小白学习c++的的第一节课
初识c++
- 目录:
- 一、c++关键字(c++98)
- 二、命名空间
-
- 2.1 命名空间的定义
- 2.2 命名空间的使用
- 三、c++输入与输出
- 四、缺省参数
- 五、函数重载
- 六、引用
-
- 6.1引用特性
- 6.2常引用
- 6.3使用场景
- 6.4传值和传引用效率比较
- 6.5引用和指针的区别
- 七、内联函数
-
- 7.1 概念
- 7.2特性
- 八、auto关键字(c++11)
-
- 8.1 auto的使用
- 8.2 auto不能用的场景
- 九、基于范围的for循环(c++11)
-
- 9.1 范围for的使用条件
- 十、指针空值——nullptr(c++11)
目录:
经过了很长时间对C语言和c的数据结构学习,终于开始学C++了。前面基础不牢,后面地动山摇,给自己加油。
该如何去学习c++?
多写博客。写博客,主要是总结自己学习的知识,更系统更全面对所学的知识进行概况,也能起到复习的作用。
有时间的话多看看课外书
c++的学习不是一年、两年能学会的,要把学习语言作为一个持续的过程。
写代码能力很重要,多去牛客网和leetcode去刷题。
这篇博客写的是:
C语言语法的不足,以及c++在C语言设计不合理的地方进行优化,为以后的c++学习奠定基础。
c++是贝尔实验室的本贾尼等人在C语言的基础上进行扩展,增加了类的机制,称为c with classes。c++是面向对象的语言,它包含c。
一、c++关键字(c++98)
c++63个关键字,c语言32个关键字
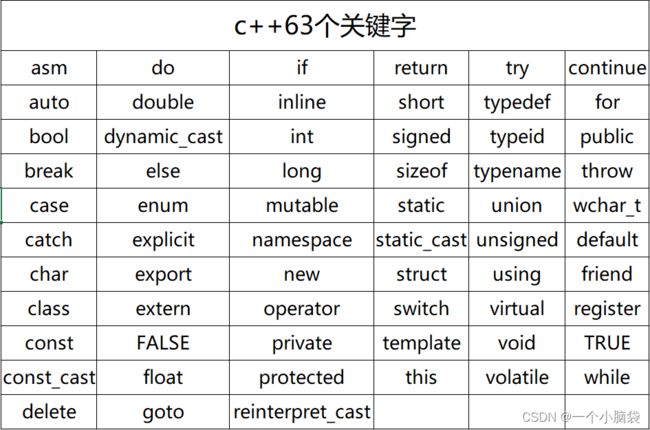
等c++学完后,我会单独总结关键字。
二、命名空间
命名空间解决C语言的命名冲突问题
2.1 命名空间的定义
如:
rand重定义了,以前是函数,C语言没有办法解决这个命名冲突问题,c++提出了用namespace来解决

下面就是命名空间的定义
pp是命名空间的名字,命名空间中可以定义/变量/函数/类型。

命名空间可以嵌套使用

同一个工程文件可以存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中(如头文件的声明给它封起来,源文件的定义也给它封起来,因为它们的命名空间相同,所以最后会合成为同一个命名空间)
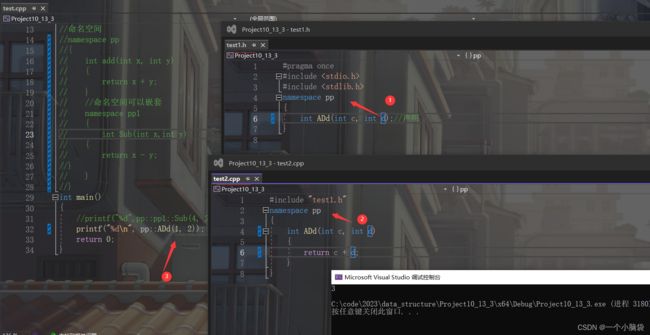
注意 :一个命名空间就定义了一个新的作用域,命名空间的所有内容都局限于该命名空间中。
2.2 命名空间的使用
命名空间的使用有三种方式:
- 加命名空间名称以及作用域限定符
N::a - 使用using将命名空间中某个成员引用
using N::a; - 使用using namespace 命名空间名称引用
using namespace N;
三、c++输入与输出
解释:
1.使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含头文件以及按命名空间使用方法使用std。
2.cout和cin是全局的流对象,endl是特殊的c++符号,表示换行输出。
3.<<流插入运算符,>>流提取运算符。
4。使用c++输入输出更方便,不需要C语言那样,手动控制格式,c++自动识别变量类型。
#includestd命名空间的使用:
1.日常生活中直接使用 using namespace std即可,这样方便使用。
2.using namespace std展开,标准库就全部暴露出来了,如果我们的定义和库有重名,就会存在冲突问题。日常练习很少出现问题,所以可以展开;项目开发的时候,代码很多,就容易出现冲突问题,在项目开发过程中,我们可以std::cout这样使用指定命名空间+using std::cout 展开常用的库对象和类型等。。
四、缺省参数
缺省参数就是声明和定义函数的时候为函数的参数指定一个缺省值。调用该函数时,如果没有指定实参,就会采用该形参的缺省值,否则使用该实参。
- 全缺省参数
- 半缺省参数
参考:

注意:
1.半缺省参数必须从右往左连续给值,不能间隔给。
2.缺省参数不能在函数声明和定义中同时出现。
3.缺省参数必须是常量或者全局变量。
4.C语言不支持(编译器不支持)。
五、函数重载
函数重载: 同一个作用域中声明的功能相似的同名函数,这些同名函数的形参列表(参数个数或类型或顺序)都不同。
- 参数类型不同
- 参数个数不同
- 参数类型顺序不同
参考:
#include为什么c++支持函数重载,而C语言不支持函数重载?
c/c++程序要想运行起来必须经历:预编译、编译、汇编、链接这几个阶段。
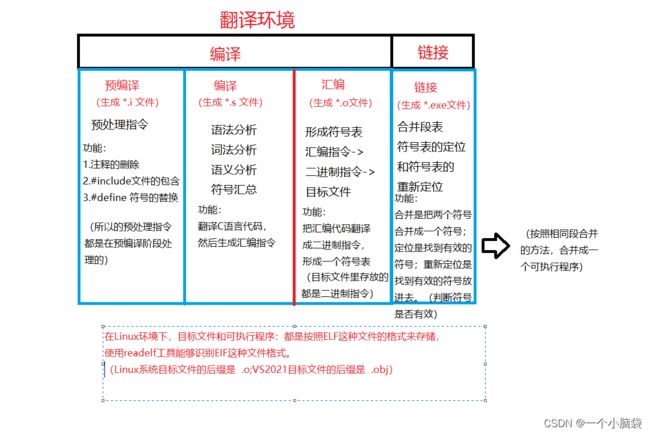 符号表里有函数名和它的地址,C语言链接函数地址时,就用函数名去找(C语言不存在同名函数);c++是通过函数修饰规则来区分的,只要参数不同,修饰出来的名字就不一样,就支持重载。
符号表里有函数名和它的地址,C语言链接函数地址时,就用函数名去找(C语言不存在同名函数);c++是通过函数修饰规则来区分的,只要参数不同,修饰出来的名字就不一样,就支持重载。
举例:
在LINUX系统环境下,gcc的函数修饰后不变,而g++函数修饰后变成【_z+函数长度+函数名+类型首字母】
采用C语言编译器编译后的结果:


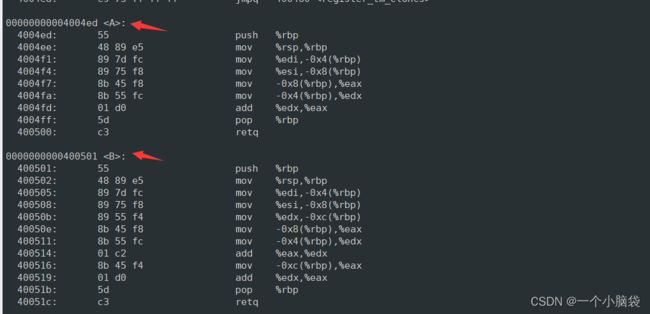
结论:在linux系统下,用gcc编译完成后,函数名字没有发生改变
采用c++编译器编译的结果:


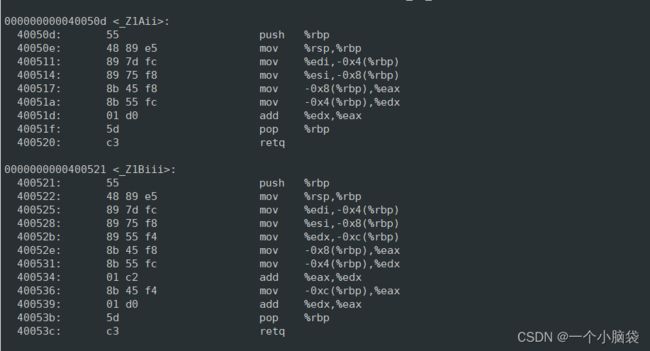
结论:在linux系统下,用g++编译完成后,函数名字发生改变了。
注意:
两个函数的函数名和参数一样,返回值不同是构不成重载的,因为调用时编译器没办法区分。
六、引用
类型& 引用变量名(对象名)=引用实体
引用不是新定义一个变量,是给已经存在的变量取个别名,编译器不会为引用开辟一块空间,它和它引用的那个变量共用一块内存空间。
注意: 引用类型必须和引用实体是同种类型。
6.1引用特性
1.引用定义时,必须初始化
2.一个变量可以有多个引用
3.引用一旦引用一个实体,就不能引用其他实体。
6.2常引用
#include 
算术转换,整型提升,在赋值/引用的时候都会产生一个临时变量,这个临时变量具有常属性。
6.3使用场景
- 做参数
- 做返回值
#include 注意:如果函数返回时,出了函数作用域,返回的那个对象还在(没有还给系统),就可以使用返回值了;如果返回的那个对象不在(已经返回给系统),就必须使用传值返回,要是使用引用返回,结果就是未定义得(可能对,也可能错)。
6.4传值和传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
引用的作用就是为了提高效率。
1.引用做参数的比较
#include 
2.引用做返回值的比较
#include 
通过上面比较,我们发现引用在作为函数的参数和返回值类型效率比传值的效率高。
6.5引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
在底层实现上实际是有空间的,因为引用是按照指针的方式去实现的(引用和指针的汇编代码一样)。
需要牢牢记住
引用和指针的不同点:
1.引用概念上是定义一个变量的别名,指针存储的是一个变量地址。
2.引用在定义上必须初始化,指针没有要求。
3.引用对一个实体初始化过后,就不能在引用其他的实体了,而指针可以在任何时候指向任何一个同类型实体。
4.没有NULL引用,但有NULL指针。
5.在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占的字节个数(32位平台下占4个字节)
6.引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
7.有多级指针,但是没有多级引用。
8.访问实体方式不同,指针需要解引用操作,引用编译器自己处理。
9.引用比指针使用起来更加安全。
七、内联函数
必须掌握:
宏的优缺点:
优点:
1.增强代码的复用性。
2.提高性能。
缺点:
1.不能调试(预编译阶段进行了替换)
2.宏没有类型,比较危险
3.代码可读性差,可维护性差,容易误用。
c++用那些技术代替宏:
故c++推荐:const和enum替换宏常量,iline替换宏函数(不用建立栈帧,把宏的缺点全部去掉,inline会对函数进行优化,debug环境下,需要进行配置,内联函数是个建议)
7.1 概念
inline修饰的函数也叫内联函数,编译时c++编译器会在调用内联函数的地方展开,不需要函数调用建立栈帧的开销,内联函数提升运行效率。
案例:
在debug模式下,F10来调试,然后进行反汇编。add函数建立一个函数栈帧,然后通过call 跳转到add函数的地址,去访问那块空间。
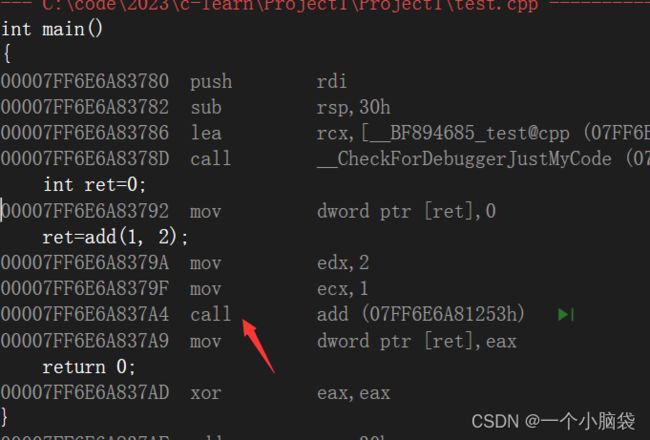
在debug模式下,需要对编译器进行设置,inline内联函数才会展开(debug模式下编译器不会对代码进行优化)

1.右击弹出菜单
2.点击属性
3.按图操作,快速掌握


下面就是设置完成后,进行debug调试,反汇编的代码,我们可以看到,内联函数直接在调用的地方展开,极大的提高了程序运行的效率。

7.2特性
1.inline是以空间换时间的做法。缺点:编译出来的指令多,目标文件会变大;优点:少了调用的开销,提高了程序运行效率。指令影响的是可执行程序的大小。
2.inline只是一个建议,不同编译器关于inline实现机制可能不同。它适合函数规模小,并且不能递归,且频繁调用的函数。(一般10行以内的可以用内联函数,内联只是向编译器发出一种请求,编译器可以忽略这个请求,可能会被编译器当成函数处理)
3.内联函数不建议声明和定义分离,会产生链接错误(链接阶段,符号表里没有函数地址,链接找不到)。内联函数在调用的地方展开,不进入符号表,函数的地址是个跳转指令。
八、auto关键字(c++11)
程序越来越复杂,用到的类型也越来越复杂:
1.类型难于拼写。
2.含义不明确导致容易出错。
auto的实际价值就是简化代码,类型很长时,可以直接推导,用它比较方便。
案例:
使用typedef给类型取别名,可以简化代码,但是也会遇到新的问题

在编译的时候,常常需要把表达式的值赋给变量,函数声明变量的时候,要清除的知道表达式的类型,要做到这点非常不容易,所以c++给auto赋予了新的含义。
8.1 auto的使用
早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量。
C++11中,标准委员会赋予了auto全新的含义即: 作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
auto的使用:
#include 
注意:
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一 种“类型”的声明,而是一个类型声明时的“占位符”, 编译器在编译期会将auto替换为变量实际的类型。
1.auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto*没有区别,但是用auto声明引用类型时,必须加&
2.在同一行定义多个变量
在同一行声明多个变量,必须是相同类型,否则编译器会报错,因为编译器实际上只对第一个类型进行推导,然后用推导来的类型定义其它的变量。
8.2 auto不能用的场景
1.auto不能做函数的参数
auto不能作为形参类型,因为编译器无法对形参的实际参数进行推导
2.auto不能直接用来声明数组。
3.为了避免与c++98中的auto混淆,c++11只保留了auto作为类型指示符的用法。
4.auto常用的优势用法是与c++11提供的新式for循环,还有lambda表达式等进行配合使用。
九、基于范围的for循环(c++11)
c++11引入了基于范围的for循环。for循环后面的括号被冒号‘:’分成了两部分,左边部分是在范围内用于迭代的变量,右边部分是被迭代的范围。
#include 
注意:与普通循环类似,可以用continue来结束本次循环,也可以用break跳出整个循环。
9.1 范围for的使用条件
1.for循环迭代的范围必须明确
对于数组而言就是数组中的第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
2 .迭代的操作要实现++和==的操作。(还没学到这个知识点)
十、指针空值——nullptr(c++11)
良好的c++编程习惯中,声明一个变量最好给它一个初始值,否则容易出现不可预料的错误。
我们一般会给指针进行初始化:
int* p1= NULL;
int* p2=0;
NULL实际是一个宏,在c头文件(stddef.h)中:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL被定义成了字面常量0,或者被定义成了无类型指针(void*)的常量。
#include 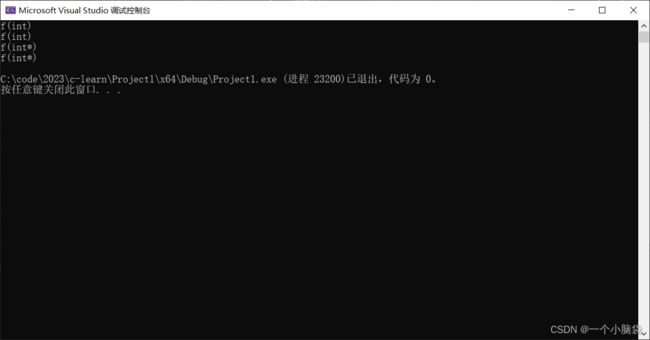
解释:
程序本意是想通过f(NULL)调用指针版本的(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。
在C++98中,字面常量0既可以是一个整形数字, 也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量, 如果要将其按照指针方式来使用,必须对其进行强转(void*)0。
注意:
1.在使nullptr表示指针空值时,不需要包含头文件,因为nullptr是c++1作为新关键字引入的。
2.在c++中,sizeof(nullptr)和sizeof((void *)0)所占的字节数相同。
3.为了提高代码的实用性,后续表示指针空值时,最好使用nullptr。