Transformer 相关理解(上)
Transformer 是自然语言处理(NLP)领域一个十分知名的特征处理器,其本质是使用注意力机制进行自然语言的翻译。
你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。

所以在理解Transformer之前我们需要首先理解什么是注意力机制
注意力机制 Attention
一般的的Encoder-Decoder框架是没有体现“注意力模型”的,所以可以把它看做是注意力不集中分心模型。因为在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子的语义编码C都是一样的,没有任何区别。而语义编码C是由原句子中的每个单词经过Encoder编码产生的,这意味着原句子中任意单词对生成某个目标单词来说影响力都是相同的,这就是模型没有体现出注意力的缘由。

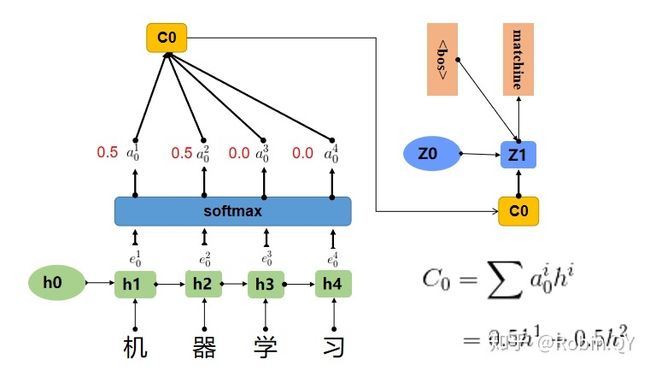
在上边那个例子中在生成“machine”时,"机","器","学",""习"的贡献是相同的,很明显,这是不太合理,显然,"机","器",对于翻译成"machine"更为重要。所以我们希望在模型翻译"machine"的时候,"机","器"两个字的贡献(权重)更大,当在翻译成"learning"时,"学","习"两个字贡献(权重)更大。

上图中,输入序列上是“机器学习”,因此Encoder中的h1、h2、h3、h4分别代表“机","器","学","习”的信息,在翻译"macine"时,第一个上下文向量C1应该和"机","器"两个字最相关,所以对应的权重a比较大,在翻译"learning"时,第二个上下文向量C2应该和"学","习"两个字最相关,所以"学","习"对应的权重a比较大。
a其实是一个0-1之间的值,a可以看成是e的softmax后的结果。

那现在关于attention来说就只剩下一个问题了,就是e是怎么来的。关于e的计算,业界有很多种方法,常用的有以下三种方式:
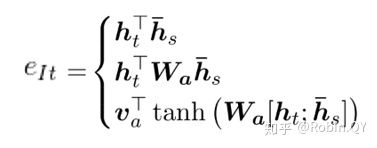
- 计算Encoder的序列h与Decoder的序列h的余弦相似度.
- 在1的基础上,乘上一个Wa,Wa是需要学习的参数,从学习到Encoder和Decoder的隐藏的打分e。
- 设计一个前馈神经网络,前馈神经网络的输入是Encoder和Decoder的两个隐藏状态,Va、Wa都是需要学习的参数。
Transformer
在理解了注意力机制以后我们继续来看这个叫transformer的黑盒子,它其实主要是由两部分组成的,分别是Encoder和Decoder,编码器和解码器。

当我输入一个文本的时候,该文本数据会先经过一个叫Encoders的模块,对该文本进行编码,然后将编码后的数据再传入一个叫Decoders的模块进行解码,解码后就得到了翻译后的文本,对应的我们称Encoders为编码器,Decoders为解码器。
那么编码器和解码器里边又都是些什么呢?
细心的同学可能已经发现了,上图中的Decoders后边加了个s,那就代表有多个编码器了呗,没错,这个编码模块里边,有很多小的编码器,一般情况下,Encoders里边有6个小编码器,同样的,Decoders里边有6个小解码器。
其中每个encoder和每个decoder他们的结构相同,但是参数不同,相当于每一个都是独立训练的一个神经网络。
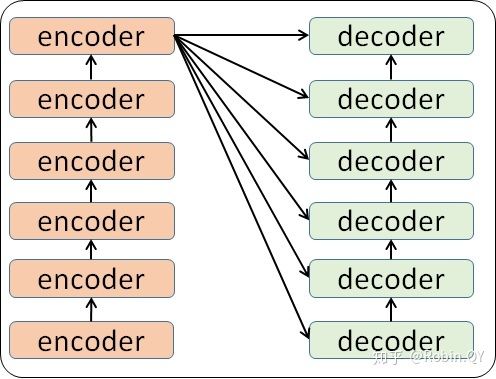
我们首先看一下原论文里的结构图 ,可以看到左半边是Encoder,右半边是Decoder,他们的结构基本相同,但是Decoder比Encoder多了一个Masked Multi-Head Attention机制,接下来的部分我们将Encoder和Decoder拆分开分析。

Encoder

第一部分:输入部分
位置编码



第二部分:注意力机制 【重点】

这里是注意力机制的公式,其中Q代表query,K代表key,V代表value,他们本质上是3个向量矩阵。
想要简单地理解它我们这里可以先把Q,K,V简单的想成3个向量而不是向量矩阵,这个向量是由我们的词Embedding过来的。
key向量和value向量是相对应的可以理解为一句话中每个词都有一对key和value向量,而query向量可以理解为我当前词的向量,当我当前词和某一个词key向量相似时【相似性比较】对应的value权重就大,最终这个词的query和每个词都有相似性,将他们做一个归一化就得到这个词和一句户每一个词的vaule的权重,最后做一个加权即可得到这个词在这个话中的attention。

这里可以理解it_为query,每一条线的深浅为权重大小,他们和为1(经过softmax)。
这里还需要提到相似性比较,一般来说有以下几种求向量相似度的方法:
- 点积也叫内积 :当两向量相似度越高,内积越大;当两向量正交内积为0;当两向量方向不同时内积小于0
- 基于距离的相似度度量:
欧式距离 (Euclidean Distance)、曼哈顿距离 (Manhattan Distance)、切比雪夫距离 (Chebyshev Distance)、马氏距离 (Mahalanobis Distance)等
-
余弦距离: cosine
-
MLP: 多层感知器也可以用来计算相似度
-
相关系数:皮尔逊相关系数(Pearson Correlation Coefficient)
我们还注意到他的公式里除了一个![]() ,这里作者给到的解释是当dk过大(向量过长)时,两个向量做点积可能会很大/很小,每组相对差距很大,导致做softmax后值会接近1/0,这样后续算梯度时会比较麻烦,收敛比较慢。
,这里作者给到的解释是当dk过大(向量过长)时,两个向量做点积可能会很大/很小,每组相对差距很大,导致做softmax后值会接近1/0,这样后续算梯度时会比较麻烦,收敛比较慢。
Self-Attention:
在自注意力机制中,Q,K和V向量是相同或相似的,他们都是由同一个词Embedding而来,这样自己的Q和K相似度是极高等,由于它只关注和自己相似度高的词向量(包括自己本身),所以叫做自注意力机制。
Mutli-Head Attention:
我们通过图片可以看到,原本的Q,K和V向量经过线性层的映射分别变为h组,每一组都进行Scaled 点积处理,最后整合起来,再进行线性层映射为原来的维度。
这样做的目的是为了像CNN一样可以识别更多的模式,提高鲁棒性。
愿论文中的W参数是可以通过学习来控制的。
每一个Q,K和V都是Embedding后的词向量与W的乘积得来的,如上图所示。
多头也指每一套Q,K和V他们对应的W权重不同。


