【golang】Go中的切片slice和操作笔记,垃圾回收机制,重组 reslice ,复制和追加,内存结构
切片
文章目录
- 切片
-
- 将切片传递给函数
- make() 创建一个切片
- new() 和 make()的区别
- 多维切片
- bytes包
- for-range
- 切片重组 reslice
- 切片的复制和追加
- 字符串、数组和切片的应用
-
- 获取字符串的某一部分
- 字符串和切片的内存结构
- 修改字符串中的某个字符
- 字节数组对比函数
- 搜索及排序切片和数组
- append() 函数常见操作
- 切片和垃圾回收
-
切片是对数组中一个连续片段的引用,该数组我们称之为相关数组,通常是匿名
-
切片是一个引用类型
-
这个片段可以是整个数组,或者是由起始和终止索引标识的一些项的子集。需要注意的是,终止索引标识的项不包括在切片内。切片提供了一个相关数组的动态窗口
-
切片是可索引的
-
给定项的切片索引可能比相关数组的相同元素的索引小。和数组不同的是,切片的长度可以在运行时修改,最小为 0, 最大为相关数组的长度:切片是一个 长度可变的数组。
-
切片提供了计算容量的函数
cap()可以测量切片最长可以达到多少:它等于切片的长度 + 数组除切片之外的长度。如果s是一个切片,cap(s)就是从s[0]到数组末尾的数组长度。切片的长度永远不会超过它的容量,所以对于切片s来说该不等式永远成立: -
0 < = l e n ( s ) < = c a p ( s ) 0 <= len(s) <= cap(s) 0<=len(s)<=cap(s)
-
多个切片如果表示同一个数组的片段,它们可以共享数据;因此一个切片和相关数组的其他切片是共享存储的,相反,不同的数组总是代表不同的存储。数组实际上是切片的构建块。
-
优点 因为切片是引用,所以它们不需要使用额外的内存并且比使用数组更有效率,所以在 Go 代码中切片比数组更常用。
声明切片的格式是:
var identifier []type //不需要说明长度
一个切片在未初始化之前默认为 nil,长度为 0。
切片的初始化格式是:
var slice1 []type = arr1[start:end]
这表示 slice1 是由数组 arr1 从 start 索引到 end-1 索引之间的元素构成的子集(切分数组,start:end 被称为切片表达式)。所以 slice1[0] 就等于 arr1[start]。这可以在 arr1 被填充前就定义好。
如果某个人写:
var slice1 []type = arr1[:]
那么 slice1 就等于完整的 arr1 数组(所以这种表示方式是 arr1[0:len(arr1)] 的一种缩写)。另外一种表述方式是:
slice1 = &arr1
arr1[2:] 和 arr1[2:len(arr1)] 相同,都包含了数组从第三个到最后的所有元素。
arr1[:3] 和 arr1[0:3] 相同,包含了从第一个到第三个元素(不包括第四个)。
如果你想去掉 slice1 的最后一个元素,只要 :
slice1 = slice1[:len(slice1)-1]
一个由数字 1、2、3 组成的切片可以这么生成
s := [3]int{1,2,3}[:]
(注:应先用 s := [3]int{1, 2, 3} 生成数组, 再使用 s[:] 转成切片)甚至更简单的 s := []int{1,2,3}。
s2 := s[:] 是用切片组成的切片,拥有相同的元素,但是仍然指向相同的相关数组。
一个切片 s 可以这样扩展到它的大小上限:s = s[:cap(s)],如果再扩大的话就会导致运行时错误
w
对于每一个切片(包括 string),以下状态总是成立的:
s == s[:i] + s[i:] // i是一个整数且: 0 <= i <= len(s)
len(s) <= cap(s)
切片也可以用类似数组的方式初始化:var x = []int{2, 3, 5, 7, 11}。这样就创建了一个长度为 5 的数组并且创建了一个相关切片。
切片在内存中的组织方式实际上是一个有 3 个域的结构体:指向相关数组的指针,切片长度以及切片容量。下图给出了一个长度为 2,容量为 4 的切片 y。
y[0] = 3且y[1] = 5。- 切片
y[0:4]由 元素3,5,7和11组成。
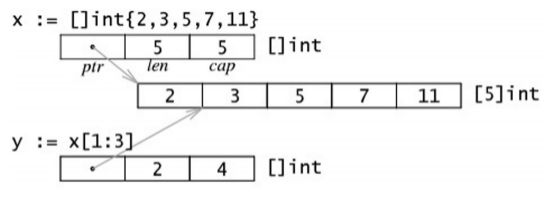
如果 s2 是一个切片,你可以将 s2 向后移动一位 s2 = s2[1:],但是末尾没有移动。切片只能向后移动,s2 = s2[-1:] 会导致编译错误。切片不能被重新分片以获取数组的前一个元素。
注意 绝对不要用指针指向切片。切片本身已经是一个引用类型,所以它本身就是一个指针!!
将切片传递给函数
如果你有一个函数需要对数组做操作,你可能总是需要把参数声明为切片。当你调用该函数时,把数组分片,创建为一个切片引用并传递给该函数。这里有一个计算数组元素和的方法:
func sum(a []int) int {
s := 0
for i := 0; i < len(a); i++ {
s += a[i]
}
return s
}
func main() {
var arr = [5]int{0, 1, 2, 3, 4}
sum(arr[:])
}
make() 创建一个切片
当使用make函数创建切片时,Go会分配虚拟内存,而不会立即分配物理内存。这是一种延迟分配的策略;这种方式可以节省物理内存,因为程序不会立即占用大量内存,而是根据实际需要逐渐分配。
当相关数组还没有定义时,我们可以使用 make() 函数来创建一个切片,同时创建好相关数组:
var slice1 []type = make([]type, len)
也可以简写为:
slice1 := make([]type, len) //这里的len是数组的长度也是slice的初始长度
如果你想创建一个 slice1,它不占用整个数组,而只是占用len 长度,那么只要:
slice1 := make([]type, len, cap)
切片的长度为 len,并且具有与容量 cap 相同的底层数组的大小。这意味着 slice1 会占用以 len 为个数个元素,但在需要时可以增长到 cap,这是Go切片的一个特性。这对于在不需要整个数组的情况下,有效地管理内存和数据非常有用
所以下面两种方法可以生成相同的切片:
make([]int, 50, 100)
new([100]int)[0:50]
下图描述了使用 make() 方法生成的切片的内存结构:

new() 和 make()的区别
都在堆上分配内存,但是它们的行为不同,适用于不同的类型。
new(T)为每个新的类型T分配一片内存,初始化为0并且返回类型为*T的内存地址:这种方法 返回一个指向类型为T,值为0的地址的指针,它适用于值类型如数组和结构体体或用户定义的类型;它相当于&T{}。make(T)用于分配内存并初始化数据结构的内部字段,返回的是数据结构本身,它只适用于 3 种内建的引用类型:切片、map和channel。
换言之,new() 函数分配内存,make() 函数初始化;下图给出了区别:

如何理解 new、make、slice、map、channel 的关系*
1.slice、map 以及 channel 都是 golang 内建的一种引用类型,三者在内存中存在多个组成部分,
需要对内存组成部分初始化后才能使用,而 make 就是对三者进行初始化的一种操作方式
2. new 获取的是存储指定变量内存地址的一个变量,对于变量内部结构并不会执行相应的初始化操作,
所以 slice、map、channel 需要 make 进行初始化并获取对应的内存地址,而非 new 简单的获取内存地址
多维切片
和数组一样,切片通常也是一维的,但是也可以由一维组合成高维。通过分片的分片(或者切片的数组),长度可以任意动态变化,所以 Go 语言的多维切片可以任意切分。而且,内层的切片必须单独分配(通过 make() 函数)。
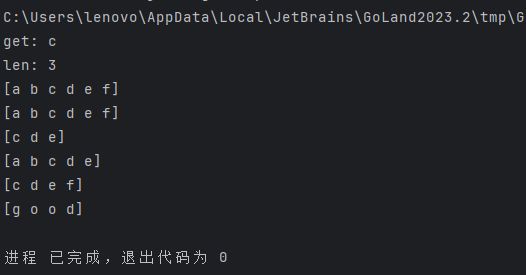
package main
import "fmt"
func main() {
s := make([]string, 3)
s[0] = "a"
s[1] = "b"
s[2] = "c"
fmt.Println("get:", s[2])
fmt.Println("len:", len(s))
s = append(s, "d")
s = append(s, "e", "f")
fmt.Println(s)
c := make([]string, len(s))
copy(c, s)
fmt.Println(c)
fmt.Println(s[2:5])
fmt.Println(s[:5])
fmt.Println(s[2:])
good := []string{"g", "o", "o", "d"}
fmt.Println(good)
}
输出
bytes包
类型 []byte 的切片十分常见,Go 语言有一个 bytes 包专门用来提供这种类型的操作方法。
- 动态缓冲区:
bytes.Buffer是一个动态缓冲区,它可以自动调整其大小以容纳不断增长的数据。这使它非常适合在运行时动态构建和拼接二进制数据,而不必担心缓冲区溢出。 - 高效的字符串拼接:
bytes.Buffer可以用于高效地拼接字符串,而不必反复分配和释放内存。这对于构建大型字符串或将文本逐行追加到缓冲区非常有用。 - 读写接口:
bytes.Buffer实现了io.Reader和io.Writer接口,因此它可以与标准的 I/O 操作和函数一起使用。您可以使用它来从缓冲区读取数据或将数据写入缓冲区,而无需关心底层的内存管理。 - 字节操作:
bytes.Buffer主要用于操作字节数据,而不是文本。它提供了一系列方法来操作和读取二进制数据,包括读取、写入、截取、查找等操作。
而且它还包含一个十分有用的类型 Buffer:
import "bytes"
type Buffer struct {
...
}
这是一个长度可变的 bytes 的 buffer,提供 Read() 和 Write() 方法,因为读写长度未知的 bytes 最好使用 buffer。
Buffer 可以这样定义:
var buffer bytes.Buffer
或者使用 new() 获得一个指针:
var r *bytes.Buffer = new(bytes.Buffer)
或者通过函数:
func NewBuffer(buf []byte) *Buffer
创建一个 Buffer 对象并且用 buf 初始化好;NewBuffer 最好用在从 buf 读取的时候使用。
通过 buffer 串联字符串
类似于 Java 的 StringBuilder 类。
在下面的代码段中,我们创建一个 buffer,通过 buffer.WriteString(s) 方法将字符串 s 追加到后面,最后再通过 buffer.String() 方法转换为 string:
var buffer bytes.Buffer
for {
if s, ok := getNextString(); ok { //method getNextString() not shown here
buffer.WriteString(s)
} else {
break
}
}
fmt.Print(buffer.String(), "\n")
这种实现方式比使用 += 要更节省内存和 CPU,尤其是要串联的字符串数目特别多的时候。
for-range
这种构建方法可以应用于数组和切片:
for ix, value := range slice1 {
...
}
第一个返回值 ix 是数组或者切片的索引,第二个是在该索引位置的值;他们都是仅在 for 循环内部可见的局部变量。value 只是 slice1 某个索引位置的值的一个拷贝,不能用来修改 slice1 该索引位置的值。
多维切片下的 for-range:
通过计算行数和矩阵值可以很方便的写出:
for row := range screen {
for column := range screen[row] {
screen[row][column] = 1
}
}
切片重组 reslice
切片创建的时候通常比相关数组长度小,这么做的好处是切片在达到容量上限之后可以进行扩容,改变切片长度的过程称之为切片重组,用法:
slice1 = slice1[0 : end]
切片可以反复拓展至占据整个相关数组
切片的复制和追加
如果想增加切片的容量,我们必须创建一个新的更大的切片并把原分片的内容都拷贝过来。下面的代码描述了从拷贝切片的 copy 函数和向切片追加新元素的 append() 函数:
func copy(dst, src []T) int 方法将类型为 T 的切片从源地址 src 拷贝到目标地址 dst,覆盖 dst 的相关元素,并且返回拷贝的元素个数。源地址和目标地址可能会有重叠。拷贝个数是 src 和 dst 的长度最小值。如果 src 是字符串那么元素类型就是 byte。如果你还想继续使用 src,在拷贝结束后执行 src = dst:
slFrom := []int{1, 2, 3}
slTo := make([]int, 10)
n := copy(slTo, slFrom)
func append(s[]T, x ...T) []T 其中 append() 方法将 0 个或多个具有相同类型 s 的元素追加到切片后面并且返回新的切片;追加的元素必须和原切片的元素是同类型。
如果 s 的容量不足以存储新增元素,append() 会分配新的切片来保证已有切片元素和新增元素的存储。因此,返回的切片可能已经指向一个不同的相关数组了。append() 方法总是返回成功,除非系统内存耗尽了。
sl3 := []int{1, 2, 3}
sl3 = append(sl3, 4, 5, 6)
如果你想将切片 y 追加到切片 x 后面,只要将第二个参数扩展成一个列表即可:x = append(x, y...)。
注意: append() 在大多数情况下很好用,但是如果你想完全掌控整个追加过程,你可以实现一个这样的 AppendByte() 方法:
func AppendByte(slice []byte, data ...byte) []byte {
m := len(slice)
n := m + len(data)
if n > cap(slice) { // if necessary, reallocate
// allocate double what's needed, for future growth.
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
字符串、数组和切片的应用
假设 s 是一个字符串(本质上是一个字节数组),那么就可以直接通过 c := []byte(s) 来获取一个字节的切片 c 。另外,您还可以通过 copy() 函数来达到相同的目的:copy(dst []byte, src string):
func main() {
s := "\u00ff\u754c"
for i, c := range s {
fmt.Printf("\n%d: %c", i, c)
}
}
输出:
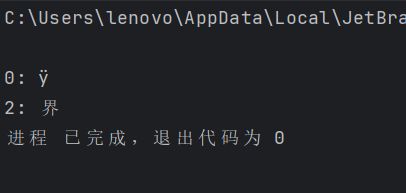
我们知道,Unicode 字符会占用 2 个字节,有些甚至需要 3 个或者 4 个字节来进行表示。如果发现错误的 UTF8 字符,则该字符会被设置为 U+FFFD (�)来代替它。这是一个特殊字符,表示无效的Unicode字符;并且索引向前移动一个字节。
和字符串转换一样,同样可以使用 c := []int32(s) 语法,这样切片中的每个 int 都会包含对应的 Unicode 代码,因为字符串中的每次字符都会对应一个整数
也可以将字符串转换为元素类型为 rune 的切片:r := []rune(s),其中每个rune表示字符串中的一个Unicode字符。这可以通过将字符串转换为[]rune来实现。
可以通过代码 len([]int32(s)) 来获得字符串中字符的数量,但使用 utf8.RuneCountInString(s) 效率会更高一点
获取字符串的某一部分
使用
substr := str[start:end]
可以从字符串 str 获取到从索引 start 开始到 end-1 位置的子字符串。同样的:
str[start:]
则表示获取从 start 开始到 len(str)-1 位置的子字符串。而 str[:end] 表示获取从 0 开始到 end-1 的子字符串。
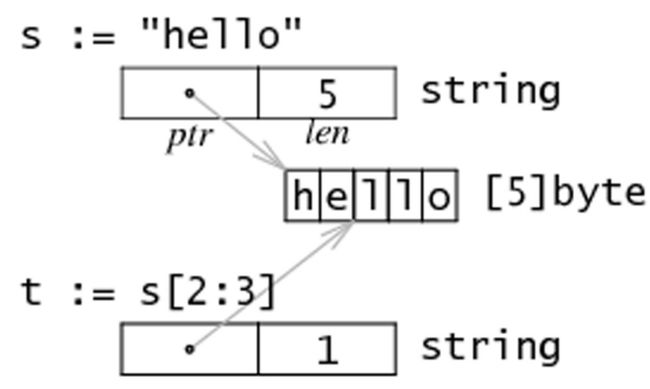
字符串和切片的内存结构
在内存中,一个字符串实际上是一个双字结构,即一个指向实际数据的指针和记录字符串长度的整数。因为指针对用户来说是完全不可见,因此我们可以依旧把字符串看做是一个值类型,也就是一个字符数组。
字符串的底层内存是只读的,因此多个字符串可以共享相同的字节数组,这有助于节省内存。
字符串 string s = "hello" 和子字符串 t = s[2:3] 在内存中的结构可以用下图表示:
切片是可变的数据类型,在内存中包含一个指向底层数据的指针、长度和容量
切片的内容是底层数组的一部分,可以通过索引来读取或修改切片的元素。
切片支持动态调整长度和容量,通过 append() 函数可以增加切片的长度,但可能会分配新的底层数组。
总结:
切片和字符串在内存结构上的主要区别在于,切片是一个引用类型,它引用底层的数组,而字符串是一个值类型,它是一个不可变的字节数组。这使得切片更适合用于处理动态数据集合,而字符串更适合用于不可变文本。理解这些区别对于有效地使用这两种数据类型非常重要
修改字符串中的某个字符
Go 语言中的字符串是不可变的,也就是说 str[index] 这样的表达式是不可以被放在等号左侧的。如果尝试运行 str[i] = 'D' 会得到错误:cannot assign to str[i]。
因此,您必须先将字符串转换成字节数组,然后再通过修改数组中的元素值来达到修改字符串的目的,最后将字节数组转换回字符串格式。
例如,将字符串 "hello" 转换为 "cello":
s := "hello"
c := []byte(s)
c[0] = 'c'
s2 := string(c) // s2 == "cello"
注意:在需要频繁修改字符串的情况下,会有一些性能开销。如果只需要构建新的字符串,可以使用 + 运算符或 strings.Join() 等方法来构建新字符串而不修改原始字符串。
字节数组对比函数
下面的 Compare() 函数会返回两个字节数组字典顺序的整数对比结果,即 0 if a == b, -1 if a < b, 1 if a > b。
func Compare(a, b[]byte) int {
for i:=0; i < len(a) && i < len(b); i++ {
switch {
case a[i] > b[i]:
return 1
case a[i] < b[i]:
return -1
}
}
// 数组的长度可能不同
switch {
case len(a) < len(b):
return -1
case len(a) > len(b):
return 1
}
return 0 // 数组相等
}
搜索及排序切片和数组
标准库提供了 sort 包来实现常见的搜索和排序操作。您可以使用 sort 包中的函数 func Ints(a []int) 来实现对 int 类型的切片排序。例如 sort.Ints(arri),其中变量 arri 就是需要被升序排序的数组或切片。为了检查某个数组是否已经被排序,可以通过函数 IntsAreSorted(a []int) bool 来检查,如果返回 true 则表示已经被排序。
类似的,可以使用函数 func Float64s(a []float64) 来排序 float64 的元素,或使用函数 func Strings(a []string) 排序字符串元素。
想要在数组或切片中搜索一个元素,该数组或切片必须先被排序(因为标准库的搜索算法使用的是二分法)。然后,您就可以使用函数 func SearchInts(a []int, n int) int 进行搜索,并返回对应结果的索引值。
当然,还可以搜索 float64 和字符串:
func SearchFloat64s(a []float64, x float64) int
func SearchStrings(a []string, x string) int
您可以通过查看 官方文档 来获取更详细的信息。
这就是如何使用 sort 包的方法,我们会在第 11.7 节 对它的细节进行深入,并实现一个属于我们自己的版本。
append() 函数常见操作
我们在第 7.5 节提到的 append() 非常有用,它能够用于各种方面的操作:
-
将切片
b的元素追加到切片a之后:a = append(a, b...) -
复制切片
a的元素到新的切片b上:b = make([]T, len(a)) copy(b, a) -
删除位于索引
i的元素:a = append(a[:i], a[i+1:]...) -
切除切片
a中从索引i至j位置的元素:a = append(a[:i], a[j:]...) -
为切片
a扩展j个元素长度:a = append(a, make([]T, j)...) -
在索引
i的位置插入元素x:a = append(a[:i], append([]T{x}, a[i:]...)...) -
在索引
i的位置插入长度为j的新切片:a = append(a[:i], append(make([]T, j), a[i:]...)...) -
在索引
i的位置插入切片b的所有元素:a = append(a[:i], append(b, a[i:]...)...) -
取出位于切片
a最末尾的元素x:x, a = a[len(a)-1], a[:len(a)-1] -
将元素
x追加到切片a:a = append(a, x)
因此,您可以使用切片和 append() 操作来表示任意可变长度的序列。
从数学的角度来看,切片相当于向量,如果需要的话可以定义一个向量作为切片的别名来进行操作。
如果您需要更加完整的方案,可以学习一下 Eleanor McHugh 编写的几个包:slices、chain 和 lists。
切片和垃圾回收
切片的底层指向一个数组,该数组的实际容量可能要大于切片所定义的容量。只有在没有任何切片指向的时候,底层的数组内存才会被释放,这种特性有时会导致程序占用多余的内存。
函数 FindDigits() 将一个文件加载到内存,然后搜索其中所有的数字并返回一个切片:
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
这段代码可以顺利运行,但返回的 []byte 指向的底层是整个文件的数据。只要该返回的切片不被释放,垃圾回收器就不能释放整个文件所占用的内存。换句话说,一点点有用的数据却占用了整个文件的内存。
想要避免这个问题,可以通过拷贝我们需要的部分到一个新的切片中:
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}
事实上,上面这段代码只能找到第一个匹配正则表达式的数字串。要想找到所有的数字,可以尝试下面这段代码:
func FindFileDigits(filename string) []byte {
fileBytes, _ := ioutil.ReadFile(filename)
b := digitRegexp.FindAll(fileBytes, len(fileBytes))
c := make([]byte, 0)
for _, bytes := range b {
c = append(c, bytes...)
}
return c
}
是的,底层的数组内存在没有任何切片指向时才会被释放。在 Go 中,切片是对底层数组的引用,它们包括一个指向数组的指针、长度和容量。底层数组的内存只有在没有任何切片引用时才会被回收。
这是因为 Go 的垃圾回收机制(Garbage Collection)负责管理内存,它会跟踪对象(包括切片和底层数组),并在这些对象不再被引用时将它们标记为垃圾,最终释放它们占用的内存。
当没有任何切片指向底层数组时,底层数组就变成不可达的对象,即没有引用指向它。在下一次垃圾回收周期时,底层数组的内存将被释放,以便重用或返回给操作系统。这有助于Go应用程序有效地管理内存。
这也意味着在某些情况下,即使你不再使用切片,底层数组的内存也可能不会立即被释放,因为垃圾回收的时机是由Go运行时系统控制的。如果需要确保内存立即被释放,可以使用 runtime.GC() 强制进行垃圾回收,但这在一般情况下是不推荐的,因为Go的垃圾回收机制通常会在合适的时机进行内存回收。