Hypertext Transfer Protocol -- HTTP/1.0
文章目录
-
- Hypertext Transfer Protocol -- HTTP/1.0
-
- 1. Introduce
-
- 1.1 Purpose
- 1.2 Terminology
- 1.3 Overall Operation
- 3. Protocol Parameters
-
- 3.1 Protocol Parameters
- 3.2 Uniform Resource Identifiers
-
- 3.2.2 http URL
- 4. HTTP Message
-
- 4.1 Message Types
- 4.2 Message Header
- 4.3 General Header Fields
- 5. Request
-
- 5.1 Request-Line
-
- 5.1.1 Method
- 5.1.2 Request-URI
- 5.2 Request Header Fields
- 6. Response
-
- 6.1 Status-Line
- 6.1.1 Status Code and Reason Phrase
- 6.2 Response Header Fields
- 7. Entity
-
- 7.1 Entity Header Fields
- 7.2 Entity Body
-
- 7.2.1 Type
- 7.2.2 Length
- 8. Method Definitions
-
- 8.1 GET
- 8.2 HEAD
- 8.3 POST
- 9. Status Code Definitions
-
- 9.1 Informational 1xx
- 9.2 Successful 2xx
- 9.3 Redirection 3xx
- 9.4 Client Error 4xx
- 9.5 Server Error 5xx
- 10. Header Field Definitions
-
- 10.1 Allow
- 10.2 Authorization
- 10.3 Content - Encoding
- 10.4 Content-Length
- 10.5 Content-Type
- 10.6 Date
- 10.7 Expires
- 10.8 From
- 10.9 If-Modified-Since
- 10.10 Last-Modified
- 10.11 Location
- 10.12 Pragma
- 10.13 Referer
- 10.14 Server
- 10.15 User-Agent
- 10.16 WWW-Authenticate
- 11. Access Authentication
-
- 11.1 Basic Authentication Scheme
- 12. Security Considerations
-
- 12.1 Authtication of Clients
- 12.2 Safe Methods
- 12.3 Absue of Server Log Information
- 12.4 Transfer of Sensitive Information
- 12.5 Attack Based On File and Path Names
Hypertext Transfer Protocol – HTTP/1.0
1. Introduce
1.1 Purpose
Hypertext Transfer Protocol (HTTP) 是一个无状态的应用层协议,用于分布式的,相互协作的超媒体系统。本文档定义了 HTTP/1.0 的消息语义,分为 request method,request header fields,response status codes,和 response header field是,和 payload of messages(metadata 和 body content)。
HTTP 是 stateless protocol。一个 stateless protocol 不需要 web server 在多个请求期间保留用户的信息和状态。
stateless protocol 是一种通讯协议,接收方不能保留先前请求的 session state。发送方向接收方传输相关的 session state,每个请求都能被单独理解,不需要引用接收方保留的先前请求中的 session state。
相反,stateful protocol 是一种通讯协议,接收方可能保留了先前请求的 session state。
在计算机网络中,stateless protocol 的例子有 Internet Protocol(IP) 和 Hypertext Transfer Protocol(HTTP)。stateful protocol 的例子有 Transmission Control Protocol(TCP)和 File Transfer Protocol(FTP)。
Stateless protocols 提高了可见性,可靠性和可拓展性。可见性被提升,因为监视系统不必查看单个请求之外的信息就可以确定请求的全部性质。可靠性被提升,因为它简化了从部分失败中恢复的任务。拓展性被提升,因为不必存储请求间的 session state,允许 server 快速释放资源,进一步简化了实现。
stateless protocol 的缺点是,它们可能会降低网络性能,因为可能会在一系列请求中发送重复的数据,这是因为数据不能被 server 保留重用。
Examples:
HTTP server 能够理解每个单独的请求。
相反,传统的 FTP server 进行与用户的交互 session。在会话期间,为用户提供一种方式来进行权限验证并设置多个变量(工作目录,传输模式),都作为 session state 的一部分存储于 server 上。
Stacking of stateless and stateful protocol layers:
在不同协议层的 stateful protocols 和 stateless protocols 间可能有复杂的交互。例如,HTTP,一个 stateless protocol,在 stateful protocol TCP 之上的层级,TCP 又在 stateless protocol IP 之上的层级。
层级的重叠甚至在 HTTP 之上继续出现。作为缺少保留的 session state 的近似解决方法,HTTP servers 实现多种 session management 方法,典型地在 HTTP cookie 中使用 session 标识符引用存储在 server 上的 session state,有效地在 HTTP 协议之上创建一个 stateful protocol。HTTP cookies 违反了 REST 架构风格,因为即使没有引用存储于 server 上的 session state,它们也独立于 session state(它们会影响浏览器历史中相同网页的前几页),且他们没有定义的语义。
Hytertext 是展现在计算机屏幕或着其他电子设备上的文本,它有指向其他文本的引用(hyperlinks),读者可以立即访问。Hypertext 文档通过 hyperlinks 互联。从文件中分离出来,术语 “hypertext” 有时用于描述具有集成的 hyperlinks 的 tables,images,和其他表达的内容格式
实际的信息系统需要更多的功能,不单单是简单的检索功能,包括搜索,前后端更新,和 annotation。HTTP 使用 method 表明 request 的目的,使用 URI,作为定位(URL)或名字(URN),来表明方法所要应用的资源。
HTTP 同样被用作通用协议,用于 user agent 和使用其他 Internet 协议的 proxy/gateways 间的通讯,例如 SMTP,NNTP,FTP,Gopher 和 WAIS,允许基本的超媒体访问来自不同应用的资源,简化 user agents 的实现。
在计算机领域,user agent 是任何软件,代表用户行为,它“检索,渲染,促进终端用户与 Web 内容间的交互”。通常,在 client-server 系统中,user agent 表现为 client。比如,Web 浏览器。
在计算机网络中,proxy server 是一个 server 应用,作为在 client 请求一个资源,server 提供资源的中介。
client 直接请求 proxy server,而不是直接连接满足对资源,例如,文件或 web page,的请求的服务器,proxy server 评估请求并执行需要的网络事务。这作为一种简化和控制请求的复杂度的方法,或者提供额外的好处,比如 load balancing,privacy 或者 security。Proxies 被设计出来用于对分布式系统添加结构或封装。因此,当请求服务时,proxy server 代表 client 工作,潜在的掩盖了指向资源服务器的真实来源。
Gateway 是一块网络硬件或软件,用在电信网络中,允许数据从一个分离的网络中流向另一个网络。gateways 与 routers 或 switches 的不同之处在于它们使用超过一个协议来连接多个网络进行通讯,且可以运行于 open systems interconnection(OSI)模型的 7 层中的任意一层。
术语 gateway 可以指代配置用于执行网关任务的计算机或计算机程序,例如 default gateway 或者 router,在 HTTP 的情况下,gateway 也经常用作 reverse proxy 的同义词。
Network gateway:
Network gateway 提供 network 和包含 devices,例如 protocol translators,impedance matchers,rate converters,fault isolators,或者 signal translators。network gateway 需求在使用 gateway 的网络间建立相互接受的管理过程。Network gateways,也被称为 protocol translation gateways 或者 mapping gateways,可以对连接的使用不同网络协议技术的网络执行协议转换。例如,network gateway 连接办公室或家庭内部网到 Internet。如果办公室或家庭计算机用户想要加载一个 web page,至少两个 network gateways 是可访问的 – 一个是从办公室或家庭网络到 Internet 的网关,另一个是从 internet 到服务于 web page 的计算机的 network gateways。
在 Internet Protocol network 中,目的在所给子网掩码之外的 IP packets 被发送到 network gateway。例如,如果私有网络有一个基本的 IPv4 地址 192.168.1.1 且有一个子网掩码 255.255.255.0,然后任何发往 192.168.1.0 之外地址的数据都会被发往 network gateway。IPv6 网络以类似的方式工作。当将 IP packet 转发到另一个网络时,gateway 可能执行 network address translation。
在企业网络中,network gateway 通常也作为 proxy server 和 firewall。
在 Microsoft Windows 上,Internet Connection Sharing 特性允许计算机作为 gateway,通过提供在 internet 和 内部网之间的连接。
在计算机网络中,reverse proxy 是在后端应用之前的一个应用,它转发 client 请求到后端应用上。Reserve proxy 帮助增加拓展性,性能,恢复性和安全性。这些返回到 client 的资源就好像直接来自原始的 server 本身一样。
大型网站和 content delivery networks 搭配其他技术使用 reverse proxies,进行 internal servers 间的 load balance。Reverse proxies 能够保存静态内容的缓存,这更进一步的减少了这些 internal servers 和 internal network 上的负载。在 reverse proxy 在 client 和 reverse proxy 的通讯通道上添加特性也是十分常见的,比如 compression 或 TLS encryption。
Reverse proxies 通常由 web service 拥有或管理,它们被来自公网的 client 访问。相反,forward proxy 通常由 client 管理,它被限制在私有,内部的网络中,除了 client 能请求 forward proxy 作为 client 的代表检索来自公有 Internet 的资源。
Reverse proxy servers 在例如,Apache,Nginx,和 Caddy 等流行的开源 web servers 中被实现。这个软件能检查 HTTP 部首,允许它向 Internet 呈现单一的 IP 地址,基于 HTTP 请求的域名向不同的内部 servers 传递请求。专用的 reverse proxy server 例如开源软件 HAProxy 和 Squid 被用于 Internet 中更大的网站。
1.2 Terminology
connection:两个应用程序间为了通讯的目的建立的传输层虚拟回路。
message:HTTP 通讯的基本单元,由 octets 的结构化序列组成,匹配定义在 Section 4 的语法,通过连接传输。
request:HTTP 请求消息。
response:HTTP 响应消息。
resource:网络数据对象或服务,能使用 URI 标识。
entity:数据资源的特定表示或演示,或者来自服务资源的回复,可能包含在请求或响应消息之中。entity 由 metainformation 和 content 组成,metainformation 的形式为 entity header,content 的形式为 entity body。
client:以发送请求为目的建立连接的应用程序。
user agent:初始化请求的 client。通常是 browsers,editors,spiders(web-traversing robots),或其他终端用户工具。
server:接受连接的应用程序,通过发送响应来服务请求。
origin server:给定资源所在或被创建的 server。
proxy:同时作为 server 和 client 的中间程序,代表 clients 生成请求。请求被内部处理或者 (在翻译后) 将它们传递到其他服务器。一个 proxy 在转发请求消息前必须解释请求消息,必要的话,重写它们。Proxies 通常用作 client-side 的入口来通过网络防火墙,或作为帮助应用来处理请求,使用 user agent 没有实现的协议。
gateway:作为其他服务其中介的服务器。不像 proxy,gateway 在接收请求时表现得如同它就是请求资源得原始服务器一般;请求的 client 可能意识不到它在与 gateway 通讯。Gateway 通常作为 server-side 入口来通过网络防火墙,或者作为 protocol translator 来访问存储于 non-HTTP 系统的资源。
tunnel:tunnel 是中间程序,作为两个连接间的 blind relay。一旦激活,tunnel 不被认为是 HTTP 通讯的一方,虽然 tunnel 可能通过一个 HTTP 请求初始化。当 relayed 连接的两端都关闭时,tunnel 不复存在。Tunnel 在当入口是必要的的时候被使用,且中间程序不能或不应该解释 relayed(转发的)通讯。
cache:响应信息的本地存储,是控制消息的存储,检索,和删除的子系统。缓存存储可缓存的消息,以减少对将来等效的请求的响应时间和网络带宽的消耗。任何 client 或 server 都可能包含缓存,但当 server 作为 tunnel 是不能包含缓存。
任何给定的程序都能既是 client 又是 server;我们使用这些术语仅仅是指代在特定连接中程序所担任的角色,而不是程序通常意义上的能力。同样,任何 server 都可能作为 origin server,proxy,gateway,或 tunnel,基于请求的性质转换其行为。
1.3 Overall Operation
HTTP 协议基于请求/响应范式。client 与 server 建立连接,并向 server 发送请求,请求格式为 request method,URI,和协议版本,紧跟着的是 MINE-like 的消息,包含请求修饰符,client 信息,和可能的 body content。server 的响应如下,状态行,包含消息的协议版本,和成功或失败码,entity 元消息,和可能的 body content。
大部分的 HTTP 通讯由 user agent 初始化,且由被应用于某些 origin server 上的资源的请求组成。在最简单的场景中,这可能通过 user agent (UA) 和 origin server (0) 之间的单个连接完成。

当一个或多个中介出现在请求/响应链中,情况变得更复杂。有三种常见形式的中介:proxy,gateway,和 tunnel。
- proxy 是 forwarding agent,接收指向某使用绝对形式表示的 URI 的请求,重写消息的所有或部分内容,然后转发重写格式化后的消息到 URI 表示的 server 上。
- gateway 是 receiving agent,表现的像是其他 servers 之上的一层,且如果必要的话,将请求翻译为底层 server 的协议格式。
- tunnel 表现得像是两个连接间得转发点,它不改变消息。当通讯需要通过一个中介(比如防火墙),即使中介不能理解消息的内容, 此时使用 tunnel。
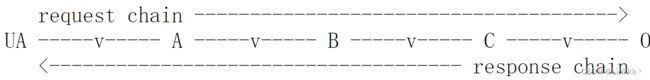
上图表示三个中介(A,B 和 C)出现在 user agent 和 origin server 之间。通过整个通讯链的请求或响应消息必须通过四个独立的连接。这些区别十分重要,因为一些 HTTP 通讯选项可能仅能应用于与最近的,non-tunnel 的邻居的连接,或是与通讯链的终端的连接,或者是通讯链上的所有连接。虽然图表是线性的,每个参与者可能忙于多个同时的通讯。例如,B 可能接收到很多非 A 的 client 的请求,并转发这些请求到非 C 的 server 上,与此同时,它也处理来自 A 的请求。
在通讯中不作为 tunnel 的任何一方可能都会使用内部缓存来处理请求。缓存缩短了请求/响应链,因为链上的某个参与者缓存了对某请求的响应。下图表示如果 B 缓存了来自 0(通过 C)的对某请求的早期响应,而 A 和 UA 没有缓存,其结果链如何:
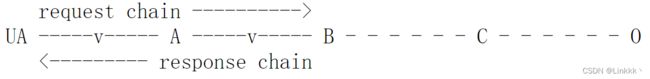
不是所有的响应都能缓存,一些请求可能包含修饰词,以对缓存行为提出特定的需求。一些 HTTP/1.0 应用使用 heuristics 来描述响应能不能被缓存,但这些规则不是标准。
在因特网中,HTTP 通讯通常发生在 TCP/IP 连接上。默认的端口号是 TCP 80,但是其他端口也能被使用。这并不会阻止 HTTP 在其他因特网或其他网络中的协议之上被实现。HTTP 只假定一个可靠的传输;任何能提供这样保证的协议都能被使用。
除了实验性质的应用,当前实践需要 client 先建立连接再发送请求,server 先响应请求再关闭连接。client 和 server 都应意识到双方都由可能过早的关闭连接,因为用户行为,自动超时,或程序失败,应当以一种可预测的方式处理这种关闭。对双方来说,任何情况下,连接的关闭总是会结束当前的请求,不论请求的状态是什么。
3. Protocol Parameters
3.1 Protocol Parameters
HTTP 使用 “
HTTP 消息的版本由 HTTP-Version 字段表明,在消息的第一行。如果协议版本没有指定,接收方必须假设消息使用简单的 HTTP/0.9 格式。
HTTP-Version = "HTTP" "/" 1*DIGIT "." 1*DIGIT
3.2 Uniform Resource Identifiers
3.2.2 http URL
“http” 方案被用于通过 HTTP 协议定位网络资源。
http_URL = "http:" "//" host [ ":" port ] [ abs_path ]
其中,host 是一个合法的互联网主机域名或者 IP 地址(以点分十进制形式)。
如果 port 为空或没有给定,则假设使用 port 80。语义是被标识的资源被定位于在主机的该端口上监听 TCP 连接的服务器,资源的 Request-URI 是 abs_path。如果在 URL 中没有出现 abs_path,当作为 Request-URI 使用时,必须给定为 “/”。
注意:虽然 HTTP 协议独立于传输层协议,http URL 仅通过它们的 TCP 定位来标识资源,因此非 TCP 资源必须由其他 URI 方案来标识。
“http” URLs 的标准格式转换任何主机中 UPALPHA 字符为 LOALPHA 等价字符(hostnames 是大小写不敏感的),如果端口是 80 省略 [ “:” port ],使用 “/” 取代空的 abs_path。
4. HTTP Message
4.1 Message Types
HTTP 消息由 client 到 server 的请求和 server 到 client 的响应组合而成。请求和响应消息必须包含可选的 header fields(也被称为 “headers”)和 entity body。entity body 通过一个 null line 与 header 分开。
Full-Request = Request-Line
*( General-Header
| Request-Header
| Entity-Header )
CRLF
[ Entity-Body ]
Full-Response = Status-Line
* ( General-Header
| Response-Header
| Entity-Header )
CRLF
[ Entity-Body ]
4.2 Message Header
HTTP header 字段,包含 General-Header,Request-Header,Response-Header,和 Entity-Header 字段。
HTTP-header = field-name ":" [ field-value ] CRLF
field-name = token
field-value = *( field-content | LWS )
field-content = \
header fields 的顺序是无意义的。但是,习惯上先发送 General-Header fields,然后是 Request-Header 或 Response-Header,最后发送 Entity-Header fields。
4.3 General Header Fields
有几个 header field 对请求和响应消息都有通用的应用性,但是不应用于被传输的实体。这些 header 仅应用于传输的消息。
5. Request
从 client 到 server 的请求消息的第一行包含,应用到资源的方法,资源标识符,和协议使用的版本。
Full-Request = Request-Line
*( General-Header
| Request-Header
| Entity-Header )
CRLF
[ Entity-Body ]
5.1 Request-Line
Request-Line 以 method token 起始,紧跟着的是 Request-URI 和协议版本,以 CRLF 结束。元素以 SP 字符分割。
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
5.1.1 Method
Method token 表明在由 Request-URI 标识的资源上执行的方法。方法是大小写敏感的。
Method = "GET"
| "HEAD"
| "POST"
| extension-method
extension-method = token
5.1.2 Request-URI
Request-URI 是一个 Uniform Resource Identifier 且标识应用请求的资源。
Request-URI = absoluteURI | abs_path
Request-URI 的两种选项取决于请求的性质。
absoluteURI 格式仅当请求被发往 proxy 时允许。proxy 转发请求和返回响应。如果请求是 GET 或 HEAD 且先前的响应被缓存,proxy 可能使用缓存消息,如果它通过了任何 Expires header field 中的限制。注意 proxy 可能转发请求到另一个 proxy 或者直接转发到 absoluteURI 指定的 server。为了避免请求循环,proxy 必须能够识别它的所有的 server 名称,包括任何别名,本地变体,和数字化的 IP 地址。一个 Request-Line 的例子可能是:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.0
Request-URI 最常见的格式用于标识 origin server 或 gateway 上的资源。在这种情况下,仅有 URI 的绝对路径被传输。例如,client 想要从 origin server 上直接检索上述资源,它将与主机 “www.w3.org” 在端口 80 上建立一个 TCP 连接并发送一行:
GET /pub/WWW/TheProject.html HTTP/1.0
紧接着的是 Full-Request 剩下的部分。注意绝对路径不能为空;如果在原始的 URI 中没有出现任何东西,必须将其视为 “/”(server 根目录)。
Request-URI 作为一个被编码的字符串被传输,一些字符可能使用由 RFC 1738 定义的 “% HEX HEX” 编码方式进行转义。origin server 必须对 Request-URI 进行解码以便正确地解释请求。
5.2 Request Header Fields
request header 字段允许 client 传递关于请求或关于 client 本身或关于 server 的额外信息,这些 fields 作为请求修饰符,其语义等价于程序语言方法调用中的参数。
Request-Header = Authorization
| From
| If-Modified-Since
| Referer
| User-Agent
6. Response
在接收和解释一个请求消息后,server 以 HTTP 响应消息的方式响应。
Full-Response = Status-Line
| (General-Header
| Response-Header
| Entity-Header)
CRLF
[ Entity-Body ]
6.1 Status-Line
Full-Response 消息的第一行是 Status-Line,由协议版本,数字状态码,和它的关联的文本短语。
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
因为 status line 总是以 protocol version 和 status code 起始
"HTTP/" 1*DIGIT "." 1*DIGIT 3DIGIIT SP
(e.g., “HTTP/1.0 200”)。
6.1.1 Status Code and Reason Phrase
Status-Code 元素是 3 位整型结果码,表示尝试理解和满足请求的结果。Reason-Phrase 给予 Status-Code 的短文本描述。
Status-Code 的第一个数字定义了响应的类型。
- 1xx: 信息 - 未使用,保留
- 2xx: 成功 - 行为被成功接收,理解,和接受
- 3xx: 重定向 - 为了完成请求,必须有进一步行动
- 4xx: 客户端错误 - 请求包含错误语法,不能被满足
- 5xx: 服务器错误 - 服务器不能满足一个明显合理的请求

6.2 Response Header Fields

7. Entity
Full-Request 和 Full-Response 消息可能携带 entity。一个 entity 由 Entity-Header 和 Entity-Header 字段和 (通常) Entity-Body。
7.1 Entity Header Fields
Entity-Header 字段定义可选的关于 Entity-Body 的元信息,或,如果没有 body 存在,关于请求标识的资源。

extension-header 机制允许定义额外的 Entity-Header 字段,且不改变协议,但是这些字段不能假设被接收方识别。未识别的 header 字段应当被接收方忽略,被 proxies 转发。
7.2 Entity Body
使用 HTTP 请求或响应发送的 entity body 使用 Entity-Header 字段定义的格式和编码。
Entity-Body = *OCTET
请求消息中是否包含 entity body 取决于请求本身是否需要。请求中 entity body 的存在由请求消息 headers 中的 Content-Length header 字段的内容暗示。包含 entity body 的 HTTP/1.0 请求必须一个 合法的 Content-Length header 字段。
对于响应消息,是否包含 entity body 取决于 request method 和 response status code。所有对 HEAD 请求的响应都不能包含 entity body,即使响应包含 entity header 字段。所有的 1xx (informational),204 (no content),和 304 (not modified) 响应都不能包含 body。所有其他的响应都必须包含一个 entity body 或者 Content-Length header 字段的值被定义为 0。
7.2.1 Type
当消息中包含 Entity-Body,body 的数据类型由 header 字段 Content-Type 和 Content-Encoding 共同决定。这定义了一个 two-layer,ordered 编码模型:
entity-body := Content-Encoding( Content-Type( data) )
Content-Type 指定 underlying data 的 media type。Content-Encoding 被用于解释任何额外的应用于该类型的 content coding,通常用于数据压缩的目的,这是请求资源的一个属性。content encoding 默认为空。
任何包含 entity body 的 HTTP/1.0 消息都应该包含 Content-Type header 字段,以定义 body 的 media type。如果 media type 时未知的,接收方将其视为 “application/octet-stream”。
7.2.2 Length
当消息中包含 Entity-Body,有两种方式可以决定 body 的 length。如果存在 Content-Length header 字段,它的值表示 Entity-Body 的长度。否则,body length 由服务器进行连接的关闭决定(连接关闭,Entity-Body 结束)。
关闭连接不能被用于表明 request body 的结束,因为这样 server 就无法发送响应了。包含 entity body 的 HTTP/1.0 request 必须包含一个合法的 Content-Length header 字段。
8. Method Definitions
8.1 GET
GET 方法意为检索由 Request-URI 标识的信息(以 entity 的格式)。如果 Request-URI 引用一个数据处理程序,应当以 response 中的 entity 的形式返回处理后的数据,而不是返回程序的源码。
如果 request 消息中包含 If-Modified-Since header 字段,GET method 的语义变为 “conditional GET”。有条件的 GET 方法请求仅当标识的资源自 If-Modified-Since header 所给的日期起发生变化时才进行传输。有条件的 GET 方法通过允许缓存的 entities 不用进行多次请求或传输不必要的数据来刷新,来减少网络的使用。
8.2 HEAD
HEAD 方法除去 server 不能再 response 中返回任何 Entity-Body 外,等价于 GET 方法。对 HEAD 请求的响应中 HTTP header 包含的元信息应当与对 GET 请求的响应一致。这一方法能被用于获取由 Requset-URI 标识的资源的元信息而不必传输 Entity-Body。这一方法通常用于测试 hypertext 链接的合法性,可访问性,和最近的修改。
8.3 POST
POST 方法被用于请求目标服务器接受包含在请求中的 entity 作为 Request-Line 中的 Request-URI 标识资源的新的部署。POST 在设计上允许一个统一的方法覆盖下述所有功能:
- 对现存资源的注释;
- 发布消息到电子公告栏,新闻组,邮件列表,或类似的文章组。
- 提供数据块,例如向数据处理程序提供表单的结果。
- 通过追加行为拓展数据库。
一个成功的 POST 不需要 entity 作为 origin server 上的资源被创建,或者 entity 能在将来被引用。即,POST 方法执行的结果可能不会产生能被 URI 标识的资源。在这种情况下,200(ok) 和 204(no content) 都是合适的响应状态,取决于 response 是否包含描述结果的日志。
如果资源被创建于 origin server 上,response 应该是 201(created) 且包含一个 entity (类型优先为 text/html) 用于描述 request 的 status 和引用新的资源。
一个合法的 Content-Length 对所有的 HTTP/1.0 POST 请求来说都是必要的。如果不能决定请求消息内容的长度,HTTP/1.0 server 应该使用 400(bad request) 消息进行响应。
应用不能缓存对 POST 请求的响应,因为应用无法知道 server 将来是否会返回等价的 response。
9. Status Code Definitions
9.1 Informational 1xx
这类状态码指示一个暂时的响应,由 Status-Line 和可选的 headers 组成,以一个空行结束。HTTP/1.0 没有定义任何 1xx 状态码,且它们不是 HTTP/1.0 请求的合法响应。
9.2 Successful 2xx
这类状态码表明客户端的请求被成功的接收,理解和接受。
200 OK
请求成功。返回的响应中的信息取决于请求中的方法
- GET 对应请求资源的 entity。
- HEAD 仅包含 header 信息,没有 entity body
- POST 描述或包含处理结果的 entity
201 Created
请求被满足,新的资源被创建。新的被创建的资源能被返回的响应 entity 中的 URI 引用。origin server 应当在使用这个 Status-Code 之前就创建资源。如果行为不能被立刻执行,server 必须将何时资源可用的描述包含到响应的 body 中;否则,server 应当响应 202 (accepted)。
此规范中定义的方法,只有 POST 能创建资源。
202 Accepted
请求已被接受,但是处理还没有完成。请求最终可能生效也可能不生效,因为当处理实际发生时,它可能不被允许。没有设施会为像这样的异步操作再次发送状态码。
202 响应有意不做承诺。它的目的是允许服务器接受对其他进程 (或许是一天仅允许一次的面向批处理的进程) 的请求,不需要 user agent 与服务器间的连接持续到处理完成。该 response 中返回的 entity 应当包含一个请求当前状态的标识,要么是指向 status monitor 的指针,要么是对用户可以期望的请求被满足的时刻的估计。
204 No Content
server 已经满足了请求,但是没有新的信息需要返回。如果 client 是 user agent,它不应该改变产生这个请求的文档视图。这个响应主要倾向于允许对脚本的输入或其他行为的发生,而不改变 user agent 的活动文档视图。response 可能包含新的元信息,以 entity header 的形式,它应当应用到 user agent 的活动视图的当前文档上。
9.3 Redirection 3xx
此类状态码表示 user agent 应该采取进一步行动,以满足请求。需要的行为可能被 user agent 执行,当且仅当随后的请求使用的方法是 GET 或 HEAD 时,user agent 不与用户交互。user agent 不该重定向一个请求超过 5 次,因为这样的重定向通常表明是无限循环。
300 Multiple Choices
该响应码不直接被 HTTP/1.0 应用使用,但是是 3xx 类型响应的默认解释。
请求的资源在一个或多个位置可用。除非它是 HEAD 请求,response 包含的 entity 应当包含资源特性的列表和 user 或 user agent 能选择的最合适的资源的位置。如果服务器有优先选择项,它应当在 Location 字段中包含一个 URL;user agent 可能使用这个字段值进行自动重定向。
301 Moved Permanently
请求的资源已经被赋值到一个新的永久的 URL 上了,任何未来的对此资源的引用都应该使用新的 URL 完成。具有链接编辑能力的客户端应当尽可能地自动重新链接对 Request-URI 的引用到服务器返回的新的引用。
新的 URL 必须由响应中地 Location 字段给出。除非它是 HEAD 请求,响应的 Entity-Body 应当包含对新的 URL 的简单注释,注释中应包含超链接。
如果 301 状态码在对使用 POST 方法的请求的响应中被接收,user agent 不必自动重定向请求,除非它能被 user 确认,因为这可能会改变请求被发起的条件。
注意: 在收到 301 状态码后自动重定向 POST 请求时,一些现存的 user agent 将错误地将其修改为 GET 请求。
302 Moved Temporarily
请求的资源临时的存在于不同的 URL 下。因为重定向有时可能发生改变,客户端应当继续使用该 Request-URI 进行将来的请求。
URL 在响应中必须在 Location 字段中给出。除非它是 HEAD 请求,响应的 Entity Body 应当包含简短的提示,包含对新的 URI(s) 的超链接。
如果对 POST 请求的响应中收到 302 状态码,user agent 不必自动重定向请求,除非它能由用户确认,因为这可能改变请求被发起的条件。
注意: 在收到 302 状态码后自动重定向 POST 请求时,一些现存的 user agent 将错误地将其修改为 GET 请求。
304 Not Modified
如果客户端执行了一个有条件的 GET 请求且访问是允许的,但是文档自 If-Modified-Since 字段中指定的 date 和 time 起没有被修改,服务器必须使用这个状态码进行响应,且不向客户端发送 Entity-Body。包含在响应中的 Header fields 应当仅包含与 cache manager 相关的信息或独立于 entity 的 Last-Modified date 改变的信息。相关的 header 字段包括:Date,Server,和 Expires。缓存应当更新它的缓存 entity 来反映 304 响应中所给的新的字段值。
9.4 Client Error 4xx
4xx 类的状态码用于客户端出错的场景。如果客户端没有完成请求,就会收到 4xx 状态码,客户端应当立刻结束向服务器发送数据。除了对 HEAD 请求进行响应,服务器应当包含一个 entity,它包含错误场景的解释,无论它的临时的还是永久的状态。这些状态码可以应用到任何请求方法。
注意:如果客户端正在发送数据,TCP上的服务器实现应当保证客户端确认包含响应的 packet(s) 的接收先于 input 连接的关闭。如果客户端在连接关闭后继续向服务器发送数据,服务器的控制器将向客户端发送 reset packet,这样在输入缓存被 HTTP 应用读取和解释前,客户端的未确定的输入缓存可能被删除。
400 Bad Request
服务器无法理解请求,因为请求的畸形语法。客户端在修改前不应该重复请求。
401 Unauthorized
请求需要用户授权。响应必须包含 WWW-Authenticate header 字段,包含一个适用于请求资源的挑战。客户端可能使用一个合适的 Authorization header 字段来重复该请求。如果请求已经包含 Authorization 证书,那么 401 响应表示使用这些证书的授权被拒绝。如果 401 响应包含与先前响应相同的挑战,且 user agent 已经尝试身份验证至少一次,响应中所给的 entity 应当展现给 user,因为 entity 可能包含相关的诊断信息。HTTP 访问授权在 11 章节中阐述。
403 Forbidden
服务器理解请求,但是拒绝满足它。授权不会有帮助,且请求不应该被重复。如果请求的方法不是 HEAD 且服务器希望公开请求没有被满足的原因,它应该在 entity body 中描述拒绝的理由。这一状态码通常用于服务器不希望揭露请求被拒绝的准确原因,或没有其他响应适用。
404 Not Found
服务器没有发现任何匹配 Request-URI 的东西。没有给出任何说明表示这种情况是临时的还是永久的。如果服务器不希望使这一信息对客户端可用,可以适用 403 (forbidden) 状态码替代。
9.5 Server Error 5xx
以数字 “5” 开头的响应状态码表示服务器出错无法执行请求。如果客户端收到 5xx 状态码,没有完成请求,它应当立刻停止向服务器发送数据。除了对 HEAD 请求的响应,服务器应当包含一个 entity,解释错误发生的场景,这是一个临时的还是永久的状态。这些响应码对任何请求方法都适用,没有必须的 header 字段。
500 Internal Server Error
服务器遇到预期之外的情况,使它不能满足请求。
501 Not Implement
服务器不支持满足请求需要的功能。当服务器不能识别请求方法且它不能为任何资源支持该请求方法时,返回该状态码是合适的。
502 Bad Gateway
服务器,当作为网关或代理时,从它访问的上流服务器接收到一个非法的响应。
503 Service Unavailable
服务器现在不能处理请求,因为一个临时的服务器过载或维护。暗示这是一个暂时的情况,一段时间后情况将会得到缓解。
注意:503 状态码的存在并不意味着服务器过载时必须使用它。一些服务器可能希望简单的拒绝连接。
10. Header Field Definitions
10.1 Allow
Allow entity-header 字段列出由 Request-URI 标识的资源支持的一系列方法。这一字段的目的是提醒接收方关于该资源的合法的方法。Allow header 字段不允许在使用 POST 方法的请求中使用,因此如果在 POST entity 中收到 Allow header 字段,它应该被忽略。
Allow = "Allow" ":" 1#method
使用的例子:
Allow: GET, HEAD
该字段不能避免客户端尝试使用其他方法。然而,由 Allow header 字段值表明的方法应当被允许。实际允许的方法由 origin server 定义。
proxy 不能修改 Allow header 字段,即使它不理解其指定的所有方法,因为 user agent 有其他与 origin server 通讯的含义。
Allow header 字段没有表示 server 实现了哪种方法。
10.2 Authorization
user agent 希望服务器对其进行授权 – 通常,但不是必要的,在收到 401 响应后 – 通过在 request 的 request - header 字段中包含 Authorization。Authorization 字段值由 credentials 组成,credentials 包含 user agent 的对请求资源区域的授权信息。
Authorization = "Authorization" ":" credentials
HTTP 访问授权在 Section 11 中描述。如果请求被授权且区域被指定,相同的 credentials 应当对所有对此区域的其他请求都合法。
对包含 Authorization 字段的响应是不能缓存的。
10.3 Content - Encoding
Content-Encoding entity-header 字段被用作 media-type 的修饰符。当出现时,它的值表示应用于资源的额外内容编码,和为了获取通过 Content-Type header 字段引用的 media-type 使用的解码机制。Content-Encoding 主要用于文件在不丢失它的底层媒体类型的标识的情况下进行压缩。
Content-Encoding = "Content-Encoding" ":" content-coding
Content coding 定义于 Section 3.5。使用它的一个例子是:
Content-Encoding: x-gzip
Content-Encoding 是由 Request-URI 标识的资源的一个特征。典型的,使用该 encoding 存储的资源仅在呈现或类似用法前解码。
10.4 Content-Length
Content-Length entity-header 字段表明发送向接收方的 entity-body 的大小,以十进制的八位字节数,或者,在 HEAD 方法的情况下,
表示如果请求是 GET 的话,会发送的 Entity-Body 的大小。
Content-Length = "Content-Length" ":" 1*DIGIT
例如:
Content-Length: 3495
应用应当使用此字段表明要传输的 Entity-Body 的大小,无论 entity 的 media type 是什么。一个合法的 Content-Length 字段值在所有包含 entity body 的 HTTP/1.0 请求消息中都被需要。
10.5 Content-Type
Content-Type entity-header 字段表示发送向接收方的 Entity-Body 的 media type,或者是在 HEAD 方法下,如果替换为 GET 方法,Entity-Body 应当使用的 media type。
Content-Type = "Content-Type" ":" media-type
Media type 定义于 Section 3.6 中。一个使用此字段的例子是
Content-Type: text/html
进一步关于此方法的讨论见 Section 7.2.1
10.6 Date
Date general-header 字段表示消息生成的日期和时间。字段的值是一个 HTTP-date,如 Section 3.3 中所述。
Date = "Date" ":" HTTP-date
一个例子是
Date: Tue, 15 Nov 1994 08:12:31 GMT
如果消息是通过与 user agent 或 origin server 直接连接来接收的话,那么 date 能被假设为接收端的当前日期。然而,因为日期对于评估缓存响应十分重要,origin server 应当总是包含 Date header。即使它是可选的,客户端也应当仅在包含 entity body 的消息中发送 Date header,正如在 POST 请求中那样。不包含 Date header 字段的接收消息应当应当通过接收方赋予一个,如果消息要被接收方缓存或者网关通过一个需要 Date 的协议。
理论上,date 应该表示在 entity 生成之前的时刻。实践中,date 能在消息组织的任意时刻生成,不会影响它的语义值。
10.7 Expires
Expires entity-header 字段给出 date/time,在该时刻后 entity 就被认为是过期了的。这允许信息提供方暗示资源的易变性,或者日期在,那之后信息不再合法。应用不能缓存这一 entity 超过所给的日期。Expires 字段的存在并不意味着在该时刻之前,之时或之后,资源将改变或终止其存在。然而,知晓,甚至怀疑在一确定日期资源将改变的信息提供方应当包含 Expires header 指示该日期。格式时一个绝对的日期和时间,如同在 Section 3.3 中定义的 HTTP-date。
Expires = "Expires" ":" HTTP-date
使用它的例子是:
Expires: Thu, 01 Dec 1994 16:00:00 GMT
如果所给日期等于或早于 Date header 的值,接收方不缓存封闭的 entity。如果资源是天然动态的,正如很多数据处理程序中那样。来自资源的 entities 应当被给予一个合适的 Expires 值,它反映了资源的动态性。
Expires 字段不能用来强制 user agent 刷新显示或重新加载资源;它的语义仅应用于缓存机制,当对该资源的新的请求被发起时,仅需要检查资源的过期状态即可。
User agent 通常由历史机制,例如 Back 按钮和历史列表,它们可以用于再次展示该会话中早期检索的 entity。默认情况下,Expires 字段不应用于历史机制。如果 entity 依然在存储中,历史机制应当展示它,即使 entity 已经过期了,除非用户将 agent 配置为刷新过期历史文档。
10.8 From
From request-header 字段,如果给出了的话,应当包含一个互联网 e-mail 地址,为控制请求的 user agent 的人类用户。地址应该是 machine-useable。
From = "From" ":" mailbox
一个例子是:
From: webmaster@w3.org
这一 header 字段能用于登录目的,作为一种标识非法资源或不期望的请求的方法。它不应该被用于访问保护的一种不安全的形式。这一字段的解释是请求代表所给的人被执行,他承担方法执行的责任。特别的是,robot agents 应当包含这个 header,这样负责运行 robot 的人就能被联系到,如果接收端发生问题的话。
10.9 If-Modified-Since
If-Modified-Since request-header 字段和 GET 方法一起使用来使他变成有条件的:如果请求的资源自该字段指定的时间起没有被修改,服务器将不会返回资源的拷贝,一个 304 (not modified) 响应将会被返回,不携带 Entity-Body.
If-Modified-Since = "If-Modified-Since" ":" HTTP-date
一个该字段的例子是:
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT
有条件的 GET 方法的请求所标识的资源仅当自 If-Modified-Since 标识的日期起资源被修改了才会被传输。判定这一点的算法包含如下情境:
a) 如果请求会导致除 200 (ok) 外的任何结果,或者传入的 If-Modified-Since 日期非法,响应与寻常的 GET 方法无二。比服务器当前时间更晚的日期非法。
b) 如果资源自 If-Modified-Since 日期后被修改了,响应与寻常的 GET 无二。
c) 如果资源自合法的 If-Modified-Since 日期没有被修改,服务器将返回 304 (not modified) 响应。
这一特征的目的是允许缓存信息的有效更新,最小化事务的开销。
10.10 Last-Modified
Last-Modified entity-header 字段表明发送方认为的资源最后一次修改的日期和时间。这一字段的准确语义由接收方应该如何解释它来定义:如果接收方有这一资源的 copy,它比 Last-Modified 字段所给的日期大,copy 应当被认为不变。
Last-Modified = "Last-Modified" ":" HTTP-date
一个例子是:
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
这一 header 字段的准确含义取决于 sender 的实现和最初的资源的特性。对于文件,它可能就是文件系统最后一次的修改时间。对于动态包含部分的 entities,它可能是对它的组件修改时间集合中最近的一次。对于数据库网关,他可能是该条记录最后一次更新的时间戳。对于虚拟对象,它可能是内部状态改变的最后时间。
origin server 不能发送一个迟于服务器的消息开始时间的 Last-Modified 日期。在这种情况下,资源的最后一次修改表示的是未来的某个时间,服务器必须用消息开始时间来替换该时间。
10.11 Location
Location response-header 字段定义由 Request-URI 标识的资源的确切位置。对于 3xx 响应,location 必须表明服务器优先使用的用于自动重定向资源的 URL。仅允许一个绝对的 URL。
Location = "Location" ":" absoluteURI
一个例子是
Location: http://www.w3.org/hypertext/WWW/NewLocation.html
10.12 Pragma
Pragma general-header 字段被用于包含实现指定的指令,可能应用于沿着接收/响应链的接收方。所有的 pragma 指令从协议的视角指定可选的行为;然而,一些系统可能需要由指令组合的行为。
Pragma = "Pragma" ":" 1#pragma-directive
pragma-directive = "no-cache" | extension-pragma
extension-pragma = token [ "= " word]
当 “no-cache” 指令出现在请求的消息中,一个应用应当向 origin server 转发请求,即使它有所请求的资源的缓存拷贝。这允许客户端坚持收到请求的授权响应。这也允许客户端刷新损坏或失效的缓存拷贝。
Pragma 指令必须通过代理或网关应用传递出去,不管它们对该应用有何意义,因为指令可能要应用到所有沿请求/响应链的接收方。不可能对指定的接收方指定一个 pragma;但是,任何与某接收方不想管的 pragma 应当被该接收方忽略。
10.13 Referer
Referer request-header 字段允许客户端指定 Request-URI 包含的资源的地址(URI)。这允许服务器生成资源的反向链接的列表,为了兴趣,日志,优化缓存等目的。它也允许废弃或输错的链接被追踪。Referer 字段不能被发送,如果 Request-URI 没有从自己所有的 URI 的源中获取,例如从用户的键盘中输入。
Referer = "Referer" ":" (absoluteURI | relativeURI)
例子:
Referer: http://www.w3.org/hypertext/DataSources/Overview.html
如果给出部分 URI,它应当相对于 Request-URI 做出解释。URI 不能包含片段。
10.14 Server
该服务器 response-header 字段包含关于被 origin server 使用的用于处理请求的软件的信息。该字段能包含多个产品 tokens (Section 3.7) ,标识服务器的注释和任何有意义的子产品。便利起见,产品 tokens 以对识别应用的重要性的顺序列出。
Server = "Server" ":" 1*(product | comment)
例子:
Server: CERN/3.0 libwww/2.17
如果响应通过代理转发,代理应用不能向产品列表添加它的数据。
10.15 User-Agent
User-Agent request-header 字段包含发起请求的 user agent 的信息。这是为了策略性目的,追踪协议版本的变化,和自动识别 user agent, 以定制针对特定 user agent 的响应,从而避免其缺陷。虽然不是必要的,user agent 应该包含在请求的字段内。字段能包含多个 product tokens (Section 3.7) 和注释以标识 agent 和任何对形成 user agent 有重要意义的部分。方便起见,product tokens 以在标识应用的重要程度进行排序。
User-Agent = "User-Agent" ":" 1*(product | comment)
Example:
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
10.16 WWW-Authenticate
WWW-Authenticate response-header 必须包含在 401(unauthorized) 响应消息中。字段值至少有一个 challenge 组成,表示适用于该 Request-URI 的认证方案和参数。
WWW-Authenticate = "WWW-Authenticate" ":" 1#challenge
HTTP 访问认证进程描述于 Section 11。User agent 必须在解析 WWW-Authenticate 字段值方面十分小心,如果它包含超过一个 challenge 或提供了超过一个 WWW-Authenticate header 字段,因为 challenge 的内容可能本身包含一个逗号分隔的认证参数列表。
11. Access Authentication
HTTP 提供一个简单的 challenge-response 认证机制,它可能被用于服务器挑战客户端请求或者客户端提供认证信息。它使用一个可拓展的,大小写不敏感的 token 来识别身份验证方案,随后是由逗号分隔的属性-值对的列表,它们携带该方案进行身份验证的必要参数。
auth-scheme = token
auto-param = token "=" quoted-string
401 (unauthorized) 响应信息被 origin server 用于挑战 user agent 的身份认证。响应必须包含 WWW-Authenticate header 字段,它包含至少一个适用于请求资源的 challenge。
challenge = auth-scheme 1*SP realm * ("," auth-param)
realm = "realm" "=" realm-value
realm-value = quoted-string
对所有发起挑战的身份认证方案都需要范围属性(大小写不敏感的)。范围值(大小写敏感),与被访问的服务器的 root URL相结合,定义了保护区域。这些范围允许服务器上的被保护的资源被划分为一系列的保护空间,每一个有它自己的身份认证方案和/或身份认证数据库。范围值是一个字符串,通常由 origin server 进行赋值,它可能有额外的由身份认证指定的语义。
如果 user agent 希望服务器对自己进行身份认证,通常情况下但不是必须的,它在收到一个 401 响应后,可能通过在请求中包含一个 Authorization header 字段来这样做。Authorization 字段值由证书组成,证书包含 user agent 对被请求资源区域的身份认证信息。
credentials = basic-credentials
| (auth-scheme #auth-param)
user agent 自动应用证书的域由保护空间决定。如果先前的某个请求被授权,一段时间内,相同的证书可能在所有对该保护空间的请求上重用,时间取决于身份验证方案,参数,和/或用户偏好。除非身份认证方案另外定义,单个的保护空间不能拓展出服务器范围之外。
如果服务器不希望接受请求发送的证书,它应当返回 403 (forbidden) 响应。
HTTP 协议不限制应用只能使用这一简单的 challenge-response 机制来进行访问身份认证。也能使用额外的机制,比如传输层的加密或通过消息封装,和使用额外的 header 字段指定身份认证信息。然而,这些额外的机制并不定义在此规范中。
对于 user agent 的身份认证,代理必须是完全透明的。即,它们必须直接转发 WWW-Authenticate 和 Authorization headers,不做任何处理,不能缓存对包含 Authorization 的请求的响应。HTTP/1.0 不为客户端提供方法向代理进行身份验证。
11.1 Basic Authentication Scheme
基础的身份认证方案基于 user agent 必须使用 user-ID 和 密码对每个区域进行身份验证的模型。区域值应当被认为是一个不透明的字符串,它只能与服务器上的其他区域比较等价性。仅当服务器确认 user-ID 和 密码对 Request-URI 的保护空间合法,服务器才会授权请求。没有可选的身份认证参数。
对于收到一个未授权对某保护空间中的 URI 的请求的接收方,服务器应当使用一个 challenge 进行响应,如下所示:
WWW-Authenticate: Basic realm = "WallyWorld"
“WallyWorld” 是由 server 赋值的字符串,用于识别 Request-URI 的保护空间。
为了接收授权,客户端发送 user-ID 和密码,使用一个冒号 “:” 分隔,以证书中的一个 base64 编码的字符串格式。
basic-credentials = "Basic" SP basic-cookie
basic-cookie =
userid-password = [ token ] ":" *TEXT
如果 user agent 期望发送 user-ID “Aladdin” 和密码 “open sesame”, 它应当使用下述 header 字段:
Authorization : Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
基础的身份认证方案是一种过滤对 HTTP 服务器上的资源进行未授权访问的不安全的方法。它基于假设客户端和服务器之间的连接能被认为是可信的载体。因为在一个开放的网络上,这通常是不能得到保证的,所以基础的身份认证方案应当根据实际情况使用。尽管如此,客户端应当实现这一方案以与使用它的服务器进行通讯。
12. Security Considerations
本节意在提醒应用开发者,信息提供方,和用户 本文档所描述的 HTTP/1.0 在安全方面的局限性。讨论不包含所提出问题的最终解决方法,虽然确实给出一些建议来减少安全风险。
12.1 Authtication of Clients
正如 Section 11.1 中提到的,Basic 身份认证方案不是一个关于用户身份认证的安全的方法,它也不能避免 Entity-Body 使用明文在物理网络上进行传输。HTTP/1.0 允许使用另外的身份验证方案和加密机制来增加安全性。
12.2 Safe Methods
GET 和 HEAD 方法不应当采取其他有意义的行为,除了检索。这些方法应当被认为是 ”safe“ 的。
12.3 Absue of Server Log Information
12.4 Transfer of Sensitive Information
如同任何通用的数据传输协议一般,HTTP 不能控制数据传输的内容,或者有任何先天的方法决定任何所给请求中的内容中的信息片的敏感性。因此,应用应当尽可能地向信息地提供方提供对信息的控制。在此上下文中有三个 header 字段值得注意:Server,Referer 和 From。
如果某版本软件被知晓有安全漏洞,揭示指定的服务器软件版本可能使服务器机器更易受到对被该版本软件的攻击。实现者应该使该 Server header 字段成为一个可配置选项。
Referer 字段允许研究读取模式,且绘制反向链接。虽然它可能十分有用,但是如果用户的细节没有从 Referer 中包含的信息分离出来,这一能力可能会被滥用。甚至当私人信息已经被移除了,Referer 字段可能表明一个私有的文档 URI,公开该 URI 是不合适的。
From 字段发送的信息可能与用户的隐私利益或他们站点的安全政策有冲突,因此在用户不能启用,禁止或修改字段内容时,它不应该被传输。用户必须能依据用户偏好或应用模式配置来设置该字段的内容。
我们建议(虽然不要求)为用户提供一个方便的切换接口,以启用或禁用From和Referer信息的发送.
12.5 Attack Based On File and Path Names
HTTP origin server 的实现应该限制由 HTTP 请求返回的文档应当仅是服务器管理员预期中的文档。如果 HTTP 服务器直接将 HTTP URIs 翻译为文件系统调用,服务器必须十分小心不要服务于不打算向 HTTP 客户端传递的文件。例如,Unix,Microsoft Windows,和其他操作系统使用 “…” 作为路径的组成以一个在当前目录之上的目录。在这样的系统上,HTTP 服务器必须禁止任何诸如此类的构造出现在 Request-URI 中,否则它将允许在 HTTP 服务器期望能被访问的资源之外的资源被访问。类似的,仅在服务器内部能被引用的文件(例如访问控制文件,配置文件,和脚本代码)必须远离不合适的检索,因为它们可能包含敏感信息。经验表明,这样的 HTTP 服务器实现中的小小 bugs 都会成为安全隐患。