flink学习(一)
前言:之前学习flink时没有系统性的复习,现在不多BB就是为了复习flink(从头再来)
1.1flink的引入
计算引擎分为几代有些争议,这里我选择的是四代
第一代计算引擎,MapReduce (首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce,它将计算分为两个阶段,分别为 Map 和 Reduce)
第二代计算引擎 ,tez+Oozie(特点:批处理 1 个 Tez = MR(1) + MR(2) + … + MR(n),相比 MR 效率有所提升)
第三代计算引擎 ,spark(特点:主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算)
第四代计算引擎,flink(特点:主要表现在 Flink 对流计算的支持,以及更 一步的实时性上面)
这里有个直观的测试
测试环境:
1.CPU:7000 个;
2.内存:单机 128GB;
3.版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
4.数据:800MB,8GB,8TB;
5.算法:K-means:以空间中 K 个点为中心进行聚类,对最靠近它们的对象归类。通过 迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
6.迭代:K=10,3 组数据
可视化结果展示如下

经过测试,Flink 计算性能上略好。
而Spark 和 Flink 全部都运行在 Hadoop YARN 上,性能为 Flink > Spark > Hadoop(MR), 迭代次数越多越明显,性能上,Flink 优于 Spark 和 Hadoop 最主要的原因是 Flink 支持 增量迭代,具有对迭代自动优化的功能。
这里我们说一下Flink 和 spark 的差异(如下图)

1.2什么是Flink?
Apache Flink 是为分布式、 高性能、 随时可用以及准确的流处理应用程序打造的开源流处理框架 。
1.3Flink流处理计算的特性
- 支持高吞吐、 低延迟、 高性能的流处理
- 支持带有事件时间的窗口(Window) 操作
- 支持有状态计算的 Exactly-once 语义
- 支持高度灵活的窗口(Window) 操作, 支持基于 time、 count、 session, 以及data-driven 的窗口操作
- 支持具有 Backpressure 功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot) 实现的容错
- 一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
- Flink 在 JVM 内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化: 避免特定情况下 Shuffle、 排序等昂贵操作, 中间结果有必要进行缓存
1.4Flink的四大基石
Flink 之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、 Window。(之后我们会专门说这四大基石)
除此之外,Flink 还实现了 Watermark 的机制,能够支持基于事件的时间的处理,或 者说基于系统时间的处理, 能够容忍数据的延时、 容忍数据的迟到、 容忍乱序的数据。 另外流计算中一般在对流数据进行操作之前都会先进行开窗, 即基于一个什么样的窗口上 做这个计算。 Flink 提供了开箱即用的各种窗口, 比如滑动窗口、 滚动窗口、 会话窗口 以及非常灵活的自定义的窗口。

1.5批处理与流处理
批处理的特点是有界、 持久、 大量, 批处理非常适合需要访问全套记录才能完成的计算工作, 一般用于离线统计 。
流处理的特点是无界、 实时, 流处理方式无需针对整个数据集执行操作, 而是对通过系统传输的每个数据项执行操作, 一般用于实时统计。
Flink 是如何同时实现批处理与流处理的呢? 答案是, Flink 将批处理( 即处理有 限的静态数据)视作一种特殊的流处理。
Flink 的核心计算架构是下图中的 Flink Runtime 执行引擎, 它是一个分布式系统, 能够接受数据流程序并在一台或多台机器上以容错方式 执行。Flink Runtime 执行引擎可以作为 YARN( Yet Another Resource Negotiator) 的应 用程序在集群上运行, 也可以在 Mesos 集群上运行, 还可以在单机上运行(这对于调试 Flink 应用程序来说非常有用)。
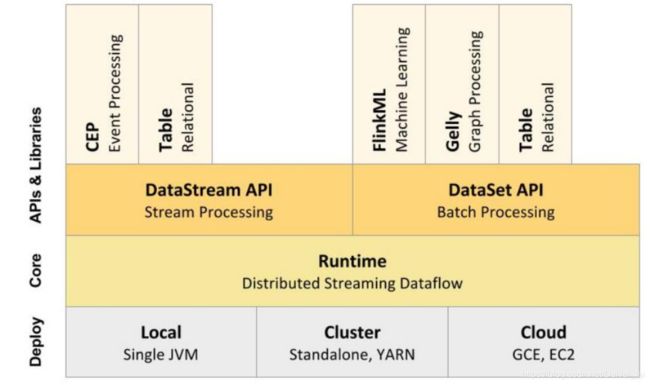
从下⾄上:
1、部署: Flink ⽀持本地运⾏、能在独⽴集群或者在被 YARN 或 Mesos 管理的集群上运 ⾏,也能部署在云上。
2、运⾏: Flink 的核⼼是分布式流式数据引擎,意味着数据以⼀次⼀个事件的形式被处理。
3、API: DataStream、 DataSet、 SQL API。
4、扩展库: Flink 还包括⽤于复杂事件处理,机器学习,图形处理。
上图为 Flink 技术栈的核心组成部分, 值得一提的是, Flink 分别提供了面向流式 处理的接口(DataStream API) 和面向批处理的接口(DataSet API) 。 因此, Flink 既 可以完成流处理,也可以完成批处理。 Flink 支持的拓展库涉及机器学习(FlinkML) 、 复 杂事件处理(CEP) 、 以及图计算(Gelly) , 还有分别针对流处理和批处理的 Table API。
Flink 本质上使用容错性数据流, 这使得开发人 员可以分析持续生成且永远不结束的数据( 即流处理)。
2.Flink的架构体系
2.1Flink中的角色
JobManager(老大)、TaskManger(小弟)
JobManager 处理器: 也称之为 Master, 用于协调分布式执行, 它们用来调度 task, 协调检查点, 协调失败 时恢复等。 Flink 运行时至少存在一个 master 处理器, 如果配置高可用模式则会存在多 个 master 处理器, 它们其中有一个是 leader, 而其他的都是 standby。
TaskManager 处理器: 也称之为 Worker, 用于执行一个 dataflow 的 task(或者特殊的 subtask)、 数据缓冲和 datastream 的交换, Flink 运行时至少会存在一个 worker 处理器。
2.2无界数据流与有界数据流
无界数据流: 无界数据流有一个开始但是没有结束
要求:流处理一般需要支持低延迟、 Exactly-once 保证
有界数据流: 有界数据流有明确定义的开始和结束
要求:批处理需要支持高吞吐、 高效处理
2.3Flink数据流编程模型
分为四层
Process Function
批处理和流处理Api
Table Api
SQL
Flink 提供了不同的抽象级别以开发流式或批处理应用。
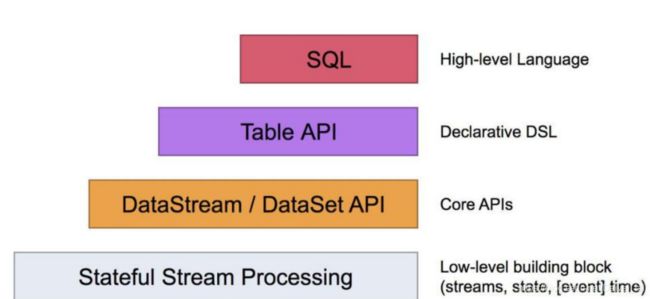
最底层级的抽象仅仅提供了有状态流, 它将通过过程函数( Process Function) 被 嵌入到 DataStream API 中。 底层过程函数(Process Function) 与 DataStream API 相 集成, 使其可以对某些特定的操作进行底层的抽象, 它允许用户可以自由地处理来自一个 或多个数据流的事件, 并使用一致的容错的状态。 除此之外, 用户可以注册事件时间并 处理时间回调, 从而使程序可以处理复杂的计算。 实际上, 大多数应用并不需要上述的底层抽象, 而是针对核心 API(Core APIs) 进 行编程,比如 DataStream API(有界或无界流数据) 以及 DataSet API(有界数据集) 。 这些 API 为数据处理提供了通用的构建模块, 比如由用户定义的多种形式的转换 ( transformations) , 连接(joins) , 聚合(aggregations) , 窗口操作(windows) 等等。 DataSet API 为有界数据集提供了额外的支持, 例如循环与迭代。 这些 API 处理 的数据类型以类(classes) 的形式由各自的编程语言所表示。Table API 是以表为中心的 声明式编程, 其中表可能会动态变化(在表达流数据时) 。 TableAPI 遵循(扩展的) 关 系模型: 表有二维数据结构(schema) (类似于关系数据库中的表) , 同时 API 提供 可比较的操作, 例如 select、 project、 join、 group-by、 aggregate 等。 Table API 程序声明式地定义了什么逻辑操作应该执行, 而不是准确地确定这些操作 代码的看上去如何 。尽管 Table API 可以通过多种类型的用户自定义函数(UDF) 进行扩 展, 其仍不如核心 API 更具表达能力, 但是使用起来却更加简洁(代码量更少) 。 除 此之外, Table API 程序在执行之前会经过内置优化器进行优化。你 可 以 在 表 与 DataStream/DataSet 之 间 无 缝 切 换 ,以 允 许 程 序 将 Table API 与 DataStream 以及 DataSet 混合使用。 Flink 提供的最高层级的抽象是 SQL 。 这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL 查询表达式的形式表现程序。 SQL 抽象与 Table API 交互密切, 同 时 SQL 查询可以直接在 Table API 定义的表上执行。
2.4Flink支持的库
支持机器学习( FlinkML)
支持图分析( Gelly)
支持关系数据处理( Table)
支持复杂事件处理( CEP)
3.Flink集群搭建
- local( 本地) ——单机模式, 一般不使用
- standalone ——独立模式, Flink 自带集群, 开发测试环境使用
- yarn——计算资源统一由 Hadoop YARN 管理, 生产环境测试
3.1Standalone集群搭建
- 解压 Flink 压缩包到指定目录(tar -zxvf flink-1.7.2-bin-hadoop26-scala_2.11.tgz -C /export/service)
- 配置 Flink
- 配置 Slaves 节点
- 分发 Flink 到各个节点
- 启动集群
- 递交 wordcount 程序测试
- 查看 Flink WebUI
3.2Standalone-HA集群搭建
- 在 flink-conf.yaml 中添加 zookeeper 配置
- 将配置过的 HA 的 flink-conf.yaml 分发到另外两个节点
- 分别到另外两个节点中修改 flink-conf.yaml 中的配置
- 在 masters 配置文件中添加多个节点
- 分发 masters 配置文件到另外两个节点
- 启动 zookeeper 集群
- 启动 flink 集群
3.3Yarn集群环境运行
3.3.1会话模式
使用场景:适用于大量的小文件
运行方式:分两步提交:yarn-session.sh(开辟资源)+flink run(提交任务)
3.3.2分离模式
适用场景:适用于大文件
运行方式:flink run -m yarn-cluster
4.Flink 运行架构
4.1任务提交流程
1.Client 向 HDFS 上传 Flink 的 Jar 包和配置
2.Client向 YarnResourceManager 提 交 任 务
3.ResourceManager 分 配 Container 资 源 并 通 知 对应 的 NodeManager 启 动 ApplicationMaster
4.ApplicationMaster 启动后加载 Flink 的Jar 包 和 配 置 构 建 环 境 , 然 后 启 动 JobManager
5.ApplicationMaster 向ResourceManager 申 请 资 源 启 动 TaskManager
6.ResourceManager 分 配 Container 源 后 , 由 ApplicationMaster 通 知 资 源 所 在 节 点 的 NodeManager 启动TaskManager
7.NodeManager 加载 Flink 的 Jar 包和配置构建环境并启动 TaskManager
8.TaskManager 启动后向 JobManager 发送心跳包, 并等待 JobManager 向其分配任务
4.2Worker 与 Slots
每个 task slot 表示 TaskManager 拥有资源的一个固定大小的子集。 假如一个
TaskManager 有三个 slot, 那么它会将其管理的内存分成三份给各个 slot。 资源 slot 化
意味着一个 subtask 将不需要跟来自其他 job 的 subtask 竞争被管理的内存, 取而代之
的是它将拥有一定数量的内存 储备。 需要注意的是, 这里不会涉及到 CPU 的隔离, slot 目前仅仅用来隔离 task 的受管理的内存 。
4.3程序与数据流
Flink 程序的基础构建模块是 流(streams) 与 转换(transformations)
4.4并行数据流
One-to-one: stream(比如在 source 和 map operator 之间)维护着分区以及元素的顺序
Redistributing: stream(map()跟 keyBy/window 之间或者 keyBy/window 跟 sink 之间)的分区会发生改变
4.5task 与 operator chains
Flink 将 operator 的 subtask 链接在一起形成 task, 每个task 在 一个线程中执行。 将 operators 链接成 task 是非常有效的优化: 它能减少线程之间的切换和基于缓存区的数据交换, 在减少时延的同时提升吞吐量