基于 KubeSphere 的 Nebula Graph 多云架构管理实践
本文是杭州站 Meetup 讲师乔雷根据其分享内容整理而成的文章。
图数据库是一种使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。图数据库的应用领域非常广泛,在反应事物之间联系的计算都可以使用图数据库来解决,常用的领域如社交领域里的好友推荐、金融领域里的风控管理、零售领域里的商品实时推荐等等。
Nebula Graph 简介与架构
Nebula Graph 是一个高性能、可线性扩展、开源的分布式图数据库,它采用存储、计算分离的架构,计算层和存储层可以根据各自的情况弹性扩容、缩容,这就意味着 Nebula Graph 可以最大化利用云原生技术实现弹性扩展、成本控制,能够容纳千亿个顶点和万亿条边,并提供毫秒级查询延时的图数据库解决方案。
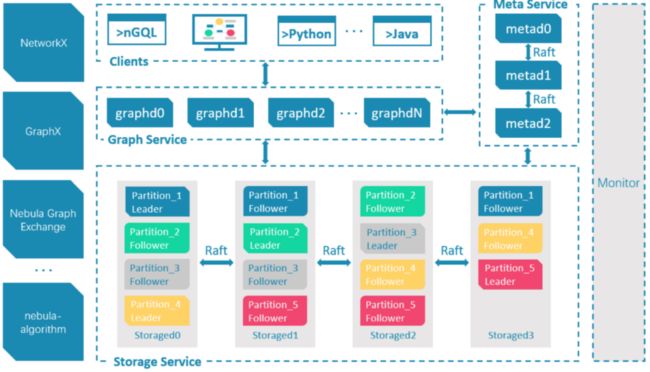
上图所示为 Nebula Graph 的架构,一个 Nebula 集群包含三个核心服务,Graph Service、Meta Service 和 Storage Service。每个服务由若干个副本组成,这些副本会根据调度策略均匀地分布在部署节点上。
Graph Service 对应的进程是 nebula-graphd,它由无状态无关联的计算节点组成,计算节点之间互不通信。Graph Service 的主要功能,是解析客户端发送 nGQL 文本,通过词法解析Lexer 和语法解析 Parser 生成执行计划,并通过优化后将执行计划交由执行引擎,执行引擎通过 Meta Service 获取图点和边的 schema,并通过存储引擎层获取点和边的数据。
Meta Service 对应的进程是 nebula-metad ,它基于 Raft 协议实现分布式集群,leader 由集群中所有 Meta Service 节点选出,然后对外提供服务,followers 处于待命状态并从 leader 复制更新的数据。一旦 leader 节点 down 掉,会再选举其中一个 follower 成为新的 leader。Meta Service 不仅负责存储和提供图数据的 meta 信息,如 Space、Schema、Partition、Tag 和 Edge 的属性的各字段的类型等,还同时负责指挥数据迁移及 leader 的变更等运维操作。
Storage Service 对应的进程是 nebula-storaged,采用 shared-nothing 的分布式架构设计,每个存储节点都有多个本地 KV 存储实例作为物理存储其核心,Nebula 采用 Raft 来保证这些KV 存储之间的一致性。目前支持的主要存储引擎为 Rocksdb 和 HBase。
Nebula Graph 提供C++、Java、Golang、Python、Rust 等多种语言的客户端,与服务器之间的通信方式为 RPC,采用的通信协议为 Facebook-Thrift。用户也可通过 nebula-console、nebula-studio 实现对 Nebula Graph 操作。
多云架构挑战
Nebula Graph 的云产品定位是 DBaaS (Database-as-a-Service)平台,因此肯定要借助云原生技术来达成这一目标。到底该如何落地呢?首先要明确一点,任何技术都不是银弹,只有合适的场景使用合适的技术。虽然我们拥有很多可供挑选的开源产品来搭建这个平台,但是最终落实到交付给用户的产品上,还有很多挑战。
这里我列举了三个方面的挑战:
业务挑战
多个云厂商的资源适配,这里需要实现统一的资源抽象模型,同时还要做好国际化,国际化需要考虑地域文化差异、当地法律法规差异、用户消费习惯差异等多个要素,这些要素决定了需要在设计模式上去迎合当地用户的使用习惯,从而提升用户体验。
性能挑战
在大多数情况下,通过同一云厂商网络传输的数据移动速度比必须通过全球互联网从一个云厂商传输到另一个云厂商的数据移动速度要快得多。这意味着跨云之间的网络连接可能成为多云体系结构的严重性能瓶颈。数据孤岛很难打破,因为企业无法迁移格式不同且驻留在不同技术中的数据,缺乏可迁移性会带给多云战略带来潜在的风险。在单个云厂商中,使用云厂商的原生自动扩展工具配置工作负载的自动扩展非常容易,当用户的工作负载跨越多个云厂商时,自动扩展就会变得棘手。
运营挑战
大规模的 Kubernetes 集群运营是非常有挑战的事情,满足业务的快速发展和用户需求也是对团队极大的考验。首先是做到集群的管理标准化、可视化,其次全部的运维操作流程化,这需要有一个深入了解运维痛点的管理平台,可以解决我们大部分的运维需求。数据安全上需要考虑在没有适当的治理和安全控制的情况下,将数据从一个平台迁移到另一个平台(或从一个区域迁移到另一个区域)会带来数据安全风险。
DBaaS(Database-as-a-Service)
云原生技术简单概括就是为用户提供一种简易的、敏捷的、可弹性扩展的、可复制的方式,最大化使用云上资源的能力。云原生技术不断演进也是为了用户更好的专注于业务开发。大家可以看到这个金字塔,从 IaaS 到最上面的云原生应用层,产品形态越来越灵活,计算单元的粒度越来越细,模块化程度、自动化运维程度、弹性效率、故障恢复能力都是越来越高,这说明每往上走一层,应用与底层物理基础设施解耦就越彻底,用户的关注点不再是从硬件服务器到业务实现整个链条,而是仅需要关注于当下业务本身。

PaaS 平台的容器编排系统是 Kubernetes,自然而然地就能想到基于 Kubernetes 构建这套平台,Kubernetes 提供了容器运行时接口,你可以选择任意一种实现这套接口的运行时来构建应用运行的基础环境。因此,利用好 Kubernetes 提供的能力,就能达到事半功倍的效果。Kubernetes 提供了从命令行终端 kubectl 到容器运行依赖的存储、网络、计算的多个扩展点,用户可以根据业务场景实现一些自定义扩展插件对接到 kubernetes 平台,而不用担心侵入性。
用户视图
NebulaCloud 目前为用户提供两种访问方式,一种是通过浏览器进入 Studio 操作窗口,在数据导入后可以做图探索,nGQL 语句执行等操作,另一种是通过厂商提供的 private-link 打通用户到 NebulaCloud 之间的网络连接,用户可以通过 nebula-console 或者 nebula client 直连到 Nebula 实例。

NebulaCloud 架构
从业务架构上看,NebulaCloud 可以分为三层,最底层是资源适配层,主要负责提供资源层面上的适配,提供对多云厂商、多地域集群、同构或异构资源池的抽象描述。再往上是业务层与资源层,业务层涵盖基础服务、实例管理、租户管理、计费管理、数据导入管理等业务模块;资源层负责提供 Nebula 集群的运行环境,在调度策略下提供最佳的资源配置。最上层是网关层,对外提供访问服务。

NebulaCloud 内部流程
这里以 AWS 为例策略地描述一个 Nebula 集群的创建过程。用户创建实例请求提交后,nebula-platform 服务根据输入的厂商、地域、规格等参数信息做资源调度,比如资源池、负载均衡、安全策略等配置,然后通过 nebula-operator 的 api 完成实例的创建,最后配置 ALB 规则,为用户提供访问实例的入口。

Nebula-Operator
在 Kubernetes 中,定义一个新对象可以有两种方式,一个是 CustomResourceDefinition, 一个是 Aggregation ApiServer,其中 CRD 是目前主流的做法,nebula-operator 就是 CRD 来实现的。
CRD+Custom Controller 就是典型的 Operator 模式了。通过向 Kubernetes 系统注册好的 CRD,我们可以使用 controller 来观察 Nebula 集群以及与它相关联的资源对象状态,然后按照写的协调逻辑来驱动 Nebula 集群向期望状态转移。这么实现可以把 Nebula 相关的管理工作都沉淀到 Operator 里,用户使用 NebulaGraph 的复杂度降低,可以轻松完成弹性扩缩容、滚动升级等核心操作。我们基于 kubernetes 的 Restful API 生成了一套管理 Nebula 集群的 API,这样用户可以拿着 API 就能实现对接自己的 PaaS 平台,搭建自己的图计算平台。
nebula-operator 目前的功能还在不断完善中,实例的滚动升级需要 Nebula 提供底层支持,预计今年会支持上。

KubeSphere 多集群管理
平台化管理
KubeSphere 衍生自青云公有云的操作面板,除了继承颜值,同时在功能上也是相当完备。NebulaCloud 需要对接的主流云厂商都已经支持上,因此一套管理平台就可以运维所有的 Kubernetes 集群。多集群管理是我们最为看重的功能点。
我们在本地环境部署了 Host 集群,其余的云上托管 Kubernetes 集群通过直连接入的方式作为 Member 集群,这里需要注意 ApiServer 访问配置放通单个 IP,比如本地环境的出口公网 IP。


流程化操作
我们使用 IaC 工具 pulumi 部署新集群,再通过自动化脚本工具设置待管理集群 member 角色,全部过程无需人工操作。集群的创建由平台的告警模块来触发,当单集群的资源配额达到告警水位后,会自动触发弹性出一套新的集群。
自动化监控
KubeSphere 提供了丰富的内置告警策略,同时还支持自定义告警策略,内置的告警策略基本可以覆盖日常所需的监控指标。在告警方式上也有多种选择,我们采用了邮件与钉钉相结合的方式,重要紧急的可以通过钉钉直接钉到值班人员,普通级别的可以走邮件方式。


智能化运营
KubeSphere 提供了集群多个维度的全局展示视图,目前管理的集群数量少足够使用。未来随着接入 member 集群数量的增加,可以通过运营数据的分析做资源的精细化调度和故障预测,进一步提前发现风险,提升运营的质量。


其他
KubeSphere 还有很多好用的配套工具,比如日志查询、事件查询、操作审计日志等,这些工具在精细化运营都是必不可少的。 我们目前已经接入了测试环境集群,在深度使用掌握 KubeSphere 的全貌后会尝试接入生产集群。
未来规划
我们将充分挖掘自定义告警策略并加以利用,同时结合 Nebula 集群自身的监控指标打造监控全景图;覆盖核心指标的多级、多维度的告警机制,将风险消灭在源头;完善周边配套工具,通过主动、被动以及流程化等减少误操作风险;启用 DevOps 工作流,打通开发、测试、预发、生产环境,减少人力介入。
本文由博客一文多发平台 OpenWrite 发布!