【机器学习合集】人脸表情分类任务Pytorch实现&TensorBoardX的使用 ->(个人学习记录笔记)
人脸表情分类任务
- 注意:整个项目来自阿里云天池,下面是开发人员的联系方式,本人仅作为学习记录!!!
- 该文章原因,学习该项目,完善注释内容,针对新版本的Pytorch进行部分代码调整
- 本文章采用pytorch2.0.1版本,python3.10版本
源码链接
这是一个使用pytorch实现的简单的2分类任务
项目结构:
- net.py: 网络定义脚本
- train.py:模型训练脚本
- inference.py:模型推理脚本
- run_train.sh 训练可执行文件
- run_inference.sh 推理可执行文件
# Copyright 2019 longpeng2008. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# If you find any problem,please contact us [email protected]
1. 网络结构
# coding:utf8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# 3层卷积神经网络simpleconv3定义
# 包括3个卷积层,3个BN层,3个ReLU激活层,3个全连接层
class simpleconv3(nn.Module):
# 初始化函数
def __init__(self, nclass):
# 继承父类
super(simpleconv3, self).__init__()
# 3通道 输入图片大小为3*48*48,输出特征图大小为12*23*23,卷积核大小为3*3,步长为2
'''
输出特征图大小 = [(输入大小 - 卷积核大小) / 步长] + 1
输入大小是 48x48
卷积核大小是 3x3
步长是 2
将这些值代入公式,您将得到输出特征图的大小:
输出特征图大小 = [(48 - 3) / 2] + 1 = (45 / 2) + 1 = 22.5 + 1 = 23
'''
self.conv1 = nn.Conv2d(3, 12, 3, 2)
# 批量标准化操作 12个特征通道
self.bn1 = nn.BatchNorm2d(12)
# 输入图片大小为12*23*23,输出特征图大小为24*11*11,卷积核大小为3*3,步长为2
'''
输出特征图大小 = [(输入大小 - 卷积核大小) / 步长] + 1
输入大小是 23x23
卷积核大小是 3x3
步长是 2
将这些值代入公式,您将得到输出特征图的大小:
输出特征图大小 = [(23 - 3) / 2] + 1 = (20 / 2) + 1 = 10 + 1 = 11
'''
self.conv2 = nn.Conv2d(12, 24, 3, 2)
# 批量标准化操作 24个特征通道
self.bn2 = nn.BatchNorm2d(24)
# 输入图片大小为24*11*11,输出特征图大小为48*5*5,卷积核大小为3*3,步长为2
'''
输出特征图大小 = [(输入大小 - 卷积核大小) / 步长] + 1
输入大小是 11x11
卷积核大小是 3x3
步长是 2
将这些值代入公式,您将得到输出特征图的大小:
输出特征图大小 = [(11 - 3) / 2] + 1 = (8 / 2) + 1 = 4 + 1 = 5
'''
self.conv3 = nn.Conv2d(24, 48, 3, 2)
# 批量标准化操作 48个特征通道
self.bn3 = nn.BatchNorm2d(48)
# 输入向量长为48*5*5=1200,输出向量长为1200 展平
self.fc1 = nn.Linear(48 * 5 * 5, 1200)
# 1200 -> 128
self.fc2 = nn.Linear(1200, 128) # 输入向量长为1200,输出向量长为128
# 128 -> 类别数
self.fc3 = nn.Linear(128, nclass) # 输入向量长为128,输出向量长为nclass,等于类别数
# 前向函数
def forward(self, x):
# relu函数,不需要进行实例化,直接进行调用
# conv,fc层需要调用nn.Module进行实例化
# 先卷积后标准化再激活
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
# 更改形状 改为1维
x = x.view(-1, 48 * 5 * 5)
# 全连接再激活
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
if __name__ == '__main__':
import torch
x = torch.randn(1, 3, 48, 48)
model = simpleconv3(2)
y = model(x)
print(model)
'''
simpleconv3(
(conv1): Conv2d(3, 12, kernel_size=(3, 3), stride=(2, 2))
(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 24, kernel_size=(3, 3), stride=(2, 2))
(bn2): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(24, 48, kernel_size=(3, 3), stride=(2, 2))
(bn3): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc1): Linear(in_features=1200, out_features=1200, bias=True)
(fc2): Linear(in_features=1200, out_features=128, bias=True)
(fc3): Linear(in_features=128, out_features=2, bias=True)
)
'''
2. 训练函数
部分代码内容与作者不同
- scheduler.step()与optimizer.step()修改前后顺序
- RandomSizedCrop改为RandomCrop
- transforms.Scale修改为transforms.Resize
# coding:utf8
from __future__ import print_function, division
import os
import torch
import torch.nn as nn
import torch.optim as optim
# 使用tensorboardX进行可视化
from tensorboardX import SummaryWriter
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
from net import simpleconv3
writer = SummaryWriter('logs') # 创建一个SummaryWriter的示例,默认目录名字为runs
# 训练主函数
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
"""
训练模型
Args:
model: 模型
criterion: loss函数
optimizer: 优化器
scheduler: 学习率调度器
num_epochs: 训练轮次
Returns:
"""
# 开始训练
for epoch in range(num_epochs):
# 打印训练轮次
print(f'Epoch {epoch+1}/{num_epochs}')
for phase in ['train', 'val']:
if phase == 'train':
# 设置为训练模式
model.train(True)
else:
# 设置为验证模式
model.train(False)
# 损失变量
running_loss = 0.0
# 精度变量
running_accs = 0.0
number_batch = 0
# 从dataloaders中获得数据
for data in dataloaders[phase]:
inputs, labels = data
if use_gpu:
inputs = inputs.cuda()
labels = labels.cuda()
# 清空梯度
optimizer.zero_grad()
# 前向运行
outputs = model(inputs)
# 使用max()函数对输出值进行操作,得到预测值索引
_, preds = torch.max(outputs.data, 1)
# 计算损失
loss = criterion(outputs, labels)
if phase == 'train':
# 误差反向传播
loss.backward()
# 参数更新
optimizer.step()
running_loss += loss.data.item()
running_accs += torch.sum(preds == labels).item()
number_batch += 1
# 调整学习率
scheduler.step()
# 得到每一个epoch的平均损失与精度
epoch_loss = running_loss / number_batch
epoch_acc = running_accs / dataset_sizes[phase]
# 收集精度和损失用于可视化
if phase == 'train':
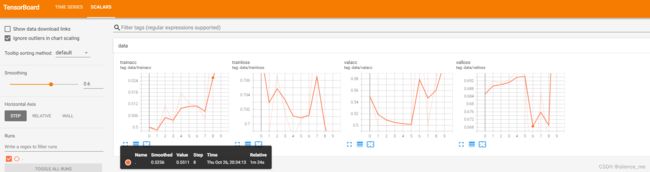
writer.add_scalar('data/trainloss', epoch_loss, epoch)
writer.add_scalar('data/trainacc', epoch_acc, epoch)
else:
writer.add_scalar('data/valloss', epoch_loss, epoch)
writer.add_scalar('data/valacc', epoch_acc, epoch)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
writer.close()
return model
if __name__ == '__main__':
# 图像统一缩放大小
image_size = 60
# 图像裁剪大小,即训练输入大小
crop_size = 48
# 分类类别数
nclass = 2
# 创建模型
model = simpleconv3(nclass)
# 数据目录
data_dir = './data'
# 模型缓存接口
if not os.path.exists('models'):
os.mkdir('models')
# 检查GPU是否可用,如果是使用GPU,否使用CPU
use_gpu = torch.cuda.is_available()
if use_gpu:
model = model.cuda()
print(model)
# 创建数据预处理函数,训练预处理包括随机裁剪缩放、随机翻转、归一化,验证预处理包括中心裁剪,归一化
data_transforms = {
'train': transforms.Compose([
transforms.RandomCrop(48), # 随机大小、长宽比裁剪图片size=48 RandomSizedCrop改为RandomCrop
transforms.RandomHorizontalFlip(), # 随机水平翻转 默认概率p=0.5
transforms.ToTensor(), # 将原始的PILImage格式或者numpy.array格式的数据格式化为可被pytorch快速处理的张量类型
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 数据标准化 要将图像三个通道的数据 整理到 [-1,1] 之间 ,可以加快模型的收敛
]),
'val': transforms.Compose([
transforms.Resize(64), # Scale用于调整图像的大小,现在采用transforms.Resize()代替
transforms.CenterCrop(48), # 从图像中心裁剪图片尺寸size=48
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
]),
}
# 使用torchvision的dataset ImageFolder接口读取数据
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# 创建数据指针,设置batch大小,shuffle,多进程数量
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=16, # 每个小批次包含16个样本
shuffle=True, # 是否随机打乱数据
num_workers=4) # 加载数据的子进程数
for x in ['train', 'val']}
# 获得数据集大小
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
# 优化目标使用交叉熵,优化方法使用带动量项的SGD,学习率迭代策略为step,每隔100个epoch,变为原来的0.1倍
criterion = nn.CrossEntropyLoss()
# 优化器 传入权重阈值,学习率0.1 动量(momentum)是一个控制梯度下降方向的超参数。
# 它有助于加速训练,特别是在存在平坦区域或局部极小值时。动量的值通常在0到1之间。较大的动量值会使参数更新更平滑。在这里,动量设置为0.9。
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
'''
lr_scheduler.StepLR 是PyTorch中的学习率调度器(learning rate scheduler),用于在训练神经网络时动态调整学习率。
lr_scheduler.StepLR 允许您在训练的不同阶段逐步减小学习率,以帮助优化过程。
optimizer_ft:这是您用于优化模型参数的优化器,通常是 optim.SGD 或其他PyTorch优化器的实例。
学习率调度器将监控这个优化器的状态,并根据其规则更新学习率。
step_size=100:这是学习率更新的周期,也称为学习率下降步数。在每个 step_size 个训练周期之后,学习率将减小。
gamma=0.1:这是学习率减小的因子。在每个 step_size 个训练周期之后,学习率将乘以 gamma。这意味着学习率将以 gamma 的倍数逐步减小。
'''
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1)
model = train_model(model=model,
criterion=criterion,
optimizer=optimizer_ft,
scheduler=exp_lr_scheduler,
num_epochs=10)
torch.save(model.state_dict(), 'models/model.pt')
3. 预测
执行以下内容,或者自行安排数据集
## 使用方法 python3 inference.py 模型路径 图片路径
python3 inference.py models/model.pt data/train/0/1neutral.jpg
python3 inference.py models/model.pt data/train/1/1smile.jpg
# coding:utf8
import sys
import numpy as np
import torch
from PIL import Image
from torchvision import transforms
# 全局变量
# sys.argv[1] 权重文件
# sys.argv[2] 图像文件夹
testsize = 48 # 测试图大小
from net import simpleconv3
# 定义模型
net = simpleconv3(2)
# 设置推理模式,使得dropout和batchnorm等网络层在train和val模式间切换
net.eval()
# 停止autograd模块的工作,以起到加速和节省显存
torch.no_grad()
# 载入模型权重
modelpath = sys.argv[1]
net.load_state_dict(torch.load(modelpath, map_location=lambda storage, loc: storage))
# 定义预处理函数
data_transforms = transforms.Compose([
transforms.Resize(48),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# 读取3通道图片,并扩充为4通道tensor
imagepath = sys.argv[2]
image = Image.open(imagepath)
imgblob = data_transforms(image).unsqueeze(0)
# 获得预测结果predict,得到预测的标签值label
predict = net(imgblob)
index = np.argmax(predict.detach().numpy())
# print(predict)
# print(index)
if index == 0:
print('the predict of ' + sys.argv[2] + ' is ' + str('none'))
else:
print('the predict of ' + sys.argv[2] + ' is ' + str('smile'))
4. TensorBoardX的使用
TensorBoardX 是一个用于在 PyTorch 中可视化训练过程和结果的工具。它是 TensorBoard 的 Python 版本,用于创建交互式、实时的训练和评估图表。以下是一些使用 TensorBoardX 的一般步骤:
-
安装 TensorBoardX:首先,您需要安装 TensorBoardX 库。您可以使用以下命令安装它:
pip install tensorboardX -
导入库:在您的 PyTorch 代码中,导入 TensorBoardX 库:
from tensorboardX import SummaryWriter -
创建 SummaryWriter:创建一个
SummaryWriter对象,以将日志数据写入 TensorBoard 日志目录。writer = SummaryWriter() -
记录数据:在训练循环中,使用
writer.add_*方法来记录各种数据,例如标量、图像、直方图等。以下是一些示例:-
记录标量数据:
writer.add_scalar('loss', loss, global_step) -
记录图像数据:
writer.add_image('image', image, global_step) -
记录直方图数据:
writer.add_histogram('weights', model.conv1.weight, global_step) -
记录文本数据:
writer.add_text('description', 'This is a description.', global_step)
-
-
启动 TensorBoard 服务器:在命令行中,使用以下命令启动 TensorBoard 服务器:
tensorboard --logdir=/path/to/log/directory其中
/path/to/log/directory是存储 TensorBoardX 日志的目录。 -
查看可视化结果:在浏览器中打开 TensorBoard 的 Web 界面,通常位于
http://localhost:6006,您可以在该界面上查看可视化结果。
请注意,您可以根据需要记录不同类型的数据,并根据训练过程的不同阶段定期记录数据。TensorBoardX 提供了丰富的可视化工具,以帮助您监视和分析模型的训练过程。
确保在训练循环中适时记录数据,并使用 TensorBoardX 查看结果,以更好地理解和改进您的深度学习模型。
这是 TensorBoard 启动时的一般信息,表明TensorBoard运行在本地主机(localhost)。如果您想使 TensorBoard 可以在网络上访问,可以采取以下几种方法:
-
使用代理:您可以使用代理服务器来将 TensorBoard 的端口暴露到网络上。这通常需要在代理服务器上进行一些配置,以便外部用户可以访问 TensorBoard。代理服务器可以是诸如 Nginx 或 Apache 之类的 Web 服务器。
-
使用 --bind_all 参数:在启动 TensorBoard 时,您可以使用
--bind_all参数,以将 TensorBoard 绑定到所有网络接口。这样,TensorBoard 将可以在本地网络上的任何 IP 地址上访问,而不仅仅是本地主机。例如:tensorboard --logdir=/path/to/log/directory --bind_all -
使用 --host 参数:您还可以使用
--host参数来指定 TensorBoard 的主机名(hostname),以使其在指定的主机上可用。例如:tensorboard --logdir=/path/to/log/directory --host=0.0.0.0这将允许 TensorBoard 在所有网络接口上运行,从而在网络上的任何 IP 地址上访问。
请根据您的需求和网络设置选择适当的方法。如果只需要在本地访问 TensorBoard,无需进行任何更改。如果需要在网络上访问,可以使用上述选项之一。不过,请注意,为了安全起见,最好将 TensorBoard 限制在受信任的网络上,或者使用身份验证和授权来保护访问。
效果展示