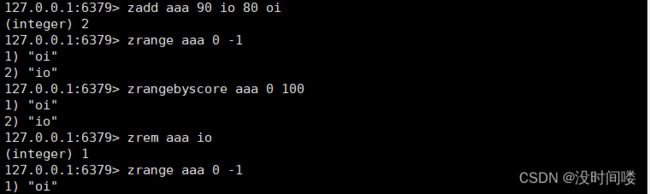
user: { id=1,name="zhagsan" } 修改复杂 需要序列化与反序列化
user:id 1 数据结构太乱
user:name zhangsan
key value key(用户id) filed(属性标签)
操作对应数据简单,不需要重复存
user field value 没有序列化和并发修改控制的问题
id 1
name zhangsan
hset 给集合中的 键赋值
hget 从集合取出 value
hdel 删除指定key的field (field全删掉 key也会删掉)
hmset ... 批量设置hash的值
hexists查看哈希表 key 中,给定域 field 是否存在。
hkeys 列出该hash集合的所有field
hvals 列出该hash集合的所有value
hincrby 为哈希表 key 中的域 field 的值加上增量 返回为结果
hsetnx 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .
androi中提到了布尔数组;
布尔数组默认的是false, 并且只会打印false或者是true
布尔数组的例子; 根据字符数组创建布尔数组
char[] c = {'p','u','b','l','i','c'};
//根据字符数组的长度创建布尔数组的个数
boolean[] b = new bool
文章摘自:http://blog.csdn.net/yangwawa19870921/article/details/7553181
在编写HQL时,可能会出现这种代码:
select a.name,b.age from TableA a left join TableB b on a.id=b.id
如果这是HQL,那么这段代码就是错误的,因为HQL不支持
1. 简单的for循环
public static void main(String[] args) {
for (int i = 1, y = i + 10; i < 5 && y < 12; i++, y = i * 2) {
System.err.println("i=" + i + " y="
异常信息本地化
Spring Security支持将展现给终端用户看的异常信息本地化,这些信息包括认证失败、访问被拒绝等。而对于展现给开发者看的异常信息和日志信息(如配置错误)则是不能够进行本地化的,它们是以英文硬编码在Spring Security的代码中的。在Spring-Security-core-x
近来工作中遇到这样的两个需求
1. 给个Date对象,找出该时间所在月的第一天和最后一天
2. 给个Date对象,找出该时间所在周的第一天和最后一天
需求1中的找月第一天很简单,我记得api中有setDate方法可以使用
使用setDate方法前,先看看getDate
var date = new Date();
console.log(date);
// Sat J
MyBatis的update元素的用法与insert元素基本相同,因此本篇不打算重复了。本篇仅记录批量update操作的
sql语句,懂得SQL语句,那么MyBatis部分的操作就简单了。 注意:下列批量更新语句都是作为一个事务整体执行,要不全部成功,要不全部回滚。
MSSQL的SQL语句
WITH R AS(
SELECT 'John' as name, 18 as









 数据结构
数据结构