Flink CDC 2.0 主要是借鉴 DBLog 算法
DBLog 算法原理

DBLog 这个算法的原理分成两个部分,第一部分是分 chunk,第二部分是读 chunk。分 chunk 就是把一张表分为多个 chunk(桶/片)。我可以把这些 chunk 分发给不同的并发的 task 去做。例如:有 reader1 和 reader2,不同的 reader 负责读不同的 chunk。其实只要保证每个 reader 读的那个 chunk 是完整的,也能跟最新的 Binlog 能够匹配在一起就可以了。在读 chunk 的过程中,会同时读属于这个 chunk的历史数据,也会读这个 chunk 期间发生的 Binlog 事件,然后来做一个 normalize。

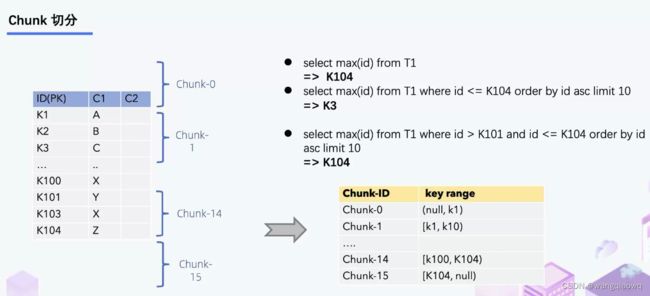
首先是 chunk 的划分。一张表,它的 ID 字段是主键 PK。通过 query 能够知道最大的 PK 也能知道最小的 PK。然后根据最大最小的 PK 设定一个步长,那么就能把这个表分成一些 chunk。每个 chunk 是一个左闭右开的区间,这样可以实现 chunk 的无缝衔接。第一个 chunk 和最后一个 chunk 最后一个字段,是一个正无穷和负无穷的表示, 即所有小于 k1 的 key 由第一个 chunk 去读,所有大于 K104 的 key 由最后一个chunk去读。
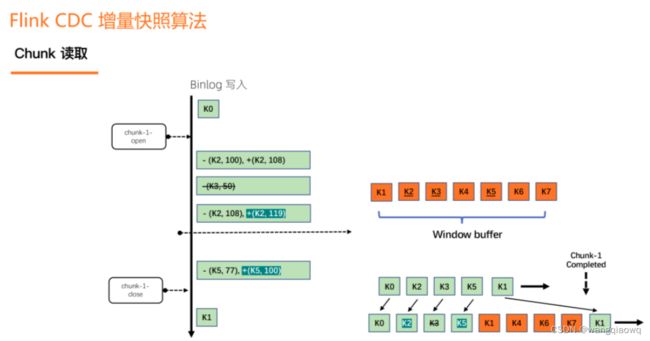
chunk 的读取,首先有一个 open 打点的过程,还有一个 close 打点的过程。例如,读属于这个 chunk1 的所有数据时,橘色的 K1 到 K7 是这些全量数据。橘黄色里面有下划线的数据,是在读期间这些 Binlog 在做改变。比如 K2 就是一条 update,从 100 变成 108,K3 是一条 delete。K2 后面又变成 119。还有 K5 也是一个update。在 K2、K3、K5 做标记,说明它们已经不是最新的数据了,需要从 Binlog 里面读出来,做一个 merge 获取最新的数据, 最后读出来的就是在 close 位点时刻的最新数据。最后的效果就是,将 update 最新的数据最终输出,将 delete 的数据如 K3 不输出。所以在 chunk1 读完的时候,输出的数据是 K0、K2、K4、K5、K6、K7 这些数据,这些数据也是在 close 位点时数据库中该 chunk 的数据。
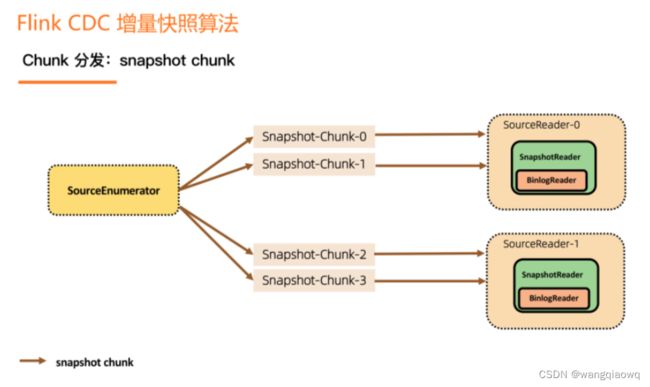
接下来是 chunk 的分发。一张表切成了 N 个 chunk 后,SourceEnumerator 会将这些 chunk 分给一些 SourceReader 并行地读取,并行读是用户可以配置的,这就是水平扩展能力。
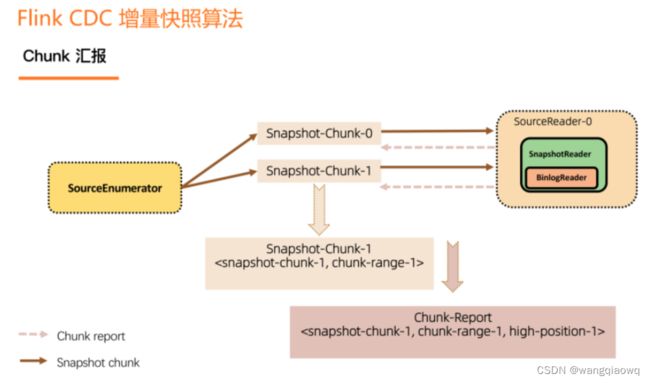
每一个 Snapshot chunk 读完了之后有一个信息汇报过程,这个汇报非常关键,包含该 chunk 的基本信息和该 chunk 是在什么位点读完的(即 close 位点)。在进入 Binlog 读取阶段之后, 在 close 位点之后且属于这个 chunk 的 binlog 数据,是要需要继续读取的,从而来保证数据的完整性。

在所有的 Snapshot chunk 读完之后会发一个特殊的 Binlog chunk,该 chunk 里包含刚刚所有 Snapshot chunk 的汇报信息。Binlog Reader 会根据所有的 Snapshot chunk 汇报信息按照各自的位点进行跳读,跳读完后再进入一个纯粹的 binlog 读取。跳读就是需要考虑各个 snapshot chunk 读完全量时的 close 位点进行过滤,避免重复数据,纯 binlog 读就是在跳读完成后只要是属于目标表的 changelog 都读取。
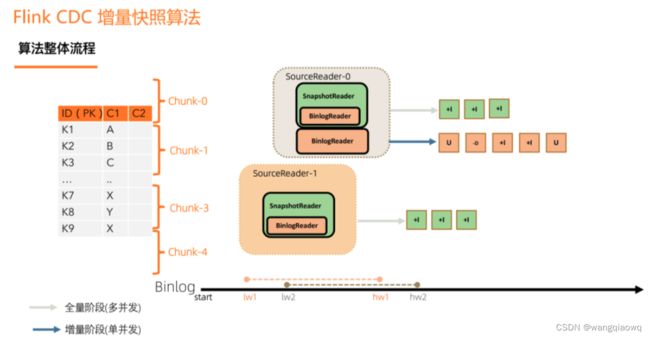
Flink CDC 增量快照算法流程为,首先,一张表按 key 分成一个个 chunk,Binlog在不断地写,全量阶段由 SourceReader 去读,进入增量阶段后,SourceReader 中会启一个 BinlogReader 来读增量的部分。全量阶段只会有 insert only 的数据,增量阶段才会有 update、delete 数据。SourceReader 中具体去负责读 chunk 的 reader 会根据收到的分片类型,决定启动 SnapshotReader 还是 BinlogReader。

Flink CDC 增量快照算法的核心价值包括:
第一,实现了并行读取,水平扩展的能力,即使十亿百亿的大表,只要资源够,那么水平扩展就能够提升效率;
第二,实现 Dblog 算法的变动,它能够做到在保证一致性的情况下,实现无锁切换;
第三,基于 Flink 的 state 和 checkpoint 机制,它实现了断点续传。比如 task 1 失败了,不影响其它正在读的task,只需要把 task 1 负责的那几个 chunk 进行重读;
第四,全增量一体化,全增量自动切换。
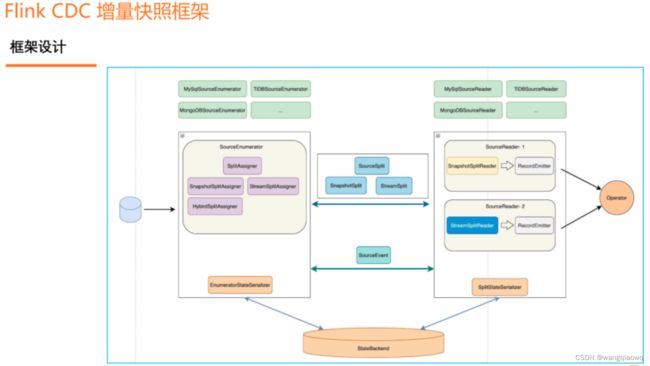
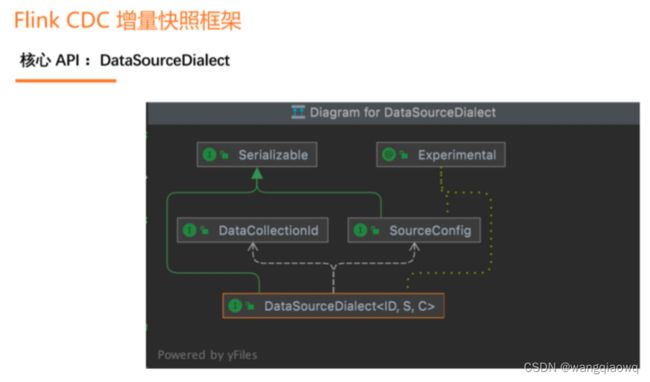
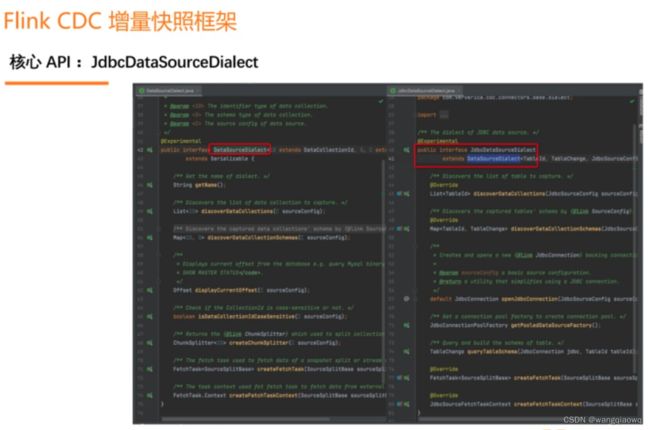
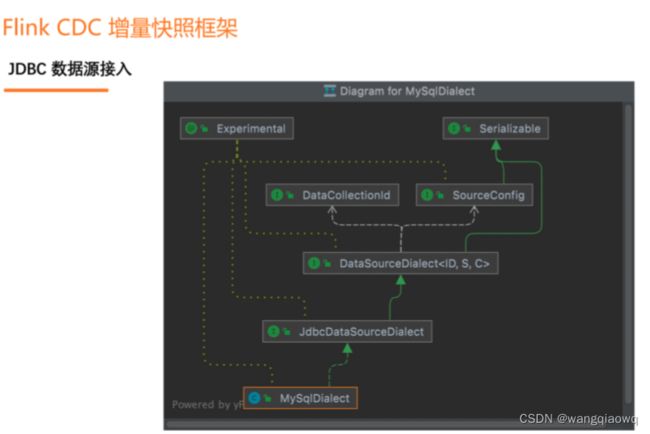
增量快照框架的设计围绕一个核心的 API 展开,这个核心的 API 就是DataSourceDialect(数据源方言),这个方言关心的就是面向某个数据源特有的,在接入全增量框架时需要实现的方法。
比较常见的CDC工具大都有过使用经验:
Debezium是国外⽤户常⽤的CDC组件,单机对于分布式来说,在数据读取能力的拓展上,没有分布式的更具有优势,在大数据众多的分布式框架中(Hive、Hudi等)Flink CDC 的架构能够很好地接入这些框架。
DataX无法支持增量同步。如果一张Mysql表每天增量的数据是不同天的数据,并且没有办法确定它的产生时间,那么如何将数据同步到数仓是一个值得考虑的问题。DataX支持全表同步,也支持sql查询的方式导入导出,全量同步一定是不可取的,sql查询的方式没有可以确定增量数据的字段的话也不是一个好的增量数据同步方案。
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。Canal主要支持了MySQL的Binlog解析,将增量数据写入中间件中(例如kafka,Rocket MQ等),但是无法同步历史数据,因为无法获取到binlog的变更。
Sqoop主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递。Sqoop将导入或导出命令翻译成mapreduce程序来实现,这样的弊端就是Sqoop只能做批量导入,遵循事务的一致性,Mapreduce任务成功则同步成功,失败则全部同步失败。
Apache SeaTunnel是一个当前也非常受欢迎的数据集成同步组件。其可以支持全量和增量,支持流批一体。SeaTunnel的使用是非常简单的,零编写代码,只需要写一个配置文件脚本提交命令即可,同时也使用分布式的架构,可以依托于Flink,Spark以及自身的Zeta引擎的分布式完成一个任务在多个节点上运行。其内部也有类似Flink checkpoint的状态保存机制,用于故障恢复,sink阶段的两阶段提交机制也可以做到精准一次性Excatly-once。对于大部分的场景,SeaTunnel都能完美支持,但是SeaTunnel只能支持简单的数据转换逻辑,对于复杂的数据转换场景,还是需要Flink、Spark任务来完成。
Flink CDC 基本都弥补了以上框架的不足,将数据库的全量和增量数据一体化地同步到消息队列和数据仓库中;也可以用于实时数据集成,将数据库数据实时入湖入仓;无需像其他的CDC工具一样需要在服务器上进行部署,减少了维护成本,链路更少;完美套接Flink程序,CDC获取到的数据流直接对接Flink进行数据加工处理,一套代码即可完成对数据的抽取转换和写出,既可以使用flink的DataStream API完成编码,也可以使用较为上层的FlinkSQL API进行操作。
DBlog paper 论文的 chunk 切分算法。
该算法在数据库中维护了一张watermark(信号)表,记录每个chunk块的区间值位点LW和HW。

Flink CDC2.x 并没有维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能。
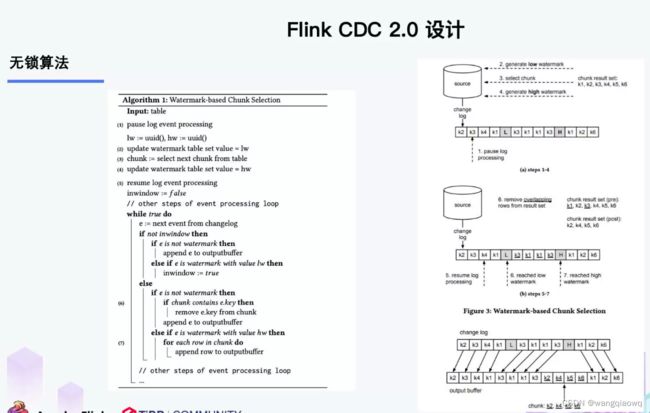
左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。
因为每个 chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个 Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
Netflix 的 DBLog 论文中 Chunk 读取算法是通过在 DB 维护一张信号表,再通过信号表在 binlog 文件中打点,记录每个 chunk 读取前的 Low Position (低位点) 和读取结束之后 High Position (高位点) ,在低位点和高位点之间去查询该 Chunk 的全量数据。在读取出这一部分 Chunk 的数据之后,再将这 2 个位点之间的 binlog 增量数据合并到 chunk 所属的全量数据,从而得到高位点时刻,该 chunk 对应的全量数据。
Flink CDC 结合自身的情况,在 Chunk 读取算法上做了去信号表的改进,不需要额外维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能,整体的 chunk 读算法描述如下图所示:
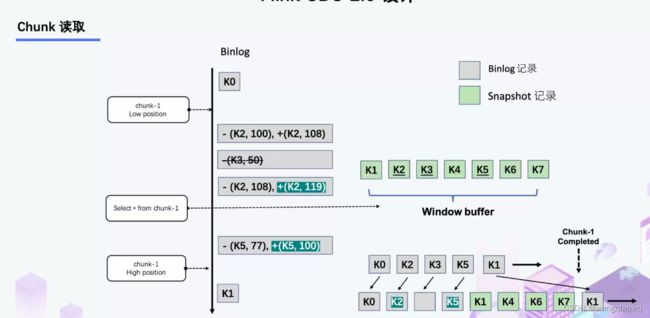
比如正在读取 Chunk-1,Chunk 的区间是 [K1, K10],首先直接将该区间内的数据 select 出来并把它存在 buffer 中,在 select 之前记录 binlog 的一个位点 (低位点),select 完成后记录 binlog 的一个位点 (高位点)。然后开始增量部分,消费从低位点到高位点的 binlog。
- 图中的 - ( k2,100 ) + ( k2,108 ) 记录表示这条数据的值从 100 更新到 108;
- 第二条记录是删除 k3;
- 第三条记录是更新 k2 为 119;
- 第四条记录是 k5 的数据由原来的 77 变更为 100。
观察图片中右下角最终的输出,会发现在消费该 chunk 的 binlog 时,出现的 key 是k2、k3、k5,我们前往 buffer 将这些 key 做标记。
- 对于 k1、k4、k6、k7 来说,在高位点读取完毕之后,这些记录没有变化过,所以这些数据是可以直接输出的;
- 对于改变过的数据,则需要将增量的数据合并到全量的数据中,只保留合并后的最终数据。例如,k2 最终的结果是 119 ,那么只需要输出 +(k2,119),而不需要中间发生过改变的数据。
通过这种方式,Chunk 最终的输出就是在高位点是 chunk 中最新的数据。
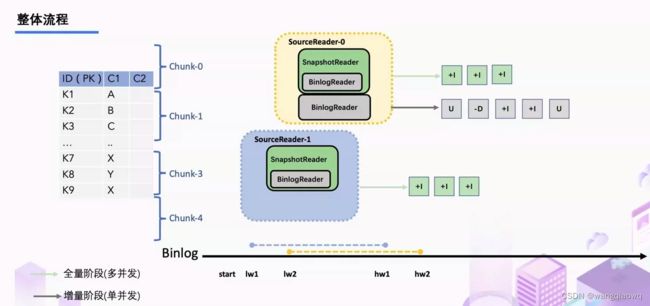
上图描述的是单个 Chunk 的一致性读,但是如果有多个表分了很多不同的 Chunk,且这些 Chunk 分发到了不同的 task 中,那么如何分发 Chunk 并保证全局一致性读呢?
有 SourceEnumerator 的组件,这个组件主要用于 Chunk 的划分,划分好的 Chunk 会提供给下游的 SourceReader 去读取,通过把 chunk 分发给不同的 SourceReader 便实现了并发读取 Snapshot Chunk 的过程,同时基于 FLIP-27 我们能较为方便地做到 chunk 粒度的 checkpoint。

当 Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。

汇报的主要目的是为了后续分发 binlog chunk (如下图)。因为 Flink CDC 支持全量 + 增量同步,所以当所有 Snapshot Chunk 读取完成之后,还需要消费增量的 binlog,这是通过下发一个 binlog chunk 给任意一个 Source Reader 进行单并发读取实现的。
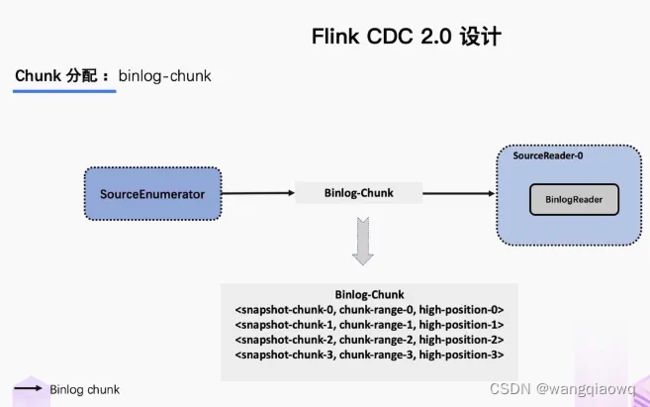
整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有 Snapshot Chunk 读取完成后,下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程,如下图所示:
MySQL CDC 2.0,核心feature 包括
- 并发读取,全量数据的读取性能可以水平扩展;
- 全程无锁,不对线上业务产生锁的风险;
- 断点续传,支持全量阶段的 checkpoint。
SQL server CDC
CDC实现的原理:
① 数据源:监控的源表所有操作都会进入日志。日志为变更表提供数据源,作为捕获进程的输入来源。
② 捕获进程:扫描日志并将列数据以及与事务有关的信息写入变更数据捕获更改表中。
③ 捕获进程将在每个扫描周期内打开并提交其自己的事务。它检测何时为表新启用了变更数据捕获,并自动将这些表加入到当前在日志中监视更改项的表集中。 同样,它还会检测禁用的变更数据捕获,进而从当前监视更改数据的表集中删除源表。 在处理完日志的某个部分后,捕获进程将通知服务器日志截断逻辑,后者使用此信息来确定适合截断的日志项,所以采用完整备份和简单备份日志方式对CDC捕获不会产生影响。
SQL Server CDC 长什么样?
原始日志
常见的数据库往往存在以下两种日志
- redo 日志
- 记录数据的正向变更,简单来说,事务的 commit 通常先记录在这个文件,再返回应用程序成功,可确保数据 持久性
- undo 日志
- 用于保证事务的 原子性,如执行 rollback 命令即反向执行 undo 日志中内容以达成数据回滚
一条 DML 语句写入数据库流程如下

- 大部分关系型数据库中,一个或多个变更会被隐式或显式包装成一个事务
- 事务开始,数据库引擎定位到数据行所在的 文件位置 并根据已有的数据生成 前镜像 和 后镜像
- 后镜像 数据记录到 redo 日志中,前镜像 数据记录到 undo 日志中
- 事务提交后,日志提交位点(检查点)向前推进,已提交的日志内容即可能被覆盖或者释放
SQL Server redo/undo 日志采用了 ldf 格式 ,文件循环使用。
- ldf 日志文件由多个 VLF(逻辑日志) 组合在一起,这些 VLF 首尾相连形成完整的数据库日志记录
- ldf 在逻辑日志末端到达物理日志文件末端时,新的日志记录将回到物理日志文件开始,复写旧的数据
ldf 文件即 CDC 所分析的增量日志文件。
- cdc.console_capture
- 负责分析 ldf 日志 并解析 console 数据库事件,再将其写入到 CDC 表中
- 间隔 5 秒钟执行一次扫描,每次扫描 10 轮,每轮扫描最多 500 个事务
- cdc.console_cleanup
- 负责定期清理 CDC 表中较老的数据
- 默认保留 3 天 CDC 日志数据(4320秒)
开启 CDC 功能后,SQL Server 数据库会多出一个名称为 cdc 的 schema,里面会多出下列这些表。
- change_tables
- 记录每一个启用了 CDC 的 源表 及其对应的 捕获表
- captured_columns
- 记录对应 捕获表 中每个列的信息
- index_columns
- 记录 源表 含有的主键信息(如果有)
- lsn_time_mapping
- 记录每个事务的开始/结束时间及 LSN 位置信息
- ddl_history
- 记录源表发生的 增/减列 对应的 DDL 信息,除此之外的 DDL 都不会被记录
有了上述准备动作和信息,即可开始对原始表开启 change data capture(CDC),即增量数据捕获了。
+I 表示新增、-U 表示记录更新前的值、+U 表示记录更新后的值,-D 表示删除