java毕业设计——基于java+Jsoup+HttpClient的网络爬虫技术的网络新闻分析系统设计与实现(毕业论文+程序源码)——网络新闻分析系统
基于java+Jsoup+HttpClient的网络爬虫技术的网络新闻分析系统设计与实现(毕业论文+程序源码)
大家好,今天给大家介绍基于java+Jsoup+HttpClient的网络爬虫技术的网络新闻分析系统设计与实现,文章末尾附有本毕业设计的论文和源码下载地址哦。需要下载开题报告PPT模板及论文答辩PPT模板等的小伙伴,可以进入我的博客主页查看左侧最下面栏目中的自助下载方法哦
文章目录:
- 基于java+Jsoup+HttpClient的网络爬虫技术的网络新闻分析系统设计与实现(毕业论文+程序源码)
-
- 1、项目简介
- 2、资源详情
- 3、关键词:
- 4、毕设简介
- 5、资源下载
1、项目简介
- 利用相关网络爬虫技术与算法,实现网络媒体新闻数据自动化采集与结构化存储,并利用中文分词算法和中文相似度分析算法进行一些归纳整理,得出相关的新闻发展趋势,体现网络新闻数据的挖掘价值。
2、资源详情
项目难度:中等难度
适用场景:相关题目的毕业设计
配套论文字数:24872个字57页
包含内容:整套源码+完整毕业论文+辅导视频+运行截图
3、关键词:
网络爬虫;网络新闻;数据挖掘4、毕设简介
提示:以下为毕业论文的简略介绍,项目源码及完整毕业论文下载地址见文末。
1 绪论
1.1 论文研究背景与意义
省略
1.2 论文研究内容
若要实时监测网络新闻的发展与变化,则必须使用相关工具,人工的速度太慢,这时候网络爬虫就应运而生了。爬虫需要定时爬取相关网络媒体页面,获取页面源码并进行解析,取出正文部分。这里面涉及到过滤算法,或者是网页结构的解析算法,同时还涉及到如何应对网站反爬虫策略,主要分为以下几个部分:
爬虫技术:采用什么语言、什么框架来写爬虫,现阶段有什么样的流行的java爬虫框架?如何从松散、非结构化的网络新闻中得到结构化的、紧凑的网络新闻数据。
网页处理技术:如何处理js、面对ajax加载的网站该使用什么样的策略,以及如何从html语句中准确抽取出文章正文,同时还要提防网站的反爬虫技术,需要的时候爬虫请求头还可能需要带上cookie等等。
中文分词技术:能够以相对较高的准确率将抽出出来的正文进行中午分词,以便后续使用分词来确定文章的相似性。网络新词层出不穷,所以分词是否能准确识别未知的新词很是重要。目前分词工具准备使用采用Lucene作为核心的IK分词、或者国产的Ansj中文分词等分词工具。
省略
2 系统需求分析
软件需求分析对软件系统提出了清楚、准确、全面而具体的要求,是对软件使用者意图不断进行揭示与准确判断的过程,它并不考虑系统的具体实现,而是严密地、完整地描述了软件系统应该做些什么的一种过程。
2.1 系统需求概述
要求爬虫系统能完成对凤凰网新闻、网易新闻、新浪新闻、搜狐新闻等网站新闻数据的实时抓取,并正确抽取出正文,获取新闻的点击量,实现每日定时抓取。能将抓取回来的新闻进行中文分词,利用中文分词结果来计算新闻相似度,将相似的新闻合并起来,同时也合并点击率,最后一点,能将相似因为一段事件内的用户点击趋势以合适的形式展现出来。
基于网络爬虫技术的网络新闻分析由以下几个模块构成:
网络爬虫模块。
中文分词模块。
中文相似度判定模块。
数据结构化存储模块。
数据可视化展示模块。
2.2 系统需求分析
2.2.1 系统功能要求
按照对系统需求调用的内容分析,系统功能划分为了一下五个模块:
数据采集模块:
数据采集模块负责数据采集,即热点网络新闻数据的定时采集,以及数据的初步拆分处理。
(1)中文分词模块:
中文分词模块能将数据采集模块采集到的热点网络新闻数据进行较为准确的中文分词。
(2)中文相似度判定模块:
中文相似度判定模块通过将数据采集模块采集到的热点网络新闻数据结合中文分词模块的分词结果,进行网络热点新闻的相似度分析,并能够将相似新闻进行数据合并。
(3)数据结构化存储模块:
数据结构化存储模块贯穿在其他模块之中,在数据采集模块中,负责存储采集拆分后的热点网络新闻数据;在中文分词模块中,负责从数据库读出需要分词处理的网络新闻数据;在中文相似度判定模块中,负责从将分析得到的相似新闻进行存储;在数据可视化展示模块中负责将相似热点新闻数据从数据库读出,其中涉及到大量关于数据库资源的处理。
(4)数据可视化展示模块:
数据可视化展示模块负责将中文相似度判定模块判定为相似新闻的数据以可视化的形式展示出来,展示形式可以自定义。
2.2.2 系统IPO图
整个系统的IPO图如图2-1。
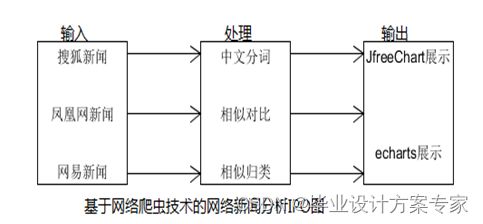
图2-1 系统IPO图
爬虫输入新闻数据,然后处理分析,最后用可视化界面展示出来。
2.2 系统非功能性需求分析
本系统设计的非功能性需求涵盖了一下几个方面:
性能需求:
要求爬虫能并行爬取网络新闻,并行分析,数据库的并发处理能力要足够强。
可靠性需求:
要求系统运行能保持稳定持久状态,没有明显的BUG
易用性需求:
要求爬虫系统能做到尽可能的自动化,争取不需要人为操作。
维护性需求:
要求系统出现BUG能比较容易的修复,系统的后期拓展功能较强。
3 系统概要设计
省略
3.1 设计约束
3.1.1 需求约束
系统能稳定运行在最低为JDK1.7的平台上。
数据库向后兼容,最低适配Mysql5.1。
要求程序有较好的跨平台性,可以同时运行在Linux、windows、Unix系统上。
要求数据库连接方面,设置的密码足够复杂,数据库连接管理良好,数据库系统能健壮运行。
禁止使用商业性软件,在本系统中使用的算法或是类库必须是免费的。
系统对系统配置的要求要尽可能低。
程序具有良好的可移植性、兼容性、安全性。
3.1.2 设计策略
省略
3.1.3 技术实现
本系统设计与开发工具采用以下配置:
开发语言:java JDK版本1.7。
Java是一种具有非常棒的面向对象的设计思想的一门计算机语言语言。Java 技术具有很高的生产力,原因是大量的程序员为其贡献了大量的代码,目前Java程序广泛应用于Web、企业管理系统、云计算、大数据计算等方面,同时Java目前在全球的编程语言的稳居第一。
开发环境:Eclipse。
Eclipse 一开始是IBM旗下的一款开发工具,知道后来被IBM贡献给了开源社区,虽然开源,但是其功能一点也不逊于专业收费类型的开发IDE,Eclipse有着强大的开源活力,以及良好的扩展性,很容易在论坛上下载到各种各样为Eclipse量身定制的插件,所以开发本系统采用了Eclipse作为开发IDE。
3.3 模块结构
3.3.1 模块结构图
爬虫系统软件结构图:
向爬虫系统输入网页URL,爬虫打开网页解析处理抽出网页正文,然后输出网页正文,如图3-1所示。
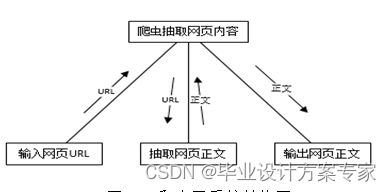
图3-1 爬虫子系统结构图
将网页正文传入系统,系统根据词库以及相关策略开始分词,最后将分词结果以数据形式(词组的形式)输出出来,如图3-2所示。

图3-2 分词子系统结构图
首先第一步输入数据:网络爬虫系统采集到的数据作为相似度匹配系统的输入,然后进入处理过程,处理过程采用了改进了的余弦定理进行处理,然后系统返回处理后的结果,最终本系统将处理后的结果作为输出,并传递给下一个子系统进行处理,如图3-3所示。

图3-3 文章相似度匹配系统结构图
3.3.2 系统层次图
本系统设计为分别由三个子系统组成,分别是:网络爬虫系统即数据采集系统、新闻分析系统即中文语料相似度分析系统和最终结果展示系统,如图3-4所示。

图3-4 系统层次图
3.3.3 面向对象设计UML图
(1)在这里首先介绍一下系统中使用的数据库连接池,MF_DBCP自己写的一个数据库连接池,UML类图如图3-5所示。

图3-5 系统类图
在DBCP连接池UML图中,定义了数据库异常抛出类,数据库配置的POJO类,数据库连接池核心类 Pool 以及代理实现了Connection的close() 方法、setAutoCommit()等方法,还有数据库连接池监视器类,用来监视数据库的健康状况等等。
(2)爬虫核心是Web类,凤凰网新闻、搜狐新闻、网易新闻分别集成了核心Web类,然后各自实现各自的解析规则,核心Web类负责一些基础操作,例如打开网页,获取网页源码,还有一些正则表达式抽取分析算法,其实,Web类也包含了POJO类的作用,也是作为爬虫爬取新闻后生成的结果的载体,如图3-5所示。

图3-5 爬虫系统类图
4 系统详细设计
省略
4.1 系统模块设计
系统结构逻辑上由四个部分组成:第一个部分是数据采集模块,负责原生网页文档数据采集与正文抽取;第二个部分是采集数据固化模块,将数据采集模块采集回来的原始网页文档进行入库固化;第三个部分负责网页文档数据的处理与分析,从数据库读取原始网页文档数据之后进行中文分词,然后根据分词结果再进行相似度分析,并将分析结果为同一相似新闻的结果进行存储;第四层是数据展示模块,负责将分析整理后的数据以图表的形式绘制出来。
4.1.1 数据采集模块
数据采集模块(爬虫系统)采集工具使用了HttpClient框架,配合正则表达式解析,抽取网页内容。HttpClient是Apache Jakarate Common下的一个子项目,开源而且免费,HttpClient起初的目的是为了做web测试用的,后来其功能不断完善,不断加强,在功能上基本上可以以假乱真真的浏览器,但它并不是一个浏览器,仅仅是实现了浏览器的部分功能。HttpClient目前已经应用在很多的项目中,比如Apache Jakarta上很有名的另外两个开源的项目Cactus和HTMLUnit都使用了HttpClient。HttpClient基于标准而且纯净的Java语言,实现了Http1.0和Http2.0,以可扩展的面向对象的机制实现了Http协议的全部方法(GET,POST,PUT,DELETE,HEAD,OPTIONS,TRACE),并且支持Https协议,通过Http代理建立起透明的连接,利用CONNECT方法通过Http代理隧道的Https连接,支持NTLM2 Session,SNENPGO/Kerberos,Basic,Digest,NTLMv1,NTLMv2等认证方案,而且自带插件式的自定义认证方案。HttpClient设计时候注重了可扩展性以及自定义性,所以HttpClient能支持各种各样的不同的配置方案。同时在多线程的环境下HttpClient使用起来更加方便自如,HttpClient中定义了网页连接管理器,可以自动管理各种网页连接,能发现处于非正常的连接并关闭,起到了很好的防止内存泄漏的作用。HttpClient能自动处理Set-Cookie中的Cookie,可以插件式的自定义Cookie策略,Request的输出流可以有效地从Socket服务器中直接读取相关的内容。在Http1.0和Http1.1中利用Keep-Alive保持长久(持久)连接,可以直接获取服务器发送的response code和headers。另外,HttpClient可以设置连接超时,实验性的支持Http1.1 response cahing。
使用HttpClient GetMethod来爬取一个URL对应的网页,需要如下步骤:
生成一个HttpClient对象并设置相应的参数。
生成一个GetMethod对象并设置相应的参数。
利用HttpClient生成的对象来执行GetMethod生成的Get方法。
处理返回的响应状态码。
如果响应正常,则处理Http响应内容。
释放连接。
获取了响应内容后需要解析Html DOM对象,这里选用了jsoup。Jsoup是一款Java的Html文档解析器,可以直接解析某个URL地址,但是这里选用了HttpClient代替了他去获取Html DOM对象,因为jsoup自带的打开并解析URL的功能是一个比较基础的功能,远不如HttpClient提供的丰富,在这里,本文采用别的工具来替代Jsoup来获取Html DOM对象,比如上文介绍的HttpClient,获取了网页文档数据之后,可以把网页文档数据以字符串的形式传递给Jsoup来进行Html解析。在Html文档的解析方面,Jsoup自带了很多非常非常方便的方法与API,例如:可以像jQuery那样来直接操作HTML网页元素,此外还有其他提取HTML文档中需要的内容的方法,读者可以自行阅读Jsoup的官方使用文档。最后一点,也是很重要的一点,使用Jsoup是完全免费的,包括对其进行代码上的复制与克隆,可以根据项目的不同需求来修改Jsoup的源码,作为一个相当受欢迎的Html文档解析器,Jsoup具有以下的优点:
Jsoup能直接解析网页URL从中取出需要的内容,也可以直接抽取Html文档字符串来进行解析工作;
Jsoup是实现了CSS的选择器,可以像jQuery那样直接操作元素;
Jsoup 不仅能方便的处理Html文档正文内容,还能处理Html文档元素的相关元素,如获取Html标签的属性等功能;
除此之后,有一个很重要的特性,目前很多网站采用了不同的后台环境,有Java、PHP、Python、Node.js等作为开发工具,Web开发框架更是五花八门,所以很可能会出现一些纰漏,如网页标签缺乏闭合的部分,熟悉Html的人都知道,Html语言是一种容错性极高的语言,即使标签未能适时的闭合,浏览器也是能正常显示网页的,但是对于这些通过网站Html文档来获取网页信息的人来说,这个特点是非常致命的,会对最终的解析结果产生很大的负面影响。然而使用Jsoup完全可以避免这个问题,Jsoup设计的时候已经想到了这些问题,其对Html标签的闭合等特性也是具有容错性的,例如下面几种状态:
1.Html文档出现了没有关闭的html标签(比如:
陈晋豪的论文
论文写起来挺难
内容有了就好了
AB123
)2.Html文档数据中的隐式标签
(比如:它可以自动将 表格 包装成)
3.能创建非常可靠的Html文档结构(比如:html标签包含head 和 body,在head只出现恰当的元素)
爬虫系统的爬取对象分别选择了凤凰网新闻、网易新闻、搜狐新闻,因为这些新闻都开放了点击数量查询,且这三大媒体无论是影响上,还是覆盖面上,都是非常巨大非常广泛的,非常适合作为爬取对象,爬取过程中也没有复杂的Ajax需要处理,而且这些新闻的访问数据都是每天更新的。
爬虫程序需要以循环定时运行在响应的服务器上,每天定时爬取以上网站的新闻内容,并存入数据库,数据库采用了Mysql,因为Mysql比较轻量级,有免费的学术研究的版本,而且比较适合当前场景。Mysql数据库引擎采用了MyIASM,按理来说,MyIASM是比较古老的引擎,但是MyIASM存储引擎在曲度方面的性能要好于INNODB,虽然不支持事务,但是爬虫存储暂时不涉及事务的使用,再加上MyIASM优秀的插入查询速度,使得爬虫数据的存取非常快捷、迅速,所以这里选择了MyIASM作为Mysql的存储引擎。
数据采集系统的爬虫在爬取网站是采用多线程并发爬取的,所以多线程的爬虫对数据库的并发操作会有很多很多,在进行数据库操作的时候,第一步是建立数据库连接,在多线程的环境下,这些操作会进行得非常频繁,但是这些操作又非常的耗费网络、内存空间等,这些操作会对系统资源、系统运行效率有很大的负面影响,所以必须采用数据库连接池。网上有很多开源而且优秀的数据库连接池,比如Apache开源的dbcp,平时tomcat使用DateSource配置连接池的时候就是使用了tomcat内置的dbcp连接池,此外还有c3p0数据库连接池,也是非常优秀的连接池,SSH三大框架之一的Hibernate就采用了c3p0作为其内置连接池,其优秀性能可见一斑,不过这些连接池相对来说都比较重量级,所以自己在这里写了一个相对比较轻量级的连接池MF_DBCP,下面会介绍下自定义连接池相关内容。
省略
监视器初始化后开启两个线程:
1.号线程根据配置文件中的 status_checktime 字段来周期性运行实现扫描连接池中的坏链接并修复
2.号线程根据配置文件中的 num_checktime 字段来周期行创建连接池使用状态的快照,当足够三个状态时,根据三点画出的曲线来确定数据库连接池中到底需要保存多少连接,并保证连接数不小于最小连接数。
以下用 + 表示当前快照连接数大于前一快照,–表示当前快照连接数小于前一快照:
+++ 监视器不做任何动作,因为连接数在稳步增加;
-± 监视器末尾保留最后两个连接快照的平均连接数,剩下的多余连接回收;
— 监视器保留三个快照平均连接数作为当前连接,剩下的多余连接回收;
自定义数据库连接池的相关API如下:
addNew() 方法为连接池增加新的连接;
addLast() 方法为未开启事务从而可以共享的连接提供”负载均衡”的策略(当一个连接被使用一次,则将他放入队列末尾,试想这样可以循环队列);
deleteFirst() 方法循环调用可以清空连接池队列;
delete() 方法提供了从连接池中移除某个连接的方法;
getFirst() 方法提供了获取负载最轻即队首的连接;
getLoad() 方法提供了获取指定连接负载大小的方法;
getConnectionContainer() 方法提供了获取某个连接所在的连接容器(从而操作连接池中的连接池容器队列);
remove() 方法提供了从连接池中移除某个开启了事务的连接,deleteLater() 方法提供了获取数据库中可以清除(负载等于0)的连接;
getMinLoadConnection() 方法提供了获取连接池中负载最低的连接以便创造专用的事务连接;
getConnectionContainers() 方法为外界提供了获取数据库连接池队列的方法;
isFullFree() 方法判断当前连接池是否完全处于空闲状态(关闭连接池判断);
size() 方法提供获取连接池除去事务连接剩余连接的数量;
createConnection() 方法为连接池提供创造新连接的方法;
destoryConnection() 方法指定关闭某个连接;
repairPool() 方法提供了修复连接池中坏连接的方法,并用新的可用的连接替换; releasePool() 方法提供了连接池收缩大小的方法,确保保留的连接数是最合适的;
revokeConnection() 方法提供了回收连接,将其重新加入连接池队列的方法;
getConnection() 当用户需要连接时调用;
getPoolStatus() 返回当前连接池的使用情况;
close() 关闭数据库连接池;
4.1.2 中文分词模块
首先简单地介绍下中文分词的概念,中文分词也就是经过相关的算法,把原来的汉语句子或者更长的汉语语料正确分割成为一个一个的汉语词语的过程。
说到中文分词,先来介绍下英文的分词,计算机由欧美人发明,所以他们很早就进行了有关英文分词的研究,本文从简到繁进行介绍,英文分词很简单,人们平时阅读到的英文文章,英文单词与单词之间都有一个空格,利用这个特点,程序可以非常迅速的将英文文章进行英文分词。这时候回过头来看看汉语,发现问题来了,除了语句中的标点符号,基本上所有的汉语都是连续的,并没有非常明显的分割的特征。这时候原来用于英文分词的那一套工具在汉语语料的分词方面完全没有一点作用了,当然,也不能要求在汉语写作中学习英文的方式,在词语与词语之间用空格作为间隔,所以需要专门研究下汉语的分词策略。
这时候,再回到英文分词的思路上,从小到大,可没少学过英语短语,是不是发现了什么?英文短语与短语之间的分词也不能单纯的用空格作为判断了。但是英文单词之间的组合以及规律要明显比汉语强很多很多,但是汉语拥有世界上最大的使用群体,研究汉语中文分词技术还是非常非常有必要的。到底怎么进行汉语中文分词呢?所以首先得研究研究汉语的语法。
在这里声明下,汉语中文分词目前并不涉及到汉语古文的分词,具体的原因是因为古文的分词难度泰国巨大,基本上无规律可言。
经过这些年大量计算机爱好者和学术工作者的研究探索,逐渐推出了一些半成熟的中文分词的算法,中文分词的路上举步维艰,还需要各位加油研究。在这里本文先介绍下几种比较常见中文分词的算法:
(1)字符匹配的中文分词方法
字符匹配的中文分词方法时基于语料词典的分词算法,分词结果的准确性很是依赖是否有一个好的分词词典,算法的具体内容是,首先将分词词典以某种数据结构的形式载入内存,一般都是Hash散列存储的方式,因为这个方式有极快的查找速度,然后根据分词词典中的词语去匹配要分词的中文语料字符串,经过一些比较细腻的匹配规则,最终能够成功将该汉语语料字符串拆分成不重复的若干汉语词语,即匹配完成。
再拆分要分词的汉语语料时候,应该结合多种多样的拆分方法,因为不同的拆分方法可能会带来完全不同的分词结果。面对一个随机的符合规范的汉语语料,如果它具有足够的长度,足够清晰而且不存在理解歧义的情况下,从不同的拆分方法出发,最终得到的分词结果一定是一致的。
利用计算机分词的话,必定存在着很多奇奇怪怪的分词结果,完全可以采用统计学的方法来提高最终的分词结果集的正确命中率。具体的做法是,定制多个拆分汉语语料的算法,然后分别计算其最终的分词结果,然后统计最终的结果集,哪一部分分词结果在最终分词的结果集中出现的次数最多,则就取该分词作为最终的分词结果。
本文最终采用的分词方法即为本分词方法的改进版本,结合了IK分词和Lucene的一些特性。字符匹配的中文分词算法对一个合适的分词词典依赖非常大,那么如何得到这个分词词典呢?最笨的办法就是人工审阅新闻资料,或者下载汉语字典,提取其中的词语作为分词词典,其次,分词词典还需要进行不断进化。层出不穷的网络新词,对分词结果造成了巨大的挑战,这里就不讨论程序自学习以及词典的自动扩展算法了。常用的中文分词算法有下面几种:
(2)语义分析理解的中文分词方法
这种中文语料的分词方法时首先要分析得出汉语的语义、语法、句法等,得出这些规律目标是能利用这些规律来让计算机能理解汉语语句的意义,但是这种方法看似完美,但是有很遥远。首先想要彻底能总结出这些规律本身就是非常复杂的,因为汉语整个语法体系的复杂性,还有就是汉语的灵活组合性,不同的组合就是不同的意思,例如“我还欠了他的钱”,这句话如果把“还”念作“hai”,整个句子的意思是“我现在还欠着他的钱”,但如果把“还”念作“huai”,那整个句子的意思就变成“我还钱了,把欠他的钱都还给他了”,这种情况识别就一定会出现问题。再者就是如果得出了这些规律,也要把这些规律以编程的方式实现出来,这个过程也是非常困难的。语义分析理解的中文分词方法是跟人工智能的发展息息相关的,如果能实现基于语义分析的中文语料的分词,那么人工智能也能获得长足的发展。
因为本算法的研制工程周期长,且困难,目前在国际上都还处于概念阶段。就算实现了对汉语的语义语法理解,世界上还有其他语言:英语、俄语、法语、阿拉伯语等等语言,发展历程必然艰难。本文在此提及此方法仅作为一种思路,目前没有实现的思路。
(3)统计的中文分词方法
如果从汉语词语的角度出发去研究词语的规律,很快就可以得到一个结论,那就是相互组成一个词语的两个汉字顺序出现在一起的频率会很高。可以利用这个特点来判定任意相邻的汉字是否组成了一个词,但是很明显存在一个问题,到底多高的频率才能证明这几个字组成了一个词?从数学的角度来看,这不是单一系数就能解决的问题,也绝对不是单一的函数关系,因为变量太多了,可能不同的汉字本身达到可以判定它跟某个汉字组合成词的阈值是不同的,比如一些生僻的字,本文在这块献丑举个例子:“好”这个字,它可以组成“好人”,“美好”,“刚好”,“恰好”,“好运”,“好奇”,“合好”,“友好”,“问好”,“讨好”……等等词语,在百度上搜到的结果有7500条之多;举另外一个字“驭”,用“驭”组词,有“驾驭”,“驭风”……等词语,仅仅只有120条左右,明显“好”跟“驭”两个字不能用一样的判定标准,它们出现的频率差异太大,是不能共用一套判定方案来判断它们是否组字成词的。
其次,还有一个问题,有一些特殊的汉字,他们也会对整个中文分词结果产生不可忽视的干扰作用,例如“了”,“的”,“着”,这些词语各自可以组字成词,例如“了解”,“目的”,“着手”等等,但是他们在整个中文语料中更多的形式是类似于这样的形式:“走了”,“累了”,“掉了”,“好的”,“你的”,“他的”,“走着”,“跑着”,“着了”等等形式,这样的形式明显不是词语,这些字经常作为结束语出现,可能对整个基于词频的汉语分词算法产生巨大的干扰作用,而在中文语料中,列举出来的这几个词还仅仅是冰山一角。所以这种方法仅仅单靠词频是完全不够的。
不过,到目前,人工智能越来越热,发展也变得迅速起来,不得不说这种方法是具有一定的前瞻性的,如果事先能给出大量的汉语语料的训练集,再辅以人工纠错与修正操作,是这种统计的中文分词算法越来越准确,相信这种方法在不久的未来会替代其他的分词算法。在处理自然语言上,去理解语义、语法这才是正道。通过建立相关的语法模型,不断地进行统计分词的训练,后期算法一定会有非常不错的分词成果,不过本文研究仅仅是借用中文分词的工具,也不会在这方面进行太过深入的讨论。顺便提下,作为训练集的语料完全可以采用类似本文的爬虫系统从网络上每天搜集到最新的新闻情报进行训练,人工纠错,因为没有比新闻更有实效性的汉语语料训练集了,这样“网络新词”也能得到及时的补充与学习,后期需要人工参与纠正的次数会越来越少,分词结果也会越来越准确。
本文使用了IK Analyzer作为汉语分词的工具。IK Analyzer是一个完全免费开源的中文分词的工具,基于Java开发的非常优秀、快速的中文分词的工具包。国内还有一个较为著名的中文分词工具Ansj,号称能很好的识别人名与地名,而且处理速度方面完全超越IK分词,不过由于IK分词基于Lucene,最近自己又在研究Lucene的原因,况且对IK的分词结果也还算满意。
本系统使用的IK Analyzer的版本为2012u6,作者林良益是一名自身的Java程序开发工程师。在IK Analyzer中能看到很多Lucene的影子,比如IK分词的核心就是基于Lucene的,其中大量的导包也能看出来源于Apache Lucene。现在有空也在研究IK分词的算法以及原理,希望能给许久未更新的IK分词加入自己的贡献,IK分词系统结构图如图4-1所示。

图4-1 IK分词的设计结构图
4.1.3 相似度匹配模块
利用中文分词工具将爬虫系统采集回来的数据进行中文分词之后,则需要分析文章的相似度,之后再将相似的文章的数据整合到一起,为之后可视化展示同一条新闻的变化趋势打下基础,其中计算文章相似度的算法有很多,主要来说是有两种,一种是余弦定理,另一种是计算杰卡德距离的方法。
1.余弦定理相似度计算法
余弦定理是怎么能应用到计算文章的相似度呢?先想想余弦定理的概念,如果能将两篇文章转换为数学中的两条向量,那么可以用过余弦定理来计算这两条向量之间的夹角。具体应该怎么能将文章转换为数学中的向量呢?这里就用到了中文分词,然后可以将带分析的汉语语料进行中文分词,并保存各自的分词结果集A,B。分词结束后再另外设置一个集合S,令S = A ∪ B,那么分别计算A,B两个集合中的词语在原始预料中的词频,然后建立A、B到S的映射,如果S中有而A或者B中没有,那么记该词语的词频为0,那么就能得到两条维度相同的向量,这样就可以用余弦定理来计算相似度了。
第一步,进行中文语料的分词。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
第二步,列出所有汉语词语的集合。
我,喜欢,看,电视,电影,不,也。
第三步,计算集合中每个词语的词频。
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
第四步,写出每句话的词频向量。
句子A:[1, 2, 2, 1, 1, 1, 0]。
句子B:[1, 2, 2, 1, 1, 2, 1]。
有了词频向量,中文文章的相似度计算问题就简化了,变成了如何去计算这两个词频向量的离合程度。首先可以把这两条词频向量想象成存在于空间中的两条任意线段,这两条线段必然能组成类似于下图的夹角,再计算夹角的余弦值。
在这里讨论下最简单的维度,也就是二维空间,下图的a和b是两个字母分别代表两个不同的向量,需要计算它们夹角的余弦值COSθ,如图4-2所示。

图4-2 两向量形成夹角
向量a,b所构成的夹角如图4-3所示。

图4-3 向量a,b所构成的夹角
可以采用下列公式来计算出夹角θ的余弦值,计算公式如图4-4所示。

图4-4计算ab两向量的余弦值公式
如果是多维向量呢?如何计算多维向量在空间中的夹角的余弦值?经由数学推导,可以使用下面多维向量的余弦值计算公式如图4-5所示。
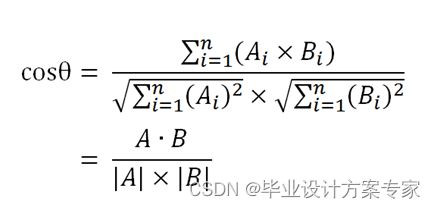
图4-5 多维向量的余弦值计算公式
两个汉语词组的词频向量的余弦值可以作为这两篇汉语语料整体相似度的度量,因为从数学上来讲,当两向量的余弦值越接近或完全等于0,则表明两个向量的夹角是两条方向完全垂直的,在中文语法的角度来解释向量垂直,就是两篇语料的分词结果是完全没有一样的,这样有很大的可信度表明,这两篇文章内容是完全不相干的,反过来,如果俩向量的夹角的余弦接近或完全等于1,则表明这两条向量几乎可以看做成同一条向量,从中文语法的角度来解释,也就是两篇中文语料的分词结果基本上是一致的,有很大的可信度表明,这两篇文章的内容是完全类似的。
由此,就得到了“找出相似文章”的一种算法:
(1)使用中文分词算法,首先需要找出这两篇带分析文章的重要关键词。
(2)从每篇文章分别取出所有的关键词,将其合并成为一个集合,然后来计算这两篇文章相对于关键词集合的词频,这样就生成了这两篇文章两条待分析的词频向量。
(3)最后计算这两个词频向量的余弦值,余弦值越接近于1则文章越相似。
“余弦相似度”是一种非常有用的算法,凡事想要知道任意两个向量的相似程度,都可以使用余弦定理。
4.1.4 数据展示模块
经过相似度匹配算法匹配为相似文章的算法则存储到同一条数据记录之中存入数据库,然后将相似数据读取出来,将数据以可视化的形式展示出来,步骤如下:
(1)将POJO对象转换为JSON:
JSON(JavaScript Object Notation) 是一种非常轻量级的类似而又超越可扩展标记语言的数据交换的格式。JSON是基于ECMAScript的一个子集。 JSON采用了完全独立于任何编程语言的书写格式,但也使用了非常类似C语言家族的一些语法习惯(包括C、C++、C#、Java、JavaScript、Perl、Python等)。
JSON一经推出,直到现在,在数据交换载体的选择上完全有替代XML的趋势。最近在公司写的一个金融项目,是为财新网写的债券实时行情的金融项目,项目中后台数据传送到前台用的是Servlet,Servlet中是将从Service层中得到的数据对象(一般都是List、Map、或者其他的POJO对象),经过fastjson转换成为JSON字符串,最终输出在Servlet上。然后前台js用ajax异步加载的方式调用Servlet,可以很容易的将获取到的JSON字符串转化为相关的对象。
此外,有大量的测试表明,同样字节数同样大小的JSON可以装载的数据信息量要比XML多出很多,这样就表明,JSON的压缩性更好,自身的负载效率高,所以,如今越来越多的网站数据交互、以及企业级的信息交互、经典的C-S模式都逐渐改用了JSON作为数据传递的载体。
从JavaScript语言层来看,JSON俨然就是JavaScript中的数组类型与对象类型之间的组合体,有点类似与C语言中结构体strut的语法定义模式,很明显,strut能通过对不同数据结构的组合,再添加各种各样的数据嵌套,可以表示世界上任意一种信息格式,JSON非常类似于这种结构体,正因为JSON作为一种高效的数据载体来说可谓是“无所不能”,近些年,有关JSON的发展飞速而且迅猛。下面分别简单介绍下JavaScript中的对象与数组:
对象:
JSON对象在js中表示为用“{}”括起来的内容,其数据结构为 {key:value,key:value,…}的键值对的结构,在绝大多数的面向对象的编程语言中,key即键是对象属性的名字,而value即值则是对象的属性值。在C语言、Java、Python等语言中通过Object.key来取得value的具体的值。
数组:
数组在js中是中用括号“[]”符号包含起来的内容,js数组的数据结构如 [“this”,“a”,“test”,…],使用数组的索引可以来获取数据相应位置的数值,数值的数据类型包括各种各样的数据类型:对象、字符串、数字、数组等等。实验证明经过对象、数组2种数据结构是可以组合成各种各样任意复杂度的数据结构。
现如今,可以把POJO对象转换为JSON的工具有很多,比如谷歌的Gson工具包,比如阿里贡献的开源JSON转换工具fastjson,本文使用了阿里巴巴的fastjson。Fastjson提供了包括JSON数据的“序列化”和“反序列化”两部分的JSON相关的功能,其优势有:号称对JSON数据的解析与反解析速度最快,测试表明,fastjson具有极快的性能,超越任其他的Java Json parser,包括自称最快的JackJson。FastJson功能强大,完全支持Date、Enum、Java Bean、Set、Map、等常见的数据模式与类型,并且原生,能在所有Java能运行的地方运行。Java对象转换为JSON格式,一般有以下几种情况:
Java普通单节点对象转换为JSON的原理:
通过对象的get()方法来获取对象的属性的值即JSON数据的值,然后通过get()方法的函数名得出具体是get的哪个成员变量,于是这样就能得出了JSON数据的键,然后经过复合JSON语法的拼接与组合,就成功将对象转换为了JSON。但如果对象没有提供响应的get()方法呢?那么就需要通过Java的反射机制来拿出要转换成JSON的对象的字段,然后判定哪些字段是必须的,同时抛弃掉“垃圾数据”的字段,最终将字段组合成JSON。组合成JSON的时候,其字段名称作为String类型的key存在,其属性值作为相对应数据类型的key存在,如图4-6所示。

图4-6 对象转换为JSON原理图
Java普通单节点数组转换为JSON的原理:
Java普通单节点数组转换为JSON可以由单节点转换JSON拓展而来,如图4-7所示。

图4-7 对象数组转换为JSON原理
Java复合对象转换为JSON的原理:
Java符合对象转换为JSON其实就是Java普通单节点对象转换为JSON的原理的拓展,获取了字段名字之后,获取字段对应的属性的时候,需要判定该属性具体的数据类型,如果该属性的具体数据类型是基本数据类型中的一种,就必须使用该数据类型对应的JSON表示方法表示出来(例如有没有引号之分就是区别字符串变量与其他变量之间的区别的),如图4-8所示。
图4-8 复合对象转换为JSON原理
(2)将Json数据以可视化的形式展示出来
显示相似新闻数据使用了开放的图表绘制类库JfreeChart,JfreeChart工具使用纯Java语言编写而来,完全是为applications, applets, servlets 以及JSP等的使用而设计。JFreeChart可以生成例如散点图(scatter plots)、柱状图(bar charts)、饼图(pie charts)、甘特图(Gantt charts)、时序图(time series)等等多种图表,此外还可以生成PNG和JPEG格式进行输出,也可以和PDF和EXCEL等工具关联。
到目前为止,在Java中JFreeChart是非常不错的统计图形解决方案,JFreeChart基本上能够满足目前的Java在统计绘图方面的各种需求。 JFreeChart的优秀特性包括以下几点:
一致的和清晰明确的API,而且支持多种图表类型。
设计非常灵活,对各种应用程序来说非常容易扩展。
支持多种多样的输出类型,包括Swing组件、图像文件(PNG、JPEG)、矢量图形文件(PDF、EPS、SVG)。
JFreeChart是完全“开源”的,或者更具体地说, 自由软件。它是遵循GNU协议的。
JfreeChart优点如下:
稳定、轻量级且功能非常强大。
免费开源,但是开发手册和示例要花钱购买。
其API学习起来非常简单,整个工具容易上手。
生成的图表运行非常地顺畅。
4.2 系统异常处理
系统在运行过程中因为复杂的运行环境,可能会产生种种异常问题。
4.2.1 爬虫异常总体概况
省略
4.2.2 爬虫访问网页被拒绝
爬虫大量爬取网站时,会对网站资源占用严重,所以很多网站加入了反爬虫机制,大量爬取网站数据时,会出现Access Denied一类的错误,网页服务器直接拒绝了访问,这时候爬虫就得需要能伪装的像一个真正的浏览器一样,有如下方法:
(1)伪装User-Agent
User-Agent标明了浏览器的类型,以便Web网站服务器能识别不同类型的浏览器。为什么要识别不同类型的浏览器呢?现在主流的优秀浏览器有windows10的Edge浏览器、微软的IE系列浏览器、谷歌的Chrome浏览器、Mozilla的FireFox浏览器,还有来自挪威的Opera浏览器,这些浏览器五花八门,分别出自各自的厂家,所以面对同样的html元素,他们的解析效果有可能是非常不同的,甚至会出现无法解析一些Html元素的情况,正式因为如此,所以Web网站服务器要判断不同的浏览器以便提供不同支持方案(例如CSS中针对不同的浏览器可能需要不同的标注)。
所以现在绝大部分的爬虫为了能够及时获取网站的数据,通常会设置一个某种浏览器的User-Agent以此来“欺骗”网站,告诉Web网站服务器自己是某一种浏览器,然后网站Web服务器才会返回真实的网页数据,一般比较常见几个浏览器的User-Agent如下:
Chrome的User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36
火狐的User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0
IE的User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; .NET4.0E; .NET4.0C; .NET CLR 3.5.30729; .NET CLR 2.0.50727; .NET CLR 3.0.30729; rv:11.0) like Gecko
HttpClient设置User Agent的方法如下:
HttpGet getMethod = new HttpGet(“URL”);
getMethod.setHeader(“User-Agent”, “user agent内容”);
(2)需要登录后才能访问网页数据
虽然绝大部分网站不登陆就能访问各个页面的内容,随着各个研究机构对互联网数据的需求越来越多的情况下,各种各样的爬虫随之诞生,但是一部分爬虫会无节制的爬取网站,大大地消耗了网站的带宽,导致正常的用户都无法访问网站,所以现在的绝大部分网站都相应推出了一些防护“恶意爬虫”的策略,例如网站一旦检测到某个IP的访问量有异常,就会要求这个IP访问的时候必须登录后才能访问。不过这样也有解决方法,可以直接在该IP所在主机上用浏览器登录,登录成功之后,如果浏览器是Chrome或者firefox那么可以直接查看浏览器的cookie,用HttpClient设置cookie即可访问即可。不过还有一些检测机制特别严格的网站,登录网站的时候必须填写随机验证码,这类网站的爬取难度可就大了,需要能识别网站随机扭曲的验证码,这些问题在本文不做讨论。
(3)使用代理IP访问
如果网站服务器维护人员用某段时间内某IP的访问次数来判定爬虫,然后将这些爬虫的IP都封掉的话,以上伪装就失效了。为了解决爬虫的IP被相关网站封停,仔细一想,如果爬虫能模拟出一批用户来访问该网站不就能解决这个问题吗?具体应该如何模拟呢?首先需要模拟出一个一个分散而又独立的用户,这就需要随机而又分散到全国各地的IP代理,爬虫运行的时候从这些IP代理中随机选取一部分IP作为代理使用,这样就能比较完美地解决单IP高频率高流量访问网站的问题了。
拥有了这些IP代理之后,应该如何去管理这些代理IP呢?这里可以做一个类似于数据库连接池的东西,当然这里存放的不是数据库连接,而是一个一个的代理IP,然后指定相关的代理IP分配策略。代理IP池做好之后,要做一个负载均衡,每次轮流使用代理IP池中可以正常使用的IP做循环访问,这样单一IP对网页服务器会迅速下降,非常明显。
5 软件测试
省略
5.1 白盒测试
白盒测试是一种基于软件逻辑结构设计的测试,在整个测试过程中,测试的参与者是完全熟知整个系统的逻辑分支的。白盒测试的盒子是指被测试的软件系统,白盒指的是程序结构与逻辑代码是已知的,非常清楚盒子内部的逻辑结构以及运行逻辑的。“白盒”法全面了解程序内部逻辑结构、对所有逻辑路径都进行相关测试。“白盒测试”会争取能够测试完软件系统中所有的可能的逻辑路径。使用白盒测试的方式时,一定要先画出软件所有的逻辑顺序结构与设计,然后再分别设计出合适而又全面的测试用例,最终完成白盒测试。
5.1.1 爬虫系统测试结果
因为爬虫系统逻辑设计相对来说是比较简单的,不涉及到基本路径法,因为整个正序只需要定时运行就行,不像其他软件系统那样,有较深的用户需求根基,需要相关人员配合使用。本次开发的爬虫系统是全自动的,所以百合测试结果与黑盒测试结果一致。
下图为爬虫系统的百合测试结果截图,测试方法即定时运行爬虫即可,下图中的条目为爬虫此次执行所爬取到结果中的一部分,爬取结果如图5-1所示。

图5-1 爬虫爬取结果
5.1.2 中文分词系统测试结果
中文分词系统测试也比较简单,没有复杂的业务逻辑,结果基本呈线程顺序,且执行路径唯一,下图为中文分词系统的白盒测试结果,首先是测试的语料的截图,如图5-2所示。

图5-2 中文分词原文
最终的分词结果如下,目前想要提高分词结果非常困难,需要加大词库的准确性,白盒测试结果如图5-3所示:

图5-3 中文分词结果
5.1.3 中文文章相似度匹配系统测试结果
中文文章相似度计算方法采用了余弦定理计算两篇文章所对应的汉语词语的词频向量的夹角的余弦值,在经过大量的试验后发现其准确率还是非常非常高的,测试结果如图5-4所示。

图5-4 余弦定理相似度匹配
可以看出,“国家专项计划引苏鄂家长担忧教育部回应”这篇新闻与“向中西部调剂生源致高考减招数万?湖北江苏连夜回应”两条新闻均是有关高考的,完美匹配到了一起,其次不排除有些极端的情况,导致匹配结果不正确,这个也会继续研究,提高准确率。
5.1.4 相似新闻趋势展示系统测试结果
相似新闻的展示采用了JfreeChart作为白盒测试的测试对象,测试结果如下图所示,精确显示了每一条新闻的关注度走势,如图5-5所示。

图5-5 JfreeChart测试图
5.2 黑盒测试
黑盒测试与白盒测试恰好相反,从名字就能看出,一黑一白,白盒测试者熟悉盒子中的内容,而黑盒测试者是完全不知道盒子中的内容的。黑盒测试主要是面向程序的功能实现而进行的测试,例如检验程序是否具有某一功能,而完全不必关心程序的逻辑设计。也就是说,整个黑盒测试关注的是软件系统的功能完整性,而不考虑程序逻辑上的BUG等问题。
5.2.1 爬虫系统测试结果
上面已经提到,本爬虫系统逻辑较为简单,白盒测试结果与黑盒测试结果一致,结果如图5-6所示。

图5-6 爬虫系统黑盒测试
5.2.2 中文文章相似度匹配系统测试结果
总体来说,黑盒测试的结果也是比较令人满意的,同样,瑕疵还是有的,这也是编程的挑战与乐趣所在之处,黑盒测试结果如图5-7所示。

图5-7 中文匹配黑盒测试
5.2.3 相似新闻趋势展示系统测试结果
黑盒测试相似新闻趋势展示系统测试了Echarts的效果,以便能跟白盒测试JfreeChart区别开来,测试结果如图5-8所示。

图5-8 黑盒测试新闻排行
点击上面的相关新闻会出现单个新闻的趋势发展图,如图5-9所示。

图5-9 echarts黑盒测试
6 结 论
省略
参考文献
[11] 于娟,刘强. 主题网络爬虫研究综述[J]. 计算机工程与科学, 2015, 37(02):231-237.
[12] 张红云. 基于页面分析的主题网络爬虫的研究[D]. 武汉理工大学, 2010.
[13] 张莹. 面向动态页面的网络爬虫系统的设计与实现[D]. 南开大学, 2012.
[14] 张晓雷. 面向Web挖掘的主题网络爬虫的研究与实现[D]. 西安电子科技大学, 2012.
[15] 奉国和,郑伟. 国内中文自动分词技术研究综述[J]. 图书情报工作, 2011, 55(2):41-45.
[16] 许智宏,张月梅,王一. 一种改进的中文分词在主题搜索中的应用[J]. 郑州大学学报, 2014(5):44-48.
[17] 欧振猛,余顺争. 中文分词算法在搜索引擎应用中的研究[J]. 计算机工程与应用, 2000, 36(08):80-82.
[18] Batsakis.S, Petrakis E G M, Milios E. Improving the performance of focused web crawlers[J]. Data & knowledge engineering, 2009, 68(10):1001-1013.
[19] Pant.G, Menczer F. MySpiders:Evolve Your Own Intelligent Web Crawlers[J]. Autonomous agents and multi-agent systems, 2002, 5(2):221-229.
[20] Ahmadi-Abkenari F, Ali S. A Clickstream-based Focused Trend Parallel Web Crawler[J]. International Journal of Computer Applications, 2010, 9(5):24-28.
致 谢
省略
外文资料
省略
中文翻译
省略
5、资源下载
本项目源码及完整论文如下,有需要的朋友可以点击进行下载。如果链接失效可点击下方卡片扫码自助下载。
序号
毕业设计全套资源(点击下载)
本项目源码
基于java+Jsoup+HttpClient的网络爬虫技术的网络新闻分析系统设计与实现(源码+文档)网络爬虫_数据挖掘.zip
你可能感兴趣的:(精选毕业设计完整源码+论文,爬虫,java,python)