html2canvas实现浏览器截图的原理(包含源码分析的通用方法)
DevUI是一支兼具设计视角和工程视角的团队,服务于华为云DevCloud平台和华为内部数个中后台系统,服务于设计师和前端工程师。
官方网站:devui.design
Ng组件库:ng-devui(欢迎Star)
官方交流:添加DevUI小助手(devui-official)
DevUIHelper插件:DevUIHelper-LSP(欢迎Star)
引言
有时用户希望将我们的报表页面分享到其他的渠道,比如邮件、PPT等,每次都需要自己截图,一是很麻烦,二是截出来的图大小不一。
有没有办法在页面提供一个下载报表页面的功能,用户只需要点击按钮,就自动将当前的报表页面以图片形式下载下来呢?
html2canvas库就能帮我们做到,无需后台支持,纯浏览器实现截图,即使页面有滚动条也是没问题的,截出来的图非常清晰。
这个库的维护时间非常长,早在2013年9月8日它就发布了第一个版本,比Vue的第一个版本(2013年12月8日)还要早。
截止到今天2020年12月18日,html2canvas库在github已经有22.3k star,在npm的周下载量也有506k,非常了不起!
上一次提交是在2020年8月9日,可见作者依然在很热情地维护着这个库,而且用TypeScript重构过,不过这个库的作者非常保守,哪怕已经持续不断地维护了7年,他在README里依然提到这个库目前还在实验阶段,不建议在生产环境使用。
事实上我很早就将这个库用在了生产环境,这篇文章就来分析下这个神奇和了不起的JavaScript库,看看它是怎么实现浏览器端截图的。
1 如何使用
在介绍html2canvas的原理之前,先来看看怎么使用它,使用起来真的非常简单,几乎是1分钟上手。
使用html2canvas只要以下3步:
- 安装
- 引入
- 调用
Step 1: 安装
npm i html2canvas
Step 2: 引入
随便在一个现代框架的工程项目中引入html2canvas
import html2canvas from 'html2canvas';
Step 3: 截图并下载
html2canvas就是一个函数,在页面渲染完成之后直接调用即可。
视图渲染完成的事件:
1. Angular的ngAfterViewInit方法
2. React的componentDidMount方法
3. Vue的mounted方法
可以只传一个参数,就是你要截图的DOM元素,该函数返回一个Promise对象,在它的then方法中可以获取到绘制好的canvas对象,通过调用canvas对象的toDataURL方法就可以将其转换成图片。
拿到图片的URL之后,我们可以
我们选择后者。
html2canvas(document.querySelector('.main')).then(canvas => {
const link = document.createElement('a'); // 创建一个超链接对象实例
const event = new MouseEvent('click'); // 创建一个鼠标事件的实例
link.download = 'Button.png'; // 设置要下载的图片的名称
link.href = canvas.toDataURL(); // 将图片的URL设置到超链接的href中
link.dispatchEvent(event); // 触发超链接的点击事件
});
是不是非常简单?
参数
我们再来大致看一眼它的API,该函数的签名如下:
html2canvas(element: HTMLElement, options: object): Promise
options对象可选的值如下:
| Name | Default | Description |
|---|---|---|
| allowTaint | false |
是否允许跨域图像污染画布 |
| backgroundColor | #ffffff |
画布背景颜色,如果在DOM中没有指定,设置“null”(透明) |
| canvas | null |
使用现有的“画布”元素,用来作为绘图的基础 |
| foreignObjectRendering | false |
是否使用ForeignObject渲染(如果浏览器支持的话) |
| imageTimeout | 15000 |
加载图像的超时时间(毫秒),设置为“0”以禁用超时 |
| ignoreElements | (element) => false |
从呈现中移除匹配元素 |
| logging | true |
为调试目的启用日志记录 |
| onclone | null |
回调函数,当文档被克隆以呈现时调用,可以用来修改将要呈现的内容,而不影响原始源文档。 |
| proxy | null |
用来加载跨域图片的代理URL,如果设置为空(默认),跨域图片将不会被加载 |
| removeContainer | true |
是否清除html2canvas临时创建的克隆DOM元素 |
| scale | window.devicePixelRatio |
用于渲染的缩放比例,默认为浏览器设备像素比 |
| useCORS | false |
是否尝试使用CORS从服务器加载图像 |
| width | Element width |
canvas的宽度 |
| height | Element height |
canvas的高度 |
| x | Element x-offset |
canvas的x轴位置 |
| y | Element y-offset |
canvas的y轴位置 |
| scrollX | Element scrollX |
渲染元素时使用的x轴位置(例如,如果元素使用position: fixed) |
| scrollY | Element scrollY |
渲染元素时使用的y轴位置(例如,如果元素使用position: fixed) |
| windowWidth | Window.innerWidth |
渲染元素时使用的窗口宽度,这可能会影响诸如媒体查询之类的事情 |
| windowHeight | Window.innerHeight |
渲染元素时使用的窗口高度,这可能会影响诸如媒体查询之类的事情 |
忽略元素
options有一个ignoreElements参数可以用来忽略某些元素,从渲染过程中移除,除了设置该参数外,还有一种忽略元素的方法,就是在需要忽略的元素上增加data-html2canvas-ignore属性。
Ignore element
2 基本原理
介绍完html2canvas的使用,我们先来了解下它的基本原理,然后再分析细节实现。
它的基本原理其实很简单,就是去读取已经渲染好的DOM元素的结构和样式信息,然后基于这些信息去构建截图,呈现在canvas画布中。
它无法绕过浏览器的内容策略限制,如果要呈现跨域图片,需要设置一个代理。
3 主流程 html2canvas方法
基本原理很简单,但源码里面其实东西很多,我们一步一步来,先找到入口,然后慢慢调试,走一遍大致的流程。
寻找入口文件
拉取到源码,有很多方法可以找到入口文件:
- 方法一:最简单的方法是直接全局搜索
html2canvas,这种方法效率很低,而且要碰运气,不推荐 - 方法二:在项目中引入这个库,调用它,跑起来,并在该方法前面打断点进行调试,一般能精确地找到入口文件,推荐
- 方法三:观察下是否有
webpack.config.js或者rollup.config.js的构建工具的配置文件,然后在配置文件中找到精确的入口文件(一般是entry或input之类的属性),推荐 - 方法四:直接扫一眼目录结构,一般入口文件在
src/core/packages之类的目录下,文件名是index或者main,或者是模块的名字,有经验的话可以用这个方法,找起来很快,强烈推荐
方法一:全局搜索
最简单最容易想到的的方法,就是全局搜索关键字html2canvas,因为我们在不了解html2canvas的实现之前,我们接触到的关键字就只有这一个。
但是全局搜索运气不好的话,很可能搜出来很多结果,在里面找入口文件费时费力,比如:

42个文件285个结果,找起来很麻烦,不推荐。
方法二:打断点
在调用html2canvas的地方打一个断点。

然后在执行到断点处时,点击向下的小箭头,进入该方法。
![]()
因为在开发环境,很快我们就能发现入口文件和入口方法在哪儿,这里显示的是html2canvas文件,实际上这个文件是构建之后的文件,但是这个文件的上下文给我们提供了找入口方法的信息,这里我们发现了renderElement方法。
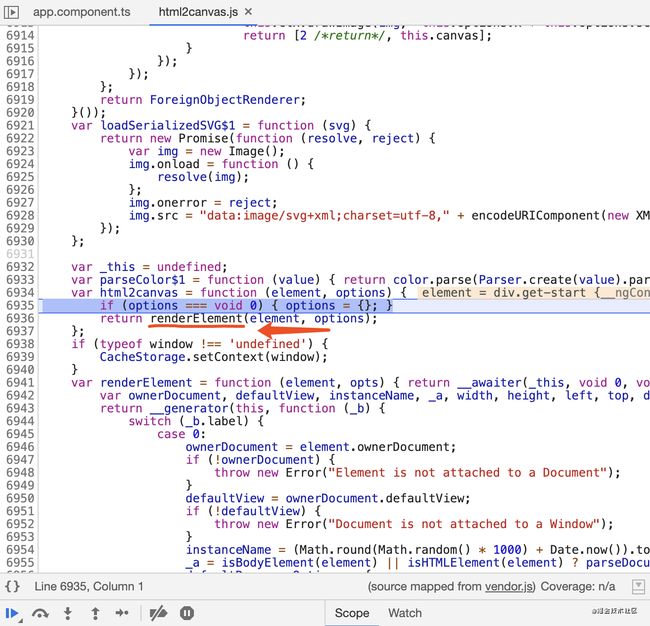
这时我们可以尝试全局搜索这个方法,很幸运直接找到了
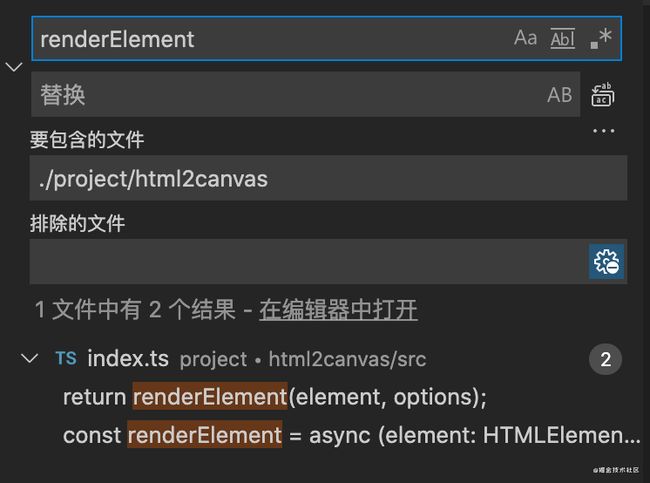
方法三:找配置文件
寻找配置文件一般也要靠经验,一般配置文件都会带.config后缀常见构建工具的配置文件:
| 构建工具 | 配置文件 |
|---|---|
| Webpack | webpack.config.js |
| Rollup | rollup.config.js |
| Gulp | glupfile.config.js |
| Grunt | Gruntfile.js |
配置文件找到,入口文件一般很容易就找到
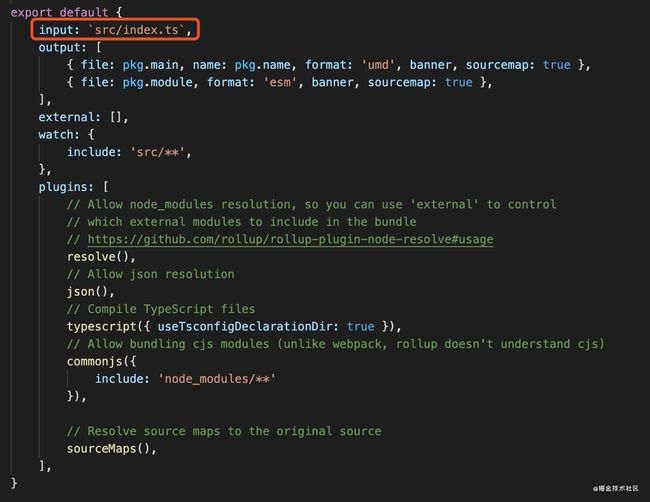
方法四:
方法四一般也要靠经验,我们扫一眼目录结构,其实很容易就能发现主入口src/index.ts
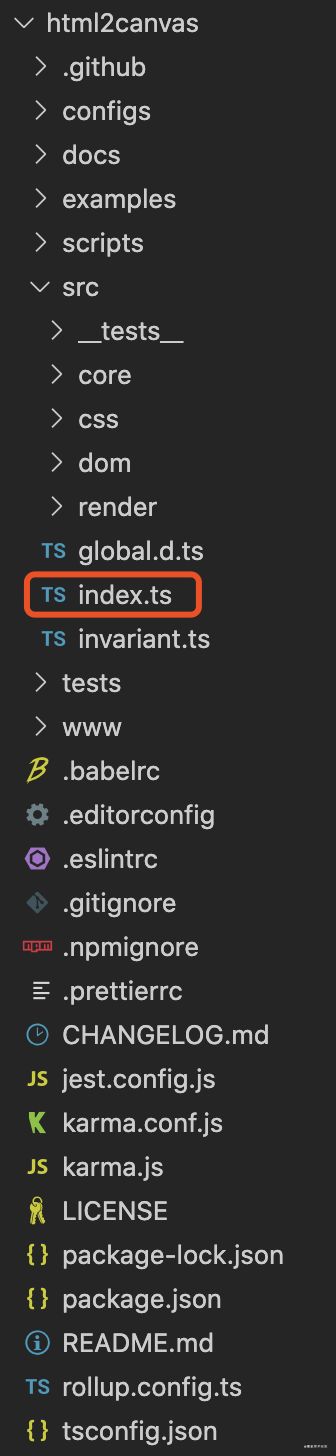
从主入口出发
我们已经找到了入口方法在src/index.ts文件中,先从主入口出发,把大致的调用关系梳理出来,对全局有个基本的了解,然后再深入细节。
入口方法几乎啥也没做,直接返回了另一个方法renderElement的调用结果。
// 入口方法
const html2canvas = (element: HTMLElement, options: Partial = {}): Promise => {
return renderElement(element, options);
};
沿着调用关系往下,很快我们就梳理出了如下简易火焰图(带方法注释)

这张简易的火焰图主要有两点需要注意:
- 简易火焰图只是帮助我们对整个流程有个粗略的认识,这种认识既不细致也不全面,需要进一步分析里面的关键方法
- renderStackContent这个渲染层叠内容的方法是整个html2canvas最核心的方法,我们将在
4 渲染层叠内容一章中单独分析
将页面中指定的DOM元素渲染到离屏canvas中 renderElement
通过简易火焰图,我们已经对html2canvas的主流程有了一个基本的认识,接下来我们一层一层来分析,先看renderElement方法。
这个方法的主要目的是将页面中指定的DOM元素渲染到一个离屏canvas中,并将渲染好的canvas返回给用户。
它主要做了以下事情:
- 解析用户传入的options,将其与默认的options合并,得到用于渲染的配置数据renderOptions
- 对传入的DOM元素进行解析,取到节点信息和样式信息,这些节点信息会和上一步的renderOptions配置一起传给canvasRenderer实例,用来绘制离屏canvas
- canvasRenderer将依据浏览器渲染层叠内容的规则,将用户传入的DOM元素渲染到一个离屏canvas中,这个离屏canvas我们可以在then方法的回调中取到
renderElement方法的核心代码如下:
const renderElement = async (element: HTMLElement, opts: Partial): Promise => {
const renderOptions = {...defaultOptions, ...opts}; // 合并默认配置和用户配置
const renderer = new CanvasRenderer(renderOptions); // 根据渲染的配置数据生成canvasRenderer实例
const root = parseTree(element); // 解析用户传入的DOM元素(为了不影响原始的DOM,实际上会克隆一个新的DOM元素),获取节点信息
return await renderer.render(root); // canvasRenderer实例会根据解析到的节点信息,依据浏览器渲染层叠内容的规则,将DOM元素内容渲染到离屏canvas中
};
合并配置的逻辑比较简单,我们直接略过,重点分析下解析节点信息(parseTree)和渲染离屏canvas(renderer.render)两个逻辑。
解析节点信息 parseTree
parseTree的入参就是一个普通的DOM元素,返回值是一个ElementContainer对象,该对象主要包含DOM元素的位置信息(bounds: width|height|left|top)、样式数据、文本节点数据等(只是节点树的相关信息,不包含层叠数据,层叠数据在parseStackingContexts方法中取得)。
解析的方法就是递归整个DOM树,并取得每一层节点的数据。
ElementContainer对象是一颗树状结构,大致如下:
{
bounds: {height: 1303.6875, left: 8, top: -298.5625, width: 1273},
elements: [
{
bounds: {left: 8, top: -298.5625, width: 1273, height: 1303.6875},
elements: [
{
bounds: {left: 8, top: -298.5625, width: 1273, height: 1303.6875},
elements: [
{styles: CSSParsedDeclaration, textNodes: Array(1), elements: Array(0), bounds: Bounds, flags: 0},
{styles: CSSParsedDeclaration, textNodes: Array(1), elements: Array(0), bounds: Bounds, flags: 0},
{styles: CSSParsedDeclaration, textNodes: Array(1), elements: Array(0), bounds: Bounds, flags: 0},
{styles: CSSParsedDeclaration, textNodes: Array(3), elements: Array(2), bounds: Bounds, flags: 0},
...
],
flags: 0,
styles: {backgroundClip: Array(1), backgroundColor: 0, backgroundImage: Array(0), backgroundOrigin: Array(1), backgroundPosition: Array(1), …},
textNodes: []
}
],
flags: 0,
styles: CSSParsedDeclaration {backgroundClip: Array(1), backgroundColor: 0, backgroundImage: Array(0), backgroundOrigin: Array(1), backgroundPosition: Array(1), …},
textNodes: []
}
],
flags: 4,
styles: CSSParsedDeclaration {backgroundClip: Array(1), backgroundColor: 0, backgroundImage: Array(0), backgroundOrigin: Array(1), backgroundPosition: Array(1), …},
textNodes: []
}
里面包含了每一层节点的:
- bounds - 位置信息(宽/高、横/纵坐标)
- elements - 子元素信息
- flags - 用来决定如何渲染的标志
- styles - 样式描述信息
- textNodes - 文本节点信息
渲染离屏canvas renderer.render
有了节点树信息,就可以用来渲染离屏canvas了,我们来看看渲染的逻辑。
渲染的逻辑在CanvasRenderer类的render方法中,该方法主要用来渲染层叠内容:
- 使用上一步解析到的节点数据,生成层叠数据
- 使用节点的层叠数据,依据浏览器渲染层叠数据的规则,将DOM元素一层一层渲染到离屏canvas中
render方法的核心代码如下:
async render(element: ElementContainer): Promise {
/**
* StackingContext {
* element: ElementPaint {container: ElementContainer, effects: Array(0), curves: BoundCurves}
* inlineLevel: []
* negativeZIndex: []
* nonInlineLevel: [ElementPaint]
* nonPositionedFloats: []
* nonPositionedInlineLevel: []
* positiveZIndex: [StackingContext]
* zeroOrAutoZIndexOrTransformedOrOpacity: [StackingContext]
* }
*/
const stack = parseStackingContexts(element);
// 渲染层叠内容
await this.renderStack(stack);
return this.canvas;
}
其中的
inlineLevel- 内联元素negativeZIndex- zIndex为负的元素nonInlineLevel- 非内联元素nonPositionedFloats- 未定位的浮动元素nonPositionedInlineLevel- 内联的非定位元素,包含内联表和内联块positiveZIndex- z-index大于等于1的元素zeroOrAutoZIndexOrTransformedOrOpacity- 所有有层叠上下文的(z-index: auto|0)、透明度小于1的(opacity小于1)或变换的(transform不为none)元素
代表的是层叠信息,渲染层叠内容时会根据这些层叠信息来决定渲染的顺序,一层一层有序进行渲染。
parseStackingContexts解析层叠信息的方式和parseTree解析节点信息的方式类似,都是递归整棵树,收集树的每一层的信息,形成一颗包含层叠信息的层叠树。
而渲染层叠内容的renderStack方式实际上调用的是renderStackContent方法,该方法是整个渲染流程中最为关键的方法,下一章单独分析。
4 渲染层叠内容 renderStackContent
将DOM元素一层一层得渲染到离屏canvas中,是html2canvas所做的最核心的事情,这件事由renderStackContent方法来实现。
因此有必要重点分析这个方法的实现原理,这里涉及到CSS布局相关的一些知识,我先做一个简单的介绍。
CSS层叠布局规则
默认情况下,CSS是流式布局的,元素与元素之间不会重叠。
流式布局的意思可以理解:在一个矩形的水面上,放置很多矩形的浮块,浮块会漂浮在水面上,且彼此之间依次排列,不会重叠在一起
这是要绘制它们其实非常简单,一个个按顺序绘制即可。
不过有些情况下,这种流式布局会被打破,比如使用了浮动(float)和定位(position)。
因此需要需要识别出哪些脱离了正常文档流的元素,并记住它们的层叠信息,以便正确地渲染它们。
那些脱离正常文档流的元素会形成一个层叠上下文,可以将层叠上下文简单理解为一个个的薄层(类似Photoshop的图层),薄层中有很多DOM元素,这些薄层叠在一起,最终形成了我们看到的多彩的页面。
这些不同类型的层的层叠顺序规则如下:
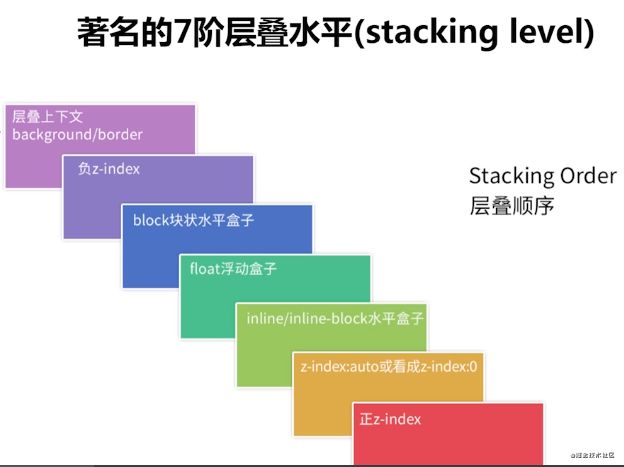
这张图很重要,html2canvas渲染DOM元素的规则也是一样的,可以认为html2canvas就是对这张图描述的规则的一个实现。
详细的规则在w3官方文档中有描述,大家可以参考:
https://www.w3.org/TR/css-position-3/#painting-order
renderStackContent就是对CSS层叠布局规则的一个实现
有了这些基础知识,我们分析renderStackContent就一目了然了,它的源码如下:
async renderStackContent(stack: StackingContext) {
// 1. 最底层是background/border
await this.renderNodeBackgroundAndBorders(stack.element);
// 2. 第二层是负z-index
for (const child of stack.negativeZIndex) {
await this.renderStack(child);
}
// 3. 第三层是block块状盒子
await this.renderNodeContent(stack.element);
for (const child of stack.nonInlineLevel) {
await this.renderNode(child);
}
// 4. 第四层是float浮动盒子
for (const child of stack.nonPositionedFloats) {
await this.renderStack(child);
}
// 5. 第五层是inline/inline-block水平盒子
for (const child of stack.nonPositionedInlineLevel) {
await this.renderStack(child);
}
for (const child of stack.inlineLevel) {
await this.renderNode(child);
}
// 6. 第六层是以下三种:
// (1) ‘z-index: auto’或‘z-index: 0’。
// (2) ‘transform: none’
// (3) opacity小于1
for (const child of stack.zeroOrAutoZIndexOrTransformedOrOpacity) {
await this.renderStack(child);
}
// 7. 第七层是正z-index
for (const child of stack.positiveZIndex) {
await this.renderStack(child);
}
}
小结
本文主要介绍html2canvas实现浏览器截图的原理。
首先简单介绍html2canvas是做什么的,如何使用它;
然后从主入口出发,分析html2canvas渲染DOM元素的大致流程(简易火焰图);
接着按火焰图的顺序,依次对renderElement方法中执行的parseTree/parseStackingContextrenderer.render三个方法进行分析,了解这些方法的作用和原理;
最后通过介绍CSS布局规则和7阶层叠水平,自然地引出renderStackContent关键方法实现原理的介绍。
加入我们
我们是DevUI团队,欢迎来这里和我们一起打造优雅高效的人机设计/研发体系。招聘邮箱:[email protected]。
文/DevUI Kagol
往期文章推荐
《在瀑布下用火焰烤饼:三步法助你快速定位网站性能问题(超详细)》
《 DevUI × 掘金 | 技术人的2020》
《手把手教你搭建一个灰度发布环境》