Linux I/O编程
一、实验目的:
练习用UNIX I/O进行文件读写的编程方法,用UNIX I/O函数管理文本信息、二进制数据、结构体数据,掌握UNIX I/O的基本编程方法。练习测时函数使用,通过测量UNIX I/O函数运行时间,建立UNIX I/O API函数基本开销的概念。
二、实验内容与要求:
先创建用户家目录下创建文件名为“姓名+学号+04”的子目录,作为本次实验目录,本次实验的所有代码都放到该目录下,要求将所有源代码与数据文件打包成文件”学号-姓名-lab4.tar.gz”, 压缩包与实验报告分别上传到指定目录下。
- 任务1. 在当前用户目录下创建数据文件student.txt,文件的内部信息存储格式为Sname:S#:Sdept:Sage:Ssex,即“姓名:学号:学院:年龄:性别”,每行一条记录,输入不少于10条学生记录,其中包括学生本人记录。调用标准I/O库编写程序task41.c,从文件中查找Sdept字段值为“计算机与网络安全学院”的文本行,输出到文件csStudent.txt中,保存时各字段顺序调整为S#:Sname:Sage: Ssex:Sdept。
提示:从终端读入一个文本行到字符串 char buf[MAXSIZE]可调用函数可调用函数:
“fgets(buf, MAXSIZE, stdin);”,其中stdin是表示键盘输入设备的文件指针。
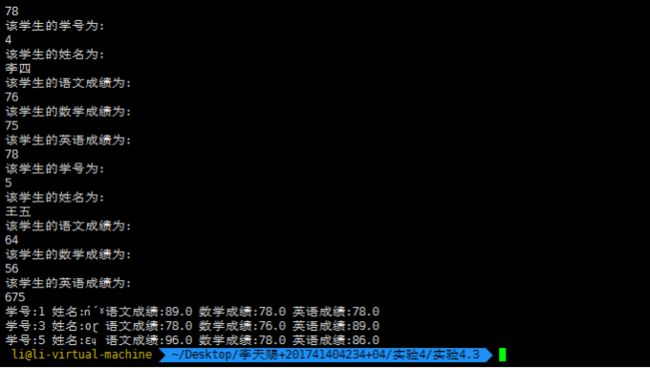
- 任务2. 调用Unix I/O库函数,编写程序task42.c,从键盘读入5个学生的成绩信息,包括学号、姓名、语文、数学、英语,成绩允许有一位小数,存入一个结构体数组,结构体定义为:
typedef struct _subject {
char sno[20]; //学号
char name[20]; //姓名
float chinese; //语文成绩
float math; //数学成绩
float english; //英语成绩
} subject;
将学生信息,逐条记录写入数据文件data,最后读回第1、3、5条学生成绩记录,显示出来,检查读出结果是否正确。
- 任务3(可选):在Linux环境下,可以调用库函数gettimeofday测量一个代码段的执行时间,请写一个程序task43.c,测量read、write、fread、fwrite函数调用所需的执行时间,并与prof/gprof工具测的结果进行对比,看是否基本一致。并对四个函数的运行时间进行对比分析。
提示:由于一次函数调用时间太短,测量误差太多,应测量上述函数多次(如10000次)运行的时间,结果才会准确。
附录:使用prof/gprof测量程序运行时间
Linux/Unix环境提供了prof/gprof工具来收集一个程序各函数的执行次数和占用CPU时间等统计信息,使用prof/gprof工具查找程序性能问题,要求编译命令添加-p选项(prof)或-pg选项(gprof),程序执行时就会产生执行跟踪文件mon.out(或gmon.out),再运行prof(或gprof)程序读取跟踪数据,产生运行报告。现在用gprof对以下程序各函数运行性能(占用CPU时间)进行测量。先输入程序源代码:
$ cat multiply.c
#include 然后编译和执行该程序,检查是否函数性能跟踪数据文件gmon.out:
$ gcc -pg -o multiply multiply.c -pg -g
$ ./multiply
x=5995001, y=5995001
$ ls gmon.out
gmon.out
最后,用gprof命令产看各函数执行时间:
$ gprof multiply gmon.out
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls us/call us/call name
99.44 14.11 14.11 6000000 2.35 2.35 slow_multiply
0.42 14.17 0.06 main
0.14 14.19 0.02 6000000 0.00 0.00 fast_multiply
在这里,slow_multipy和fast_multiply执行600000次所花运行时间为14.11s和0.02秒。
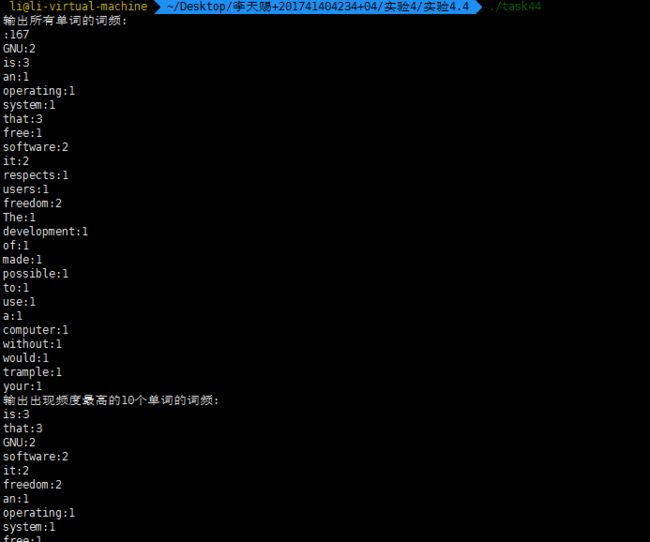
- 任务4:在Linux系统环境下,编写程序task44.c,对一篇英文文章文件的英文单词词频进行统计。
(1)以“单词:次数”格式输出所有单词的词频(必做)
(2)以“单词:次数”格式、按词典序输出各单词的词频(选做)
(3)以“单词:次数”格式输出出现频度最高的10个单词的词频
例如,若某个输入文件内容为:
GNU is an operating system that is free software—that is, it respects users’ freedom.
The development of GNU made it possible to use a computer without software that would trample your freedom.
则输出应该是:
GNU:2
is:3
it:2
……
提示:可以调用字符串处理函数、二叉树处理函数等库函数
三、涉及实验的相关情况介绍(包含使用软件或实验设备等情况):
安装Linux操作系统的计算机
四、报告内容(给出每个任务的要求、设计思想、源代码,后接编译过程、测试数据与运行结果截图)
- 任务一:
源代码:
#include运行结果:
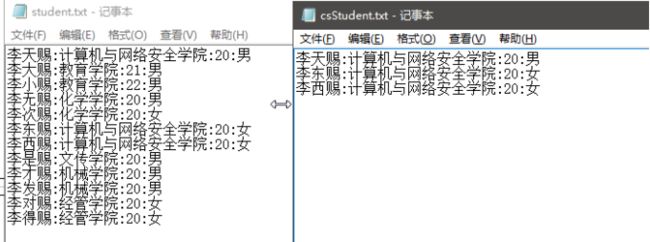
- 任务二:
源代码:
#include运行结果:
- 任务四:
源代码:
#include 运行结果:
五、实验分析和总结(任务3要求进行分析)
学会了文件的读取操作.加强了对C语言语法的理解.