并发编程之线程池
目录
一、线程池基本概念
二、线程池常用队列
LinkedBlockingQueue
DelayQueue
SynchronousQueue
TransferQueue
三、拒绝策略
四、jdk自带线程池
SingleThreadPool
CachedThreadPool
FixedThreadPool
ScheduledThreadPool
五、部分线程池源码
六、两个特殊的线程池
WorkStealingPool
ForkJoinPool
七、补充知识
一、线程池基本概念
从下面这段线程池源码的构造方法,对线程池的基本概念有一个大致的了解:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
} 这是建立一个线程时最全的参数,对上面的参数做一个说明:
corePoolSize:核心线程数,线程池中允许长久存在的线程数;
maxPoolSize:最大线程数,线程池中允许出现的最大线程数;
keepAliveTime:超出核心线程数的线程允许存活的最大时间数值;
unit:超出核心线程数的线程允许存活的最大时间单位;
workQueue:等待队列,存放暂时无法执行线程,即超出核心线程数的线程;
handler:拒绝策略,当等待队列满,并且线程池中运行着最大线程数的线程,此时再来线程的话,如何处理。
下面对一个线程进来以后的整个流程做一个图示说明:
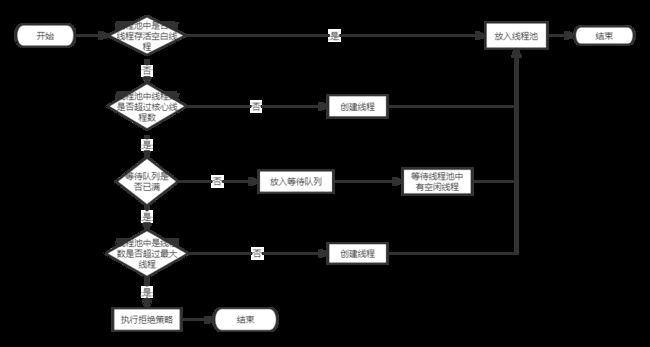
二、线程池常用队列
LinkedBlockingQueue
普通阻塞队列,队列的最大长度为Integer.MAX;
DelayQueue
可以针对时间进行排序的阻塞队列,但是需要注意的是该队列里面的元素的类需要实现Delayed接口,改接口需要实现compareTo方法,原因就是在DelayQueue中等待时间越短的就越先运行;DelayQueue是通过PriorityQueue实现的,PriorityQueue的底层是通过树结构来实现的;
SynchronousQueue
长度为0的阻塞队列,这个队列它内部不会放任何信息,它只是用来调度线程。当一个线程读取SynchronousQueue队列的信息的时候,由于它本身容量为0,线程会进行等待,此时当另一个线程往这个队列中"存储"信息的时候,线程会直接拿到该信息进行处理。它起到任务调度的作用。需要注意的是应为Synchronous的容量为0,所以只能执行put()方法,不能调用add()方法,不然会抛出以下异常
Exception in thread "main" java.lang.IllegalStateException: Queue full
at java.util.AbstractQueue.add(AbstractQueue.java:98)
at pool.D_SynchronousQueue.main(D_SynchronousQueue.java:12)TransferQueue
它也是一个信息传递的queue,但是它与SynchronousQueue的区别是,它存在容量。需要注意的是,只有执行它的transfer()方法的时候,它的特殊性才会被启用。当一个线程执行完transer()方法以后,该线程不会断开与TransferQueue的链接,他会等待另一个线程处理完它存放的信息以后,他才会断开链接。
三、拒绝策略
拒绝策略指的是当等待队列中已满,并且线程数达到最大线程数,再添加任务时,线程池如何处理。jdk本身自带四种拒绝策略:
AbortPolicy:抛出异常;
DiscardPolicy:直接丢弃该任务;
DiscardOldPolicy:丢弃等待队列中最早的那个任务;
CallerRunsPolicy:调用线程池的线程执行该任务。
除了上述jdk自带的拒绝策略以外我们还可以自定义拒绝策略,并且在实际开发中,大部分情况是使用自定义拒绝策略,下面大致描述一下如何自定义拒绝策略:
public class D_RejectHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 第一步,打印要执行的任务信息,为了让我们知道‘拒绝’是什么任务
// 第二步,对要'拒绝'的任务进行补偿处理,可以进行循环尝试,判断线程池在循环过程中是否可以被执行
// 第三步,如果第二步还不能执行该任务r,则将r放入缓存或者消息队列,进行补偿处理
}
}四、jdk自带线程池
SingleThreadPool
单线程线程池,核心线程数和最大线程数都为1,等待队列为无界队列,存活时间为0s,创建方式如下:
// 创建SingleThreadPool
ExecutorService singleThreadPool = Executors.newSingleThreadExecutor();
// 线程池执行线程
singleThreadPool.execute(()-> System.out.println("SingleThreadPool"));
// 创建源码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
// 单线程线程池创建的时候也允许传入ThreadFactory,默认的ThreadFactory创建的线程名称不友好
// 我们可以自定义ThreadFactory,对线程名称进行友好化处理
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory));
} 在使用单线程线程池的时候,等待队列是LinkedBlockingQueue,它的最大值为Integer.Max,如果线程太多的时候,可能会造成OOM。
CachedThreadPool
CachedThreadPool,核心线程数是0,最大线程数是Integer.MAX,线程存活时间60s,等待队列为SynchronousQueue,在上面的常用队列里面有过介绍,该队列的容量为0,它相当于是一个管道,通过这个队列我们能保证线程顺序执行,看下面的代码:
// 创建CachedThreadPool
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 线程池添加线程
cachedThreadPool.execute(()-> System.out.println("CachedThreadPool"));
// 创建源码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
// 创建源码,指定CachedThredPool
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue(),
threadFactory);
} 这种线程池不建议使用,因为最大线程数为Integer.MAX,如果线程数太多的时候,cpu基本都是在进行线程的切换,程序会卡死。
FixedThreadPool
固定线程数线程池,它的核心线程数和最大线程数相同,因此存活时间为0s,等待队列为LinkedBlockingQueue。
// 创建FixedThreadPool
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(10);
// 线程池添加线程
fixedThreadPool.execute(()-> System.out.println("FixedThreadPool"));
// 创建源码,指定核心线程数/最大线程数
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
// 创建源码,指定核心线程数/最大线程数和ThreadFactory
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory);
} 因为任务队列和SingleThreadPool使用的一样,因此当线程数过多时,也会造成OOM。
ScheduledThreadPool
定时任务线程池,核心线程数在创建时指定,最大线程数为Integer.MAX,存活时间为0,也就意味着只要线程空闲就消亡,等待队列使用DelayedWorkQueue。该线程池可以指定定时任务。
// 创建ScheduledThreadPool
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(10);
// 执行定时任务
scheduledThreadPool.scheduleAtFixedRate(
()-> System.out.println("FixedThreadPool"), 0, 500, TimeUnit.SECONDS);
// 创建源码,指定核心线程数
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
// 创建源码,指定核心线程数和threadFactory
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}利用上述jdk自带线程池时,如果不指定ThreadFactory,都会使用默认的ThreadFactory,为:
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
// 线程名称前缀
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}使用jdk自带线程池的时候,无法指定拒绝策略,采用默认的拒绝策略,即AbortPolicy。
五、部分线程池源码
下面对ThreadPoolExecutor的部分源码做一个简单的说明:
// 一个int类型的数字,int大小为8byte,32位,前三位表示线程池状态,后29位表示线程数
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 获取表示线程池线程数的位数
private static final int COUNT_BITS = Integer.SIZE - 3;
// 计算线程池允许的最大线程数
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池的五种状态,1.running:运行状态;2.shutdown:调用了shutdown()方法;
// 3.stop:调用了shutdownNow()方法;4.tidying:整理阶段;5.terminated:线程池运行结束
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 获取线程池状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 获取线程池中正在工作的线程数
private static int workerCountOf(int c) { return c & CAPACITY; }
// 根据线程池状态以及工作线程数量生成ctl
private static int ctlOf(int rs, int wc) { return rs | wc; }
// 线程池状态c是否小于s
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
// 线程池状态c是否大于等于s
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}execute方法:
public void execute(Runnable command) {
// 如果添加的任务为空,则直接抛出异常
if (command == null)
throw new NullPointerException();
// 获取当前线程状态
int c = ctl.get();
// 如果线程池中的工作线程数小于核心线程数,则创建核心线程
if (workerCountOf(c) < corePoolSize) {
// addWorker方法,true代表创建核心线程,false代表非核心线程
if (addWorker(command, true))
return;
// 再次获取线程池状态,防止在创建线程过程中,线程池状态被改变
c = ctl.get();
}
// 如果线程池状态为运行状态,并且将任务添加队列成功
if (isRunning(c) && workQueue.offer(command)) {
// 再次获取线程池状态
int recheck = ctl.get();
// 当前线程池状态不是运行状态并且从等待队列中移除任务成功,则执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 创建非核心线程失败,执行拒绝策略
else if (!addWorker(command, false))
reject(command);
} }六、两个特殊的线程池
WorkStealingPool
在上面我们说过的那些线程池中,所有的线程都是从一个等待队列中去拿取任务,WorkStealingPool每个线程都有一个对应的等待队列,当线程执行结束以后,它会从自己的队列中取任务,如果该线程对应的队列中已经没有任务了,那么会从其它线程的队列中去拿取任务。我们从创建WorkStealingPool的源码中,可以看到它内部其实是一个ForkJoinPool,如下
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}它的大致工作流程图如下:
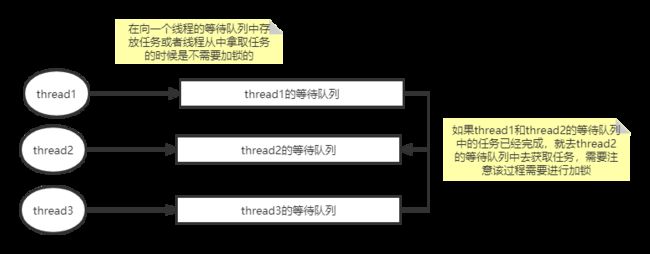
ForkJoinPool
该线程池适合的场景是,如果某个任务很大并且可以拆分的时候,可以使用该线程池。它的工作原理如下图:

下面通过一段代码对该线程池做一个介绍:
static int[] nums = new int[100000];
static int counts = 30000;
static Random random = new Random();
static {
for(int i = 0; i < nums.length; i++){
nums[i] = random.nextInt(100);
}
System.out.println("通过普通方法进行相加"+Arrays.stream(nums).sum());
}
/**
* ForkJoinPool里面的任务必须实现RecursiveTask(RecursiveAction)
* RecursiveTask有返回值
* RecursiveAction无返回值
*/
static class MyTask extends RecursiveTask{
int start, end;
MyTask(int start, int end){
this.start = start;
this.end = end;
}
/**
* 任务拆分的具体实现
* @return
*/
@Override
protected Integer compute() {
// 如果总数量小于任务拆分的限制,直接进行计算
if (end - start <= counts){
int result = 0;
for (int i = start; i < end; i++){
result += nums[i];
}
System.out.println("start:"+start+",end:"+end+",result:"+result);
return result;
}else {
// 如果总数量大于拆分限制,进行任务拆分,并且是递归拆分
int middle = start + (end - start)/2;
MyTask taskOne = new MyTask(start, middle);
MyTask taskTwo = new MyTask(middle, end);
taskOne.fork();
taskTwo.fork();
return taskOne.join() + taskTwo.join();
}
}
}
public static void main(String[] args) {
// 创建ForkJoinPool
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 创建执行任务
MyTask myTask = new MyTask(0, nums.length);
// 将任务交给线程池
forkJoinPool.execute(myTask);
long result = myTask.join();
System.out.println("通过forkJoinPool计算结果:"+result);
} 我们再来看一下执行结果:
通过普通方法进行相加4969283
start:50000,end:75000,result:1246136
start:0,end:25000,result:1244464
start:75000,end:100000,result:1244184
start:25000,end:50000,result:1234499
通过forkJoinPool计算结果:4969283我们对执行结果分析一下,根据里面的输出,可以很清晰的发现,将一个数据的总和计算任务拆分成了4部分来执行,分别为[0, 25000),[25000, 50000),[50000, 75000),[75000, 100000)。这个拆分规则是通过我们设定的值以及任务拆分规则来处理的。
七、补充知识
Executor:他是一个任务执行器,将线程创建和线程运行进行了一个分离,它里面只有一个execute方法,入参为Runnable,源码如下:
public interface Executor {
// 用来执行任务
void execute(Runnable command);
}ExecutorService:它继承自Executor,并且完善了任务执行器的生命周期,并且做任务执行器做了进一步的完善,我们所说的线程池就是基于ExecutorService实现的。线面看一下这个接口的源码:
public interface ExecutorService extends Executor {
// 关闭线程池,并且不再接收新任务。
// 并且不会等待已经提交的任务执行完成。
void shutdown();
// 尝试停止所有正在运行以及等待的线程,并返回等待线程的集合
List shutdownNow();
// 获取当前线程是否已经关闭
boolean isShutdown();
// 如果执行了shutdown以后所有任务都执行完成,则返回true
// 需要注意前提是必须先执行shutdown/shutdownNow
boolean isTerminated();
// 直到所有任务在收到shutdown请求之后执行完成,或者超过指定时间,或者当前线程被打断之前阻塞
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
// 提交一个带有返回值的任务,并且是异步处理,交给线程池以后不会等待结果,
// 可以调用get()方法进行阻塞等待,并返回执行结果
Future submit(Callable task);
// 提交一个runnable任务,异步,大致流程同上
Future submit(Runnable task, T result);
// 提交一个runnable任务,异步,大致流程同上,但是调用get()方法返回null
Future submit(Runnable task);
} CompleatableFuture,是一个更高级的管理类,它既可以对任务进行管理,又可以对任务的运行结果进行管理,通过以下代码对它有一个大致的了解:
// 创建CompletableFuture,并将要执行的任务交给它管理
CompletableFuture first = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(500);
}catch (Exception e){
e.printStackTrace();
}
return 1;
});
CompletableFuture second = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
}catch (Exception e){
e.printStackTrace();
}
return 2;
});
CompletableFuture third = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1500);
}catch (Exception e){
e.printStackTrace();
}
return 3;
});
long start = System.currentTimeMillis();
// 上面三个异步任务,阻塞到任意一个任务执行完成
System.out.println(CompletableFuture.anyOf(first, second, third).get());
System.out.println("any耗时:"+(System.currentTimeMillis() - start));
// 上面三个异步任务,需要阻塞到所有任务执行结束
CompletableFuture.allOf(first, second, third).get();
System.out.println("all耗时:"+(System.currentTimeMillis() - start));
System.out.println("first:"+first.get()+"second:"+second.get()+"third:"+third.get());
System.out.println("输出结果耗时:"+(System.currentTimeMillis() - start));
看一下输出结果:
1
any耗时:519
all耗时:1501
first:1second:2second:2
输出结果耗时:1501