【教3妹学java】6.String是引用类型吗?

2哥:3妹,我们已经学习了java的基本数据类型和引用类型,那你知道String是引用类型吗?
3妹:String是引用类型。Java语言除了8大基本类型(byte,short,char,int,long,float,double,boolean), 其他的都是引用类型, 所以String也是引用类型。
2哥:great, 答对了,那我再问你,以下这些概念你了解吗?
- String变量可以被修改吗?
- String.intern()
- 常量池
3妹:String是被final修饰的,不可以修改,其他的就不太了解了。
2哥:好,其他的我们慢慢来学习。

String源码
首先我们来看下String的源码:
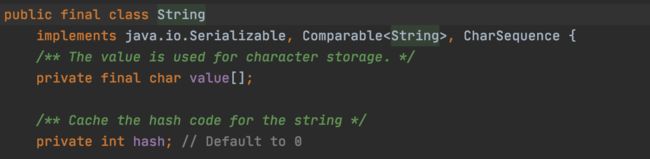
可以看到, String类被final修饰,表示该类不能被继承。
value[] 字符串数组变量也是被fina修饰表示该变量不能被修改,就是说不能再引用其他对象。
所有涉及修改字符串的方法,都会最后创建新的字符串对象。
为什么要String 要设计成不可变的?
- 不可变对象是线程安全的。
- 方便实现字符串常量池,如果String可变,那么对象池就需要考虑何时实现深拷贝的问题了。
- 不可变对象方便缓存hash code,作为key时可以更高效的保存到HashMap中。
直接定义一个字符串
String s1 = "hello";
String s2 = s1;
String s3 = "hello";
System.out.println(s1 == s2); //true
System.out.println(s1 == s3); //true
s1直接赋值给s2,所以s1==s2为true很好理解,这里不再多说。 那么既然 String是引用类型, 为什么s1 == s3也为true呢? 这里要介绍下字符串常量池。
字符串常量池
-
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能
-
JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化
-
为字符串开辟一个字符串常量池,类似于缓存区
-
创建字符串常量时,首先坚持字符串常量池是否存在该字符串
-
存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
实现的基础:
实现该优化的基础是因为字符串是不可变的,可以不用担心数据冲突进行共享
运行时实例创建的全局字符串常量池中有一个表,总是为池中每个唯一的字符串对象维护一个引用,这就意味着它们一直引用着字符串常量池中的对象,所以,在常量池中的这些字符串不会被垃圾收集器回收
再来分析一下下面的代码:
String s1 = "hello";
String s3 = "hello";
System.out.println(s1 == s3); //true
- 首先,常量池中查找“hello”的指针
- 如果在常量池中未能找到“hello”的指针,则在堆中分配“hello”的内存空间,把地址保存到常量池中,并把这个地址赋值给String型指针s1
- 定义s3的时候,因为在常量池中找到“hello”的指针,说明堆中已经存在“hello”的实体,因为常量表示一个不可变的对象,所以,没有必要再创建新的实例,直接把常量池中的指针内容赋值给String型指针s3
new String()
String s1 = "hello";
String s2 = new String("hello");
System.out.println(s1 == s2); //false
new String()会在堆中创建一个新的String实体,并深度拷贝“hello”的内容,并返回新的String实体的地址,赋值给指针s2. 因为不是同一个实例,所以s1 == s2会返回false.
思考题:
1、String str = new String(“abc”) 最多创建多少个对象?
- 在常量池中查找是否有“abc", 有则返回对应的引用实例,没有则在常量池中创建;在堆中 new 一个 String(“abc”) 对象;将对象地址赋值给str4,创建一个引用。 所以最多创建了2个对象,1个引用;
2、String str1 = new String(“A”+“B”) ; 会创建多少个对象?
String str2 = new String(“ABC”) + “ABC” ; 会创建多少个对象?
str1:
字符串常量池:“A”,“B”,“AB” : 3个
堆:new String(“AB”) :1个
引用: str1 :1个
总共 : 5个
str2 :
字符串常量池:“ABC” : 1个
堆:new String(“ABC”) :1个
引用: str2 :1个
总共 : 3个
String.intern()
java.lang.String.intern()返回一个保留池字符串,就是一个在全局字符串池中有了一个入口。如果以前没有在全局字符串池中,那么它就会被添加到里面
// Create three strings in three different ways.
String s1 = "Hello";
String s2 = new StringBuffer("He").append("llo").toString();
String s3 = s2.intern();
// Determine which strings are equivalent using the ==
System.out.println("s1 == s2? " + (s1 == s2)); // false
System.out.println("s1 == s3? " + (s1 == s3)); // true
补充:字面量和常量池初探
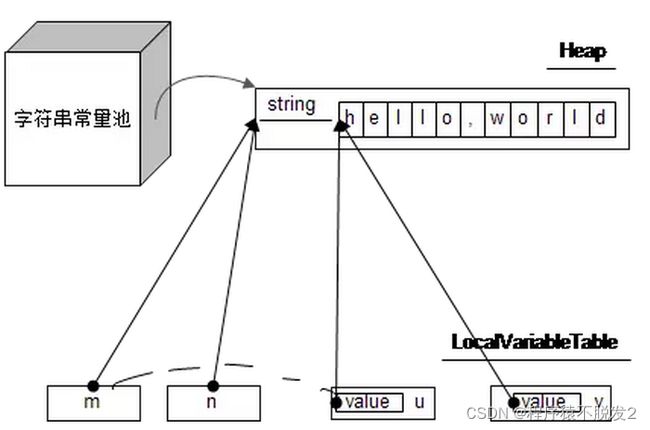
字符串对象内部是用字符数组存储的,那么看下面的例子:
String m = "hello,world";
String n = "hello,world";
String u = new String(m);
String v = new String("hello,world");
会分配一个11长度的char数组,并在常量池分配一个由这个char数组组成的字符串,然后由m去引用这个字符串
用n去引用常量池里边的字符串,所以和n引用的是同一个对象
生成一个新的字符串,但内部的字符数组引用着m内部的字符数组
同样会生成一个新的字符串,但内部的字符数组引用常量池里边的字符串内部的字符数组,意思是和u是同样的字符数组
使用图来表示的话,情况就大概是这样的(使用虚线只是表示两者其实没什么特别的关系):
测试demo:
String m = "hello,world";
String n = "hello,world";
String u = new String(m);
String v = new String("hello,world");
System.out.println(m == n); //true
System.out.println(m == u); //false
System.out.println(m == v); //false
System.out.println(u == v); //false
结论:
-
m和n是同一个对象
-
m,u,v都是不同的对象
-
m,u,v,n但都使用了同样的字符数组,并且用 equal判断的话也会返回true
String,StringBuffer和StringBuilder之间的区别是什么?
1.可变性
String是一个不可变类,任何对String改变都是会产生一个新的String对象,所以String类是使用final来进行修饰的。而StringBuffer和StringBuilder是可变类,对应的字符串的改变不会产生新的对象。
2.执行效率
当频繁对字符串进行修改时,使用String会生成一些临时对象,多一些附加操作,执行效率降低。
stringA = StringA + "2";
//实际上等价于
{
StringBuffer buffer = new StringBuffer(stringA)
buffer.append("2");
return buffer.toString();
}
在对stringA进行修改时,实际上是先根据字符串创建一个StringBuffer对象,然后调用append()方法对字符串修改,再调用toString()返回一个字符串。
3.线程安全
StringBuffer的读写方法都使用了synchronized修饰,同一时间只有一个线程进行操作,所以是线程安全的,而StringBuilder不是线程安全的。