influxdb基本使用及其源码解析
文章目录
-
- 基本介绍
-
- 简介
- 属性
- 特点
- 场景
- 相关概念
-
- series
- series cardinality
- Shard
- Shard group
- Shard Duration
- Retention policy
- TSM
- LSM
- 源码解析
-
- 编译
- IDE调试
- 服务启动
- meta
-
- Shard
- Shard group
- RetentionPolicy
- DatabaseInfo
- Data
-
- 数据写入
- Series
- Index
-
- Inmem Index
- tsi index
- Store
- Shard
- Engine
- TSM Engine Cache
- TSM Engine WAL
- 安装使用
-
- 安装
- 命令
-
- 数据库操作
- 新增查询操作
- 配置详解
基本介绍
简介
- 在介绍InfluxDB之前,先来介绍下时序数据。按照时间顺序记录系统、设备状态变化的数据被称为时序数据(Time Series Data),如CPU利用率、某一时间的环境温度等。
- InfluxDB是一个由InfluxData开发的开源时序型数据,由Go编写在时序型数据库DB-Engines Ranking上排名第一。
- InfluxDB自发布至今,已经有两个版本,InfluxDB1.x系列提供一种类似SQL的查询语言InfluxQL,用于数据交互。2019年1月新推出的influxDB2.0 alpha版本,主推全新的查询语言Flux,支持TICK架构。在 2020 年底推出InfluxDB 2.0 正式版本,该版本又分为InfluxDB Cloud 和 InfluxDB OSS两个系列。
- InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便,适合用于包括DevOps监控,应用程序指标,物联网传感器数据和实时分析的后端存储。类似的数据库有Elasticsearch、Graphite等。
- 对于传统关系型数据库,增删改查应该是必备且常用的功能,而
influxdb常用的只有insert和select,没有提供update语法,虽然有delete可以删除数据(delete语法和mysql相似),但是需求不大。统计的数据是秒级,甚至毫秒、纳秒级的,势必产生海量数据。有些数据越旧越失去它的时效性,越没有参考价值,所以保留策略retention policy就是可以让数据存储一段时间后自动清除。
属性
-
Time Series (时间序列):你可以使用与时间有关的相关函数(如最大,最小,求和等)
-
Metrics(度量):你可以实时对大量数据进行计算
-
Eevents(事件):它支持任意的事件数据

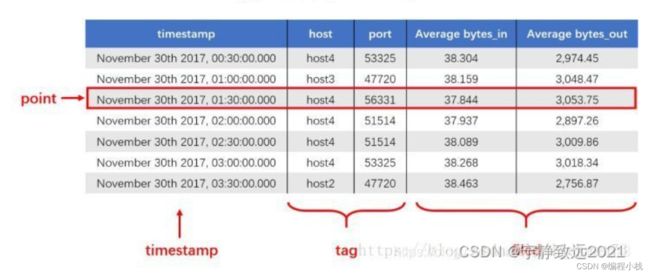
| Point属性 | 传统数据库中的概念 |
|---|---|
| time(时间戳) | 代表每个数据记录时间,是数据库中的主索(会自动生成) |
| fields(字段) | 代表数据的测量值,随时间平滑波动(没有索引的属性) |
| tags(标签) | 代表数据的归属,一般不随着时间变化,供查询使用(索引的属性) |
注意:
- 在influxdb中,字段必须存在。因为字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。类比一下,fields相当于SQL的没有索引的列。
- tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型。
- 所有在数据库中的数据,都需要通过图表来表示,series(系列)表示这个表里面的所有的数据可以在图标上画成几条线(注:线条的个数由tags排列组合计算出来)
- tag 只能为字符串类型,field 类型无限制
- 不支持join,支持连续查询操作(汇总统计数据):CONTINUOUS QUERY
- 配合Telegraf服务(Telegraf可以监控系统CPU、内存、网络等数据)
- 配合Grafana服务(数据展现的图像界面,将influxdb中的数据可视化)
特点
-
通过实现高度可扩展的数据接收和存储引擎,高效地实时收集、存储、查询、可视化显示和执行预定义操作。
-
通过连续查询提升查询效率和缩短延迟,通过数据保留策略,及时高效地删除过期冷数据,提升存储效率。
- 为时间序列数据专门编写的自定义高性能数据存储。 TSM引擎具有高性能的写入和数据压缩
- Golang编写,没有其它的依赖,支持类sql查询语句
- tags可以索引序列化,提供快速有效的查询
- Retention policies自动处理过期数据
- Continuous queries自动聚合,提高查询效率
- schemaless(无结构),可以是任意数量的列
- 提供简单、高性能的写入、查询 http api,Native HTTP API, 内置http支持,使用http读写
- 插件支持其它数据写入协议,例如 graphite、collectd、OpenTSDB
- Scalable可拓展
- min, max, sum, count, mean,median 一系列函数,方便统计
- Built-in Explorer 自带管理工具
场景
解决什么问题
传统数据库通常记录数据的当前值,时序型数据库则记录所有的历史数据,在处理当前时序数据时又要不断接收新的时序数据,同时时序数据的查询也总是以时间为基础查询条件,并专注于解决以下海量数据场景的问题:
- 专为时序存储和高性能读写而设计:计算机虚拟世界的各种系统和应用,以及物理世界的IoT设备等都在创建海量的时序数据,每秒千万级的数据吞吐量是很常见的,而且这些数据还需要可以以非阻塞方式接收并且可压缩以节省有限的存储资源。如何支持千万级/秒数据的写入。如何支持千万级/秒数据的聚合和查询。
- 专为实时操作而设计:预测能力和实时决策能力,需要收到数据后,就能实时输出最新的数据分析结果,执行预定义的操作。
- 专为高可用性而设计:现代软件系统需要全天候可用,除了基本的集群能力,还需要根据需求自动扩容和缩容,支持柔性可用等。
- 成本敏感:海量数据存储带来的是成本问题,如何更低成本存储这些数据是时序型数据库需要解决的关键问题。
监控软件系统: 虚拟机、容器、服务
监控物理系统:制造业工厂中的设备监控、国家安全相关的数据监控、通讯监控、传感器数据、血压、心率变化等
资产跟踪应用: 汽车、卡车、物理容器、运货托盘
金融交易系统: 传统证券、新兴的加密数字货币
事件应用程序: 跟踪用户、客户的交互数据
商业智能工具: 跟踪关键指标和业务的总体健康情况
在互联网行业中,也有着非常多的时序数据,例如用户访问网站的行为轨迹,应用程序产生的日志数据等等
相关概念
上述主要提到了measurement,tag,point等一些基本的概念。些概念和我们常用的DBMS有些像。
series
series也叫做序列,这个概念其实在大多数时序数据库里面都有。在influxDB的概念是:
![]()
一个series指的是**(measurement,tag set,field key**)定义的一组数据。
比如下面有一组关于cpu的数据,和一组关于memory的数据:
timestamp host rock usage load
1648974723 1.2.3.4 rock1 0.33 2
1648974743 1.2.3.5 rock2 0.34 3
这组数据就有两个series,首先measurement是cpu,tag有两个,分别是host和rock,代表了这个cpu的host的所在的rock(机架)。
field有两个,usage和load,代表这个时刻的cpu.load 和cpu.usage。
按照定义tag set是固定的,field就是usage和load,所以就是两个series。
这里的seires的概念和其他时序数据库有点出入,
比如openTSDB定义的series是(name,tagK,tagV),也就是每个name+tagK+tagV唯一确定了一个series。


series cardinality
![]()
series的大小,一般也叫series的维度;通俗点解释就是这个series有多少种组合情况。
-- show estimated cardinality of measurement set on current database
SHOW MEASUREMENT CARDINALITY
-- show exact cardinality of measurement set on specified database
SHOW MEASUREMENT EXACT CARDINALITY ON mydb
Shard

shard翻译过来也叫分片,一个shard就是编码压缩后的数据真实存储的位置。这种数据被组织成了一个TSM的结构。并且每一个shard属于一个shard group。在一个shard里面,series相同的点,会被存储在一个TSM里面。这里可以看出来,series其实还是非常重要的,是贯穿了存储和查询的概念。
Shard group

shard group其实是一个逻辑的概念,shard是一个物理的概念。
这里逻辑的概念指的是之存在于理解和代码种,存储到磁盘时,是没有shard group相关的信息存储的。
shard group是对shard的分组,那么分组的依据是什么呢?
时序数据有一个非常重要的特点就是时间属性很强,比如机器监控数据,大家可能只关心最近两天的数据,比如你会关心一年前机器的cpu 使用率是多少吗?(PS:也可能关心,比如每年一度的活动的时候,会环比去年同期)大部分场景下,还是关注的是最近的数据。所以在时序数据种,数据过期和保留策略就很重要。这个在influxDB里面,叫做retention policy。shard group是一个和retention policy强相关的概念。
Shard Duration

上面提到了,shard group是一组逻辑的概念,并且和retention policy紧密相关。决定了一个shard group的有限期是多长时间的东西,叫做Shard Duration。
这里解释了shard duration的概念。并且举了个例子,假设给的shard duration是1w(week),那么这一周创建的shard,都是属于一个shard group内(也就是说这一周不会有新建shard group的操作出现)。
Retention policy

retention policy也叫数据保留策略,是一个非常重要的概念。而且这不是一个逻辑概念,retention policy是直接能够在存储的时候非常明显的体现出来。
retention policy是描述了influxDB把数据保留多久,数据有多少个副本(replication factor),以及一个shard group的时间范围。这里面数据保留多久和shard group的范围我想都是能够理解的。
对于replication factor解释一下,指的是一个数据的副本数量。在分片存储的环境下,数据副本是非常重要的。因为一旦shard 损坏,那么造成数据丢失,所以为了应对这种缺陷,就会采用副本(replica).shard1和shard2互为副本,写入shard1的数据同时也会写入到shard2,一旦shard1有损坏,那么就可以使用shard2来顶替。这里的副本数量值得就是,对于一个shard,给他配置多少个副本。
TSM
![]()
(Time Structured Merge tree)时间结构合并树
InfluxDB的存储结构树是时间结构合并树(Time-Structured Merge Tree,TSM),它是由日志结构化合并树(Log-Structured Merge Tree,LSM),根据实际需求变化而来的。
下图说明了database,retention policy,measurement以及series上面的包含关系。

下图基本说明了influxDB的架构,可以看到每个database都是分开存储的,database下面,每个retention policy也是分开存储的,retention policy下面就是每个shard,这里没有shard group,因为shard group是一个逻辑概念,不体现在存储上。
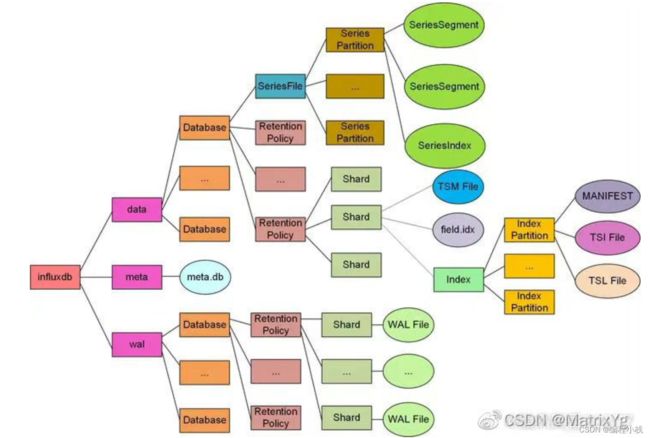
TSM存储引擎主要包括四部分:Cache,WAL,TSM File,Compactor。
下图中shard与TSM引擎主要部分放在一起,但其实shard group是在TSM存储引擎之上的一个概念。在 InfluxDB 中按照数据产生的时间范围,会创建不同的shard分组,每个 shard 都有本身的 cache、wal、tsm file 以及 compactor。

LSM
log-structed merge-tree
日志结构:系统日志是不会出错的,只需要在后面追加。所以日志结构就代指追加型结构。
**实现原理:**把磁盘看做一个日志,在日志中存放永久性数据及其索引,每次都添加到日志的末尾。文件传输(存取)大多是顺序的,提高磁盘带宽利用率。
**特点:**LSM-tree是专门为key-value存储系统设计的,主要业务是查找和插入。LSM的特点是利用磁盘的顺序写,写入速度比随机写入的B-树更快。
**层次结构:**LSM-tree是由两个或两个以上存储数据的结构组成的。最简单的LSM-tree由两个部件构成。一个部件常驻内存,称为C0树(或C0),可以为任何方便键值查找的数据结构,另一个部件常驻硬盘之中,称为C1树(或C1),其数据结构与B-tree类似。C1的结构与B-tree相似,但其结点中的条目是满的,结点的大小为一页,树根之下的 所有单页结点合并到地址连续的多页块中。
内部数据结构:
LSM树包含三部分:Memtable,Immutable,SSTable。
MemTable是内存中的数据结构,往往是一个跳表(Skip List)组织的有序数据结构。用于保存最近产生的数据,并按照Key有序地组织数据。内存并不是可靠存储,若断电就会丢失数据,因此通常会使用预写式日志(Write-ahead logging,WAL)的方式来保证数据的可靠性。
SSTable一般由一组数据block和一组元数据block组成。元数据block存储了SSTable数据block的描述信息,如索引、BloomFilter、压缩、统计等信息。因为SSTable是不可更改的,且是有序的,索引往往采用二分法数组结构就可以了。
增删改查
DBLSM-tree文件在内存中有两种:不可修改的immutable table,可修改的,正常用于写入的memtable,
磁盘上:存放有序字节组的表SStable(Sorted String Table),存储数据的key。
SStable 一共有七层(L0 到 L6),大小十倍递增。
SStable一旦写入磁盘就不能修改,(这就是Log-Structured Merge Tree名字中Log-Structured一词的由来)。
当要修改现有数据时,LSM Tree并不直接修改旧数据,而是直接将新数据写入新的SSTable中。
删除数据时,LSM Tree也不直接删除旧数据,而是写一个相应数据的删除标记的记录到一个新的SSTable中。
这样一来,LSM Tree写数据时对磁盘的操作都是顺序块写入操作,而没有随机写操作。
源码解析
由于influxDB是golang实现的,所以确保本地的golang环境是正常的,比如goroot,gopath这些都是正常配置。
然后到github上拉取代码:influxDB源码
编译
go mod tidy
go get ./…
go install
执行成功之后,在$GOPATH/bin下面,就会出现influxd,influx等相关二进制文件。可以直接执行。
IDE调试
在上述编译通过之后,可以打开IDE(Goland),直接在IDE里面启动。influxDB的服务端在cmd/influxd/main.go文件,
直接右键debug模式启动。
服务启动
在cmd/influxd/main.go中,main函数:
func main() {
rand.Seed(time.Now().UnixNano())
m := NewMain()
if err := m.Run(os.Args[1:]...); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
构建了一下Command结构,调用了Command的Run函数:
if err := cmd.Run(args...); err != nil {
return fmt.Errorf("run: %s", err)
}
构建Server结构,并且启动:
buildInfo := &BuildInfo{
Version: cmd.Version,
Commit: cmd.Commit,
Branch: cmd.Branch,
Time: cmd.BuildTime,
}
s, err := NewServer(config, buildInfo)
if err != nil {
return fmt.Errorf("create server: %s", err)
}
s.Logger = cmd.Logger
s.CPUProfile = options.CPUProfile
s.MemProfile = options.MemProfile
if err := s.Open(); err != nil {
return fmt.Errorf("open server: %s", err)
}
这里有一个重要的结构:Server它是服务端的抽象。定义在cmd/influxd/run/server.go中。一个Server主要有以下这些结构:
MetaClient:meta 信息的访问抽象。meta信息主要包括RetentionPolicy,ContinuousQueryInfo,UserInfo,ShardInfo,ShardGroupInfo等。metaClient提供了对这些信息增删改查的接口。
TSDBStore:时序存储的抽象。提供了对所有的database,所有的shard的读写功能。可以理解为存储的核心
QueryExecutor:查询执行器。用来执行用户的查询请求,这些查询都被看作为statement。
PointWrite: point 写入抽象。时序数据都看做一个个数据点,所以叫做point。那么这里为什么是被单独作为一个模块出现,而不是集成到TSDBStore里面呢?原因是influxdb不仅仅支持自己独有的行协议(line protocol),还支持其他协议,例如openTSDB等,这里可以看做是一个统一的点写入接口。可以拓展。
[]Service,这里是一个数组。表示多种service。influxdb把一些不是存储查询相关的功能,大部分都定义为Service。类似插件一样集成到系统内部。例如支持http写入的HTTDService,支持
SnapshotterService 支持snapshot的服务。
除了这些关键的成员,还有一些其他的,例如绑定的端口信息,profile信息等。
type Server struct {
buildInfo BuildInfo
err chan error
closing chan struct{}
BindAddress string
Listener net.Listener
Logger *zap.Logger
MetaClient *meta.Client
TSDBStore *tsdb.Store
QueryExecutor *query.Executor
PointsWriter *coordinator.PointsWriter
Subscriber *subscriber.Service
Services []Service
// These references are required for the tcp muxer.
SnapshotterService *snapshotter.Service
Monitor *monitor.Monitor
// Server reporting and registration
reportingDisabled bool
// Profiling
CPUProfile string
CPUProfileWriteCloser io.WriteCloser
MemProfile string
MemProfileWriteCloser io.WriteCloser
// httpAPIAddr is the host:port combination for the main HTTP API for querying and writing data
httpAPIAddr string
// httpUseTLS specifies if we should use a TLS connection to the http servers
httpUseTLS bool
// tcpAddr is the host:port combination for the TCP listener that services mux onto
tcpAddr string
config *Config
}
Server 启动
server构建完成之后,就是启动Server,这里调用的是Open函数。在Open函数里,会开始装配[]Service数组,来确定开启哪些服务:
s.appendMonitorService()
s.appendPrecreatorService(s.config.Precreator)
s.appendSnapshotterService()
s.appendContinuousQueryService(s.config.ContinuousQuery)
s.appendHTTPDService(s.config.HTTPD)
s.appendRetentionPolicyService(s.config.Retention)
for _, i := range s.config.GraphiteInputs {
if err := s.appendGraphiteService(i); err != nil {
return err
}
}
for _, i := range s.config.CollectdInputs {
s.appendCollectdService(i)
}
for _, i := range s.config.OpenTSDBInputs {
if err := s.appendOpenTSDBService(i); err != nil {
return err
}
}
for _, i := range s.config.UDPInputs {
s.appendUDPService(i)
}
以及一些依赖的赋值:
s.Subscriber.MetaClient = s.MetaClient
s.PointsWriter.MetaClient = s.MetaClient
s.Monitor.MetaClient = s.MetaClient
s.SnapshotterService.Listener = mux.Listen(snapshotter.MuxHeader)
这里比如pointWriter也是依赖了metaClient的,因为pointWriter写入每个点的时候,需要知道写到哪个shard上,所以需要知道shard相关的信息,而shard相关的信息是metaClient提供的,所以这里会对内部的一些依赖赋值。
完成赋值之后,会开始启动内部的组件。
if err := s.TSDBStore.Open(); err != nil {
return fmt.Errorf("open tsdb store: %s", err)
}
// Open the subscriber service
if err := s.Subscriber.Open(); err != nil {
return fmt.Errorf("open subscriber: %s", err)
}
// Open the points writer service
if err := s.PointsWriter.Open(); err != nil {
return fmt.Errorf("open points writer: %s", err)
}
s.PointsWriter.AddWriteSubscriber(s.Subscriber.Points())
for _, service := range s.Services {
if err := service.Open(); err != nil {
return fmt.Errorf("open service: %s", err)
}
}
meta
meta,data,wal是几个比较重要的模块。
在上面看到了influxdb在启动的时候,装配server模型,然后启动server。其中依赖了metaClient
主要分析databaseinfo,retention policy,shardgroup,shard等结构的元数据信息。这些信息被定义在influxdb/services/meta中
其中client.go提供了对这些信息统一的增删改查接口。data.go定义了这些结构的真正操作。
internal下面是一些内部信息,用于序列化和反序列化的。
Meta都有哪些:
type Data struct {
Term uint64 // associated raft term
Index uint64 // associated raft index
ClusterID uint64
Databases []DatabaseInfo
Users []UserInfo
// adminUserExists provides a constant time mechanism for determining
// if there is at least one admin user.
adminUserExists bool
MaxShardGroupID uint64
MaxShardID uint64
}
Databases:保存了influxdb所有和数据库相关的信息,例如retention policy,continousQuery等
Users: users 保存了用户相关的信息。
Term和Index是和raft term相关的,因为influxdb集群版其实是没有开放的,这里侧面证明了,influxdb 集群版中实现副本共识用的是raft算法,在开源的时候,其实有一些部分没有删除干净。
在上面的两个结构中,UserInfo不是重点关心的,主要看一下Datatases。

Shard
只有一个id,也就是shardId另外一个字段是Owners,表示shard对应的node。
type ShardInfo struct {
ID uint64
Owners []ShardOwner
}
//ShardOwner的结构也很简单
type ShardOwner struct {
NodeID uint64
}
Shard group
shardGroup的元数据信息:
shardGroup的一组shard,shardGroup的id,全局唯一递增的id;StartTime和EndTime表示这个shardGroup的开始和结束时间。
type ShardGroupInfo struct {
ID uint64
StartTime time.Time
EndTime time.Time
DeletedAt time.Time
Shards []ShardInfo
TruncatedAt time.Time
}
在创建一个retention policy时,可以指定这个retention policy对应的shard duration,这个参数决定了一个shard group的范围。
举个例子:
CREATE RETENTION POLICY keep_one_week ON test2 DURATION 2w REPLICATION 1 SHARD DURATION 1w
这里表示创建的这个retention policy 过期时间是2 week,每1 week创建一个shard group。
当系统运行一段时间之后,系统的内部是这个样子:

第[1,7]天创建的shard,都位于shard group 1内,第[8,14]天创建的shard,都在shard group 2内。
其实shard group是从时间上,对shard做一个逻辑上的分组注意这里说的是逻辑上,shard group只是一个逻辑概念,在存储的时候,这些shard是平铺开的,并不是一个shard group的shard 存储在一起。
ShardGroup的创建
shardGroup的创建是一种预先创建的模式。在influxdb/services/precreator/service.go中,有一个定时轮询的goroutine
func (s *Service) runPrecreation() {
defer s.wg.Done()
for {
select {
case <-time.After(s.checkInterval):
if err := s.precreate(time.Now().UTC()); err != nil {
s.Logger.Info("Failed to precreate shards", zap.Error(err))
}
case <-s.done:
s.Logger.Info("Terminating precreation service")
return
}
}
}
func (s *Service) precreate(now time.Time) error {
cutoff := now.Add(s.advancePeriod).UTC()
return s.MetaClient.PrecreateShardGroups(now, cutoff)
}
这里会定时的检查,是不是需要预先创建一些东西,创建shardGroup的逻辑就这里。
PrecreateShardGroups的实现在influxdb/services/meta/client.go中。
func (c *Client) PrecreateShardGroups(from, to time.Time) error {
c.mu.Lock()
defer c.mu.Unlock()
data := c.cacheData.Clone()
var changed bool
for _, di := range data.Databases {
for _, rp := range di.RetentionPolicies {
if len(rp.ShardGroups) == 0 {
// No data was ever written to this group, or all groups have been deleted.
continue
}
g := rp.ShardGroups[len(rp.ShardGroups)-1] // Get the last group in time.
if !g.Deleted() && g.EndTime.Before(to) && g.EndTime.After(from) {
// Group is not deleted, will end before the future time, but is still yet to expire.
// This last check is important, so the system doesn't create shards groups wholly
// in the past.
// Create successive shard group.
nextShardGroupTime := g.EndTime.Add(1 * time.Nanosecond)
// if it already exists, continue
if sg, _ := data.ShardGroupByTimestamp(di.Name, rp.Name, nextShardGroupTime); sg != nil {
c.logger.Info("Shard group already exists",
logger.ShardGroup(sg.ID),
logger.Database(di.Name),
logger.RetentionPolicy(rp.Name))
continue
}
newGroup, err := createShardGroup(data, di.Name, rp.Name, nextShardGroupTime)
if err != nil {
c.logger.Info("Failed to precreate successive shard group",
zap.Uint64("group_id", g.ID), zap.Error(err))
continue
}
changed = true
c.logger.Info("New shard group successfully precreated",
logger.ShardGroup(newGroup.ID),
logger.Database(di.Name),
logger.RetentionPolicy(rp.Name))
}
}
}
if changed {
if err := c.commit(data); err != nil {
return err
}
}
return nil
}
第7,8两行,是遍历所有的database,以及database下面的retention policy。这个在上面的结构分析也能看出来,shardgroup是位于这些结构之下的。然后13,14行是在取出来最后一个shardGroup,来检查,当前的时间是不是被最后一个shardGroup覆盖了。注意这里很重要,说明shardgroup数组,是按照结束时间升序排序了的,这个在后面也能看出来。
如果最后一个shardgroup的时间,是没有覆盖住当前的时间(这个当前的时间,指的是now-now+advandance,可以在上面看到)。那么开始创建。
第20行计算了下一个shardgroup的开始时间,这里是通过上一个shardgroup的结束时间+1,说明shardgroup的时间是完全连续的。
第29行开始真正创建shardGroup
createShardGroup里面有进行了一次校验,然后委托给了data结构的CreateShardGroup注意,到这里,逻辑还是在client.go里面。
func createShardGroup(data *Data, database, policy string, timestamp time.Time) (*ShardGroupInfo, error) {
// It is the responsibility of the caller to check if it exists before calling this method.
if sg, _ := data.ShardGroupByTimestamp(database, policy, timestamp); sg != nil {
return nil, ErrShardGroupExists
}
if err := data.CreateShardGroup(database, policy, timestamp); err != nil {
return nil, err
}
rpi, err := data.RetentionPolicy(database, policy)
if err != nil {
return nil, err
} else if rpi == nil {
return nil, errors.New("retention policy deleted after shard group created")
}
sgi := rpi.ShardGroupByTimestamp(timestamp)
return sgi, nil
}
进入data.CreateShardGroup,这里开始创建shardgroup
//CreateShardGroup creates a shard group on a database and policy for a given timestamp.
func (data *Data) CreateShardGroup(database, policy string, timestamp time.Time) error {
// Find retention policy.
rpi, err := data.RetentionPolicy(database, policy)
if err != nil {
return err
} else if rpi == nil {
return influxdb.ErrRetentionPolicyNotFound(policy)
}
// Verify that shard group doesn't already exist for this timestamp.
if rpi.ShardGroupByTimestamp(timestamp) != nil {
return nil
}
// Create the shard group.
data.MaxShardGroupID++
sgi := ShardGroupInfo{}
sgi.ID = data.MaxShardGroupID
// 这里是对齐到duration
sgi.StartTime = timestamp.Truncate(rpi.ShardGroupDuration).UTC()
sgi.EndTime = sgi.StartTime.Add(rpi.ShardGroupDuration).UTC()
if sgi.EndTime.After(time.Unix(0, models.MaxNanoTime)) {
// Shard group range is [start, end) so add one to the max time.
sgi.EndTime = time.Unix(0, models.MaxNanoTime+1)
}
data.MaxShardID++
sgi.Shards = []ShardInfo{
{ID: data.MaxShardID},
}
// Retention policy has a new shard group, so update the policy. Shard
// Groups must be stored in sorted order, as other parts of the system
// assume this to be the case.
rpi.ShardGroups = append(rpi.ShardGroups, sgi)
// 这里是强制转换,差点没看明白
sort.Sort(ShardGroupInfos(rpi.ShardGroups))
return nil
}
前面15行是一些基本参数的校验,直接跳过。
17行更新了maxShardGroupId,18行新建了shardGroup结构。
重点在21-22行,这里其实是做了一个时间的对齐。timestamp参数是上面传下来的上一个shardgroup的endtime+1,这会把shardGroup 的开始时间,对齐到小于等于timestamp时间的并且是shard duration倍数最大的那个数。这里似乎说的有点奇怪,其实就是向下取整。
第40行,给shardgroup做了个排序,排序的规则刚才已经说了。具体的规则可以参考shardGroup的Less函数。
func (a ShardGroupInfos) Less(i, j int) bool {
iEnd := a[i].EndTime
if a[i].Truncated() {
iEnd = a[i].TruncatedAt
}
jEnd := a[j].EndTime
if a[j].Truncated() {
jEnd = a[j].TruncatedAt
}
if iEnd.Equal(jEnd) {
return a[i].StartTime.Before(a[j].StartTime)
}
return iEnd.Before(jEnd)
}
到这里一个shardgroup算是创建完了。
小结
-
预先创建shardgroup,避免临时创建
-
client.go的所有操作,都会委托到data.go里面执行。边界和职责很清晰。
-
shardgroup的时间是完全连续的,并且开始和结束时间都是shard duration的倍数。按照shard duration对齐。
关于shardGroup还有一个重要的函数:
这个函数在写入的时候是十分重要的,用来选择某个point到底写入那个shard。
其中入参hash是point的hash值。这里就是直接使用取模选取。
func (sgi *ShardGroupInfo) ShardFor(hash uint64) ShardInfo {
return sgi.Shards[hash%uint64(len(sgi.Shards))]
}
RetentionPolicy
retention policy除了刚才介绍的shardGroups,就是Duration和ShardGroupDuration,这两个参数在之前也介绍过了,不再赘述。ReplicaN表示副本数量,这个在集群版有用。
type RetentionPolicyInfo struct {
Name string
ReplicaN int
Duration time.Duration
ShardGroupDuration time.Duration // shardGroup的切分时长
ShardGroups []ShardGroupInfo // 所有的shardGroup
Subscriptions []SubscriptionInfo
}
主要的函数:
这个函数式通过timestamp来寻找具体的shardgroup,这个函数在写入point的时候,需要确定当前的point位于那个shardgroup里面。这里有个细节,由于shardgroup是按照时间排序的,这里顺序遍历,所以point会被写入第一个满足条件的shardgroup,也就是时间最小的那个
func (rpi *RetentionPolicyInfo) ShardGroupByTimestamp(timestamp time.Time) *ShardGroupInfo {
for i := range rpi.ShardGroups {
sgi := &rpi.ShardGroups[i]
if sgi.Contains(timestamp) && !sgi.Deleted() && (!sgi.Truncated() || timestamp.Before(sgi.TruncatedAt)) {
return &rpi.ShardGroups[i]
}
}
return nil
}
DatabaseInfo
最后来到了顶层的结构:DatabaseInfo
这个结构除了刚才介绍的retention policy,还有就是cq, databaseInfo结果是进一步的封装,把底层相关信息的接口给封装一下。
type DatabaseInfo struct {
Name string
DefaultRetentionPolicy string
RetentionPolicies []RetentionPolicyInfo
ContinuousQueries []ContinuousQueryInfo
}
Data
数据写入
数据写入的基本流程:从一个http的请求解析数据,然后计算shardgroup,shard等元数据信息,最后写入到具体的shard上。
influxdb 默认的存储路径是**${PWD}/.influxdata**在这个目录下执行。
tree -L 3
HTTP路由
influxdb启动之后,会监听8086端口,然后提供http服务。在influxdb/influxd/run/server.go中,cmd/influxd/run/server.go:378 open函数,表示了server启动之后,装配哪些service。其中有一个service是appendHTTPDService
s.appendHTTPDService(s.config.HTTPD)
s.appendRetentionPolicyService(s.config.Retention)
// httpd.NewService,通过http.config 新建了一个http service,看一下NewService的逻辑
func (s *Server) appendHTTPDService(c httpd.Config) {
if !c.Enabled {
return
}
srv := httpd.NewService(c)
srv.Handler.MetaClient = s.MetaClient
authorizer := meta.NewQueryAuthorizer(s.MetaClient)
srv.Handler.QueryAuthorizer = authorizer
srv.Handler.WriteAuthorizer = meta.NewWriteAuthorizer(s.MetaClient)
srv.Handler.QueryExecutor = s.QueryExecutor
srv.Handler.Monitor = s.Monitor
srv.Handler.PointsWriter = s.PointsWriter
srv.Handler.Version = s.buildInfo.Version
srv.Handler.BuildType = "OSS"
ss := storage.NewStore(s.TSDBStore, s.MetaClient)
srv.Handler.Store = ss
if s.config.HTTPD.FluxEnabled {
srv.Handler.Controller = control.NewController(s.MetaClient, reads.NewReader(ss), authorizer, c.AuthEnabled, s.Logger)
}
s.Services = append(s.Services, srv)
}
//一些基本信息的装配,这里主要注意一下Handler字段的赋值,一般在web开发中,Handler都是用来处理用户的http请求的,这里也不例外。在NewHandler中,定义了路由参数:
func NewService(c Config) *Service {
s := &Service{
addr: c.BindAddress,
https: c.HTTPSEnabled,
cert: c.HTTPSCertificate,
key: c.HTTPSPrivateKey,
limit: c.MaxConnectionLimit,
tlsConfig: c.TLS,
err: make(chan error),
unixSocket: c.UnixSocketEnabled,
unixSocketPerm: uint32(c.UnixSocketPermissions),
bindSocket: c.BindSocket,
Handler: NewHandler(c),
Logger: zap.NewNop(),
}
if s.tlsConfig == nil {
s.tlsConfig = new(tls.Config)
}
if s.key == "" {
s.key = s.cert
}
if c.UnixSocketGroup != nil {
s.unixSocketGroup = int(*c.UnixSocketGroup)
}
s.Handler.Logger = s.Logger
return s
}
// 通过http 写入和查询的入口所在,所有的请求都是从这里开始
h.AddRoutes([]Route{
Route{
"query-options", // Satisfy CORS checks.
"OPTIONS", "/query", false, true, h.serveOptions,
},
Route{
"query", // Query serving route.
"GET", "/query", true, true, h.serveQuery,
},
Route{
"query", // Query serving route.
"POST", "/query", true, true, h.serveQuery,
},
Route{
"write-options", // Satisfy CORS checks.
"OPTIONS", "/write", false, true, h.serveOptions,
},
Route{
"write", // Data-ingest route.
"POST", "/write", true, writeLogEnabled, h.serveWriteV1,
},
Route{
"write", // Data-ingest route.
"POST", "/api/v2/write", true, writeLogEnabled, h.serveWriteV2,
},
Route{
"prometheus-write", // Prometheus remote write
"POST", "/api/v1/prom/write", false, true, h.servePromWrite,
},
Route{
"prometheus-read", // Prometheus remote read
"POST", "/api/v1/prom/read", true, true, h.servePromRead,
},
Route{ // Ping
"ping",
"GET", "/ping", false, true, authWrapper(h.servePing),
},
Route{ // Ping
"ping-head",
"HEAD", "/ping", false, true, authWrapper(h.servePing),
},
Route{ // Ping w/ status
"status",
"GET", "/status", false, true, authWrapper(h.serveStatus),
},
Route{ // Ping w/ status
"status-head",
"HEAD", "/status", false, true, authWrapper(h.serveStatus),
},
Route{ // Ping
"ping",
"GET", "/health", false, true, authWrapper(h.serveHealth),
},
Route{
"prometheus-metrics",
"GET", "/metrics", false, true, authWrapper(promhttp.Handler().ServeHTTP),
},
}...)
从上面找到了http的路由定义之后,先看一下写入的逻辑:
写入有两个版本,对应两个处理函数,这里先看serveWriteV1:
func (h *Handler) serveWriteV1(w http.ResponseWriter, r *http.Request, user meta.User) {
precision := r.URL.Query().Get("precision")
switch precision {
case "", "n", "ns", "u", "ms", "s", "m", "h":
// it's valid
default:
err := fmt.Sprintf("invalid precision %q (use n, u, ms, s, m or h)", precision)
h.httpError(w, err, http.StatusBadRequest)
}
db := r.URL.Query().Get("db")
rp := r.URL.Query().Get("rp")
h.serveWrite(db, rp, precision, w, r, user)
}
serviceWriteV1做了一下基本参数的校验,然后委托给了serveWrite
serveWrite主要分为以下步骤
- 参数校验
- http payload 信息读取
- point的反序列化
- point写入到本地
- 写入结果处理
- 返回
写入influxdb的数据都是要遵循influxdb的协议的,influxdb使用这个协议来对数据反序列化,这个协议也叫行协议(line protocol)。
具体的协议内容:influxdb 行协议
#weather是measurement,location=us-midwest,season=summer 是tag,temperature=82是field,
#1465839830100400200是timestamp
weather,location=us-midwest,season=summer temperature=82 1465839830100400200
measurement[,tagk=tagv] fieldkey=fieldv[,fieldkey2=fieldv2] timestamp
其实反序列化,就是按照行协议,把byte数组给反序列出来。这部分逻辑在ParsePointsWithPrecision和parsePoint里面
通过http写入的数据完成了解析,得到了一个point的数组
解析到的点通过pointsWriterWithContext的WritePointsWithContext完成写入
pointsWriterWithContext是一个interface,真正的实现在PointsWriter
PointsWriter是位于coordinator模块下面的一个结构,用来接受点的写入,有多种协议的实现。
PointsWriter实现了WritePointsWithContext,并且委托给了WritePointsPrivilegedWithContext执行
参考:
数据写入
数据写入详细
Series
https://blog.csdn.net/weixin_41863129/article/details/124369726
Index
Inmem Index
inmem 的index是启动默认的,比较简单,不支持持久化。为了解决这个问题,influxdb在tsi index里面,对index做了非常详细的设计,支持持久化,倒排索引等。
https://blog.csdn.net/weixin_41863129/article/details/124521131
tsi index
https://blog.csdn.net/weixin_41863129/article/details/124521131
tsi index的重要组成部分:cache,wal,SSTable等。index是一个database粒度的,这里对index也做了下分段,上层抽象了Partition结构,Index包含多个partition,每个partition 包含一部分index。
Store
Store结构在influxdb中是一个存储层的抽象。这是一个全局的概念,所有的database,retention policy,shard都会被一个store管理。具体的结构定义在了tsdb/store.go中。
store是存储和查询的总抽象,代理了所有shard,series,index等信息。
shard结构虽然从属于database+retention policy的,但是在store中是打平的。
series,index是database级别的概念,在整个database里面是共享的。
https://blog.csdn.net/weixin_41863129/article/details/124556720
Shard
Store是数据库核心功能的一个总体抽象。里面包含了其他核心组件,例如Shard,series,index等。本篇文章分析的是Shard结构。
Shard是一个物理的概念,在存储时,最小的存储粒度就是Shard。Shard封装了单个分片的存储查询功能。这个结构定义在tsdb/shard.go中
Engine
Engine是shard的存储引擎,负责读写数据用的。和大多数结构一样,为了能够更好地拓展,Engine也定义了一个顶层的抽象,在tsdb/engine.go中。
TSM Engine Cache
TSM Engine是influxdb实现的一个存储时序数据的存储引擎,结构的定义在tsdb/engine/tsm1/engine.go 这个结构的字段很多
只关心核心逻辑:
type Engine struct {
mu sync.RWMutex
index tsdb.Index
id uint64
path string
sfile *tsdb.SeriesFile
fieldset *tsdb.MeasurementFieldSet
WAL *WAL
Cache *Cache
Compactor *Compactor
CompactionPlan CompactionPlanner
FileStore *FileStore
}
这个结构主要分为三部分
- index 和series 信息。database 粒度的
- id,path,fieldSet 基本信息
- WAL,Cache,Compactor,FileStore TSM 相关。
https://blog.csdn.net/weixin_41863129/article/details/124558988
TSM Engine WAL
WAL是(Write Ahead Log)的缩写,翻译过来叫做预写日志,是一种保证数据可靠性的方案。一般写入数据时,会先写入WAL,然后再更新本地的数据。当数据被持久化到真正用于存储它的文件上(SSTable),WAL就会被删除。
https://blog.csdn.net/weixin_41863129/article/details/124559974
安装使用
安装
下载连接
winds版:
下载解压之后,直接双击Influx.exe 即可启动
然后另外开一个窗口,作为客户端连接:执行influx.exe 即可连接成功。
执行命令的时候你需要进入当前目录,否则可能会找不到你的这个命令,如果想一劳永逸把这个目录写到环境变量里面即可。
mac版:
brew update
brew install influxdb
brew services start influxdb
命令
数据库操作
create database db_name
show databases
drop database db_name
-- 查看所有的数据库
show databases;
-- 使用特定的数据库
use database_name;
-- 查看所有的measurement
show measurements;
-- 查询10条数据
select * from measurement_name limit 10;
-- 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式
precision rfc3339; -- 之后再查询,时间就是rfc3339标准格式
-- 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339
-- 查看一个measurement中所有的tag key
show tag keys
-- 查看一个measurement中所有的field key
show field keys
-- 查看一个measurement中所有的保存策略(可以有多个,一个标识为default)
show retention policies;
#查看表
use db_name;show measurements;
#查看db序列列表
use db_name; show series;
show series from status_detail where time >= '2023-06-10T16:00:00Z' and time <= '2023-06-16T16:17:57Z'
#查看db序列总数
SHOW SERIES EXACT CARDINALITY ON db_name
# ==================数据库策略操作==================
show retention policies on device_ea
# ===创建===
CREATE RETENTION POLICY <retention_policy_name> ON <database_name>
DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
# 为monitor库创建一个数据保留时长30天的rp,同时设置shard duration为1d,副本为1,并设置为默认rp
create retention policy rp_30_days on monitor duration 30d replication 1 shard duration 1d default
# 为monitor库创建一个数据保留时长一个星期的rp,副本为1
create retention policy rp_one_week on monitor duration 1w replication 1
# ===修改===
# 修改rp_1_week 保留数据时长为15days
alter retention policy rp_1_week on monitor duration 15d replication 1 default
# 设置rp_30_days为默认rp
alter retention policy rp_30_days on monitor default
# ===删除===
# 删除名为rp_1_week的rp
drop retention policy rp_1_week on monitor
新增查询操作
# ==================新增操作==================
# 在没有use 哪个db的时候需要指定db,选择monitor数据库,指定rp为rp_3_days写入数据到service_qps
insert into monitor.rp_3_days service_qps,svrName=TaskSvr,hostName=dev4 qps=12.9
# 切换选择monitor
use monitor
# 并指定rp为rp_3_days写入数据到service_qps
insert into rp_3_days service_qps,svrName=TaskSvr,hostName=dev4 qps=12.9
# 【完全错误的写法】
insert rp_3_days.service_qps,svrName=TaskSvr,hostName=dev4 qps=12.9
# ==================查询操作==================
# 默认指定默认RP
select * from "xxx"."xxxx"."alarm_history"
# 手动指定RP查询
select * from "xxx"."xxxx"."alarm_history"
# 范围查询
select tag_code, id, code from "xxx"."xxxx"."alarm_history" where time >= '2023-06-10T16:00:00Z' and time <= '2023-06-16T16:17:57Z'
# 区域条件查询
select * from "xxx"."xxxx"."alarm_history" where time >= '2023-10-01T04:00:00Z' and time <= '2023-10-20T04:00:00Z' and device_code = '868274069732776' and dev_code = '46902590000002' and (province_id=~/^462500|460400$/ or city_id=~/^462500|460400$/ or county_id=~/^462500|460400|469025$/) and (province_id=~/^462500|460400$/ or city_id=~/^462500|460400$/ or county_id=~/^462500|460400|469025$/) limit 10 offset 0
#==================查询统计==================
====count函数====
根据device_code统计告警次数
select count(alarm_name) as count from "xxx"."xxx"."alarm_history" where time >= '2023-10-01T04:00:00Z' and time <= '2023-10-20T04:00:00Z' and mid='105' group by device_code
====top函数====
select top("alarmNum",50) from
from "xxx"."xxx"."alarm_history"
where time >= '2023-10-01T04:00:00Z' and time <= '2023-10-20T04:00:00Z' and id='200'
配置详解
官方介绍:https://docs.influxdata.com/influxdb/v1.2/administration/config/
InfluxDB 的数据存储主要有三个目录。默认情况下是 meta, wal 以及 data 三个目录,服务器运行后会自动生成。
- meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
- wal 目录存放预写日志文件,以 .wal 结尾。
- data 目录存放实际存储的数据文件,以 .tsm 结尾。
#全局配置
reporting-disabled = false # 该选项用于上报influxdb的使用信息给InfluxData公司,默认值为false
bind-address = ":8088" # 备份恢复时使用,默认值为8088
#meta相关配置
[meta]
dir = "/var/lib/influxdb/meta" # meta数据存放目录
retention-autocreate = true #用于控制默认存储策略,数据库创建时,会自动生成autogen的存储策略,默认值:true
logging-enabled = true # 是否开启meta日志,默认值:true
#data相关配置
[data]
dir = "/var/lib/influxdb/data" # 最终数据(TSM文件)存储目录
wal-dir = "/var/lib/influxdb/wal" # 预写日志存储目录
query-log-enabled = true # 是否开启tsm引擎查询日志,默认值: true
cache-max-memory-size = 1048576000 # 用于限定shard最大值,大于该值时会拒绝写入,默认值:1000MB,单位:byte
cache-snapshot-memory-size = 26214400 # 用于设置快照大小,大于该值时数据会刷新到tsm文件,默认值:25MB,单位:byte
cache-snapshot-write-cold-duration = "10m" # tsm引擎 snapshot写盘延迟,默认值:10Minute
compact-full-write-cold-duration = "4h" # tsm文件在压缩前可以存储的最大时间,默认值:4Hour
max-series-per-database = 1000000 # 限制数据库的级数,该值为0时取消限制,默认值:1000000
max-values-per-tag = 100000 # 一个tag最大的value数,0取消限制,默认值:100000
#coordinator查询管理的配置选项
[coordinator]
write-timeout = "10s" # 写操作超时时间,默认值: 10s
max-concurrent-queries = 0 # 最大并发查询数,0无限制,默认值: 0
query-timeout = "0s # 查询操作超时时间,0无限制,默认值:0s
log-queries-after = "0s" # 慢查询超时时间,0无限制,默认值:0s
max-select-point = 0 # SELECT语句可以处理的最大点数(points),0无限制,默认值:0
max-select-series = 0 # SELECT语句可以处理的最大级数(series),0无限制,默认值:0
max-select-buckets = 0 # SELECT语句可以处理的最大"GROUP BY time()"的时间周期,0无限制,默认值:0
#retention旧数据的保留策略
[retention]
enabled = true # 是否启用该模块,默认值 : true
check-interval = "30m" # 检查时间间隔,默认值 :"30m"
#shard-precreation分区预创建
[shard-precreation]
enabled = true # 是否启用该模块,默认值 : true
check-interval = "10m" # 检查时间间隔,默认值 :"10m"
advance-period = "30m" # 预创建分区的最大提前时间,默认值 :"30m"
#monitor 控制InfluxDB自有的监控系统。 默认情况下,InfluxDB把这些数据写入_internal 数据库,如果这个库不存在则自动创建。 _internal 库默认的retention策略是7天,如果你想使用一个自己的retention策略,需要自己创建。
[monitor]
store-enabled = true # 是否启用该模块,默认值 :true
store-database = "_internal" # 默认数据库:"_internal"
store-interval = "10s # 统计间隔,默认值:"10s"
#admin web管理页面
[admin]
enabled = true # 是否启用该模块,默认值 : false
bind-address = ":8083" # 绑定地址,默认值 :":8083"
https-enabled = false # 是否开启https ,默认值 :false
https-certificate = "/etc/ssl/influxdb.pem" # https证书路径,默值:"/etc/ssl/influxdb.pem"
#http API
[http]
enabled = true # 是否启用该模块,默认值 :true
bind-address = ":8086" # 绑定地址,默认值:":8086"
auth-enabled = false # 是否开启认证,默认值:false
realm = "InfluxDB" # 配置JWT realm,默认值: "InfluxDB"
log-enabled = true # 是否开启日志,默认值:true
write-tracing = false # 是否开启写操作日志,如果置成true,每一次写操作都会打日志,默认值:false
pprof-enabled = true # 是否开启pprof,默认值:true
https-enabled = false # 是否开启https,默认值:false
https-certificate = "/etc/ssl/influxdb.pem" # 设置https证书路径,默认值:"/etc/ssl/influxdb.pem"
https-private-key = "" # 设置https私钥,无默认值
shared-secret = "" # 用于JWT签名的共享密钥,无默认值
max-row-limit = 0 # 配置查询返回最大行数,0无限制,默认值:0
max-connection-limit = 0 # 配置最大连接数,0无限制,默认值:0
unix-socket-enabled = false # 是否使用unix-socket,默认值:false
bind-socket = "/var/run/influxdb.sock" # unix-socket路径,默认值:"/var/run/influxdb.sock"
#subscriber 控制Kapacitor接受数据的配置
[subscriber]
enabled = true # 是否启用该模块,默认值 :true
http-timeout = "30s" # http超时时间,默认值:"30s"
insecure-skip-verify = false # 是否允许不安全的证书
ca-certs = "" # 设置CA证书
write-concurrency = 40 # 设置并发数目,默认值:40
write-buffer-size = 1000 # 设置buffer大小,默认值:1000
#graphite 相关配置
[graphite]
enabled = false # 是否启用该模块,默认值 :false
database = "graphite" # 数据库名称,默认值:"graphite"
retention-policy = "" # 存储策略,无默认值
bind-address = ":2003" # 绑定地址,默认值:":2003"
protocol = "tcp" # 协议,默认值:"tcp"
consistency-level = "one" # 一致性级别,默认值:"one
batch-size = 5000 # 批量size,默认值:5000
batch-pending = 10 # 配置在内存中等待的batch数,默认值:10
batch-timeout = "1s" # 超时时间,默认值:"1s"
udp-read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。 该配置的默认值:0
separator = "." # 多个measurement间的连接符,默认值: "."
#collectd
[collectd]
enabled = false # 是否启用该模块,默认值 :false
bind-address = ":25826" # 绑定地址,默认值: ":25826"
database = "collectd" # 数据库名称,默认值:"collectd"
retention-policy = "" # 存储策略,无默认值
typesdb = "/usr/local/share/collectd" # 路径,默认值:"/usr/share/collectd/types.db"
auth-file = "/etc/collectd/auth_file"
batch-size = 5000
batch-pending = 10
batch-timeout = "10s"
read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。默认值:0
#opentsdb
[opentsdb]
enabled = false # 是否启用该模块,默认值:false
bind-address = ":4242" # 绑定地址,默认值:":4242"
database = "opentsdb" # 默认数据库:"opentsdb"
retention-policy = "" # 存储策略,无默认值
consistency-level = "one" # 一致性级别,默认值:"one"
tls-enabled = false # 是否开启tls,默认值:false
certificate= "/etc/ssl/influxdb.pem" # 证书路径,默认值:"/etc/ssl/influxdb.pem"
log-point-errors = true # 出错时是否记录日志,默认值:true
batch-size = 1000
batch-pending = 5
batch-timeout = "1s"
#udp
[udp]
enabled = false # 是否启用该模块,默认值:false
bind-address = ":8089" # 绑定地址,默认值:":8089"
database = "udp" # 数据库名称,默认值:"udp"
retention-policy = "" # 存储策略,无默认值
batch-size = 5000
batch-pending = 10
batch-timeout = "1s"
read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。 该配置的默认值:0
#continuous_queries
[continuous_queries]
enabled = true # enabled 是否开启CQs,默认值:true
log-enabled = true # 是否开启日志,默认值:true
run-interval = "1s" # 时间间隔,默认值:"1s"
参考
https://blog.csdn.net/weixin_41863129/category_11251622.html
https://www.freesion.com/article/53171426136/#retention_policy_40