【python笔记】小甲鱼
P3
查看内置函数
dir(__builtins__)P4
变量名命名规则:
1、变量名不能以数字打头;
2、变量名可以是中文
字符串可以是:
1、单引号:文本中存在双引号时使用单引号
2、双引号:文本中存在单引号时使用双引号
当文本中既有单引号又有双引号时使用转义字符。
P5
原始字符串:在字符串前加 r ,转义字符将不再有效
>>> print("D:\three\two\one\now")
D: hree wo\one
ow
>>> print(r"D:\three\two\one\now")
D:\three\two\one\now反斜杠不能放在字符串的末尾,若某行的末尾是反斜杠,则说明字符串还没有结束。反斜杠可以让字符串跨行。
三引号:分为三单引号或三双引号,前后要对应,可以实现字符串的跨行而不需要行末的反斜杠。
字符串的加法和乘法:
1、加法:拼接
2、乘法:复制
P6
字符串的输入input方法:输入的是字符串,如需要数字则需要强转一下。
>>> temp=input("你是谁?")
你是谁?我是你霸霸
>>> temp
'我是你霸霸'
>>> num=input("请输入一个数字")
请输入一个数字8
>>> num
'8'
>>> NUM=int(num)
>>> NUM
8P7
if...else...语句:
a = 1
if a < 3:
print("a is small")
else:
print('a is big')
a = 5
if a < 3:
print("a is small")
else:
print('a is big')a is small
a is bigwhile循环:
counts = 3
while counts > 0:
print("I love HZQ")
counts = counts - 1I love HZQ
I love HZQ
I love HZQ
break语句:
跳出一层循环体。
P8
random模块
1、random.randint(a,b)函数,返回一个a~b的伪随机数;
2、random.getstate()函数,返回随机数种子
3、random.setstate(x)函数,设置随机数种子,
随机数种子相同时,生成的伪随机数顺序相同。
P9
1、python可以随时随地进行大数的计算。
2、python存储浮点数存在误差,浮点数并不是百分之百精确的,
>>> 0.1+0.2
0.30000000000000004
>>> i=0
>>> while i<1:
... i=i+0.1
... print(i)
...
0.1
0.2
0.30000000000000004
0.4
0.5
0.6
0.7
0.7999999999999999
0.8999999999999999
0.9999999999999999
1.09999999999999993、python要想精确地计算浮点数,需要 decimal 模块。
>>> import decimal
>>> a=decimal.Decimal('0.1')
>>> b=decimal.Decimal('0.2')
>>> print(a+b)
0.3
>>> c=decimal.Decimal('0.3')
>>> c==a+b
True4、科学计数法
>>> 0.0000000000005
5e-13
>>> 0.00000000004003002050403
4.003002050403e-115、复数
复数的实部和虚部都是浮点数的形式存储的
>>> a=1-2j
>>> a
(1-2j)
>>> a.real
1.0
>>> a.imagP10
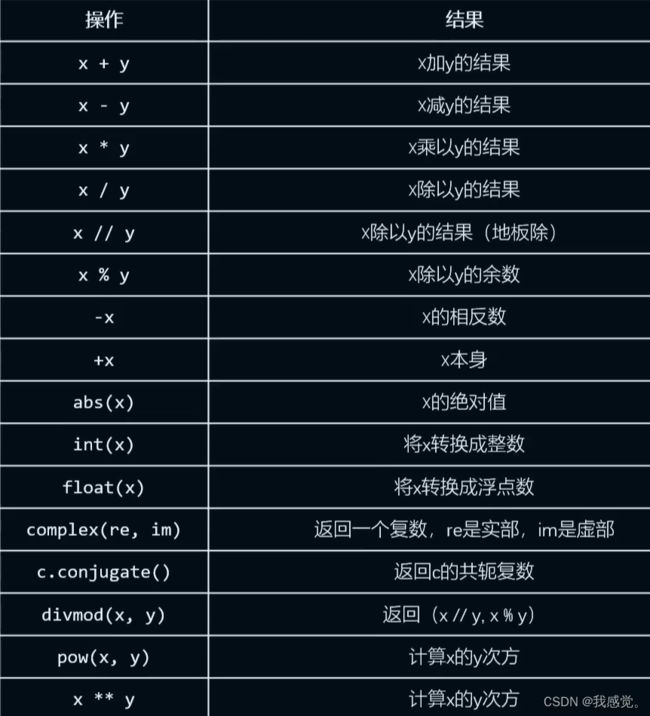
1,x//y,地板除,结果向下取整。
2,abs(x),返回x的绝对值,x为复数时返回模值。
3,complex(a,b)函数,括号中可以是两个数字表示实部和虚部,也可以是复数对应的字符串。
>>> complex(1,3)
(1+3j)
>>> complex('3+8j')
(3+8j)P11
1,布尔值为False的情况:

2,
and和or都是短路逻辑,下方代码中几种情况需要记住。
>>> 3 and 4
4
>>> 3 or 4
3
>>> "HZQ" and "LOVE"
'LOVE'
>>> '''HZQ''' and """LOVE"""
'LOVE'
>>> '''HZQ''' or """LOVE"""
'HZQ'P12
1,运算符优先级

P13
流程图
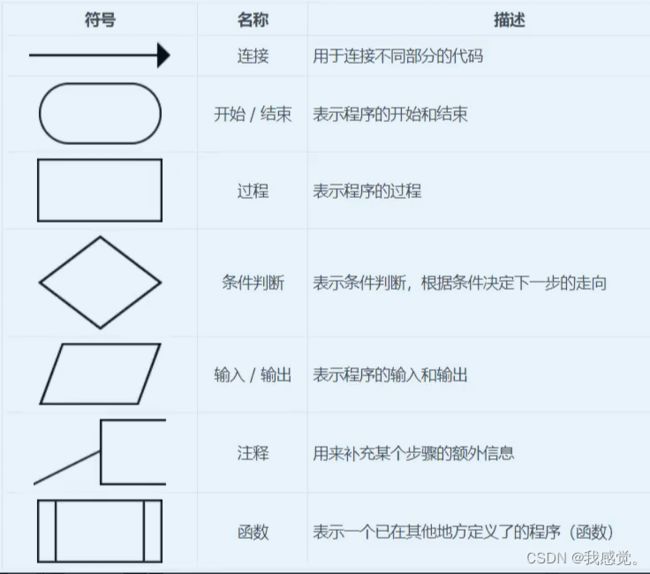
P14
P15、P16
1,基本结构:if.... elif.... else....
2,条件表达式:
score = 76
level = ("D" if 0 <= score < 60 else
"C" if 60 <= score < 70 else
"B" if 70 <= score < 80 else
"A" if 80 <= score < 100 else
"S" if score == 100 else
print("请输入0~100之间的数字"))
print(level)
运行结果:BP17
P18
1,continue,结束本轮循环,开始下一轮循环
2,while...else...语句:while后的条件不成立时,执行一次else后的操作
P19
1,for循环:
for 变量 in 可迭代对象 :
statement(s)>>> for each in "FishC":
... print(each)
...
F
i
s
h
C
>>> each
'C'1000不是可迭代对象,故以下代码报错
>>> for each in 1000 :
... print(each)
...
Traceback (most recent call last):
File "", line 1, in
TypeError: 'int' object is not iterable 2,range()函数,用于生成数字序列,将数字变为可迭代对象,形式如下:
range(stop)
range(start,stop)
range(start,stop,step)
生成的序列包括start,不包括stop
>>> for i in range(10):
... print(i)
...
0
1
2
3
4
5
6
7
8
9
>>> for i in range(8,17,2):
... print(i)
...
8
10
12
14
16P20
列表索引,列表切片
P21
1,append()方法:列表添加一个元素
>>> a=[1,2,3]
>>> a
[1, 2, 3]
>>> a.append('q')
>>> a
[1, 2, 3, 'q']2,extend()方法:列表添加一个可迭代对象
>>> a
[1, 2, 3, 'q']
>>> a.extend([5,56,'gf'])
>>> a
[1, 2, 3, 'q', 5, 56, 'gf']3,切片添加元素
>>> a=[1,2,3,4,5]
>>> a[len(a):]=[6]
>>> a
[1, 2, 3, 4, 5, 6]
>>> a[len(a):]=['qq',2,"ed"]
>>> a
[1, 2, 3, 4, 5, 6, 'qq', 2, 'ed']4,insert()方法, 指定位置插入元素
>>> a=[1,3,4,5]
>>> a.insert(1,2)
>>> a
[1, 2, 3, 4, 5]
>>> a.insert(0,0)
>>> a
[0, 1, 2, 3, 4, 5]
>>> a.insert(len(a),6)
>>> a
[0, 1, 2, 3, 4, 5, 6]5,remove()方法,删除列表元素,若有多个待删除元素,未指定时删除下标最小的一个。
>>> a=[1,2,3,4,5]
>>> a.remove(3)
>>> a
[1, 2, 4, 5]
>>> a=[1,2,4,3,4,4,5,6,7]
>>> a.remove(4)
>>> a
[1, 2, 3, 4, 4, 5, 6, 7]6,pop()方法,通过下标删除元素,同时返回删除的元素
>>> a
[1, 2, 3, 4, 4, 5, 6, 7]
>>> a.pop(3)
4
>>> a
[1, 2, 3, 4, 5, 6, 7]
>>> a.pop(5)
6
>>> a
[1, 2, 3, 4, 5, 7]7,clear(),清空列表
>>> a
[1, 2, 3, 4, 5, 7]
>>> a.clear()
>>> a
[]P22
1,s.sort(key=None,reverse=False)方法,对列表中的元素进行原地排序(key 参数用于指定一个用于比较的函数;reverse 参数用于指定排序结果是否反转)
2,reverse()方法,纯数字列表从大到小排序
3,count(a),返回元素出现的次数
4,index(a,start,end),返回元素的索引
5,copy(),拷贝列表
6,切片和copy都是浅拷贝,
*P23
1,对于嵌套列表,用乘法进行拷贝时,内存中开辟的空间是同一个;
判断是否在内存中开辟空间是同一个用 is 关键词
列表元素用*复制,指向同一内存空间,用*复制后在分别赋值,则指向不同空间;
>>> A=[0]*3
>>> for i in range(3):
... A[i]=[0]*2
...
>>> A
[[0, 0], [0, 0], [0, 0]]
>>> B=[[0]*2]*3
>>> B
[[0, 0], [0, 0], [0, 0]]
>>> A[1][1]=1
>>> B[1][1]=1
>>> A
[[0, 0], [0, 1], [0, 0]]
>>> B
[[0, 1], [0, 1], [0, 1]]2,两个相同的字符串分别赋值,即使不是用*复制的,内存空间也是指向同一个,因为字符串和列表不同,字符串是不可变的。
>>> a=[1,2,3]
>>> b=[1,2,3]
>>> a is b
False
>>> c="WAHZQ"
>>> d='WAHZQ'
>>> c is d
TrueP24
1,等号赋值单个变量,只是让两个变量地址相同,改变一个变量时,这个变量的地址将会改变,两个变量地址将不相同。
>>> a=2
>>> b=a
>>> a is b
True
>>> a=3
>>> b
2
>>> a is b
False等号赋值列表,是让两个变量列表地址相同,当改变其中一个列表的某一元素时,另一个列表中对应元素也改变。当对整个列表赋值时,这个列表的地址将会改变。
>>> a=[1,2,3,'qwe']
>>> b=a
>>> b is a
True
>>> b
[1, 2, 3, 'qwe']
>>> a[1]=5
>>> b
[1, 5, 3, 'qwe']
>>> b=[1,5,3,'qwe']
>>> b is a
False2,copy()方法,切片
copy()方法和切片不仅拷贝列表的引用,拷贝的是整个列表,拷贝后的列表与被拷贝的列表的地址不同,改变一个元素,另一个列表中对应元素的值不变。
>>> a=[1,2,3]
>>> b=a.copy()
>>> b
[1, 2, 3]
>>> a[1]=5
>>> b
[1, 2, 3]
>>> a is b
False
>>> c=a[:]
>>> a[0]=8
>>> c
[1, 5, 3]
>>> a is c
False3,深拷贝
copy()方法和切片可以拷贝一维列表,当二维列表时,将不能完成内层的拷贝。
>>> a=[[1,2,3],[4,5,6],[7,8,9]]
>>> b=a.copy()
>>> b
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> a[1][1]=0
>>> a
[[1, 2, 3], [4, 0, 6], [7, 8, 9]]
>>> b
[[1, 2, 3], [4, 0, 6], [7, 8, 9]]这时候就需要用到深拷贝了,即copy模块中的deepcopy()函数,copy模块中的copy()函数也是浅拷贝,但是浅拷贝的效率更高,速度快。
>>> import copy
>>> a=[[1,2,3],[4,5,6],[7,8,9]]
>>> b=copy.copy(a)
>>> b
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> a[1][1]=0
>>> b
[[1, 2, 3], [4, 0, 6], [7, 8, 9]]
>>> c=copy.deepcopy(a)
>>> a[1][0]=0
>>> a
[[1, 2, 3], [0, 0, 6], [7, 8, 9]]
>>> c
[[1, 2, 3], [4, 0, 6], [7, 8, 9]]is()方法验证:
>>> import copy
>>> a=[[1,2,3],[4,5,6],[7,8,9]]
>>> b=copy.copy(a)
>>> c=copy.deepcopy(a)
>>> d=a
>>> a is b
False
>>> a is c
False
>>> a is d
True
>>> a[1] is b[1]
True
>>> a[1] is c[1]
False
>>> a[1][1] is b[1][1]
True
>>> a[1][1] is c[1][1]
True故拷贝能力强弱顺序为:
(=赋值) < (copy方法、切片操作、copy模块中的copy函数) < (copy模块中的deepcopy函数)
对于深层拷贝,再多一层还是可以完美拷贝:
>>> a=[[[11,13,14],2,3],[4,5,6],[7,8,9]]
>>> e=copy.deepcopy(a)
>>> e
[[[11, 13, 14], 2, 3], [4, 5, 6], [7, 8, 9]]
>>> a[0][0][0]=22
>>> a
[[[22, 13, 14], 2, 3], [4, 5, 6], [7, 8, 9]]
>>> e
[[[11, 13, 14], 2, 3], [4, 5, 6], [7, 8, 9]]P25
ord()函数:将字符转换为Unicode编码
列表推导式
>>> oho=[1,2,3,4,5]
>>> x=[i*2 for i in oho]
>>> x
[2, 4, 6, 8, 10]
>>> y=[i+1 for i in range(10)]
>>> y
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]P26
1,列表推导式创建二维列表
>>> a=[[0]*3 for i in range(3)]
>>> a
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> a[1][1]=2
>>> a
[[0, 0, 0], [0, 2, 0], [0, 0, 0]]
>>> b=[[0]*3]*3
>>> b
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> b[1][1]=2
>>> b
[[0, 2, 0], [0, 2, 0], [0, 2, 0]]列表推导式后还可加 if 条件限制:
>>> y=[i+1 for i in range(10) if i%2==0]
>>> y
[1, 3, 5, 7, 9]这个列表推导式的运行顺序是:
(1)for i in range(10)
(2)if i%2==0
(3)i+1
2,嵌套的列表推导式
根据列表推导式的运行顺序可推出嵌套列表推导式
>>> a=[[1,2,3],[4,5,6],[7,8,9]]
>>> b=[i*2 for j in a for i in j]
>>> b
[2, 4, 6, 8, 10, 12, 14, 16, 18]P27
1,元组:元素不可变,元组用的是圆括号。元组也可以省略括号,用逗号隔开就可以。
2,元组支持切片,
3,列表中有增删改查,到元组就只有了查,即count()和index()方法
4,没有元组推导式
5,生成只有一个元素的元组:需要有逗号
>>> a=(520)
>>> type(a)
>>> b=(520,)
>>> type(b)
6,元组的打包和解包,字符串、列表也可以打包和解包。
>>> x=1
>>> y=2
>>> z=3
>>> t=(x,y,z)
>>> t
(1, 2, 3)
>>> (a,b,c)=t
>>> a
1
>>> b
2
>>> c
3
>>> a,b,c,d='hjdk'
>>> a
'h'
>>> c
'd'解包时等号左侧的变量数个右侧元素数需相等,不相等时报错,可以在最后一个变量上加*来解决。
>>> a,b,c="ahjjdk"
Traceback (most recent call last):
File "", line 1, in
ValueError: too many values to unpack (expected 3)
>>> a,b,*c="ahjjdk"
>>> a
'a'
>>> b
'h'
>>> c
['j', 'j', 'd', 'k'] 7,元组元素不可变,当元组中的元素指向一个可以修改的列表时,这个元组元素列表中的元素可以改变
>>> s=[1,2,3]
>>> t=[5,6,7]
>>> w=(s,t)
>>> w
([1, 2, 3], [5, 6, 7])
>>> w[0][1]=10
>>> w
([1, 10, 3], [5, 6, 7])P28、P29、P30、P31
1,判断字符串是否是回文字符串:
>>> x='12321'
>>> "是回文数" if x==x[::-1] else "不是回文数"
'是回文数'
>>> x='12345'
>>> "是回文数" if x==x[::-1] else "不是回文数"
'不是回文数'2,字符串相关的众多方法:
(1)~(6)主要是大小写字母的变换。
(1)capitalize():返回首字母大写,其他字母小写的字符串
>>> x="I love Hzq"
>>> x.capitalize()
'I love hzq'(2)casefold():返回所有字符都是小写的字符串
>>> x="I love Hzq"
>>> x.casefold()
'i love hzq(3)title():返回每个单词的首字母都变成大写,剩下的字母变成小写
>>> x="I love Hzq"
>>> x.title()
'I Love Hzq'(4)swapcase():所有字母大小写反转
>>> x="I love Hzq"
>>> x.swapcase()
'i LOVE hZQ'(5)upper():全部大写
(6)lower():全部小写,只能处理英语,casefold()不仅英语,还可以其他语言
(7)~(10)左中右对齐
(7)center(width , fillchar = ''):width如果比原字符串小,则直接原字符串输出,如果比原字符串大,则宽度保持width,不足的部分用空格填充,字符串居中;不设置fillchar时默认空格填充,设置后以设置的fillchar填充。
(8)ljust(width , fillchar = ''):左对齐,其余同上
(9)rjust(width , fillchar = ''):右对齐,其余同上
(10)zfill(width):字符串靠右,0填充左侧;也适合负数情况,负数时,负号会被移到最左侧。
>>> x="I love Hzq"
>>> x.center(15)
' I love Hzq '
>>> x.center(15,'_')
'___I love Hzq__'
>>> x.ljust(16)
'I love Hzq '
>>> x.rjust(16)
' I love Hzq'
>>> x.zfill(16)
'000000I love Hzq'(11)~(15)查找
(11)count(x,start,end):包括索引为star的元素,不包括索引为end的元素
(12)find(x,start,end):从左往右找,返回第一个找的的元素的索引,找不到的话返回-1
(13)rfind(x,start,end):从右往左找,返回第一个找的的元素的索引,找不到的话返回-1
(14)index(x,start,end):和find()类似,找不到不到字符串时,报错
(15)rindex(x,start,end):和rfind()类似,找不到不到字符串时,报错
(16)~(18)替换
(16)expandtabs([tabsize=8]):将字符串中的tab替换为空格,返回字符串,参数代表一个tab代表多少个空格

(17)replace(old,new,count=-1):将字符串中的old替换为new,count为替换的个数,默认为全部。
>>> a="yuuiijhgfb"
>>> a.replace('u','U')
'yUUiijhgfb'
>>> a.replace('u','U',5)
'yUUiijhgfb'(18)translate(table):table代表的是一个映射关系,即将原字符串按照table进行映射,并返回映射后的字符串。
>>> a="I love Hzq"
>>> table=str.maketrans("abcdefg","1234567")
>>> a.translate(table)
'I lov5 Hzq'
// str.maketrans("abcdefg","1234567") 表示创建一个映射关系,
//该函数还支持第三个参数 str.maketrans("abcdefg","1234567","str"),表示将 str 忽略掉(删掉)。(19)~(33)表示对字符串的判断
(19)startswith(x,start,end):判断指定字符串是否在待判断字符串的起始位置,x可以是一个元组,将多个待匹配的字符串写进去,若有一个匹配成功,即返回True
(20)endswith(x,start,end):判断指定字符串是否在待判断字符串的结束位置,x可以是一个元组,将多个待匹配的字符串写进去,若有一个匹配成功,即返回True
>>> a="我爱python"
>>> a.startswith(('我','你','她'))
True(21)isupper():全大写字母,返回True
(22)islower():全小写字母,返回True
(23)istitle():所有单词以大写字母开头,其余小写,返回True
(24)isalpha():判断是否全以字母构成
(25)isascii():
(26)isspace():判断是否是空白字符串,空白包括:空格、Tab、\n、
>>> ' \n'.isspace()
True(27)isprintable():判断字符串是否是可打印的,其中 转义字符、空格 不是可打印字符
>>> ' \n'.isprintable()
False
>>> ' '.isprintable()
False
>>> ' love '.isprintable()
False
>>> 'love'.isprintable()
True(28)isdecimal():判断数字,能力最弱
(29)isdigit(): 判断数字,能力居中,可判断( )
)
(30)isnumeric():判断数字,能力最强,可判断(ⅠⅡⅢ...和一二三...)
(31)isalnum(): 判断数字,能力第一,上述三个一个为True,这个就为True
(32)isidentifier():判断字符串是否是python的合法标识符(空格不合法,下划线合法;数字开头的字符串不合法)
>>> 'I love'.isidentifier()
False
>>> 'I_love'.isidentifier()
True
>>> 'love520'.isidentifier()
True
>>> '520love'.isidentifier()
False(33)keyword模块中的iskeyword(str)函数:判断是否是关键字
>>> import keyword
>>> keyword.iskeyword('if')
True
>>> keyword.iskeyword('py')
False(34)~(38)字符串截取
(34)strip(char=None):删掉字符串左边和右边的指定字符,默认为空格
(35)lstrip(char=None):删掉字符串左边的指定字符,默认为空格
(36)rstrip(char=None):删掉字符串右边的指定字符,默认为空格
>>> ' I love '.lstrip()
'I love '
>>> ' I love '.rstrip()
' I love'
>>> 'www.Iloveyou.com'.lstrip('w.I')
'loveyou.com'
>>> 'www.Iloveyou.com'.rstrip('.mo')
'www.Iloveyou.c'
>>> 'www.Iloveyou.com '.rstrip(' .mo')
'www.Iloveyou.c'
>>> 'www.Iloveyou.com '.rstrip('.mo')
'www.Iloveyou.com '(37)removeprefix(prefix):删除前缀(整体)
(38)removesuffix(suffix):删除后缀(整体)
>>> 'www.Iloveyou.com'.removeprefix('www.')
'Iloveyou.com'
>>> 'www.Iloveyou.com'.removesuffix('.com')
'www.Iloveyou'
>>> 'www.Iloveyou.com '.removesuffix('.com')//原字符串在.com后加了一个空格
'www.Iloveyou.com '(39)~()字符串拆分、拼接
(39)partition(sep):从左到右找一个sep字符串,以sep为界,返回元组('左'、'sep'、'右')
(40)rpartition(sep):从右到左找一个sep字符串,以sep为界,返回元组('左'、'sep'、'右')
>>> 'www.Iloveyou.com '.partition('.')
('www', '.', 'Iloveyou.com ')
>>> 'www.Iloveyou.com '.rpartition('.')
('www.Iloveyou', '.', 'com ')(41)split(sep=None,maxsplit=-1):从左到右找到maxsplit个sep,默认为全部,并以此分割成若干字符串元素的列表,分界处的sep删去
(42)rsplit(sep=None,maxsplit=-1):从右到左找到maxsplit个sep,默认为全部,并以此分割成若干字符串元素的列表,分界处的sep删去
(43)splitlines():以行进行分割,换行符可以是\n、\r、\r\n ,括号中写True时,换行符写进前一个元素中。
(44)join(iterable):字符串拼接,join拼接比加号拼接快,大量需要拼接时,join节省大量时间。
>>> '.'.join(['www','Iloveyou','com'])
'www.Iloveyou.com'
>>> '.'.join(('www','Iloveyou','com'))
'www.Iloveyou.com'P32、P33
1,格式化字符串format()函数
>>> "love you {} years".format(num) //位置索引
'love you 10000 years'
>>> '{}看到{}很激动'.format('我','你') //位置索引
'我看到你很激动'
>>> '{1}看到{0}很激动'.format('我','你') //位置索引
'你看到我很激动'
>>> '{1}看到{1}很激动'.format('我','你') //位置索引
'你看到你很激动'
>>> '{a}看到{b}很激动'.format(a='我',b='你') //关键字索引
'我看到你很激动'
>>> '{0}看到{b}很激动'.format('我',b='你') //关键字索引和位置索引杂交
'我看到你很激动'2,在字符串中显示花括号
>>> '{},{},{}'.format(1,'{}',2)
'1,{},2'
>>> '{},{{}},{}'.format(1,2)
'1,{},2'3,格式化字符串

>>> '{:^}'.format(250)
'250'
>>> '{:^10}'.format(250)
' 250 '
>>> '{1:>10}{0:<10}'.format(520,250)
' 250520 '
>>> '{left:>10}{right:<10}'.format(left=520,right=250)
' 520250 '
>>> '{:010}'.format(520)
'0000000520'
>>> '{:010}'.format(-520)
'-000000520'
>>> '{1:%>10}{0:%<10}'.format(520,250)
'%%%%%%%250520%%%%%%%'
>>> '{:0=10}'.format(520)
'0000000520'
>>> '{:0=10}'.format(-520)
'-000000520'
>>> '{:=10}'.format(-520)
'- 520'
>>> '{:+}{:-}'.format(520,-250)
'+520-250'
>>> '{:,}'.format(12345)
'12,345'
>>> '{:.2f}'.format(3.14159)
'3.14'
>>> '{:.2g}'.format(3.14159)
'3.1'
>>> '{:.6}'.format('I love you')
'I love'
>>> '{:b}'.format(80)
'1010000'
>>> '{:c}'.format(80)
'P'
>>> '{:d}'.format(80)
'80'
>>> '{:o}'.format(80)
'120'
>>> '{:x}'.format(80)
'50'
>>> '{:#b}'.format(80)
'0b1010000'
>>> '{:#c}'.format(80)
Traceback (most recent call last):
File "", line 1, in
ValueError: Alternate form (#) not allowed with integer format specifier 'c'
>>> '{:#d}'.format(80)
'80'
>>> '{:#o}'.format(80)
'0o120'
>>> '{:#x}'.format(80)
'0x50' 适用于浮点数、复数:
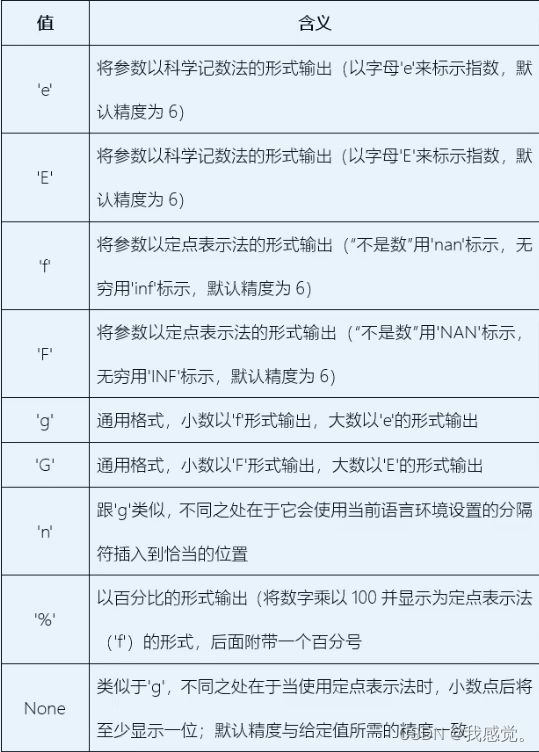
>>> '{:e}'.format(3.14159)
'3.141590e+00'
>>> '{:E}'.format(3.14159)
'3.141590E+00'
>>> '{:f}'.format(3.14159)
'3.141590'
>>> '{:g}'.format(123456789)
'1.23457e+08'
>>> '{:g}'.format(123.456789)
'123.457'
>>> '{:%}'.format(0.98)
'98.000000%'
>>> '{:.2%}'.format(0.98)
'98.00%'
>>> '{:.{prec}f}'.format(3.1415,prec=2)
'3.14'3,f-字符串:代替format()函数,python3.6以后的版本才能用
>>> F"I love you {num} year"
'I love you 10000 year'
>>> F"{-520:010}"
'-000000520'所有的格式化都可以用F-字符串代替format()函数
P34
1,列表是可变序列,元组和字符串是不可变序列。
2,id(x):返回x的id号,
3,每个对象都有三个特征:
(1)唯一标志:标签->id(x)函数获取
(2)类型
(3)值
4,
(1)对于列表,对其中元素赋值,不会改变其id,对整个列表赋值,会改变id。
例外:a*=2前后a的id相同。
>>> a=[1,2,3]
>>> id(a)
1905786440512
>>> a=[4,5,6]
>>> id(a)
1905786440768
>>> a[1]=[4,5,6]
>>> id(a)
1905786440768(2)对于元组,只能整体赋值,赋值后id就会改变
5, is、is not,同一性运算符,判断id是否相同。
>>> a=[1,2,3]
>>> b=[1,2,3]
>>> c=(1,2,3)
>>> d=(1,2,3)
>>> e='qwe'
>>> f='qwe'
>>> a is b
False
>>> c is d
False
>>> e is f
True6, in、not in,判断包含问题
>>> 'love' in 'I love you'
True
>>> 'e' in 'I love you'
True
>>> 'e' not in 'I love you'
False7,del,删除序列,也可以删除可变序列中的指定元素
>>> x=[1,2,3]
>>> del x
>>> x
Traceback (most recent call last):
File "", line 1, in
NameError: name 'x' is not defined
>>> y=[1,2,3]
>>> del y[1:]
>>> y
[1] P35
1,列表,元组,字符串相互转换的函数
(1)list()
(2)tuple()
(3)str()
>>> list('qwer')
['q', 'w', 'e', 'r']
>>> list((1,2,3))
[1, 2, 3]
>>> tuple([1,2,3])
(1, 2, 3)
>>> tuple('qwer')
('q', 'w', 'e', 'r')
>>> str([1,2,3,4,5])
'[1, 2, 3, 4, 5]'
>>> str((1,2,3,4,5,6))
'(1, 2, 3, 4, 5, 6)'2,求最大最小值函数
(1)min()
(2)max()
若是字符串,则判断每个元素的编码值。若待判断的序列为空,则抛出异常,可传入参数进行避免抛出异常。
>>> min([])
Traceback (most recent call last):
File "", line 1, in
ValueError: min() arg is an empty sequence
>>> min([],default='序列中什么有没有')
'序列中什么有没有' 3,len()和sum()
(1)len():参数有最大可承受范围((2**31-1)或(2**63-1))
(2)sum(x,[start=num]):可传入可选参数,从start开始加。
>>> len(range(10))
10
>>> sum([1,2,3,4,5])
15
>>> sum([1,2,3,4,5],start=100)4,sorted() 和 reversed()
(1)sorted():排序,可以有key函数,表示干预排序的函数 ;sort()方法只能排序列表,sorted()函数能传进去的参数可以是列表,元组和字符串,但返回结果都是列表。
>>> s=[1,2,3,0,6]
>>> sorted(s)
[0, 1, 2, 3, 6]
>>> sorted(s,reverse=True)
[6, 3, 2, 1, 0]
>>> t=['FishC','Banana','Book','Pen','Apple']
>>> sorted(t)
['Apple', 'Banana', 'Book', 'FishC', 'Pen']
>>> sorted(t,key=len)
['Pen', 'Book', 'FishC', 'Apple', 'Banana'](2)reversed():得到与输入序列反向的迭代器
s=[1,2,5,8,0]
>>> reversed(s)
>>> list(reversed(s))
[0, 8, 5, 2, 1]
>>> a=(1,2,5,8,0)
>>> list(reversed(a))
[0, 8, 5, 2, 1] P36
1,all()和any()
(1)all():判断可迭代对象中是否所有元素都为真
(2)any():判断可迭代对象中是否有为真的元素
2,enumerate()函数:用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从 0开始的序号共同构成一个二元组的列表;
>>> seasons=['Spring','Summer','Fall','Winter']
>>> enumerate(seasons)
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] 可以有start参数,用来自定义序号开始的值。
>>> list(enumerate(seasons,10))
[(10, 'Spring'), (11, 'Summer'), (12, 'Fall'), (13, 'Winter')]3,zip()
zip()函数用于创建一个聚合多个可迭代对象的迭代器。它会将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第i个元组包含来自每个参数的第i个元素。
>>> x=[1,2,3]
>>> y=[4,5,6]
>>> zip(x,y)
>>> list(zip(x,y))
[(1, 4), (2, 5), (3, 6)]
>>> z=[7,8,9]
>>> list(zip(x,y,z))
[(1, 4, 7), (2, 5, 8), (3, 6, 9)] 传入不同迭代对象长度不一致时:以最短的为准
>>> z=[7,8,9,10]
>>> list(zip(x,y,z))
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]*用itertools模块中的zip_longest()来代替zip()时:传入不同迭代对象长度不一致时,以最长的为准,短的补None
>>> import itertools
>>> zipped=itertools.zip_longest(x,y,z)
>>> list(zipped)
[(1, 4, 7), (2, 5, 8), (3, 6, 9), (None, None, 10)]4,map():第一个参数时函数,用于处理后面参数中的可迭代对象。
map()函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器。
>>> mapped=map(ord,'FishC') //ord()函数只需要一个参数
>>> list(mapped)
[70, 105, 115, 104, 67]
>>> mapped=map(pow,[2,3,10],[5,4,3]) //pow()函数需要两个参数
>>> list(mapped)
[32, 81, 1000]
>>> mapped=map(max,[1,2,3],[2,5,3],[9,1,5,4,3]) //参数长度不一致时,以短的为准
>>> list(mapped)
[9, 5, 5]5,filter()函数
filter()函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回。
>>> list(filter(str.islower,"Love Hzq"))
['o', 'v', 'e', 'z', 'q']6,迭代器和可迭代对象的关系
(1)一个迭代器一定是一个可迭代对象
(2)可迭代对象可以重复利用,迭代器是一次性的
>>> mapped=map(ord,"FishC")
>>> for each in mapped:
... print(each)
...
70
105
115
104
67
>>> list(mapped)
[]7,
(1) iter():传入可迭代对象,返回对应的迭代器
>>> x=[1,2,3,4,5]
>>> y=iter(x)
>>> type(x)
>>> type(y)
(2) next():逐个将迭代器中的元素提取出来
>>> next(y)
1
>>> next(y)
2
>>> next(y)
3
>>> next(y)
4
>>> next(y)
5
>>> next(y)
Traceback (most recent call last):
File "", line 1, in
StopIteration 传入第二个参数,可防止迭代器为空时next()报错,
>>> x=[1,2,3,4,5]
>>> y=iter(x)
>>> next(y,"没了")
1
>>> next(y,"没了")
2
>>> next(y,"没了")
3
>>> next(y,"没了")
4
>>> next(y,"没了")
5
>>> next(y,"没了")
'没了'P37
字典:python中唯一实现映射关系的内置类型。在python3.7及之前,字典中的元素是无序的,3.8之后有序。
P38、P39
1,
>>> y={'1':'one','2':'two','3':'three'}
>>> type(y)
>>> y['1'] //写字典的键,就可以得到字典的值
'one'
>>> y['4']='four' //对与字典中没有的键值对,可如此直接加入字典
>>> y
{'1': 'one', '2': 'two', '3': 'three', '4': 'four'} 2,创建字典的方法
>>> a={'1':'one','2':'two','3':'three'}
>>> b=dict(yi='one',er='two',san='three') //此方法键不加引号,键是数字时不能用此方法
>>> c=dict([('1','one'),('2','two'),('3','three')])
>>> d=dict({'1':'one','2':'two','3':'three'})
>>> e=dict({'1':'one','2':'two'},san='three')
>>> f=dict(zip(['1','2','3'],['one','two','three']))
>>> a
{'1': 'one', '2': 'two', '3': 'three'}
>>> b
{'yi': 'one', 'er': 'two', 'san': 'three'}
>>> c
{'1': 'one', '2': 'two', '3': 'three'}
>>> d
{'1': 'one', '2': 'two', '3': 'three'}
>>> e
{'1': 'one', '2': 'two', 'san': 'three'}
>>> f
{'1': 'one', '2': 'two', '3': 'three'}3,字典的增删改查方法
增:
(1)fromkeys(iterable[,value]):可以使用iterable参数指定的可迭代对象来创建一个新的字典,并将所有的值初始化为values参数指定的值。
>>> d=dict.fromkeys('Fish',25)
>>> d
{'F': 25, 'i': 25, 's': 25, 'h': 25}
>>> x=dict.fromkeys('Fish')
>>> x
{'F': None, 'i': None, 's': None, 'h': None}
>>> d['F']=30 //改字典中键的值
>>> d
{'F': 30, 'i': 25, 's': 25, 'h': 25}
>>> d['C']=40 //增加字典中的元素
>>> d
{'F': 30, 'i': 25, 's': 25, 'h': 25, 'C': 40}删:
(2)pop(key[,default]):删除字典中的键值对,返回的是键所对应的值,若字典中没有所传入的key,则抛出异常,添加参数可避免抛出异常。
>>> d
{'F': 30, 'i': 25, 's': 25, 'h': 25, 'C': 40}
>>> d.pop('s')
25
>>> d
{'F': 30, 'i': 25, 'h': 25, 'C': 40}
>>> d.pop('A')
Traceback (most recent call last):
File "", line 1, in
KeyError: 'A'
>>> d.pop('A','字典中没有该键')
'字典中没有该键' (3)popitem():python3.7之前为随机删除一个键值对,python3.8及之后为删除最后加入的一个键值对。返回删除的键值对。
>>> d
{'F': 30, 'i': 25, 'h': 25, 'C': 40}
>>> d.popitem()
('C', 40)
>>> d
{'F': 30, 'i': 25, 'h': 25}(4)del :删除字典中的键值对或整个字典。
>>> d
{'F': 30, 'i': 25, 'h': 25}
>>> del d['h']
>>> d
{'F': 30, 'i': 25}
>>> del d
>>> d
Traceback (most recent call last):
File "", line 1, in
NameError: name 'd' is not defined (5)clear():清空字典
>>> d=dict.fromkeys('Fish',25)
>>> d
{'F': 25, 'i': 25, 's': 25, 'h': 25}
>>> d.clear()
>>> d
{}改:
(6)update():修改字典中的某些键值
>>> d=dict.fromkeys('Fish',25)
>>> d
{'F': 25, 'i': 25, 's': 25, 'h': 25}
>>> d.update({'i':'103','h':'104'})
>>> d
{'F': 25, 'i': '103', 's': 25, 'h': '104'}
>>> d.update(F='201',s='302')
>>> d
{'F': '201', 'i': '103', 's': '302', 'h': '104'}查:
(7)get(key[,default]):当传入的键字典中没有时,没加default参数时无返回值,字典不改变,有default参数时打印default
>>> d=dict.fromkeys('Fish',25)
>>> d
{'F': 25, 'i': 25, 's': 25, 'h': 25}
>>> d['F']
25
>>> d['f']
Traceback (most recent call last):
File "", line 1, in
KeyError: 'f'
>>> d.get('F')
25
>>> d.get('a')
>>> d.get('a','字典中没有这个键')
'字典中没有这个键' (8)setdefault(key[,default]):若输入键值字典中有,则返回键对应的值,若输入键字典中没有,则添加此键和(值default或None)组成的键值对。
>>> d=dict.fromkeys('Fish',25)
>>> d
{'F': 25, 'i': 25, 's': 25, 'h': 25}
>>> d.setdefault('F',38)
25
>>> d.setdefault('f',38)
38
>>> d
{'F': 25, 'i': 25, 's': 25, 'h': 25, 'f': 38}
>>> d.setdefault('g')
>>> d
{'F': 25, 'i': 25, 's': 25, 'h': 25, 'f': 38, 'g': None}(9)items():获取字典的键值对的的视图对象(视图对象:随字典的变化实时变化)
(10)keys():获取字典的键的视图对象
(11)values():获取字典的值的视图对象
>>> d=dict.fromkeys('Fish',25)
>>> a=d.items()
>>> b=d.keys()
>>> c=d.values()
>>> a
dict_items([('F', 25), ('i', 25), ('s', 25), ('h', 25)])
>>> b
dict_keys(['F', 'i', 's', 'h'])
>>> c
dict_values([25, 25, 25, 25])
>>> d['f']=38
>>> a
dict_items([('F', 25), ('i', 25), ('s', 25), ('h', 25), ('f', 38)])
>>> b
dict_keys(['F', 'i', 's', 'h', 'f'])
>>> c
dict_values([25, 25, 25, 25, 38])(12)copy()方法,实现浅拷贝
(13)len(x)方法,获取键值对的数量
(14)in、not in :判断键是否在字典中
(15)list(x):字典键转化为列表,
(16)list(x.values):字典值转化为列表
(17)iter(x):返回字典的键转化为的迭代器
(18)
字典与字典的嵌套、字典与列表的嵌套
>>> d={'吕布':{'语文':60,'数学':70,'英语':80},'关羽':{'语文':80,'数学':90,'英语':70}}
>>> d['吕布']['语文']
60
>>> d={'吕布':[60,70,80],'关羽':[80,90,70]}
>>> d['吕布'][1]
70(19)字典推导式
>>> d={'F':70,'i':105,'s':115,'h':104,'C':67}
>>> b={v:k for k,v in d.items()} //交换键值位置
>>> b
{70: 'F', 105: 'i', 115: 's', 104: 'h', 67: 'C'}
>>> b={v:k for k,v in d.items() if v>100} //带条件筛选
>>> b
{105: 'i', 115: 's', 104: 'h'}
>>> d={x:ord(x) for x in 'FishC'} //求字符编码
>>> d
{'F': 70, 'i': 105, 's': 115, 'h': 104, 'C': 67}
>>> d={x:y for x in [1,3,5] for y in [2,4,6]} //嵌套的字典推导式
>>> d
{1: 6, 3: 6, 5: 6}P40
集合是无序的;集合(set)
集合中每个元素都是唯一的,可以实现去重的效果;
集合无序,不能用下标索引,可以用 in、not in 判断元素是否在集合中;
集合是可迭代的对象。
1,集合推导式
>>> {s for s in 'FishC'}
{'C', 'F', 's', 'h', 'i'}2,集合中的方法,既适用于set()创建的可变集合,又适用于frozenset()创建的不可变集合。因为以下方法并不对原集合做改变,而是返回一个新的集合

(1)copy()方法,浅拷贝
(2)isdisjoint(other):判断集合是否有交集
>>> s=set('FishC')
>>> s
{'C', 'F', 's', 'h', 'i'}
>>> s.isdisjoint(set('Python'))
False
>>> s.isdisjoint(set('JAVA'))
True
>>> s.isdisjoint('JAVA') //可以不加set()转化函数
True
>>> s.isdisjoint('Python') //可以不加set()转化函数(3)issubset(other):判断是否是other的子集
>>> s
{'C', 'F', 's', 'h', 'i'}
>>> s.issubset('FishC.com.cn')
True(4)issuperset():判断是否是other的超集
>>> s
{'C', 'F', 's', 'h', 'i'}
>>> s.issuperset('Fi')
True(5)union(other1[,other2...]):求并集,(可以多参数)
>>> s
{'C', 'F', 's', 'h', 'i'}
>>> s.union('1,2,3')
{'C', '2', 's', '3', ',', 'i', 'F', 'h', '1'}(6)intersection(other1[,other2...]):求交集,(可以多参数)
>>> s
{'C', 'F', 's', 'h', 'i'}
>>> s.intersection('1,2,3ihk')
{'i', 'h'}(7)difference(other1[,other2...]):求差集,即存在于当前集合但不存在于other的元素,(可以多参数)
>>> s
{'C', 'F', 's', 'h', 'i'}
>>> s.difference('1,2,3ihk')
{'C', 'F', 's'}(8)symmetric_difference(other):求对称差集,排除当前集合和other集合中共有的元素之后剩余的所有元素。(不能多参数,只支持一个参数)
>>> s
{'C', 'F', 's', 'h', 'i'}
>>> s.symmetric_difference('1,2,3ihk')
{'C', '2', 'F', 's', '3', '1', 'k', ','}(9)集合的运算可以直接用符号,符号两边必须都是集合形式(上面的用方法运算右侧可以是任何可迭代对象): 子集(<=),真子集(<),超级(>=),真超集(>);并集(|)、交集(&)、差集(-)、对称差集(^)
P41
set()创建的集合可变;frozenset()创建的集合不可变
1,只适用于set()的方法,直接更改原集合中的内容:
(1)update(*others):向原集合中添加others,
(2)intersection_update(*others):将原集合更新为原集合与other的交集
(3)difference_update(*others):将原集合更新为原籍和与others的差集
(4)symmetric_difference_update(*others):将原集合更新为原集合与others的对称差集
(5)add()方法,用update向集合中添加字符串时,是将字符串的每个元素分开添加的,而add是整个字符串作为一个元素添加的。
(6)remove():删除集合中的元素,若没有在集合中找到元素,抛出异常
(7)discard():删除集合中的元素,若没有在集合中找到元素,抛出静默处理
(8)pop():随机弹出一个元素
(9)clear():清空集合
2,
(1)可哈希:不可变的对象是可哈希的,如字符串,元组
不可哈希:可变的对象是不可哈希的,
只有可哈希的对象才能作为字典的键;只有可哈希的对象才能作为集合中的元素。
(2)set()集合不可以嵌套,因为set()集合是可变的,可变的对象不能作为集合的元素。
frozenset()集合可以嵌套
P42
函数
1,基本形式
>>> def my_function():
... for i in range(3):
... print('I love Hzq')
...
>>> my_function()
I love Hzq
I love Hzq
I love Hzq2,带一个参数的函数
>>> def my_function(str):
... for i in range(3):
... print(f'I love {str}')
...
>>> my_function('Python')
I love Python
I love Python
I love Python3,带两个参数的函数
>>> def my_function(str,num):
... for i in range(num):
... print(f'I love {str}')
...
>>> my_function('Python',5)
I love Python
I love Python
I love Python
I love Python
I love Python4,带返回值的函数
>>> def div(x,y):
... z=x/y
... return z
...
>>> div(2,4)
0.55,若函数不行返回值,则默认返回None
6,关键字参数:
>>> def my_func(s,vt,o):
... return ''.join((o,vt,s))
...
>>> my_func(o='我',vt='打了',s='小甲鱼')
'我打了小甲鱼'7,默认参数,在函数定义时,若使用默认参数,默认参数需要定义在参数列表的后面
>>> def my_func(s,vt,o='小甲鱼'):
... return ''.join((o,vt,s))
...
>>> my_func('我','打了')
'小甲鱼打了我'
>>> my_func('我','打了','老王八')
'老王八打了我'8,参数列表中的 * 和 / ,在函数定义中,参数列表中放一个 / ,表示在 / 的左侧只能是位置参数,不能说关键字参数;参数列表中放一个 * ,表示在 * 的右侧只能说关键字参数,不能是位置参数。
>>> def abc(a,/,b,c):
... print(a,b,c)
...
>>> abc(1,2,c=3)
1 2 3
>>> abc(a=1,b=2,c=3)
Traceback (most recent call last):
File "", line 1, in
TypeError: abc() got some positional-only arguments passed as keyword arguments: 'a'
>>> def abc(a,*,b,c):
... print(a,b,c)
...
>>> abc(1,b=2,c=3)
1 2 3
>>> abc(1,2,c=3)
Traceback (most recent call last):
File "", line 1, in
TypeError: abc() takes 1 positional argument but 2 positional arguments (and 1 keyword-only argument) were given P44