各模块的可用性判断标准、实例各模块的状态、事件中心,包括运维事件、客户事件、系统事件等;在进行实例可用性判断的同时,元仓还提供了用于实例诊断、实例巡检等各种数据。当前元仓的能力已经产品化发布为慢Query日志,用户可以通过慢query日志,进行自助化问题诊断和调优。
4 智能运维提升产品SLA
在可观测性完善的基础上,为了提升问题定位的速度和缩短实例恢复时间,即提升Hologres的MTTR,基于阿里云大数据运维中台提供的基础能力和智能运维方案,我们构建了完整的Hologres SLA管理体系和故障诊断及自愈体系。
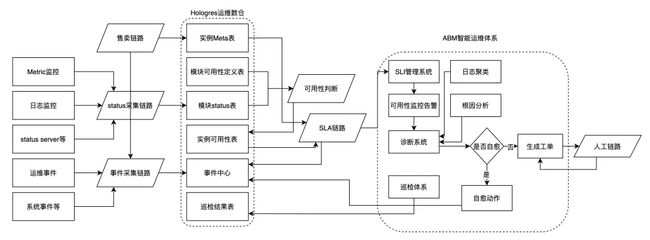
SLA体系
基于Hologres运维元仓的数据和实例可用性定义,我们建立了Hologres实例级别可用性的管理系统,实例可用性数据会进入ABM的SLI数据库,SLI根据数据和条件触发实例可用性监控,在监控发出的同时,会触发实例的诊断,系统根据诊断结果,判断是否进行自愈,如果是已知可以自动恢复情况,会触发自愈,进行故障的自动恢复;如果是未知情况,会触发生成人工工单,工单系统会由人跟进完成,并逐步形成自愈的action。
智能巡检
智能巡检解决的是集群或者实例的一些隐性和不紧急的问题,避免一些小问题的日积月累引发质变影响线上的稳定性;除了一些比较清晰定义的巡检项,智能巡检还引入了聚类算法等,对系统指标进行分析,这也会帮助我们发现一些集群中的离散节点,进行及时处理,避免问题节点导致影响整个实例的可用性。
智能诊断和自愈
智能诊断既依赖运维元仓的数据,同时还会依赖诊断相关的算法支持,包括日志聚类、根因分析等,进行错误日志的聚类,对聚类结果进行打标。在ABM提供的算法和工程能力支持下,实例诊断已经在帮助业务进行问题的快速定位,提升问题解决的效率,缩短了实例的MTTR。
四 Hologres产品级运维能力
除了上面介绍的Hologres服务本身的运维稳定性保障。在Hologres 产品侧,通过多种方式提升系统的稳定性:
1、高可用架构
采用高可用架构设计,稳定支撑阿里集团历年双11等大促流量峰值,经历大规模生产考验,包括
- 存储计算分离架构提升系统扩展灵活性
- 多形态replication解决数据读写分离,主要包括多副本提高吞吐、单实例资源组隔离、多实例共享存储高可用
- 调度系统提升节点failover快速恢复能力
2、多元化的系统可观性指标
除了Hologres本身架构的设计,同时也为用户提供多元化的观测指标,实时监控集群状态和事后复盘,无需复杂操作,只需为业务负责:
- 多维度监控指标:CPU、内存、连接数、IO等监控指标实时查询,实时预警;
- 慢query日志:发生的慢Query或失败Query通过时间、plan、cpu消耗等各项指标进行诊断、分析和采取优化措施,提高自助诊断能力;
- 执行计划可视化:通过多种可视化展现的方式,对Query进行运行分析、执行分析,详细算子解读,并进行优化建议引导,避免盲目调优,降低性能调优门槛,快速达到性能调优的目的。
五 总结
通过对大规模调度下面临的调度性能瓶颈的分析和针对性的优化,Hologres 可以完成8192节点甚至更大规模的实例交付和扩缩容。同时基于云原生的Hologres智能运维体系建设,解决了大规模集群和实例下面临的运维效率和稳定性提升问题,使得Hologres在阿里巴巴内部核心场景历经多年双11生产考验,在高负载高吞吐的同时实现高性能,实现生产级别的高可用,更好的支撑业务,为企业的数字化转型提供了良好的支持。
原文链接
本文为阿里云原创内容,未经允许不得转载。