rust学习
rust学习
-
- String类型
- clone和copy
- 结构体的内存分布
- for循环(important!)
- 堆和栈
- 数据结构
-
- vector
- panic
- 模式匹配
-
- 忽略模式的值
- @绑定
- 方法和关联函数
- 线程学习
-
- 1.多线程的风险
- 2.使用spawn创建线程
-
- 等待子线程结束
- move 关键字强制闭包获取其使用的环境值的所有权
Ok,Let’s rust !
String类型
String 类型
let mut s = String::from("hello world");
&String类型
let mut s1 = &s
字符串切片类型是&str
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
clone和copy
参考链接!link
结构体的内存分布
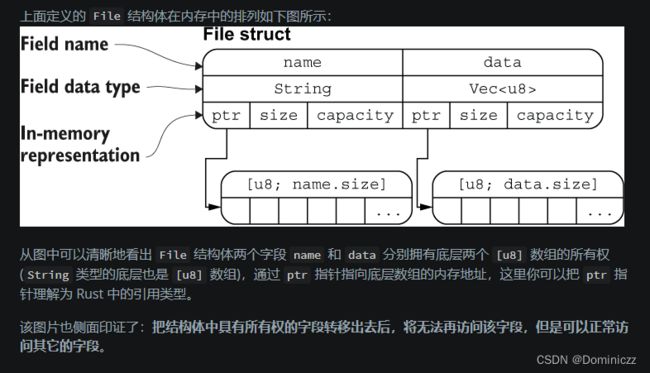
for循环(important!)
1..=5 代表 1 2 3 4 5
1..5 代表1 2 3 4
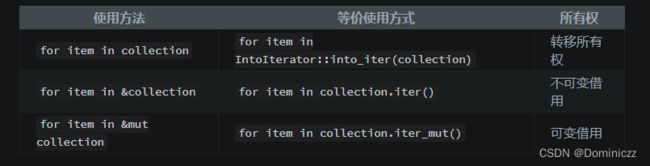
for in 结构能以几种方式与 Iterator 互动。在 迭代器 trait 一节将会谈到,如果没有特别指定,for 循环会对给出的集合应用 into_iter 函数,把它转换成一个迭代器。这并不是把集合变成迭代器的唯一方法,其他的方法有 iter 和iter_mut 函数。
下列三种情况刚好对应上面的表格!
- iter
在每次迭代中借用集合中的一个元素。这样集合本身不会被改变,循环之后仍可以使用。
fn main() {
let names = vec!["Bob", "Frank", "Ferris"];
for name in names.iter() {
match name {
&"Ferris" => println!("There is a rustacean among us!"),
_ => println!("Hello {}", name),
}
}
}
- info_iter
会消耗集合。在每次迭代中,集合中的数据本身会被提供。一旦集合被消耗了,之后就无法再使用了,因为它已经在循环中被 “移除”(move)了。
fn main() {
let names = vec!["Bob", "Frank", "Ferris"];
for name in names.into_iter() {
match name {
"Ferris" => println!("There is a rustacean among us!"),
_ => println!("Hello {}", name),
}
}
}
- iter_mut
可变地(mutably)借用集合中的每个元素,从而允许集合被就地修改。
fn main() {
let mut names = vec!["Bob", "Frank", "Ferris"];
for name in names.iter_mut() {
*name = match name {
&mut "Ferris" => "There is a rustacean among us!",
_ => "Hello",
}
}
println!("names: {:?}", names);
}
堆和栈
在很多语言中,你并不需要经常考虑到栈与堆。不过在像 Rust 这样的系统编程语言中,值是位于栈上还是堆上在更大程度上影响了语言的行为以及为何必须做出这样的抉择。我们会在本章的稍后部分描述所有权与栈和堆相关的内容,所以这里只是一个用来预热的简要解释。
栈和堆都是代码在运行时可供使用的内存,但是它们的结构不同。栈以放入值的顺序存储值并以相反顺序取出值。这也被称作 后进先出(last in, first out)。想象一下一叠盘子:当增加更多盘子时,把它们放在盘子堆的顶部,当需要盘子时,也从顶部拿走。不能从中间也不能从底部增加或拿走盘子!增加数据叫做 进栈(pushing onto the stack),而移出数据叫做 出栈(popping off the stack)。栈中的所有数据都必须占用已知且固定的大小。在编译时大小未知或大小可能变化的数据,要改为存储在堆上。 堆是缺乏组织的:当向堆放入数据时,你要请求一定大小的空间。内存分配器(memory allocator)在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer)。这个过程称作 在堆上分配内存(allocating on the heap),有时简称为 “分配”(allocating)。(将数据推入栈中并不被认为是分配)。因为指向放入堆中数据的指针是已知的并且大小是固定的,你可以将该指针存储在栈上,不过当需要实际数据时,必须访问指针。想象一下去餐馆就座吃饭。当进入时,你说明有几个人,餐馆员工会找到一个够大的空桌子并领你们过去。如果有人来迟了,他们也可以通过询问来找到你们坐在哪。
入栈比在堆上分配内存要快,因为(入栈时)分配器无需为存储新数据去搜索内存空间;其位置总是在栈顶。相比之下,在堆上分配内存则需要更多的工作,这是因为分配器必须首先找到一块足够存放数据的内存空间,并接着做一些记录为下一次分配做准备。
访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。继续类比,假设有一个服务员在餐厅里处理多个桌子的点菜。在一个桌子报完所有菜后再移动到下一个桌子是最有效率的。从桌子 A 听一个菜,接着桌子 B 听一个菜,然后再桌子 A,然后再桌子 B 这样的流程会更加缓慢。出于同样原因,处理器在处理的数据彼此较近的时候(比如在栈上)比较远的时候(比如可能在堆上)能更好的工作。
当你的代码调用一个函数时,传递给函数的值(包括可能指向堆上数据的指针)和函数的局部变量被压入栈中。当函数结束时,这些值被移出栈。
跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上的重复数据的数量,以及清理堆上不再使用的数据确保不会耗尽空间,这些问题正是所有权系统要处理的。一旦理解了所有权,你就不需要经常考虑栈和堆了,不过明白了所有权的主要目的就是为了管理堆数据,能够帮助解释为什么所有权要以这种方式工作。
fn main() {
let mut x = 5;
let mut y = x;
x = 6;
println!("{},{}", x, y)
}
输出6,5
为什么y不是6呢?因为普通i32变量在赋值的时候,只是值的拷贝,实际上他们的两个不同的5
数据结构
vector
使用宏自动推断类型
fn main() {
let v = vec![1, 2, 3];
}
更新
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}
panic
vscode默认打开的是powershell
查看更多运行错误信息的命令:$env:RUST_BACKTRACE=1;cargo run
模式匹配
忽略模式的值
_s 和 _ 有些微妙的不同:_s 会将值绑定到变量,而**_** 则完全不会绑定
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{:?}", s);
}
s 是一个拥有所有权的动态字符串,在上面代码中,我们会得到一个错误
因为 s 的值会被转移给 _s,在 println! 中再次使用 s 会报错
但是如果使用_去匹配,则不会绑定值,因为s没有被移动到_
@绑定
@(读作 at)运算符允许为一个字段绑定另外一个变量。下面例子中,我们希望测试 Message::Hello 的 id 字段是否位于 3…=7 范围内,同时也希望能将其值绑定到 id_variable 变量中以便此分支中相关的代码可以使用它。我们可以将 id_variable 命名为 id,与字段同名,不过出于示例的目的这里选择了不同的名称。
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id_variable @ 3..=7 } => {
println!("Found an id in range: {}", id_variable)
},
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
},
Message::Hello { id } => {
println!("Found some other id: {}", id)
},
}
@绑定到底有什么用呢,注意看第一个匹配和第二个匹配,当范围匹配的时候,无法直接得到这个值,这个时候,就可以使用@绑定,得到具体的值。
方法和关联函数
new 是关联函数,width是方法
pub struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
pub fn new(width: u32, height: u32) -> Self {
Rectangle { width, height }
}
pub fn width(&self) -> u32 {
return self.width;
}
}
fn main() {
let rect1 = Rectangle::new(30, 50);
println!("{}", rect1.width());
}
// let rect1 = Rectangle::new(30, 50);
线程学习
1.多线程的风险
由于多线程的代码是同时运行的,因此我们无法保证线程间的执行顺序,这会导致一些问题:
- 竞态条件(race conditions),多个线程以非一致性的顺序同时访问数据资源
- 死锁(deadlocks),两个线程都想使用某个资源,但是又都在等待对方释放资源后才能使用,结果最终都无法继续执行
- 一些因为多线程导致的很隐晦的 BUG,难以复现和解决
虽然 Rust 已经通过各种机制减少了上述情况的发生,但是依然无法完全避免上述情况,因此我们在编程时需要格外的小心,同时本书也会列出多线程编程时常见的陷阱,让你提前规避可能的风险。
2.使用spawn创建线程
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
}
但是打印顺序是随机的,主线程和子线程会随机打印。有可能主线程执行完了,子线程还没有创建,这取决于操作系统的调度。
等待子线程结束
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..5 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
}
通过调用 handle.join,可以让当前线程阻塞,直到它等待的子线程的结束
在上面代码中,由于 main 线程会被阻塞,因此它直到子线程结束后才会输出自己的 1..5:
move 关键字强制闭包获取其使用的环境值的所有权
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
}
子线程要v的所有权,但是子线程和主线程执行顺序随机。在主线程丢弃,使用drop也不行。根本原因在于存在所有权冲突。
正确写法——添加move关键字
直接将所有权转移到子线程
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
// 下面代码会报错borrow of moved value: `v`
// println!("{:?}",v);
}