Redis面试题
文章目录
-
- 1、用过redis干过啥?
- 2、redis和MySQL数据一致性问题
- 3、重新设计项目会有哪些想法?(答了redis集群)
- 4、redis缓存击穿?业界的解决方式了解吗?
- 5、Redis缓存内存满了,淘汰策略
- 6、缓存淘汰的算法
- 7、redis为什么快
- 8、Redis哈希槽
- 9、Redis脑裂
- 10、Redis 分布式锁问题
- 11、Redis 底层数据结构
- 12、Redis的AOF和RDB
- 13、Redis的使用方式
1、用过redis干过啥?
1、缓存
根据局部性原理,80%的请求会落在20%的热点数据上,对于读多写少的场景,增加缓存有利于提高吞吐量
使用过期时间兜底,先更新DB,后删除缓存,提升数据一致性
2、分布式锁
set key value nx ex secondsnx
setnx命令,key是锁名字,value是持有者id,在设置一个过期时间兜底。
value必须是谁申请、谁释放,在解锁时需要先进行检查
1、加上owner——谁申请、谁释放
2、lua脚本——保证原子操作
- 查看是否是自己的锁
- 如果是,释放锁
2、redis和MySQL数据一致性问题
1、更新MySQL即可,不管Redis,以过期时间兜底
2、更新MySQL之后,操作Redis
- 删除√(主动删除,减少不一致)
- 更新(少用)
更新MySQL,删除Redis
3、异步将MySQL同步更新到Redis
- 引入消息队列,业务解耦,但成本大
3、重新设计项目会有哪些想法?(答了redis集群)
参考8题
4、redis缓存击穿?业界的解决方式了解吗?



5、Redis缓存内存满了,淘汰策略
Redis:惰性+定期

6、缓存淘汰的算法
1、LRU淘汰最久未使用(底层链表)
2、LFU淘汰最少使用
7、redis为什么快
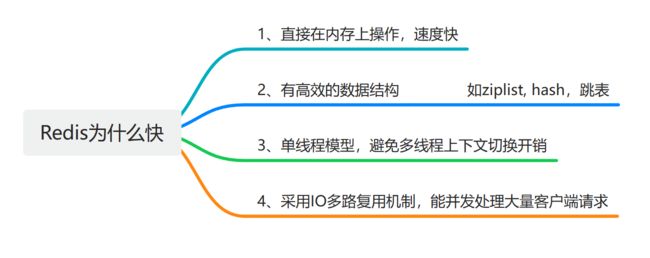
原理?
采用I/O多路复用机制同时监听多个Socket,根据Socket上的事件来选择对应的事件处理器进行处理

8、Redis哈希槽
Redis Cluser用哈希槽来处理数据和节点的映射关系
两种方案:
1、平均分配:集群创建时,Redis自动将哈希槽平均分配到集群节点上
2、手动分配:使用命令指定每个节点上面的哈希槽数目
使用手动分配时要把16384个槽位给分完,否则集群不会正常工作
Redis集群
Redis集群中有多个主节点,每个主节点有多个从节点
当主节点发生故障时,从节点被选举为主节点,继续工作
数据分片
Redis集群使用哈希槽的方式实现数据分片存储,有固定的16384个哈希槽
计算key对应槽位置:CRC16(key)%16384
流程:客户端连接Redis Cluster中任意一个master节点即可访问Redis Cluster的数据,当客户端发送命令请求的时候,需要先根据key通过上面的计算公式找到对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标节点
一个切片集群共16384个哈希槽,为什么?
假设哈希槽采用 16384,则占空间 2k(16384/8);
假设哈希槽采用 65536, 则占空间 8k(65536/8)
Redis Cluster 不太可能扩展到超过 1000 个主节点
所以,65536 个可以确保每个主节点有足够的哈希槽,但其占用的空间太大。而且,Redis Cluster 的主节点通常不会扩展太多,16384 个哈希槽完全足够用了
9、Redis脑裂
Redis主从架构一般是一主多从,主节点提供写操作,从节点提供读操作
如果主节点网络出错,与所有从节点失联,此时主节点与客户端网络正常,客户端不知道集群内部出错,继续向主节点写数据
哨兵也发现主节点失联,从从节点中选举一个leader作为主节点,导致集群有两个主节点——脑裂现象【网络出错,节点失联,选举节点,两个主节点】
网络恢复后,哨兵会把原主节点降级,从旧主节点会向新主节点请求数据同步,第一次同步是全量同步的方式,旧主节点会清空掉自己本地的数据,客户端在过程之前写入的数据就会丢失了——脑裂会导致数据丢失
解决方案
主节点发现从节点下线或通信超时总数量小于阈值,禁止主节点写数据,直接返回错误给客户端
min-slaves-to-write-N:主库至少有N个从库
min-slaves-max-lag-T:主库复制数据时,ACK延迟不能超过T秒
否则,原主节点会限制客户端写请求,只有新主节点上线,才能继续接收和处理客户端请求,因此不会造成数据丢失
10、Redis 分布式锁问题
set key value nx ex secondsnx
setnx命令,key是锁名字,value是持有者id,在设置一个过期时间兜底。
value必须是谁申请、谁释放,在解锁时需要先进行检查
1、加上owner——谁申请、谁释放
2、lua脚本——保证原子操作
- 查看是否是自己的锁
- 如果是,释放锁
11、Redis 底层数据结构
有几种数据结构?底层实现原理?应用场景?
对象、SDS、列表list、压缩列表ziplist、哈希表hash、跳表zskiplist、整数集合inset、quicklist、listpack
补充相关知识
12、Redis的AOF和RDB
RDB和AOF的区别
- 文件类型:RDB生成的是 二进制文件(快照),AOF生成的是 文本文件(追加日志)
- 安全性:缓存宕机时,RDB容易丢失较多的数据,AOF根据策略决定(默认everysec可以保证最多有一秒的丢失)
- 文件恢复速度:由于RDB是二进制文件,所以恢复速度也比 AOF更快
- 操作的开销:每一次RDB保存都是一次全量保存,操作比较重,通常设置至少5min保存一次数据。而AOF的刷盘是一次追加操作,操作比较轻,通常设置策略为每1s进行一次刷盘
13、Redis的使用方式
各个方式的介绍 集群和哨兵的区别 还有虚拟分槽 有多少个槽
单机模式、主从模式、哨兵模式、集群模式
1、单机模式
单个 Redis 节点部署,没有备用节点实时同步数据,不提供数据持久化和备份策略,适用于数据可靠性要求不高的纯缓存业务场景
2、主从模式
主库提供读写服务,从库只用于备份
三种架构:一主一从、一主多从、主从从(从节点与主节点的从节点保持一致)
三种同步方式:全量同步、增量同步、部分同步
补充相关知识
区别MySQL复制模式:同步复制、异步复制(默认)、半同步复制
问题:无法自动故障转移,主节点宕机后,必须手动设置从节点为主节点
3、哨兵模式
主动监控、主动下线、客观下线、Master选举,保证故障转移
至少3+3部署:3个哨兵节点+3个Redis节点
哨兵机制:哨兵会监测主节点是否存活,如果发现主节点挂了,会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端
工作原理
-
判断节点是否存活
哨兵会周期性给所有主节点发送PING命令来判断其他节点是否正常运行
如果PING命令响应失败哨兵会将节点标记为主观下线,然后该哨兵会向其他节点发出投票命令,当票数达到设定的阈值之后这个主节点就被标记为客观下线。然后哨兵会从从节点中选择一个作为主节点
-
投票
哨兵集群中会选择一个leader来负责主从切换,选举是一个投票过程:判断主节点为客观下线的是候选者,候选者向其他哨兵发送命令表示要成为leader,其他哨兵会进行投票,每个哨兵只有一票,可以投给自己或投给别人,但是只有候选者才能把票投给自己。候选者之后拿到半数以上的赞成票并且票数大于设置的阈值,就会成为候选者
-
选出新主节点
把网络状态不好的从节点给排除:先把已经下线的从节点过滤掉,然后把以往网络连接状态不好的从节点排除掉。接下来要对所有从节点进行三轮考察:优先级、复制进度、ID号。在进行每一轮考察的时候,哪个从节点优先胜出,就选择其作为新主节点
- 第一轮考察:哨兵首先会根据从节点的优先级来进行排序,优先级越小排名越靠前
- 第二轮考察:如果优先级相同,则查看复制的下标,哪个接收的复制数据多哪个就靠前
- 第三轮考察:如果优先级和下标都相同,选择ID较小的那个
-
更换主节点
选出新主节点之后,哨兵leader让已下线主节点属下的所有从节点指向新主节点。
-
通知客户的主节点已更换
客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后,哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了。
-
将旧主节点变为从节点
继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送SLAVEOF命令,让它成为新主节点的从节点
4、集群模式
海量数据存储、高并发、高可用
分片存储:Twemproxy、Codis中间件
原理:中间件将请求的数据key经过哈希算法、一致性哈希算法、取模等,将数据分配到不同的节点上
用哈希槽实现数据分片【查看第8题】