访问者模式在JDK以及Spring源码中的应用
行为型模式
目录
1、访问者模式(Visitor Pattern)
1.1 访问者模式UML图
1.2 日常生活中看访问者模式
1.3 Java代码实现
2、访问者模式在源码中的应用
2.1 JDK源码中访问者模式体现
2.2 Spring源码中访问者模式体现
3、访问者模式优缺点
3.1 优点
3.2 缺点
3.3 使用场景
3.4 注意事项
1、访问者模式(Visitor Pattern)
最复杂的设计模式,并且使用频率不高,《设计模式》的作者评价为:大多情况下,你不需要使用访问者模式,但是一旦需要使用它时,那就真的需要使用了。
访问者模式是一种将数据操作和数据结构分离的设计模式。(觉得太抽象,可以看下面的例子)。
在访问者模式中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随着访问者改变而改变。根据模式,元素对象已接受访问者对象,这样访问者对象就可以处理元素对象上的操作。
- 意图:主要将数据结构与数据操作分离。
- 主要解决:稳定的数据结构和易变的操作耦合问题。
- 何时使用:需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,使用访问者模式将这些封装到类中。
- 如何解决:在被访问的类里面加一个对外提供接待访问者的接口。
- 关键代码:在数据基础类里面有一个方法接受访问者,将自身引用传入访问者。
1.1 访问者模式UML图
访问者模式(Visitor),封装一些作用于某种数据结构的各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。UML结构图如下:
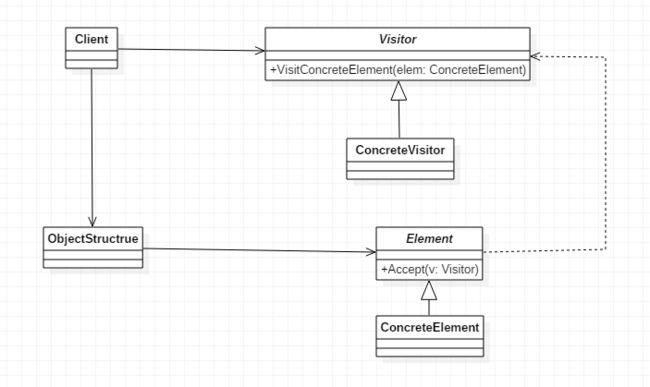
其中,Visitor是抽象访问者,为该对象结构中ConcreteElement的每一个类声明一个Visit操作;ConcreteVisitor是具体访问者,实现每个由visitor声明的操作,是每个操作实现算法的一部分,而该算法片段是对应于结构中对象的类;ObjectStructure为能枚举它的元素,可以提供一个高层的接口以允许访问者访问它的元素;Element定义了一个Accept操作,它以一个访问者为参数;ConcreteElement为具体元素,实现Accept操作。
1.2 日常生活中看访问者模式
您在朋友家做客,您是访问者,朋友接受您的访问,您通过朋友的描述,然后对朋友的描述做出一个判断,这就是访问者模式。
1.3 Java代码实现
年底,CEO和CTO开始评定员工一年的工作绩效,员工分为工程师和经理,CTO关注工程师的代码量、经理的新产品数量;CEO关注的是工程师的KPI和经理的KPI以及新产品数量。
由于CEO和CTO对于不同员工的关注点是不一样的,这就需要对不同员工类型进行不同的处理。访问者模式此时可以派上用场了。
// 员工基类
public abstract class Staff {
public String name;
public int kpi;// 员工KPI
public Staff(String name) {
this.name = name;
kpi = new Random().nextInt(10);
}
// 核心方法,接受Visitor的访问
public abstract void accept(Visitor visitor);
}Staff 类定义了员工基本信息及一个 accept 方法,accept 方法表示接受访问者的访问,由子类具体实现。Visitor 是个接口,传入不同的实现类,可访问不同的数据。下面看看工程师和经理的代码:
// 工程师
public class Engineer extends Staff {
public Engineer(String name) {
super(name);
}
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
// 工程师一年的代码数量
public int getCodeLines() {
return new Random().nextInt(10 * 10000);
}
}// 经理
public class Manager extends Staff {
public Manager(String name) {
super(name);
}
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
// 一年做的产品数量
public int getProducts() {
return new Random().nextInt(10);
}
}工程师是代码数量,经理是产品数量,他们的职责不一样,也就是因为差异性,才使得访问模式能够发挥它的作用。Staff、Engineer、Manager 3个类型就是对象结构,这些类型相对稳定,不会发生变化。
然后将这些员工添加到一个业务报表类中,公司高层可以通过该报表类的 showReport 方法查看所有员工的业绩,具体代码如下:
// 员工业务报表类
public class BusinessReport {
private List mStaffs = new LinkedList<>();
public BusinessReport() {
mStaffs.add(new Manager("经理-A"));
mStaffs.add(new Engineer("工程师-A"));
mStaffs.add(new Engineer("工程师-B"));
mStaffs.add(new Engineer("工程师-C"));
mStaffs.add(new Manager("经理-B"));
mStaffs.add(new Engineer("工程师-D"));
}
/**
* 为访问者展示报表
* @param visitor 公司高层,如CEO、CTO
*/
public void showReport(Visitor visitor) {
for (Staff staff : mStaffs) {
staff.accept(visitor);
}
}
} 下面看看 Visitor 类型的定义, Visitor 声明了两个 visit 方法,分别是对工程师和经理对访问函数,具体代码如下:
public interface Visitor {
// 访问工程师类型
void visit(Engineer engineer);
// 访问经理类型
void visit(Manager manager);
}首先定义了一个 Visitor 接口,该接口有两个 visit 函数,参数分别是 Engineer、Manager,也就是说对于 Engineer、Manager 的访问会调用两个不同的方法,以此达成区别对待、差异化处理。具体实现类为 CEOVisitor、CTOVisitor类,具体代码如下:
// CEO访问者
public class CEOVisitor implements Visitor {
@Override
public void visit(Engineer engineer) {
System.out.println("工程师: " + engineer.name + ", KPI: " + engineer.kpi);
}
@Override
public void visit(Manager manager) {
System.out.println("经理: " + manager.name + ", KPI: " + manager.kpi +
", 新产品数量: " + manager.getProducts());
}
}在CEO的访问者中,CEO关注工程师的 KPI,经理的 KPI 和新产品数量,通过两个 visitor 方法分别进行处理。如果不使用 Visitor 模式,只通过一个 visit 方法进行处理,那么就需要在这个 visit 方法中进行判断,然后分别处理,代码大致如下:
public class ReportUtil {
public void visit(Staff staff) {
if (staff instanceof Manager) {
Manager manager = (Manager) staff;
System.out.println("经理: " + manager.name + ", KPI: " + manager.kpi +
", 新产品数量: " + manager.getProducts());
} else if (staff instanceof Engineer) {
Engineer engineer = (Engineer) staff;
System.out.println("工程师: " + engineer.name + ", KPI: " + engineer.kpi);
}
}
}这就导致了 if-else 逻辑的嵌套以及类型的强制转换,难以扩展和维护,当类型较多时,这个 ReportUtil 就会很复杂。而使用 Visitor 模式,通过同一个函数对不同对元素类型进行相应对处理,使结构更加清晰、灵活性更高。
再添加一个CTO的 Visitor 类:
public class CTOVisitor implements Visitor {
@Override
public void visit(Engineer engineer) {
System.out.println("工程师: " + engineer.name + ", 代码行数: " + engineer.getCodeLines());
}
@Override
public void visit(Manager manager) {
System.out.println("经理: " + manager.name + ", 产品数量: " + manager.getProducts());
}
}重载的 visit 方法会对元素进行不同的操作,而通过注入不同的 Visitor 又可以替换掉访问者的具体实现,使得对元素的操作变得更灵活,可扩展性更高,同时也消除了类型转换、if-else 等“丑陋”的代码。
下面是客户端代码:
public class Client {
public static void main(String[] args) {
// 构建报表
BusinessReport report = new BusinessReport();
System.out.println("=========== CEO看报表 ===========");
report.showReport(new CEOVisitor());
System.out.println("=========== CTO看报表 ===========");
report.showReport(new CTOVisitor());
}
}具体输出如下:
=========== CEO看报表 ===========
经理: 经理-A, KPI: 9, 新产品数量: 0
工程师: 工程师-A, KPI: 6
工程师: 工程师-B, KPI: 6
工程师: 工程师-C, KPI: 8
经理: 经理-B, KPI: 2, 新产品数量: 6
工程师: 工程师-D, KPI: 6
=========== CTO看报表 ===========
经理: 经理-A, 产品数量: 3
工程师: 工程师-A, 代码行数: 62558
工程师: 工程师-B, 代码行数: 92965
工程师: 工程师-C, 代码行数: 58839
经理: 经理-B, 产品数量: 6
工程师: 工程师-D, 代码行数: 53125在上述示例中,Staff 扮演了 Element 角色,而 Engineer 和 Manager 都是 ConcreteElement;CEOVisitor 和 CTOVisitor 都是具体的 Visitor 对象;而 BusinessReport 就是 ObjectStructure;Client就是客户端代码。
访问者模式最大的优点就是增加访问者非常容易,我们从代码中可以看到,如果要增加一个访问者,只要新实现一个 Visitor 接口的类,从而达到数据对象与数据操作相分离的效果。如果不实用访问者模式,而又不想对不同的元素进行不同的操作,那么必定需要使用 if-else 和类型转换,这使得代码难以升级维护。
2、访问者模式在源码中的应用
2.1 JDK源码中访问者模式体现
Java 7 版本后,Files 类提供了 walkFileTree() 方法,该方法可以很容易的对目录下的所有文件进行遍历,需要 Path、FileVisitor 两个参数。其中,Path 是要遍历文件的路径,FileVisitor 则可以看成一个文件访问器。源码如下。
package java.nio.file;
public final class Files {
...
public static Path walkFileTree(Path start, FileVisitor visitor)
throws IOException
{
return walkFileTree(start,
EnumSet.noneOf(FileVisitOption.class),
Integer.MAX_VALUE,
visitor);
}
...
}FileVisitor 提供了递归遍历文件树的支持,这个接口的方法表示了遍历过程中的关键过程,允许在文件被访问、目录将被访问、目录已被访问、发生错误等过程中进行控制。换句话说,这个接口在文件被访问前、访问中和访问后,以及产生错误的时候都有相应的钩子程序进行处理。
FileVisitor 主要提供了 4 个方法,且返回结果的都是 FileVisitResult 对象值,用于决定当前操作完成后接下来该如何处理。FileVisitResult 是一个枚举类,代表返回之后的一些后续操作。源码如下。
package java.nio.file;
import java.nio.file.attribute.BasicFileAttributes;
import java.io.IOException;
public interface FileVisitor {
FileVisitResult preVisitDirectory(T dir, BasicFileAttributes attrs)
throws IOException;
FileVisitResult visitFile(T file, BasicFileAttributes attrs)
throws IOException;
FileVisitResult visitFileFailed(T file, IOException exc)
throws IOException;
FileVisitResult postVisitDirectory(T dir, IOException exc)
throws IOException;
}
package java.nio.file;
public enum FileVisitResult {
CONTINUE,
TERMINATE,
SKIP_SUBTREE,
SKIP_SIBLINGS;
} FileVisitResult 主要包含 4 个常见的操作。
- FileVisitResult.CONTINUE:这个访问结果表示当前的遍历过程将会继续。
- FileVisitResult.SKIP_SIBLINGS:这个访问结果表示当前的遍历过程将会继续,但是要忽略当前文件/目录的兄弟节点。
- FileVisitResult.SKIP_SUBTREE:这个访问结果表示当前的遍历过程将会继续,但是要忽略当前目录下的所有节点。
- FileVisitResult.TERMINATE:这个访问结果表示当前的遍历过程将会停止。
通过访问者去遍历文件树会比较方便,比如查找文件夹内符合某个条件的文件或者某一天内所创建的文件,这个类中都提供了相对应的方法。它的实现也非常简单,代码如下。
public class SimpleFileVisitor implements FileVisitor {
protected SimpleFileVisitor() {
}
@Override
public FileVisitResult preVisitDirectory(T dir, BasicFileAttributes attrs)
throws IOException
{
Objects.requireNonNull(dir);
Objects.requireNonNull(attrs);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(T file, BasicFileAttributes attrs)
throws IOException
{
Objects.requireNonNull(file);
Objects.requireNonNull(attrs);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(T file, IOException exc)
throws IOException
{
Objects.requireNonNull(file);
throw exc;
}
@Override
public FileVisitResult postVisitDirectory(T dir, IOException exc)
throws IOException
{
Objects.requireNonNull(dir);
if (exc != null)
throw exc;
return FileVisitResult.CONTINUE;
}
} 2.2 Spring源码中访问者模式体现
PropertySourcesPlaceholderConfigurer 允许我们用 Properties 文件中的属性来定义应用上下文(配置文件或者注解)
我们在 XML 配置文件(或者其他方式,如注解方式)中使用占位符的方式来定义一些资源,并将这些占位符所代表的资源配置到 Properties 中,这样只需要对 Properties 文件进行修改即可就是支持${jdbc.url}这种变量
PropertySourcesPlaceholderConfigurer要做到替换,至少需要先获取bean的属性并解析,BeanDefinitionVisitor就是对bean的属性配置信息做解析用的。BeanDefinitionVisitor用到了访问者模式。
在PropertySourcesPlaceholderConfigurer的postProcessBeanFactory(生命周期方法)方法中,调用了doProcessProperties
public class PropertySourcesPlaceholderConfigurer extends PlaceholderConfigurerSupport implements EnvironmentAware {
...
//本方法在Bean对象实例化之前执行,通过beanFactory可以获取bean的定义信息,并可以修改bean的定义信息。
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
...
processProperties(beanFactory, new PropertySourcesPropertyResolver(this.propertySources));
...
}
//访问给定bean工厂中的每个bean定义,并尝试用给定属性中的值替换${…}属性占位符。
protected void processProperties(ConfigurableListableBeanFactory beanFactoryToProcess,
final ConfigurablePropertyResolver propertyResolver) throws BeansException {
...
doProcessProperties(beanFactoryToProcess, valueResolver);
}
}
我们doProcessProperties是在PropertySourcesPlaceholderConfigurer的父类PlaceholderConfigurerSupport中实现的
public abstract class PlaceholderConfigurerSupport extends PropertyResourceConfigurer
implements BeanNameAware, BeanFactoryAware {
protected void doProcessProperties(ConfigurableListableBeanFactory beanFactoryToProcess,
StringValueResolver valueResolver) {
BeanDefinitionVisitor visitor = new BeanDefinitionVisitor(valueResolver);
String[] beanNames = beanFactoryToProcess.getBeanDefinitionNames();
for (String curName : beanNames) {
if (!(curName.equals(this.beanName) && beanFactoryToProcess.equals(this.beanFactory))) {
BeanDefinition bd = beanFactoryToProcess.getBeanDefinition(curName);
try {
// 对bean进行访问
visitor.visitBeanDefinition(bd);
}
catch (Exception ex) {
throw new BeanDefinitionStoreException(bd.getResourceDescription(), curName, ex.getMessage(), ex);
}
}
}
...
}
}
BeanDefinitionVisitor:对Spring IoC容器内的BeanDefinition属性配置信息做解析
public class BeanDefinitionVisitor {
@Nullable
private StringValueResolver valueResolver;
public BeanDefinitionVisitor(StringValueResolver valueResolver) {
Assert.notNull(valueResolver, "StringValueResolver must not be null");
this.valueResolver = valueResolver;
}
// 遍历给定的BeanDefinition对象以及其中包含的可变PropertyValue和ConstructorArgumentValue。
public void visitBeanDefinition(BeanDefinition beanDefinition) {
visitParentName(beanDefinition);
visitBeanClassName(beanDefinition);
visitFactoryBeanName(beanDefinition);
visitFactoryMethodName(beanDefinition);
visitScope(beanDefinition);
if (beanDefinition.hasPropertyValues()) {
visitPropertyValues(beanDefinition.getPropertyValues());
}
if (beanDefinition.hasConstructorArgumentValues()) {
ConstructorArgumentValues cas = beanDefinition.getConstructorArgumentValues();
visitIndexedArgumentValues(cas.getIndexedArgumentValues());
visitGenericArgumentValues(cas.getGenericArgumentValues());
}
}
}
分析下这里怎么体现出访问者模式了:
- BeanDefinition 为 Spring Bean 的定义信息,在 Spring 解析完配置后,会生成 BeanDefinition 并且记录下来。下次通过 getBean 获取 Bean 的时候,会通过 BeanDefinition 来实例化具体的 Bean 对象。
- Spring 的 BeanDefinitionVisitor 用来访问 BeanDefinition。
- 抽象元素为 BeanDefinition。对 Bean 的定义信息,比如属性值、构造方法参数或者更具体的实现。
- 具体元素有 RootBeanDefinition、ChildBeanDefinition、GenericBeanDefinition 等等。
- 因为没有对访问者进行扩展,所以只有一个具体访问者 BeanDefinitionVisitor
- 访问的具体调用就是visitor.visitBeanDefinition(bd);
再回顾下访问者的定义:封装一些作用于某种数据结构中的各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新的操作。
3、访问者模式优缺点
3.1 优点
- 符合单一职责原则
- 优秀的扩展性
- 灵活性非常高
3.2 缺点
- 具体元素对访问者公布细节,也就是说访问者关注了其他类的内部细节,这是迪米特法则所不建议的
- 具体元素变更比较困难
- 违背了依赖倒转原则。访问者依赖的是具体元素,而不是抽象元素
3.3 使用场景
- 1、对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作。
- 2、需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,也不希望在增加新操作时修改这些类。
3.4 注意事项
- 访问者可以对功能进行统一,可以做报表、UI、拦截器与过滤器。
- 访问者模式适用于数据结构相对稳定的系统
参考文章:
https://www.jianshu.com/p/1f1049d0a0f4
http://c.biancheng.net/view/8501.html
https://blog.csdn.net/hhy107107/article/details/107892386
https://www.runoob.com/design-pattern/visitor-pattern.html