流式计算系统
流式计算系统系列:总纲
流式计算系统方兴未艾。为了反映现实世界事件驱动的特性,为了对接消息队列事件驱动的设计,为了获得更好的时延,越来越多的业务采用流式计算系统来处理它们的数据。在批流统一的理论指导下,可想而知,未来的计算是属于流式计算的天下。
从 2018 年年中参与 Flink 社区的开发,到在阿里巴巴 BLINK 团队和鹅厂数据中心的 FLINK 团队基于 Flink 支持了诸多流式计算作业的运行,这段时间的经历使我深深地体会到了自己作为本领域新人的局限性。虽然在我优秀的导师施晓罡博士的指导和帮助下,偶然的成为 Flink Committer,但是为了填平技术上的泡沫,还是必须多做思考和学习。
近日拿到了若干本流式计算系统相关的经典书籍,结合 Apache Flink 及相关项目的源码开始锻炼自己在本领域更深层次的理解和运用。在此过程中偶有所得,一并记录为《流式计算系统系列》系列文章。小作分享,以飨读者。
流式计算系统系列(1):恰好一次处理
什么是恰好一次处理
恰好一次处理(exactly-once)简而言之就是保证数据记录(record)在整个计算过程中恰好被处理一次。显然,每条数据恰好处理一次是整个计算结果正确性的必要条件。
由于分布式系统天然的不可靠性,数据是否发送成功是不可知的(false-negative 是可能的)。因此,几乎总是需要某种程度的重试和去重逻辑。我们在流式计算系统中所说的恰好一次处理强调的是从结果来看,数据恰好被处理一次,或者说结果是数据恰好被处理一次时产生的结果。
为了支持恰好一次处理,需要实现网络传输层面的容错和作业层面的容错。网络传输层面,在 Flink 的实现中,Task 上下游之间通过 TCP 传输,我们可以认为在 TCP 层面解决了消息重发和消息去重的问题;对于其他不使用 TCP 传输的实现,也需要在应用层面实现类似的重发和去重逻辑,方法和 TCP 采用的方法类似。作业层面的容错则是本文的核心内容。
对于批处理系统,例如 Spark,恰好一次处理并不是一个复杂的问题。由于数据是有限的,上游总有一天会终止。如果下游失败,只需要重新启动一个实例并从上游重新拉取数据消费即可。而对于流处理系统,例如 Flink,数据理论上是无限的,上游无法无限地缓存中间结果,因此需要其他方案来实现恰好一次的处理。
Flink 基于算子上的 state 和 checkpoint 机制实现了流处理系统上的恰好一次处理,下面我们介绍其实现方式。
checkpoint 与 state
我们先简单介绍一下 checkpoint 和 state 的含义。
state 指的是与算子绑定的持久化状态。Flink 的作业表示为一个有向无环图,图上的节点即各个不同功能的算子,例如 Map 算子,Reduce 算子,Source 算子和 Sink 算子等等。应用层的算子可以通过实现 CheckpointedFunction 接口,获取 Flink 框架层面支持的状态读写。典型的 state 例如处理函数调用次数的计数器,Window 算子当前窗口的中间状态和 Source 算子当前读取数据源的 offset 等等。
checkpoint 指的是 Flink 对所有算子的 state 做分布式快照的动作。checkpoint 成功时将产生一个序号全局单调递增的分布式快照,这个快照是所有算子的 state 的一致性记录。Flink 采用的分布式快照算法是Chandy-Lamport算法的一个变体,我们会在后面介绍 Flink 产生分布式快照的细节。
state 与 exactly-once
我们先认为通过 checkpoint 机制能够产生最新版本的全局一致的 state 的分布式快照,基于这个知识我们来介绍 state 是如何支持 Flink 实现恰好一次处理的。
回顾前文,我们定义的恰好一次处理,指的是数据记录在整个计算过程中恰好被处理一次。由于分布式系统天然的不可知性,我们实际上说的是从结果来看,产生的结果是数据记录恰好被处理一次的结果。state 就是数据记录被处理之后产生的结果,因此 state 都应该是数据记录恰好被处理一次的结果。由于 Flink 的传输基于 TCP,在作业没有发生错误的情况下,这一点我们可以认为是成立的。在作业发生错误的情况下,一个典型的流处理作业会进行全图重启,从上一个 checkpoint 开始重新计算,Flink 是怎么保证这样的计算从结果来看是恰好一次处理的呢?
首先,我们需要让 Source 算子从上一个 checkpoint 记录的位置开始重新发送数据,这就要求数据源是可重播的。如果数据源是不可重播的,例如无缓存的实时 socket,在容错场景下,我们无法再次取得先前的数据,恰好一次处理是无法支持的。前面举例说明 state 的应用的时候提到了 Source 算计当前读取数据源的 offset 就是可重播数据源支持恰好一次处理的一种方式。例如数据源是 Kafka,我们在 checkpoint 的时候将当前读取到的 Kafka partition offset 作为 Source 算子的 state 高可靠的持久化,在容错场景下,Source 算子即可恢复出上次读取的 offset,从正确的位置开始产生输出。
对于其他算子,它们的输入来自于上游。现在 Source 节点产生的输出是正确不重复的,下游算子先前持久化的 state 也已经被成功加载,只需要再次消费上游发送的数据,即可保证 state 是数据恰好被处理一次的结果。再下游的算子以此类推,就能够推出所有算子的 state 都将是数据恰好被处理一次的结果。
另外值得强调的是 Sink 算子,Sink 算子在写出到外部存储时,要实现用户层面上的恰好一次处理,也需要通过实现 CheckpointedFunction 接口来配合。目前 Flink 原生地支持 Kafka 和 HDFS 作为 Sink 的恰好一次写出,需要扩展时推荐实现自己的 TwoPhaseCommitSinkFunction 来达到目的。Sink 算子的特别之处在于它的处理跨越了 Flink 框架和外部存储的边界,因此为了实现用户层面的恰好一次处理,需要和外部存储互相配合。
这里提一下恰好处理一次的两个需要注意的点。如果数据处理函数有副作用,或者输出是非确定性的,实际容错效果可能与直觉上的恰好一次处理会有出入。
前一个问题的例子,例如在数据处理函数中打印数据,或者更改外部世界的状态,由于这样的副作用不像上面提到的 Sink 算子的跨越边界的一致性处理时那样被管理起来,当 Flink 框架进行容错的时候,是有可能多次执行副作用的,从用户角度来看,就是数据不止被处理了一次。这是无法避免的。
后一个问题的例子,例如在数据处理函数中获取随机数用于计算,容错前后的随机数取值很可能是不同的,从理论上说这不算是数据真的从头到尾仅处理一次的结果。另一个不太直观的例子是,数据处理函数中获取配置中心当前时刻的配置,容错前后配置可能被其他程序更改,这样两次取值可能是不同的。对于非确定性的输出,用户可能在用户透明的容错场景下观察到输出发生非预期的抖动。
checkpoint 与 exactly-once
本节将展开介绍上一节中作为先验知识的 checkpoint 机制,介绍 Flink 的 checkpoint 机制如何产生最新版本的全局一致的 state 的分布式快照。
checkpoint 的完整过程由 JobManager 上的 CheckpointCoordinator 组件,TaskManager 上的 Task 和高可靠的(分布式)存储系统协同完成。
假设现在要产生一个新的 checkpoint,这一过程首先由 CheckpointCoordinator 上的周期性作业触发,触发时获取所有 Source 算子对应的 Execution,并分别向对应的 Task 所在的 TaskManager 发起 triggerCheckpoint 调用。TaskManager 收到调用请求后,会触发对应的 Task(必定是 Source Task)的 triggerCheckpoint 方法,向 Mailbox 插入一条 triggerCheckpoint 的消息,随后在消息被处理时先向下游传播 CheckpointBarrier,然后触发本地 state 的快照,根据配置的不同,快照可能存储在内存中,HDFS 上,或 RocksDB 上(再存储到 HDFS 上以保证高可靠)。在快照成功生成之后,向 CheckpointCoordinator 汇报快照完成。
这一部分关键源码位置
CheckpointCoordinator#triggerCheckpoint→Execution#triggerCheckpointTaskExecutor#triggerCheckpoint→TaskExecutor#triggerCheckpointBarrier→SourceStreamTask#triggerCheckpointAsync→StreamTask#performCheckpoint
对于其他算子,它们会陆续收到上游发送的 CheckpointBarrier,如果仅有一个上游,在收到 CheckpointBarrier 之后就开始触发下发 CheckpointBarrier 和快照相关的逻辑;如果有多个上游,则在对齐所有上游的 CheckpointBarrier 之后才开始触发,在对齐之前的其他输入将被缓存(恰好一次语义,在至少一次语义下不会缓存,会继续处理,因此 state 可能是数据被处理多次的结果)。同样的,在快照成功生成之后,向 CheckpointCoordinator 汇报快照完成。
这个对齐的过程可参考社区文档中的图片。

这一部分关键源码位置
CheckpointBarrierAligner#processBarrier→CheckpointBarrierHandler#notifyCheckpoint→StreamTask#triggerCheckpointOnBarrier→StreamTask#performCheckpoint
继续上面的过程,我们提到快照生成成功后,Task 会向 CheckpointCoordinator 汇报,汇报内容核心是 state 做快照时存储在高可靠的(分布式)存储系统上的位置信息。CheckpointCoordinator 收集到所有 state 的汇报后,将上述位置信息等元数据信息打包为 CompletedCheckpoint 数据结构,一致地存储到外部存储系统中(具体到 Flink 的当前实现,是存到 HDFS 上,然后把 HDFS 的句柄存到 ZK 上),随后便可宣告 Checkpoint 完成。这样我们就完成了一次分布式快照。
这个汇报和提交的过程可参考社区文档中的图片。

这一部分关键源码位置
StreamTask.AsyncCheckpointRunnable#reportCompletedSnapshotStates→TaskStateManager#reportTaskStateSnapshotsCheckpointCoordinator#receiveAcknowledgeMessageCheckpointCoordinator#completePendingCheckpoint
其他流式计算系统的实现方案
《流式系统(Streaming Systems)》一书中提及 Google Dataflow 早期的实现方案主要着重于上下游之间数据记录(record)的重发。Google Dataflow 早期并不支持状态化的处理,因此仅考虑了单个中间算子失败的情况下向上游算子重新拉取输入的情况。具体的实现细节与 TCP 类似,把数据记录编码,并将相关的元数据存储到分布式键值存储系统中。上游会反复重试发送信息,下游会比对分布式键值存储系统中的记录,对已经接受过的信息去重。当多个算子级联失败时,递归地等待上游推送新的数据。书中并未提及 Source 算子失败时如何处理,现有公开资料也无从得知支持状态化计算后如何处理状态的存储,猜想好的实现方式应该与 Flink 类似。Google Dataflow 的采用者甚少,在此列出作为前文略过的网络层面的容错机制的补充。
Spark Streaming 的容错方案与其所基于的批处理系统 Spark 息息相关,基本是微批的产生数据集并与本文第一节提及的微批完全重试结合。这一点的实现有赖于批处理系统久经考验的正确地 shuffle 中间结果的方案。Spark Streaming 也有 checkpoint,但这更多的是作为一种优化,避免开销巨大的计算重新计算。
Flink 在批流统一的方向上也借鉴了 Spark Streaming 的思路,即需要把中间结果存储起来,以支持上游终止的情况下仍然能够正确的拉取数据。另一方面,这也是一个本地恢复优化的入手点。当然,作为这一优化的权衡(trade-off),将中间结果落盘将导致不可避免的(显著的)额外开销。结合具体业务场景特点选择相应的模式和配置是业务开发人员需要注意的。
流式计算系统系列(2):时间
《Streaming 102》将流式计算的主要问题总结成 What/Where/When/How 四个方面,What 讲的是数据流经流水线时应用各种转换(transformation)的进行的计算,流式计算特有的概念主要是后面三个,这三个概念相互关联,而其中关系到计算触发的逻辑与时间的判断和处理息息相关。
不同于批式计算处理有限的数据(至少每一批是有限的),流式计算天然地面对无界的数据集。如果只是简单的对每一条数据进行 map/flatmap/filter 操作的话,我们对于海量数据总体(聚合)所体现出来的信息挖掘就相当的不充分了。在现实生活中,我们很可能不止需要对数据进行简单的转换或者筛选——这些都是比较接近预处理的工作——真正产生价值的是诸如【每隔一个小时的成交量/访问量】【大促期间每隔五分钟输出最近一个小时成交额最高的商品】或者【实时显示用户的访问历史】这样的计算,而这些计算都与时间相关。只有把时间人为的划分成一块一块的时间片,我们才能在无限的数据集中取出有限的子集来聚合产生有价值的结果。
完整地介绍整个产生价值的过程牵涉到基于时间或记录的触发计算阶段(trigger)(when),聚合计算的不同类型(window)(where)和多个聚合结果的再聚合(accumulation)(how)。我能力有限,对这三个内容展开主题讲述还是颇为费劲,退而求其次先拆分成各个部分介绍,在行文过程中整理自己思路以后或许可以有一次 recap 来做主题介绍。
本文介绍流式计算系统当中的时间概念,同样在过程当中可能会引用 FLINK 作为实际的流式计算系统例子来说明。
流式计算中的时间分类
时间可以说是分布式系统当中最神奇的属性。时间不会倒退,只会前进,但是不同机器上的时钟却很可能是不同步的。另外,由于网络延时和处理延时,甚至数据被主动存储并延后处理,事件产生的时间往往和它被处理的时间是不一致的,甚至有可能有巨大的差别。在流式计算系统当中有两种典型的时间,一种是事件产生的时间(event time),另一种是事件被处理的时间(processing time),它们的区别简单来说如下所示。
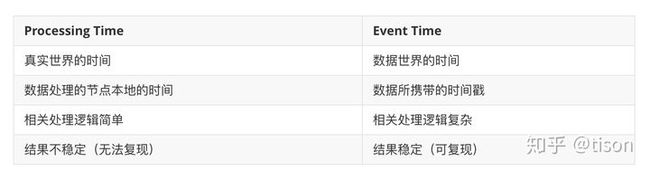
展开来说,Processing Time 表示的是数据被处理的时间,即真实世界当中发生数据被处理的时刻;Event Time 是数据产生时所带有的有信息价值的时间。回忆本系列前一章的内容,在容错场景下,由于 Event Time 是关联到数据记录的,也即是可重放的,因此基于 Event Time 的数据处理结果是可复现的;与之相对的,Processing Time 与实际处理的时间有关,在容错场景下并不能保证容错前后的结果一致(回忆前一章提到的非确定性的输出)。
可想而知,对于基于时间的数据处理逻辑,Event Time 几乎是必需的选项。Processing Time 的用处通常用于流式计算系统自身的指标监控以及系统告警,或者作为周期性的触发时间无关的数据窗口计算的触发器。
另外,在 FLINK 以及其他一些系统当中还会有一种 Ingestion Time 的概念,它指的是数据进入流式计算系统的时间。也就是说,数据的时间戳信息等于它进入流式计算系统的时刻。这样的时间能够避免使用 Processing Time 时由于不同计算节点之间的数据传输延迟等等的原因带来的更大幅度的结果抖动。但是它并不一定是准确的 Event Time,如果事件在产生之后立即进入流式计算系统被处理,而且这部分延迟先验地知道可以忍受,就可以使用 Ingestion Time 来处理数据,如果数据源本身没有 Event Time 的消息,或者进入流式计算系统的时间就是逻辑上的的 Event Time,那么这个时候 Ingestion Time 与 Event Time 就是等价的。
Watermark
Watermark 定义
在我们开篇就提到的例子里有一个是【每隔一个小时的访问量】,关于这个例子与窗口相关的语义我们暂且不提,在 Processing Time 的场景下,我们可以根据节点本地的时间使用 Timer 每隔一个小时定期触发一次计算。可是在 Event Time 的场景下,上游数据并不一定是有序产生的,传输过程也未必处处都保证有序,因此我们并不能保证到来的数据其 Event Time 属性必定是递增的。即使我们通过数据携带的 Event Time 得知当前数据的时间戳距离上次触发的窗口的时间戳达到一定时间,我们也无法确定后面就再也没有更早的数据了。
那么,在 Event Time 的场景下,我们要怎么知道【一个小时内的数据均已到达】这件事情呢?
现有的流式计算系统基本都支持一种称为 Watermark 的机制来解决这个问题。Watermark 是一种标识输入完整性的标记,携带一个时间戳,当节点收到 Watermark 时,即可认为早于该时间戳的数据均已到达,从而得到某个时间区间内的数据均已到达的结论。这里我们对 Watermark 能够标识数据完整性做一点讨论。
实际上,Watermark 本身是一种先验知识,也就是说是脱离于流式计算系统本身的,外部的,能够判断数据完整性的标识。从定义上说它就被定义成这样的标识,而不依靠流式计算系统本身来实现。对于 FLINK 这样一个具体实现来说,如果是作业本身定义的 Watermark 产生逻辑,只要它是可靠的,由于 FLINK 底层使用 TCP 传输,那么这个顺序就不会被打破。从概念上说,Watermark 可以按 Perfect Watermark 和 Heuristic Watermark 区分开来。其中前者指的是 Watermark 准确地标识了数据的完整性,后者则是说 Watermark 作为一种启发式的参考不保证准确地标识数据的完整性。在绝大多数情况下,确保数据的完整性要求知道所有输入的信息,这样的条件过于严苛,而且各个组件之间的网络延迟是无可避免的,实在迟到的数据未必会对结果造成显著的影响,因此实践当中 Heuristic Watermark 是常被采用的方式。当然,如果条件允许,Perfect Watermark 是语义上的上位替代。
Watermark 生成
数据处理逻辑处于上述不同时间策略的情况下对 Watermark 的处理方式是不同的。Processing Time 的场景不需要考虑 Watermark,只需要处理节点本地的时间;Event Time 的场景下,数据源根据先验知识产生数据对应的时间戳,理所当然的,Watermark 可以由数据源产生;Ingestion Time 的场景下,数据从数据源产生时即被附上当时时间戳,相应的 Watermark 也由数据源负责产生(在 FLINK 的实现里,Ingestion Time 的数据源根据配置的 Watermark 间隔产生 Watermark,结合 TCP 传输的特点,这是 Perfect Watermark 的一个实例)。
相关源码位置
SourceContext#collectWithTimestamp和SourceContext#emitWatermarkWatermarkContext及其子类
在 FLINK 的实现中,还支持另外一种 Watermark 的生成方式,即通过在上游算子后面串接一个专门处理上游数据并产生 Watermark 的算子。这适用于数据源本身不支持产生 Watermark 或者需要在中间算子根据具体情况产生尽可能精确的 Watermark 的情况。这种方式产生的算子会根据定制的逻辑处理上游到来的数据及其可能带有的时间戳,随后根据定制的逻辑构造 Watermark 向下游发送。FLINK 支持两种插入算子生成 Watermark 的方式。

相关源码位置
AssignerWithPunctuatedWatermarksTimestampsAndPunctuatedWatermarksOperatorAssignerWithPeriodicWatermarksTimestampsAndPeriodicWatermarksOperatorDataStream#assignTimestampsAndWatermarks
Watermark 传播
Watermark 在流式计算系统当中与数据一起从上游传播到下游。
如果算子只有一个上游,由于 Watermark 标识了比其所携带的时间戳早的数据均已到达,因此记录当前的 Watermark 需要对上游发来的 Watermark 从概念上说对其历史序列做取最大值操作。
如果算子具有多个上游,典型的是 KeyBy 的场景,此时算子会接受到多个上游发送的 Watermark,考虑 Watermark 的语义,此时能够确定的完整的数据是对应不同上游的 Watermark 之间最小的那个 Watermark,即时间最早的那一个。这是一种兜底的策略,如果不同输入彼此互不相关或者存在分组的不相关性,这种策略会导致在某一个输入延迟的情况下其他输入被延迟并缓存,可能会导致不必要的延时和缓存爆满。
从上游的角度来说,自身产生的 Watermark 会向所有下游广播。
相关源码位置
Output#emitWatermarkStatusWatermarkValve
Watermark 处理
我们说 Watermark 标识了数据的完整性,回忆一开始我们描述的场景,实际上我们是希望在获取一块完整的数据之后触发相应的聚合操作。因此,当算子收到上游发来的 Watermark 之后,需要执行相应的逻辑来触发计算。
在 FLINK 中,上游到来的 Watermark 会被发送到 InternalTimerService 中,更新其时间戳,并回调相应的触发逻辑,随后被发送到下游。
部分相关源码位置
AbstractStreamOperator#processWatermarkInternalTimerServiceImpl#advanceWatermarkWindowOperator#onEventTime
Lateness
即使使用了 Watermark 的机制,如果是 Heuristic Watermark 的话,仍然可能出现数据迟于 Watermark 到的情况。如前所述,由于现实世界的不确定性和网络延时的普遍性,这几乎不可避免。
在绝大多数流式计算系统都提供了迟到数据的处理,例如在 FLINK 中支持收到 Watermark 后保留一段时间的 WindowState 以相应迟到数据,或者将迟到数据输出到一个 side output 中接入下游或其他算子单独处理。
这部分的内容可以参考官方文档的相应内容,在这里提出是为了完整的说明常见的 Watermark 的启发式特性。在实际生产中,迟到数据不可避免,我们不可能长时间地去等待迟到数据。如果上游的数据总是迟到,那很有可能有更严重的问题需要排查。
不基于时间的触发
上面介绍的是流式计算系统当中的时间的概念,以及时间作为触发聚合的条件的来由和为了这么做需要面对的挑战。实际上,在许多实际应用场景中,我们还可能基于数据来做触发。例如,当收到上游传来的若干条数据时触发一个窗口。
相关源码的位置
Trigger及其子类,特别地CountTrigger实现了上面提到的功能WindowedStream#triggerAllWindowedStream#trigger
流式计算系统系列(3):窗口
在上一篇文章中我们提到流式计算系统当中聚合数据流以挖掘更多信息的例子,分别是【网站每隔一个小时的访问量】【每隔五分钟输出最近一个小时成交额最高的商品】和【实时显示用户的访问热点】。我们在上一篇文章中以此引出了流式计算系统当中的时间的概念,而这几个例子本身是基于时间的窗口的例子。
窗口(Window)暂存了上游输入的部分数据,以用于在给定的触发条件下对暂存的这部分数据进行聚合产生输出到下游的结果。可以看到,在这个定义下,窗口主要的属性包括:
- 窗口暂存数据的逻辑
- 窗口触发计算的逻辑
我们将从这两个属性入手,介绍窗口的分类及特定分类的语义和实现手法
窗口暂存数据的逻辑
这一部分的内容即确定一个窗口内暂存了哪些数据,这个问题包括了两个部分,即新到来的数据暂存到哪个窗口中,以及此前暂存的数据何时清理。
我们看到,在上面分拆问题的描述中,我们反转了行为的主体和受体,即不是由窗口来决定选择哪些数据,而是由数据来决定其归属的窗口。这样的逻辑更加符合流式计算中数据驱动的处理方式。在 Flink 的实现中,这个行为由 WindowAssigner 来负责,给定输入数据,由它判断将这个数据归属到若干个窗口当中。
我们看到 Flink 当中数据归属到窗口这个行为的分类。
GlobalWindow
全局所有数据都归属到同一个窗口。这是一个语义上正确的窗口,不过显而易见的是将所有数据都归属到同一个窗口的价值是有限的,同时面临着暂存区溢出的问题。通常这种窗口会结合定制的清理逻辑(Evictor)和触发逻辑(Trigger)来对窗口中的数据进行定制化的聚合和清理。
TimeWindow
数据按照附带的时间戳归属到不同的时间窗口当中。不同的数据几乎不会完全落到同一个窗口当中,因此时间窗口本身就具有将数据按照其时间戳初步划分批次的作用。我们看到具体的时间窗口的例子来介绍,这里的时间窗口按照其时间属性分为 Processing Time 的时间窗口或 Event Time 的时间窗口,关于不同时间属性的区别在前一篇文章中已经介绍,在此就不再做出区分。
TumblingTimeWindow
此窗口中文对应称为滚动窗口,我们首先看到一个滚动窗口的典型动图。

可以看到,滚动窗口根据划定的长度彼此紧邻而不交叉的出现,对于一个到来的数据,根据时间属性取得其时间戳,即可以算出它所对应的时间窗口。关于这一点,我们利用 Flink 的源码来做直观的解释。
// From TimeWindow.java
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
return timestamp - (timestamp - offset + windowSize) % windowSize;
}这里 timestamp 即数据对应的时间戳,windowSize 即窗口的大小,计算滚动窗口的关键理解难点在于 offset 参数。其实说破了也不复杂,默认滚动时间窗口是整点对齐的,即初始时间可以理解为 0:00:00,下一个窗口的起始时间是 0:00:00 + windowSize,而 offset 能够调整起始时间。上面源码是一个比较内部的逻辑,时间都是化归到距离标准开始时间偏移的毫秒为单位的长整型,实际用户接口是更加可读的时间参数。
本文开始的三个例子当中的【网站每隔一个小时的访问量】即属于滚动时间窗口的例子。
SlidingTimeWindow
此窗口中文对应称为滑动窗口,英文中也有做 HoppingTimeWindow 的,也有 SlidingWindow 表示与此处表述的滑动窗口语义略有区别的时间窗口的,具体可参考这篇文章。我们同样先看到一个滑动窗口的典型动图。

滑动窗口包括窗口长度和滑动步长两个属性,其具体语义由上图不难理解,上图中 s 对应窗口长度,h 对应滑动步长。对于一个数据来说,在滑动窗口的语义下,它有可能归属到若干个窗口当中。其计算方式与滚动窗口类似,只不过这一次首先算出其最后归属的窗口,然后按照滑动步长逐步退回到最先一个归属的窗口,在此期间遍历到的窗口将全部拥有这一个数据。
本文开始的三个例子当中的【每隔五分钟输出最近一个小时成交额最高的商品】即属于滑动时间窗口的例子。
SessionTimeWindow
此窗口中文对应称为会话窗口,与浏览器当中的会话类似,它有一个用户活跃的概念,抽象地说我们把一段连续的活跃时间内的数据划分到同一个窗口之中。我们同样先看到一个会话窗口的典型动图。

常见的会话窗口以数据之间超过一定的时间间隔来划分窗口,例如在上图中,s 代表了这个间隔,两个时间上相邻数据之间的间隔超过 0.5 个单位时间即认为是归属不同的会话窗口。
上图是从最终窗口的角度来展示会话窗口的划分过程。然而,我们在处理数据的时候,并不知道它应该归属到哪一个会话窗口中。尤其是考虑到数据无序到达的情况下,我们更不可能基于已有的数据直接在每个中间过程判断出相应的时间窗口归属。不同于前面两种时间窗口,会话窗口的产生是不可实现预知的,完全由输入数据决定。
Flink 对于会话窗口的实现与《Streaming System》或者说 Dataflow 论文介绍的方式一样,我们先看一张图。
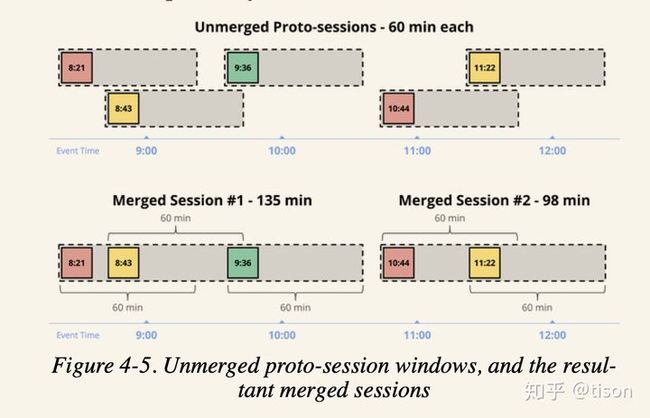
再看一段源码。
// From EventTimeSessionWindows.java
public Collection assignWindows(Object element, long timestamp, WindowAssignerContext context) {
return Collections.singletonList(new TimeWindow(timestamp, timestamp + sessionTimeout));
} 也就是说,数据被归属到一个以其时间戳为起点,超时时间为长度的窗口中,重叠的此类窗口会合并形成更大的窗口,直到 Watermark 或其他触发逻辑表明该窗口可以固化时固化并发送。窗口的合并是一个复杂的过程,包括状态的管理和回调的清理等等,相关的代码细节可以查看 Flink 中 (Evicting)WindowOperator 类中 if (windowAssigner instanceof MergingWindowAssigner) 下的代码块,也可以参考 Flink PMC 伍翀老师的这篇文章。
本文开始的三个例子当中的【实时显示用户的访问热点】即属于会话时间窗口的例子。
User-Defined Window
上面介绍的是最常见的以及 Flink 和其他流式计算系统开箱即用的窗口,在《Streaming Systems》一书中还介绍了根据输入数据的键来错开窗口的非对齐的(Unaligned)滚动时间窗口等自定义窗口。Flink 支持自定义窗口,只要按照 Window/WindowAssigner 以及配套的序列化器等一整套进行定制化实现,就可以根据特殊的用户场景实现自己的功能。根据上面的讨论,从语义上我们也并不需要将窗口和时间绑定起来,窗口只是预划分并支持数据聚合计算的一个暂存区而已。
窗口暂存数据的清理
在上面的讨论中,我们介绍了数据归属到对应的时间窗口的逻辑,关于窗口暂存那些数据,还有一个事情要讨论,即我们如何清理窗口中的数据。
清理窗口数据或者说清理窗口状态的策略总的来说有三种大的类型。
- 其之一是基于触发器(Trigger),在触发后清理所有数据,在 Flink 当中表现为回调触发器判断触发逻辑时返回
TriggerResult.FIRE_AND_PURGE,从而在触发窗口聚合计算后清理窗口状态。一个实例就是 Flink 当中的滚动计数窗口,它基于 GlobalWindow 实现,因此不会有基于事件的清理逻辑(下面提到的定时器),滚动窗口彼此互不相关,触发后将状态全部抛弃即可。 - 其之二是基于定时器(Timer),例如时间窗口在超出其最晚时间之后,由此前注册的清理逻辑定时器触发清理状态的动作。在 Flink 中可以参考
WindowOperator#registerCleanupTimer和WindowOperator#clearAllState相关的逻辑。这个方式是符合清理时间窗口的自然逻辑的,不必多举例子。 - 其之三是基于清除器(Evictor),从逻辑上说,它可以在某个时间根据当前窗口的数据状态来判断从窗口中清除掉那些元素,具有极高的清楚逻辑定制的自由度;从实现上,Flink 仅仅实现在窗口触发时处理函数执行前后在基于当时的状况判断清除掉哪些元素,在处理函数执行完成后重新计算窗口状态。一个实例就是 Flink 当中的滑动计数窗口,与上面提到的滚动计数窗口类似,问题在于滑动计数窗口的元素有重叠。由于没有像时间窗口一样将元素归类到不同的窗口中,而是从实现上在同一个 GlobalWindow 里,因此在触发计算时需要滑动地剔除不属于本计数窗口的元素。
窗口触发计算的逻辑
这一部分解决的是窗口暂存了部分数据之后何时触发聚合计算的问题。总的来说,这是触发器的职责。
关于基于时间的触发器在上一篇文章中已经详细介绍了 Watermark 的机制,也简单介绍了不基于时间的触发器的种类。在这里为了完整性以 Flink 的实现为例子介绍触发器的接口和语义。
// omit some modifiers
class Trigger implements Serializable {
TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx);
TriggerResult onProcessingTime(long time, W window, TriggerContext ctx);
TriggerResult onEventTime(long time, W window, TriggerContext ctx);
void clear(W window, TriggerContext ctx);
boolean canMerge();
void onMerge(W window, OnMergeContext ctx);
} 后面两个跟前面提到的窗口合并有关,主要涉及内部定时器的清理和状态的合并,clear 方法也是类似的作用。
对于触发计算相关的内容,我们看到有 onElement/onProcessingTime/onEventTime 三个方法,也就是说 Flink 支持基于数据和基于时间的触发逻辑,它们分别在 WindowOperator 调用 processElement 和 onProcessingTime 和 onEventTime 时被回调,并返回在当前数据或时间条件下是否触发当前窗口的计算。
关于这部分的详细展开,再次推荐参考本系列的前一篇文章关于时间和 Watermark 的介绍。
窗口状态管理
这一部分的内容要完全基于 Flink 的实现来讲了。因为前面两个部分讲的是从流式计算的理论上来说,我们是怎么理解窗口的语义的。Flink 使用其强大的可容错的状态管理机制赋能窗口计算的暂存区管理和容错能力。
根据不同的窗口处理函数,Flink 为 WindowOperator 准备的了 ListState, ReducingState, FoldingState, AggregatingState 等多种状态,以在使用明确的语义并优化状态的内存消耗。总的来说,这些状态都是 AppendingState,即支持有序追加元素的状态。
这个状态作为 WindowOperator 的算子状态,参与到本系列的第一篇文章中提到的容错管理当中,从而保证在容错场景下由检查点恢复出来的作业图在 WindowOperator 上的状态是正确的。具体地说,就是已经被处理并做检查点过的数据及其归属的窗口,这部分状态是能够容错的。因此从源数据回放输入是能够保证恰好一次的处理语义。
对于这个状态的特点,值得强调的有两点。
其之一,它是一个带有 Namespace 的状态,并且其 Namespace 就是窗口。Namespace 是状态除了天然支持的 KeyGroup 划分之外可以定制化的第二层划分的键,由于不同的窗口各自拥有一个命名空间,因此在时间窗口的场景下触发聚合计算的时候取暂存区的状态无需担心不同时间窗口的暂存区相互干扰的问题。
其之二,这个状态是一个 AppendingState,目前为了支持上面提到的一些增量聚合的窗口函数,会有特定的 ReducingState,FoldingState 和 AggregatingState 存在。这些状态实际上是跟处理逻辑相关的,并不是纯粹的数据结构的状态,例如 ListState,ValueState 和 MapState 等。这种设计使得 state backend 在提供不同实现的时候需要重复实现类似的代码去支持本该由上层处理统一的处理逻辑。另外,AppendingState 不支持 MapState,在某些增量操作例如 count distinct 时无法原生的表达,会导致性能瓶颈。性能瓶颈的另一个佐证是在引入 Evictor 时只能先全部出队,在剔除掉元素后再次入队构造状态,体现出了当前基于 AppendingState 设计的一些问题。
关于 Flink 代码,最后有一点需要提及的是,这部分代码的编写使用了大量的上下文状态的方式,即通过改变一个某种 Context 的对象可变的字段,来改变操作的目标,从而导致这部分代码非常难以阅读。建议阅读此部分代码的时候保持头脑清醒,对于上下文变量和类型参数可能的取值有一个清楚的清单。否则很容易就会陷入【我在哪?这段代码在干嘛?】的状况。
流式计算系统系列(4):状态
状态需求的来源
现实中的计算可以根据对状态的需求分为无状态的计算和有状态的计算两种。无状态的计算意味着单条输入包含计算出输出的所有信息,不需要其他信息即可得到输出;而有状态的计算意味着单条输入仅包含计算出输出的部分信息,其他信息依赖于之前的输入积累的状态。无状态的计算典型的例子比如从 socket 源将数据导入 HDFS,有状态的计算典型的例子比如经典的 WordCount 就需要累积之前的单词计数。
显而易见,大多数有业务价值的计算场景都是有状态的计算。状态的需求包括状态数据的存储和加载,快照和恢复,以及分布式场景下的划分和伸缩三个方面。批处理和流式计算都有对状态的需求,但是其重要性和实际处理方式并不相同。
对于状态数据的存储和加载,在批处理的场景下,单条输入实际上意味着单批数据。数据被划分为不同的分片,通常,根据具体的操作(如 KeyBy)被划分为彼此相关的若干块。在这种划分方式下,每个任务处理其中一个分片,最终聚合输出得到结果。在这个过程中,相互依赖的数据被分在一起,并且每个批次都只有有限的数据,内存状态即可解决有状态计算中数据相互依赖的问题,对于状态的需求并不明显。
但在流式计算中,单条输入就意味着单条数据。由于流式计算的输入理论上是个无限流,我们必须有某种方式来管理先前输入积累的状态。注意到区别于批处理分钟、小时级的处理时间,流式计算的运行时间以天、月甚至年为单位。在这种情况下,我们不能总是依赖内存来管理状态。内存状态的管理方式并不能很好的应对大数据量的状态的存储问题,容错场景下的一致性问题和横向扩展时的伸缩问题。
存储的问题是明显的,批处理每批只处理有限的数据,而流式计算需要应对无限的输入。容错场景下的一致性问题在本系列第一篇文章中也有提到,在批处理的场景下,单批失败只需要重新计算,而流式计算的场景里上游无法无限缓存中间结果,必须依赖状态的快照和恢复来容错。如果说在批处理的场景下,快照是一个快速恢复的优化,那么在流式计算的场景里 ,这就是一个必须实现的功能了。
另外,状态的划分和应对规模伸缩在流式计算中也需要被特别对待。这是因为在批处理中,状态是和一批有限的数据绑定的,在规模伸缩时,只要把数据按照不同的方式重新划分好,状态自然就跟着数据被划分好了,也就是说,状态是跟着有限的数据走的。对于已完成的计算如果牵扯进状态划分,则可以重算一遍有限数据的批次。但是在流式计算中,我们不可能实际的完整划分无限的数据,也不可能回溯过往的所有数据,规模伸缩实际改变的是网络拓扑,也就是所谓的重分区(repartition),见下图。在这种情况下,我们必须做好状态数据的格式定义,以在重分区的场景下正确地将状态重新划分。当然,批处理也可以做这样的优化避免已计算完的状态重新计算,不过只是一个优化,而且对于正在执行的作业,这样的优化有些没必要。
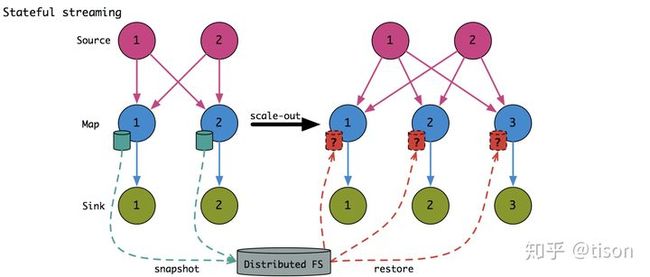
传统的流式计算对状态管理仅提供有限的支持(Spark Streaming)或者根本不提供支持(Storm),但是有状态的计算是确实存在的业务需求。在这种情况下采取的方法往往是引入另一个系统来辅助实现状态管理。例如经典的 Storm + HBase 架构,把状态数据存放在 HBase 中,计算的时候再从 HBase 中读取状态数据。但是这样的方案显然有不可忽略的性能开销,而且仅仅是解决了流式计算可能产生超大数据量的问题,以及持久化容错但不保证强一致性。同时,这样的方案在伸缩的时候需要用户手动编写代码去重新分配状态,更广泛的说,每一个业务自己都要重新实现一整套状态管理的逻辑。这种重复实现不仅是没必要的,而且显而易见的会在每次实现的时候碰到相同不相同的 BUG。
我们不会要求业务从操作系统开始自己写起来搭建应用,作为流式计算的操作系统,其本身也应该支持这种常见而且有规律的需求,即提供开箱即用的本地状态管理。这里的本地是相对于 Storm + HBase 方案中需要对每个操作都走网络而言的,强调的是状态和计算在同一台机器上,包括但不限于内存状态。
状态种类的划分
新时代的流式计算系统基本都将状态管理考虑在需要支持的核心特性当中,其中 Flink 由于长时间的考验和眼睛,支持的状态种类和兼顾到的应用场景是最多的。我们来看到 Flink 中的状态种类划分,其他的系统基本大同小异。
总的来说,Flink 的状态区分为 KeyedState 和 OperatorState 两种。顾名思义,KeyedState 跟每一个 key 相关联,也就只能使用在 KeyedStream 当中;而 OperatorState 与每个算子相关,可以使用在任意算子里。
首先说 KeyedState,我们先看一段 Flink 代码,感受一下实际使用的情况。
// KeyedState
public class WordCount extends RichFlatMapFunction> {
private transient ValueState state;
@Override
public void open(Configuration conf) {
final ValueStateDescriptor descriptor = new ValueStateDescriptor<>("C", Integer.class, 0);
state = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(String word, Collector> collector) {
int c = state.value();
c += 1;
state.update(c);
collector.collect(new Tuple2<>(word, count));
}
} 状态管理的架构和控制流会在下一节展开,这里我们关注到状态的具体使用。我们在算子的一个并发启动的时候初始化状态的句柄,随后在实际计算的过程中通过句柄来获取和更新算子。在背后,Flink 通过后文提到的 StateBackend 等抽象完成了实际读写内存或者加载存储持久化后端以及可能的序列化操作。对于用户来说,这些都是不可知的,开箱即用的。
这里我们看到使用了名为 ValueState 的状态,顾名思义,状态就像一个值一样可以被读取和更新。Flink 的 KeyedState 还支持 MapState/ListState/ReducingState/AggregatingState,其中 Map 和 List 好理解,和 Value 可以某种程度上组成 Perl 三巨头类型。后两个 State 其实也是某种意义上的 ListState,只不过 Flink 为未来也要进行状态合并的状态提供了提前压缩状态的优化,以减少状态的大小并分摊计算压力。
然后我们看到 OperatorState,同样先看一段使用代码。
// OperatorState
public class MapF extends RichMapFunction implements CheckpointedFunction {
private transient ListState countState;
private transient List count;
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor descriptor = new ListStateDescriptor<>("es", Long.class);
countState = context.getOperatorStateStore().getListState(descriptor);
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
countState.clear();
countState.addAll(count);
}
}
可以看到,对于 OperatorState,用户需要手动管理 restore 和 snapshot 的逻辑。并且我们这里使用了 ListState 来实现类似于 ValueState 的功能,这是因为 OperatorState 仅支持少数几种类型的状态的原因。
那么,KeyedState 和 OperatorState 为什么有这么多不同呢?对于这个问题,我们就要从 KeyedState 和 OperatorState 最初引入所要解决的问题来说明了。
虽然首先引入的是 KeyedState,但是更广泛和通用的概念却是 OperatorState。按照我们一般的想法,状态类似于一个持久化可容错的本地存储,看起来应该跟一个内存变量没有太多的区别才对,按照 Operator 划分,在算子的每一份并发里交流是很正常的事情。实际情况确实大抵也是如此,如果你没有重伸缩(rescale)的需求,把 ListState 在其他场景下当做单元素的列表用,基本也能搞定大多数的需求,对于原先 KeyedState 的场景,只要手动加一个 key 到 value 的映射就可以了。
那么,问题就出在重伸缩上面。正如我们在状态需求的来源一节中提到的,好的状态设计要能够应对规模伸缩,如前图所示,当某个算子的并发度从 3 改成 2 时,算子的状态并不好简单的划分。实际上,前文提到的 OperatorState 仅支持少数几种类型的状态,这些状态不同之处主要就在于重新划分状态时的策略。我们先看看都是什么策略,然后再引入 KeyedState 处理这个问题的方法。
OperatorState 支持 SPLIT_DISTRIBUTE(ListState)/UNION(UnionListState)/BROADCAST(BroadcastState) 三种类型,它们在改变并发的时候重新划分的逻辑如下图所示。

- ListState: 把所有状态先后串接在一起,然后均匀分配到新的并发上。
- UnionListState: 把所有状态先后串接在一起,然后将串接后的全量分配到新的并发上。
- BroadcastState: 此状态本来每份并发就都会拥有同样的全量数据,直接拷贝到新的并发上即可。
由于 OperatorState 并不知道用户划分状态的依据,因此只能提供这样有限的接口,对于上面使用的 count 例子,由于有交换律和结合律,还可直接使用 ListState,而非这种情况也非 broadcase 情况的,则算子不得不全量获取状态并由用户在 restore 里重新实现具体使用哪部分状态的逻辑。这个重新划分的逻辑并不好做,因为状态作为过往输入综合影响的结果,在重伸缩的情景下,上游算子的输出会发到下游算子的哪个并发上实际是由分区逻辑决定的,在用户层面,很难直接取得网络拓扑的信息,用户也不应该直接分析网络拓扑这样底层的逻辑。无论是由划分决定网络,还是本质上的网络决定划分,OperatorState 在更一般的场景下都要求更底层的操作状态,而这正是我们提供开箱即用的状态管理想要避免的问题。
KeyedState 就很好的解决了这个问题。在许多实际的业务场景里,数据并不是杂乱无章的被处理,而是有各种各样的标签信息。例如单词计数中的词汇和当前计数,以及用户点击中的用户名和点击行为。在这些场景中,我们会希望将数据按照一定的信息划分归类,在这里我们就引入了用户划分的逻辑。既然知道了用户划分的逻辑,重伸缩的时候划分状态也就好办了,只要保证原来在同一个 key 下的状态依然被划分到同一个并发上就可以了。如下图所示,其中不同颜色代表不同 key 的状态,状态有大有小。

从概念上说,你可以给数据都加上一个唯一的 id 作为 key,从而利用 KeyedState 进行状态存储,这比起 OperatorState 来也不会缺少任何功能,同时还能很好的支持重伸缩下的重分区操作。那为什么我们还需要 OperatorState 呢?在实际应用场景中,OperatorState 主要用于 Source 的状态管理,例如 KafkaConsumer,此时数据还未流经流式计算引擎,自然也不可能有什么流式计算引擎认识的 key,同时多数的 Source 支持按 offset 回拨,而 offset 本身在 Source 的哪个并发并不重要,可以适应 OperatorState 中 ListState 的场景。另外,在 BroadcastState 的场景里,我们需要把相同的数据发送到每一个下游算子上,这个 KeyedState 反而在重分区的时候不好操作。
状态管理的架构
状态管理的架构根据不同系统的具体实现会有很不一样的表现。例如 Flink 只是一个计算引擎,它会引入 StateBackend 的概念来支持不同的状态持久化存储后端,而 Hazelcast Jet 则由于构建在分布式网格存储 Hazelcast 之上,因此所有的状态都是存储在 Hazelcast 上的。本节的内容会偏向于介绍 Flink 选择的状态管理架构,不同于用户界面的大同小异,封装在后端的状态管理架构跟具体的项目实现相关。
我们不会去讲太多实际代码的细节,因为 Flink 在状态管理这边的实现命名比较混乱,设计比较随意,各种莫名的中间层也很多。我们抓住链路中关键的几个节点,根据 Flink 中状态最主要的分类 KeyedState 和 OperatorState 简要地展开介绍。注意这里讲的是状态管理的架构,不会过多涉及到 Checkpoint 的机制,这两者是相关联但是可以分开看到的功能组件。
Flink 状态管理架构的枢纽是 StateBackend,准确来说,是实际实现的 KeyedStateBackend 和 OperatorStateBackend,它们向上承接用户界面的操作,向下处理具体状态后端的输出工作。
其中,KeyedStateBackend 支持将状态存储到内存中,或者文件系统上,或者 RocksDB 里;而 OperatorStateBackend 则只支持内存和文件系统的状态后端。这是官方的和常用的说法,但其实这里统称为状态后端的概念有两个不同维度的区分。
第一个是 Working State 的位置,也就是用户函数里实际操作的 State 保存的位置,这个要么是在内存里,要么是在 RocksDB 里,其中 RocksDB 作为更大但是稍慢的内存来使用,同时利用 RocksDB 的存储格式,可以适当地压缩状态数据并支持增量的 Checkpoint。这里提到了 Checkpoint,第二个维度就是 Checkpoint 的位置,也就是状态快照保存的位置,这个要么随着 RPC 信息发送到 JobManager 端保存在内存中,要么就持久化到文件系统里。通常所说的内存状态后端和文件系统状态后端的主要区别即在于此,而 RocksDB 状态后端则可以灵活配置 Checkpoint 持久化的位置,不过基于其一般用于保存大的状态,通常是搭配文件系统状态后端来使用。
KeyedStateBackend 和 OperatorStateBackend 实际控制了状态读写的逻辑。对于 KeyedStateBackend 来说,其中基于 Heap 的实现会在内存中创建 StateTable,而 KeyedStateBackend 基于 RocksDB 的实现则直接使用 RocksDB 的数据库接口来查询和更新。对于 OperatorStateBackend 的唯一实现,则是相应创建 List 的封装或者 Map 封装的 BroadcastState。值得一提的是,KeyedState 包括一个 Namespace 属性,这个玩意主要是给 Window 算子用的,也就是在 Keyed 的第一层划分之后,新加了第二层划分的逻辑。通过将窗口对象设置为 Namespace,就可以将状态先按照 Keyed,再按照 Window 进行两阶段划分。同时在存取的时候将两个划分标准同时作为读取的依据,唯一锁定一份状态。