【小呆的概率论学习笔记】抽样调查之用抽样样本估计母体数字特征
文章目录
-
-
- 1. 随机变量的数字特征
-
- 1.1 随机变量的均值(期望)
- 1.2 随机变量的方差
- 1.3 随机变量的协方差
- 2. 抽样调查
- 3. 用抽样样本估计母体数字特征
-
- 3.1 估计母体样本均值
- 3.2 抽样样本均值的方差
- 3.2 估计母体样本方差
-
1. 随机变量的数字特征
随机变量本质上是一个随机数,他以概率的形式取任何可能的取值,但是随机变量取值却有一定的规律,我们可以称之为随机变量的数字特征。最简明、最常用的随机变量的数字特征就是均值(或者说期望)和方差。
1.1 随机变量的均值(期望)
随机变量的均值的意义类似于概率平均,意味着随机变量的取值大概率围绕这个均值并在一定的范围内变化。如下图所示。

那么概率平均的计算就可以参照加权平均的形式给定出。假设n个数 x 1 、 x 2 、 … … 、 x n x_1、x_2、……、x_n x1、x2、……、xn的权分别是 w 1 、 w 2 、 … … 、 w n w_1、w_2、……、w_n w1、w2、……、wn,难么加权平均值为
x ‾ = x 1 w 1 + x 2 w 2 + … … + x n w n n \overline x=\frac{x_1w_1+x_2w_2+……+x_nw_n}{n} x=nx1w1+x2w2+……+xnwn
上式为加权平均公式,那么类似的,概率平均可以把随机变量的各个取值的概率当成每个取值的 权数 总数 \frac{权数}{总数} 总数权数,显然这样的概率平均,也就是均值(期望)可以表示成
E ( X ) = ∑ i = 1 n x i p ( x i ) E(X)=\sum_{i=1}^n x_ip(x_i) E(X)=i=1∑nxip(xi)
其中 p ( x i ) p(x_i) p(xi)是 X = x i X=x_i X=xi的概率。
当然如果随机变量X是连续随机变量,那么均值的公式等效的变化成
E ( X ) = ∫ − ∞ ∞ x i d p ( x i ) = ∫ − ∞ ∞ x i f ( x i ) d x i = ∫ − ∞ ∞ x f ( x ) d x E(X)=\int_{-\infty}^{\infty} x_idp(x_i)=\int_{-\infty}^{\infty} x_if(x_i)dx_i=\int_{-\infty}^{\infty} xf(x)dx E(X)=∫−∞∞xidp(xi)=∫−∞∞xif(xi)dxi=∫−∞∞xf(x)dx
1.2 随机变量的方差
前面对随机变量的均值或者说期望进行了讨论,总的来说随机变量每次取值都会在均值的一定范围内变化,就是说会有几次取值比均值大,当然也会 有几次取值比均值小。这对于我们评估和使用非常重要。均值最典型应用是在于投资,当投资期望=成功率×收益+失败率×损失>0,那么这笔投资总是一笔不差的投资(理论计算)。
此外,这个随机变量围绕均值偏离的程度也是一个重要的衡量,有时候对于实际使用中有很大的影响。在很多情况,人们可能更喜欢偏离程度有限的选择,典型的比如人们喜欢波动小的股票,工厂往往控制质量,使得产品一致性尽可能高。
下图为同均值情况下不同方差的数据集,左图为小方差,右图为大方差。
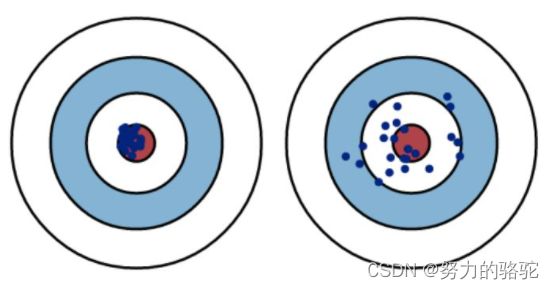
那么,就引出来用随机变量偏离均值的程度来定义方差,以便用方差来衡量这种离散程度,即
D ( X ) = E { [ X − E ( X ) ] 2 } D(X)=E\{[X-E(X)]^2\} D(X)=E{[X−E(X)]2}
那么,离散随机变量的方差表达式如下
D ( X ) = E { [ X − E ( X ) ] 2 } = ∑ ( x i − μ ) 2 p ( x i ) D(X)=E\{[X-E(X)]^2\}=\sum(x_i-\mu)^2p(x_i) D(X)=E{[X−E(X)]2}=∑(xi−μ)2p(xi)
连续随机变量的方差表达式如下
D ( X ) = E { [ X − E ( X ) ] 2 } = ∫ − ∞ ∞ ( x i − μ ) 2 d p ( x i ) = ∫ − ∞ ∞ ( x i − μ ) 2 f ( x i ) d x i = ∫ − ∞ ∞ ( x − μ ) 2 f ( x ) d x \begin{aligned}D(X)&=E\{[X-E(X)]^2\}\\ &=\int_{-\infty}^{\infty}(x_i-\mu)^2dp(x_i)\\ &=\int_{-\infty}^{\infty}(x_i-\mu)^2f(x_i)dx_i\\ &=\int_{-\infty}^{\infty}(x-\mu)^2f(x)dx\end{aligned} D(X)=E{[X−E(X)]2}=∫−∞∞(xi−μ)2dp(xi)=∫−∞∞(xi−μ)2f(xi)dxi=∫−∞∞(x−μ)2f(x)dx
1.3 随机变量的协方差
随机变量的方差能够度量其变异性,那么如果随机变量超过一个,就需要考虑怎么度量随机变量联合变异性或者说度量随机变量的关联度。参考方差的定义,我们可以定义协方差来定义这种度量
C o v ( x i , x j ) = E [ ( x i − μ x i ) ( x j − μ x j ) ] \mathbf {Cov}(x_i,x_j)=E[(x_i-\mu_{x_i})(x_j-\mu_{x_j})] Cov(xi,xj)=E[(xi−μxi)(xj−μxj)]
那么,协方差有以下特性
a) i=j时,协方差就等于方差,即方差是协方差的一种特殊情况
C o v ( x i , x i ) = E [ ( x i − μ x i ) ( x i − μ x i ) ] = σ 2 \mathbf {Cov}(x_i,x_i)=E[(x_i-\mu_{x_i})(x_i-\mu_{x_i})]=\sigma^2 Cov(xi,xi)=E[(xi−μxi)(xi−μxi)]=σ2
b) 如果x_i与x_j相互独立,那么就没有联合变异性或者关联度,协方差也能够反映这种情况,如下
C o v ( x i , x j ) = E [ ( x i − μ x i ) ( x j − μ x j ) ] = E ( x i x j − μ x i x j − x i μ x j + μ x i μ x j ) = E ( x i x j ) − μ x i E ( x j ) − E ( x i ) μ x j + μ x i μ x j = E ( x i x j ) − μ x i μ x j − μ x i μ x j + μ x i μ x j = E ( x i x j ) − μ x i μ x j \begin{aligned}\mathbf {Cov}(x_i,x_j)&=E[(x_i-\mu_{x_i})(x_j-\mu_{x_j})]\\ &=E(x_ix_j-\mu_{x_i}x_j-x_i\mu_{x_j}+\mu_{x_i}\mu_{x_j})\\ &=E(x_ix_j)-\mu_{x_i}E(x_j)-E(x_i)\mu_{x_j}+\mu_{x_i}\mu_{x_j}\\ &=E(x_ix_j)-\mu_{x_i}\mu_{x_j}-\mu_{x_i}\mu_{x_j}+\mu_{x_i}\mu_{x_j}\\ &=E(x_ix_j)-\mu_{x_i}\mu_{x_j}\\ \end{aligned} Cov(xi,xj)=E[(xi−μxi)(xj−μxj)]=E(xixj−μxixj−xiμxj+μxiμxj)=E(xixj)−μxiE(xj)−E(xi)μxj+μxiμxj=E(xixj)−μxiμxj−μxiμxj+μxiμxj=E(xixj)−μxiμxj
如果x_i与x_j相互独立,就有 E ( x i x j ) = E ( x i ) E ( x j ) = μ x i μ x j E(x_ix_j)=E(x_i)E(x_j)=\mu_{x_i}\mu_{x_j} E(xixj)=E(xi)E(xj)=μxiμxj,那么
C o v ( x i , x j ) = E ( x i x j ) − μ x i μ x j = 0 \mathbf {Cov}(x_i,x_j)=E(x_ix_j)-\mu_{x_i}\mu_{x_j}=0 Cov(xi,xj)=E(xixj)−μxiμxj=0
2. 抽样调查
自然界有些随机变量的总体或者母体 [ 注 1 ] ^{[注1]} [注1]是有限的,比如从一副扑克牌中抽一张,他的总体也就是只有108种可能,一次美国大选,支持拜登或者支持特朗普的票数总是有限的可能,有一些随机变量的总体却是无限的,比如像连续型随机变量。
注1:随机变量所有可能的取值组成的全体,称为样本空间或者总体或者母体。
那么,实际生活或者工作中,我们总需要通过观察或者少数试验来评价或者估计事务的某种可能性,诶,我们往往就通过抽样调查来实现。
当然,其实抽样调查组成的抽样样本也是随机的,比如在拜登和川普的美国大选中,我们抽取100个人做调查,其中有53个人支持拜登,47个人支持川普,但是我们如果再抽100人,可能48个人支持拜登,52个人支持川普,由此不难看出抽样样本本身也是随机的,那么抽样样本的数字特征也是一个随机变量,用它来评估母体样本的数字特征,我们需要研究其是否具备的代表性或者有效性。
在抽样调查中,有两种类型,一是重复抽样,即抽样调查的每一个样本是相互独立的,二是无重复抽样,即抽样调查的每一个样本是不是相互独立的。
3. 用抽样样本估计母体数字特征
3.1 估计母体样本均值
假设母体样本为 Ω = { x 1 , x 2 , … … , x n } \Omega=\{x_1,x_2,……,x_n\} Ω={x1,x2,……,xn},而抽样样本为 ω = { x ^ 1 , x ^ 2 , … … , x ^ m } \omega=\{\hat x_1,\hat x_2,……,\hat x_m\} ω={x^1,x^2,……,x^m},母体样本的均值为
μ = ∑ i = 1 n x i p ( x i ) = 1 n ∑ i = 1 n x i \mu=\sum_{i=1}^n x_ip(x_i)=\frac{1}{n}\sum_{i=1}^n x_i μ=i=1∑nxip(xi)=n1i=1∑nxi
当然这里 x ^ i \hat x_i x^i也是 Ω \Omega Ω内的 元素。
那么我们寻求利用抽样数据来找到一个能够相对准确可靠的估计母体样本均值的公式。其实,很容易想到用抽样数据的均值来估计母体样本的均值,那么这样是否是足够可靠的。因为抽样数据的均值其实也是一个随机数,那么相对准确可靠的含义我想应该是抽样样本均值这个随机变量应该是围绕真实值(母体均值)在一定范围内变化,也就是说抽样样本的均值的期望应该是等于母体均值。
如果抽样样本的均值
x ‾ = ∑ i = 1 m x ^ i p ( x ^ i ) = 1 m ∑ i = 1 m x ^ i \overline x=\sum_{i=1}^m \hat x_ip( \hat x_i)=\frac{1}{m}\sum_{i=1}^m \hat x_i x=i=1∑mx^ip(x^i)=m1i=1∑mx^i
注意此时 x ‾ \overline x x也是随机变量。
那么上文翻译成数学语言应该就是
E ( x ‾ ) = μ E(\overline x)=\mu E(x)=μ
实际上
E ( x ‾ ) = E { 1 m ∑ m x ^ i } = 1 m ∑ m E ( x ^ i ) = 1 m ⋅ ∑ m μ = μ \begin{aligned}E(\overline x)&=E\{\frac{1}{m}\sum_m \hat x_i\}\\ &=\frac{1}{m}\sum_m E(\hat x_i)=\frac{1}{m}\cdot \sum_m \mu=\mu \end{aligned} E(x)=E{m1m∑x^i}=m1m∑E(x^i)=m1⋅m∑μ=μ
因此抽样样本均值的期望应该是等于母体样本的均值,像这种估计我们称为无偏估计(即不存在系统性偏差的估计),如下图所示。上图是无偏估计,下图是有偏估计。
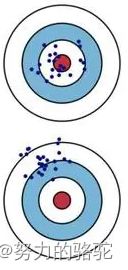
用抽样样本均值估计母体均值是一种无偏估计。
当然,不管如何,一定要记住 x ‾ \overline x x是随机变量,即在任何一次调查中得到的样本均值都不会等于母体样本的均值。
3.2 抽样样本均值的方差
既然抽样样本均值 x ‾ \overline x x是随机变量,那么也可以通过其方差来评价 x ‾ \overline x x的离散程度。按照方差的定义,有
D ( x ‾ ) = E { [ x ‾ − E ( x ‾ ) ] 2 } = E { [ 1 m ∑ i = 1 m x ^ i − μ ] 2 } = E { 1 m [ ∑ i = 1 m x ^ i − m μ ] ⋅ 1 m [ ∑ i = 1 m x ^ i − m μ ] } = 1 m 2 E { [ ∑ i = 1 m ( x ^ i − μ ) ] ⋅ [ ∑ i = 1 m ( x ^ i − μ ) ] } = 1 m 2 E { ∑ i = 1 m ∑ j = 1 m ( x ^ i − μ ) ( x ^ j − μ ) } = 1 m 2 ∑ i = 1 m ∑ j = 1 m E { ( x ^ i − μ ) ( x ^ j − μ ) } = 1 m 2 ∑ i = 1 m ∑ j = 1 m C o v ( x ^ i , x ^ j ) = 1 m 2 ∑ i = 1 m C o v ( x ^ i , x ^ i ) + 1 m 2 ∑ i = 1 m ∑ j ≠ i m C o v ( x ^ i , x ^ j ) \begin{aligned}D(\overline x)&=E\{[\overline x-E(\overline x)]^2\} \\&=E\{[\frac{1}{m}\sum_{i=1}^m \hat x_i-\mu]^2\}\\ &=E\{\frac{1}{m}[\sum_{i=1}^m \hat x_i-m\mu]\cdot\frac{1}{m}[\sum_{i=1}^m \hat x_i-m\mu]\}\\ &=\frac{1}{m^2}E\{[\sum_{i=1}^m (\hat x_i-\mu)]\cdot[\sum_{i=1}^m (\hat x_i-\mu)]\}\\ &=\frac{1}{m^2}E\{\sum_{i=1}^m\sum_{j=1}^m(\hat x_i-\mu)(\hat x_j-\mu)\}\\ &=\frac{1}{m^2}\sum_{i=1}^m\sum_{j=1}^mE\{(\hat x_i-\mu)(\hat x_j-\mu)\}\\ &=\frac{1}{m^2}\sum_{i=1}^m\sum_{j=1}^m\mathbf {Cov}(\hat x_i,\hat x_j)\\ &=\frac{1}{m^2}\sum_{i=1}^m\mathbf {Cov}(\hat x_i,\hat x_i)+\frac{1}{m^2}\sum_{i=1}^m\sum_{j\neq i}^m\mathbf {Cov}(\hat x_i,\hat x_j) \end{aligned} D(x)=E{[x−E(x)]2}=E{[m1i=1∑mx^i−μ]2}=E{m1[i=1∑mx^i−mμ]⋅m1[i=1∑mx^i−mμ]}=m21E{[i=1∑m(x^i−μ)]⋅[i=1∑m(x^i−μ)]}=m21E{i=1∑mj=1∑m(x^i−μ)(x^j−μ)}=m21i=1∑mj=1∑mE{(x^i−μ)(x^j−μ)}=m21i=1∑mj=1∑mCov(x^i,x^j)=m21i=1∑mCov(x^i,x^i)+m21i=1∑mj=i∑mCov(x^i,x^j)
其中,如果 x ^ i \hat x_i x^i是独立的,那么 C o v ( x ^ i , x ^ j ) = i ≠ j 0 \mathbf {Cov}(\hat x_i,\hat x_j)\xlongequal{i\neq j}0 Cov(x^i,x^j)i=j0, C o v ( x ^ i , x ^ j ) = i = j C o v ( x ^ i , x ^ i ) = D ( x ^ i ) = σ 2 \mathbf {Cov}(\hat x_i,\hat x_j)\xlongequal{i= j}\mathbf {Cov}(\hat x_i,\hat x_i)=D(\hat x_i)=\sigma^2 Cov(x^i,x^j)i=jCov(x^i,x^i)=D(x^i)=σ2。
D ( x ‾ ) = 1 m 2 ∑ i = 1 m C o v ( x ^ i , x ^ i ) = 1 m 2 ⋅ m σ 2 = σ 2 m D(\overline x)=\frac{1}{m^2}\sum_{i=1}^m\mathbf {Cov}(\hat x_i,\hat x_i)=\frac{1}{m^2}\cdot m\sigma^2=\frac{\sigma^2}{m} D(x)=m21i=1∑mCov(x^i,x^i)=m21⋅mσ2=mσ2
如果抽样是不重复的,那么 x ^ i \hat x_i x^i就不是独立。以离散随机变量为例,假设母体样本总共有N个元素,那么
C o v ( x ^ i , x ^ j ) = E ( x ^ i x ^ j ) − E ( x ^ i ) E ( x ^ j ) = ∑ k = 1 m ∑ l = 1 m η ^ k η ^ l P ( x ^ i = η ^ k 并 x ^ j = η ^ l ) = ∑ k = 1 m η ^ k P ( x ^ i = η ^ k ) ∑ l = 1 m η ^ l P ( x ^ j = η ^ l ∣ x ^ i = η ^ k ) \begin{aligned}\mathbf {Cov}(\hat x_i,\hat x_j)&=E(\hat x_i\hat x_j)-E(\hat x_i)E(\hat x_j)\\ &=\sum_{k=1}^m\sum_{l=1}^m\hat \eta_k\hat \eta_l P(\hat x_i=\hat\eta_k 并 \hat x_j=\hat \eta_l)\\ &=\sum_{k=1}^m\hat \eta_k P(\hat x_i=\hat\eta_k )\sum_{l=1}^m\hat \eta_lP(\hat x_j=\hat\eta_l | \hat x_i= \hat\eta_k) \end{aligned} Cov(x^i,x^j)=E(x^ix^j)−E(x^i)E(x^j)=k=1∑ml=1∑mη^kη^lP(x^i=η^k并x^j=η^l)=k=1∑mη^kP(x^i=η^k)l=1∑mη^lP(x^j=η^l∣x^i=η^k)
条件概率 P ( x ^ j = η ^ l ∣ x ^ i = η ^ k ) P(\hat x_j=\hat\eta_l | \hat x_i=\hat \eta_k) P(x^j=η^l∣x^i=η^k)由下式确定
P ( x ^ j = η ^ l ∣ x ^ i = η ^ k ) = { n l N − 1 , l ≠ k n l − 1 N − 1 , l = k P(\hat x_j=\hat\eta_l | \hat x_i=\hat \eta_k)=\begin{cases} \frac{n_l}{N-1}, l\neq k\\ \frac{n_l-1}{N-1}, l= k \end{cases} P(x^j=η^l∣x^i=η^k)={N−1nl,l=kN−1nl−1,l=k
其中 n l n_l nl是母体样本中 η l \eta_l ηl的个数,N-1是 x ^ i = η k \hat x_i= \eta_k x^i=ηk抽样后的母体样本数(因为是不重复抽样,所以母体样本变少了),如果 l = k l=k l=k那么相应的 η l \eta_l ηl的个数也要减一。
C o v ( x ^ i , x ^ j ) = E ( x ^ i x ^ j ) − E ( x ^ i ) E ( x ^ j ) = ∑ k = 1 m η ^ k P ( x ^ i = η ^ k ) ∑ l = 1 m η ^ l P ( x ^ j = η ^ l ∣ x ^ i = η ^ k ) − μ 2 = ∑ k = 1 m η ^ k n k N ( ∑ l = 1 , l ≠ k m η ^ l n l N − 1 + η ^ k n k − 1 N − 1 ) − μ 2 = ∑ k = 1 m η ^ k n k N ( ∑ l = 1 , l ≠ k m η ^ l n l N − 1 + η ^ k n k N − 1 − η ^ k 1 N − 1 ) − μ 2 = ∑ k = 1 m η ^ k n k N ( ∑ l = 1 m η ^ l n l N − 1 − η ^ k 1 N − 1 ) − μ 2 = ∑ k = 1 m η ^ k n k N ∑ l = 1 m η ^ l n l N − 1 − ∑ k = 1 m η ^ k 2 n k N ( N − 1 ) − μ 2 = 1 N ( N − 1 ) ( ∑ k = 1 m η ^ k n k ∑ l = 1 m η ^ l n l − ∑ k = 1 m η ^ k 2 n k ) − μ 2 = 1 N ( N − 1 ) [ ( ∑ i = 1 N x i ) 2 − ∑ i = 1 N x ^ i 2 ] − μ 2 = 1 N ( N − 1 ) ( N 2 μ 2 − N μ 2 − N σ 2 ) − μ 2 = − 1 N − 1 σ 2 \begin{aligned}\mathbf {Cov}(\hat x_i,\hat x_j)&=E(\hat x_i\hat x_j)-E(\hat x_i)E(\hat x_j)\\ &=\sum_{k=1}^m\hat \eta_k P(\hat x_i=\hat \eta_k )\sum_{l=1}^m\hat \eta_lP(\hat x_j=\hat \eta_l | \hat x_i= \hat \eta_k)-\mu^2\\ &=\sum_{k=1}^m\hat \eta_k \frac{n_k}{N}(\sum_{l=1,l\neq k}^m\hat \eta_l \frac{n_l}{N-1}+\hat \eta_k\frac{n_k-1}{N-1})-\mu^2\\ &=\sum_{k=1}^m\hat \eta_k \frac{n_k}{N}(\sum_{l=1,l\neq k}^m\hat \eta_l \frac{n_l}{N-1}+\hat \eta_k\frac{n_k}{N-1}-\hat \eta_k\frac{1}{N-1})-\mu^2\\ &=\sum_{k=1}^m\hat \eta_k \frac{n_k}{N}(\sum_{l=1}^m\hat \eta_l \frac{n_l}{N-1}-\hat \eta_k\frac{1}{N-1})-\mu^2\\ &=\sum_{k=1}^m\hat \eta_k \frac{n_k}{N}\sum_{l=1}^m\hat \eta_l \frac{n_l}{N-1}-\sum_{k=1}^m\hat \eta_k ^2\frac{n_k}{N(N-1)}-\mu^2\\ &=\frac{1}{N(N-1)}(\sum_{k=1}^m\hat \eta_k n_k\sum_{l=1}^m\hat \eta_l n_l- \sum_{k=1}^m\hat \eta_k ^2n_k)-\mu^2\\ &=\frac{1}{N(N-1)}[(\sum_{i=1}^Nx_i)^2 - \sum_{i=1}^N\hat x_i^2]-\mu^2\\ &=\frac{1}{N(N-1)}(N^2\mu^2 - N\mu^2-N\sigma^2)-\mu^2\\ &=-\frac{1}{N-1}\sigma^2 \end{aligned} Cov(x^i,x^j)=E(x^ix^j)−E(x^i)E(x^j)=k=1∑mη^kP(x^i=η^k)l=1∑mη^lP(x^j=η^l∣x^i=η^k)−μ2=k=1∑mη^kNnk(l=1,l=k∑mη^lN−1nl+η^kN−1nk−1)−μ2=k=1∑mη^kNnk(l=1,l=k∑mη^lN−1nl+η^kN−1nk−η^kN−11)−μ2=k=1∑mη^kNnk(l=1∑mη^lN−1nl−η^kN−11)−μ2=k=1∑mη^kNnkl=1∑mη^lN−1nl−k=1∑mη^k2N(N−1)nk−μ2=N(N−1)1(k=1∑mη^knkl=1∑mη^lnl−k=1∑mη^k2nk)−μ2=N(N−1)1[(i=1∑Nxi)2−i=1∑Nx^i2]−μ2=N(N−1)1(N2μ2−Nμ2−Nσ2)−μ2=−N−11σ2
上式过程中需要用到几个关系式:
a) 期望定义式
E ( x ^ i ) = ∑ i = 1 N x ^ i p ( x ^ i ) = ∑ i = 1 N x ^ i 1 N = 1 N ∑ i = 1 N x ^ i = ∑ j = 1 m x ^ j n j N E(\hat x_i) = \sum_{i=1}^N\hat x_ip(\hat x_i)=\sum_{i=1}^N\hat x_i\frac{1}{N}=\frac{1}{N}\sum_{i=1}^N\hat x_i\\ =\sum_{j=1}^m\hat x_j\frac{n_j}{N} E(x^i)=i=1∑Nx^ip(x^i)=i=1∑Nx^iN1=N1i=1∑Nx^i=j=1∑mx^jNnj
那么相应的
E ( x ^ i 2 ) = 1 N ∑ i = 1 N x ^ i 2 = 1 N ∑ j = 1 m x ^ j n j E(\hat x_i^2) =\frac{1}{N}\sum_{i=1}^N\hat x_i^2=\frac{1}{N}\sum_{j=1}^m\hat x_jn_j E(x^i2)=N1i=1∑Nx^i2=N1j=1∑mx^jnj
同时,有
E ( x ^ i ) = 1 N ∑ i = 1 N x ^ i = μ E(\hat x_i) =\frac{1}{N}\sum_{i=1}^N\hat x_i=\mu E(x^i)=N1i=1∑Nx^i=μ
可以推得
∑ i = 1 N x ^ i = N μ \sum_{i=1}^N\hat x_i=N\mu i=1∑Nx^i=Nμ
b) 期望与方差的关系式
这里需要引用方差和期望的一些关系 。
D ( x ^ i ) = E { [ x ^ i − E ( x ^ i ) ] 2 } = E { x ^ i 2 − 2 x ^ i μ + μ 2 } = E ( x ^ i 2 ) − 2 μ ⋅ E ( x ^ i ) + μ 2 = E ( x ^ i 2 ) − μ 2 = σ 2 \begin{aligned}D(\hat x_i)&=E\{[\hat x_i-E(\hat x_i)]^2\}\\ &=E\{\hat x_i^2-2\hat x_i\mu+\mu^2\}\\ &=E(\hat x_i^2)-2\mu\cdot E(\hat x_i)+\mu^2\\ &=E(\hat x_i^2)-\mu^2=\sigma^2 \end{aligned} D(x^i)=E{[x^i−E(x^i)]2}=E{x^i2−2x^iμ+μ2}=E(x^i2)−2μ⋅E(x^i)+μ2=E(x^i2)−μ2=σ2
同时,应用a),有
E ( x ^ i 2 ) = μ 2 + σ 2 = [ E ( x ^ i ) ] 2 + D ( x ^ i ) = 1 N ∑ i = 1 N x ^ i 2 E(\hat x_i^2)=\mu^2+\sigma^2=[E(\hat x_i)]^2+D(\hat x_i) = \frac{1}{N}\sum_{i=1}^N\hat x_i^2 E(x^i2)=μ2+σ2=[E(x^i)]2+D(x^i)=N1i=1∑Nx^i2
那么
∑ i = 1 N x ^ i 2 = N μ 2 + N σ 2 \sum_{i=1}^N\hat x_i^2=N\mu^2+N\sigma^2 i=1∑Nx^i2=Nμ2+Nσ2
应用上述公式,那么均值方差如下式
D ( x ‾ ) = 1 m 2 ∑ i = 1 m C o v ( x ^ i , x ^ i ) + 1 m 2 ∑ i = 1 m ∑ j ≠ i m C o v ( x ^ i , x ^ j ) = 1 m 2 m σ 2 − 1 m 2 ∑ i = 1 m ∑ j ≠ i m 1 N − 1 σ 2 = 1 m σ 2 − 1 m 2 m ( m − 1 ) 1 N − 1 σ 2 = 1 m σ 2 ( 1 − m − 1 N − 1 ) \begin{aligned}D(\overline x)&=\frac{1}{m^2}\sum_{i=1}^m\mathbf {Cov}(\hat x_i,\hat x_i)+\frac{1}{m^2}\sum_{i=1}^m\sum_{j\neq i}^m\mathbf {Cov}(\hat x_i,\hat x_j)\\ &=\frac{1}{m^2}m\sigma^2-\frac{1}{m^2}\sum_{i=1}^m\sum_{j\neq i}^m\frac{1}{N-1}\sigma^2\\ &=\frac{1}{m}\sigma^2-\frac{1}{m^2}m(m-1)\frac{1}{N-1}\sigma^2\\ &=\frac{1}{m}\sigma^2(1-\frac{m-1}{N-1}) \end{aligned} D(x)=m21i=1∑mCov(x^i,x^i)+m21i=1∑mj=i∑mCov(x^i,x^j)=m21mσ2−m21i=1∑mj=i∑mN−11σ2=m1σ2−m21m(m−1)N−11σ2=m1σ2(1−N−1m−1)
从上式可以看到 ( 1 − m − 1 N − 1 ) (1-\frac{m-1}{N-1}) (1−N−1m−1)就是重复抽样和非重复抽样的区别,当母体样本非常非常大时,该式趋于1,这也是可以理解的,我们从大样本中抽除一个数,几乎不影响其概率特性。
3.2 估计母体样本方差
方差是一个重要的参数,因此通过抽样调查得到的样本数据来估计母体样本的方差将是一项重要的任务。回顾母体方差是随机变量与母体样本均值偏离的平方平均,所以很自然的用同样的方式来估计,也就是用抽样样本均值的平方偏离的平均来估计:
σ ^ 2 = 1 m ∑ i = 1 m ( x ^ i − x ‾ ) 2 \hat\sigma^2=\frac{1}{m}\sum_{i=1}^m(\hat x_i-\overline x)^2 σ^2=m1i=1∑m(x^i−x)2
那么,用抽样样本的数据计算的 σ ^ 2 \hat\sigma^2 σ^2,我们用它来评估母体样本的数字特征,是否具备的代表性或者有效性。也就是说有没有产生系统性偏差,即是否是无偏估计,如果是无偏估计,那么有 E ( σ ^ 2 ) = σ 2 E(\hat\sigma^2)=\sigma^2 E(σ^2)=σ2,否则, E ( σ ^ 2 ) ≠ σ 2 E(\hat\sigma^2)\neq\sigma^2 E(σ^2)=σ2。
E ( σ ^ 2 ) = E { 1 m ∑ i = 1 m ( x ^ i − x ‾ ) 2 } = E { 1 m ∑ i = 1 m x ^ i 2 − 1 m ∑ i = 1 m 2 ⋅ x ^ i x ‾ + 1 m ∑ i = 1 m x ‾ 2 } = E { 1 m ∑ i = 1 m x ^ i 2 } − E { 2 x ‾ ⋅ 1 m ∑ i = 1 m x ^ i } + E { 1 m ∑ i = 1 m x ‾ 2 } = 1 m ∑ i = 1 m E ( x ^ i 2 ) − E ( 2 x ‾ ⋅ x ‾ ) + E ( 1 m ⋅ m x ‾ 2 ) = 1 m ∑ i = 1 m E ( x ^ i 2 ) − E ( x ‾ 2 ) \begin{aligned}E(\hat\sigma^2)&=E\{\frac{1}{m}\sum_{i=1}^m(\hat x_i-\overline x)^2\}\\ &=E\{\frac{1}{m}\sum_{i=1}^m \hat x_i^2 - \frac{1}{m}\sum_{i=1}^m 2\cdot\hat x_i\overline x+\frac{1}{m}\sum_{i=1}^m \overline x^2\}\\ &=E\{\frac{1}{m}\sum_{i=1}^m \hat x_i^2\}-E\{2\overline x\cdot \frac{1}{m}\sum_{i=1}^m\hat x_i\}+E\{\frac{1}{m}\sum_{i=1}^m \overline x^2\}\\ &=\frac{1}{m}\sum_{i=1}^mE( \hat x_i^2) - E(2\overline x\cdot \overline x) + E(\frac{1}{m}\cdot m \overline x^2)\\ &=\frac{1}{m}\sum_{i=1}^mE( \hat x_i^2)-E(\overline x^2) \end{aligned} E(σ^2)=E{m1i=1∑m(x^i−x)2}=E{m1i=1∑mx^i2−m1i=1∑m2⋅x^ix+m1i=1∑mx2}=E{m1i=1∑mx^i2}−E{2x⋅m1i=1∑mx^i}+E{m1i=1∑mx2}=m1i=1∑mE(x^i2)−E(2x⋅x)+E(m1⋅mx2)=m1i=1∑mE(x^i2)−E(x2)
同时
E ( x ^ i 2 ) = [ E ( x ^ i ) ] 2 + D ( x ^ i ) = μ 2 + σ 2 E(\hat x_i^2)=[E(\hat x_i)]^2+D(\hat x_i)=\mu^2+\sigma^2 E(x^i2)=[E(x^i)]2+D(x^i)=μ2+σ2
E ( x ‾ i 2 ) = [ E ( x ‾ i ) ] 2 + D ( x ‾ i ) E(\overline x_i^2)=[E(\overline x_i)]^2+D(\overline x_i) E(xi2)=[E(xi)]2+D(xi)
E ( x ‾ i 2 ) E(\overline x_i^2) E(xi2)分两种情况,重复抽样或者非重复抽样,那么如果是重复抽样,则
a) 重复抽样
E ( x ‾ i 2 ) = [ E ( x ‾ i ) ] 2 + D ( x ‾ i ) = μ 2 + σ 2 m E(\overline x_i^2)=[E(\overline x_i)]^2+D(\overline x_i)=\mu^2+\frac{\sigma^2}{m} E(xi2)=[E(xi)]2+D(xi)=μ2+mσ2
E ( σ ^ 2 ) = 1 m ∑ i = 1 m E ( x ^ i 2 ) − E ( x ‾ 2 ) = 1 m ∑ i = 1 m ( μ 2 + σ 2 ) − ( μ 2 + σ 2 m ) = ( μ 2 + σ 2 ) − ( μ 2 + σ 2 m ) = m − 1 m σ 2 ≠ σ 2 \begin{aligned}E(\hat\sigma^2)&=\frac{1}{m}\sum_{i=1}^mE( \hat x_i^2)-E(\overline x^2)\\ &=\frac{1}{m}\sum_{i=1}^m(\mu^2+\sigma^2) - (\mu^2+\frac{\sigma^2}{m})\\ &=(\mu^2+\sigma^2) - (\mu^2+\frac{\sigma^2}{m})\\ &=\frac{m-1}{m}\sigma^2\neq \sigma^2 \end{aligned} E(σ^2)=m1i=1∑mE(x^i2)−E(x2)=m1i=1∑m(μ2+σ2)−(μ2+mσ2)=(μ2+σ2)−(μ2+mσ2)=mm−1σ2=σ2
因此,用 σ ^ 2 \hat\sigma^2 σ^2来估计 σ 2 \sigma^2 σ2,有系统性偏差,即是有偏估计。当然也不难推得, m m − 1 σ ^ 2 = 1 m − 1 ∑ i = 1 m ( x ^ i − x ‾ ) 2 \frac{m}{m-1}\hat\sigma^2=\frac{1}{m-1}\sum_{i=1}^m(\hat x_i-\overline x)^2 m−1mσ^2=m−11∑i=1m(x^i−x)2是 σ 2 \sigma^2 σ2的无偏估计。
如果是非重复抽样,则
b) 非重复抽样
E ( x ‾ i 2 ) = [ E ( x ‾ i ) ] 2 + D ( x ‾ i ) = μ 2 + σ 2 m ( 1 − m − 1 N − 1 ) E(\overline x_i^2)=[E(\overline x_i)]^2+D(\overline x_i)=\mu^2+\frac{\sigma^2}{m}(1-\frac{m-1}{N-1}) E(xi2)=[E(xi)]2+D(xi)=μ2+mσ2(1−N−1m−1)
E ( σ ^ 2 ) = 1 m ∑ i = 1 m E ( x ^ i 2 ) − E ( x ‾ 2 ) = 1 m ∑ i = 1 m ( μ 2 + σ 2 ) − [ μ 2 + σ 2 m ( 1 − m − 1 N − 1 ) ] = ( μ 2 + σ 2 ) − [ μ 2 + σ 2 m ( 1 − m − 1 N − 1 ) ] = m − 1 m σ 2 ( 1 − m − 1 N − 1 ) ≠ σ 2 \begin{aligned}E(\hat\sigma^2)&=\frac{1}{m}\sum_{i=1}^mE( \hat x_i^2)-E(\overline x^2)\\ &=\frac{1}{m}\sum_{i=1}^m(\mu^2+\sigma^2) - [\mu^2+\frac{\sigma^2}{m}(1-\frac{m-1}{N-1})]\\ &=(\mu^2+\sigma^2) - [\mu^2+\frac{\sigma^2}{m}(1-\frac{m-1}{N-1})]\\ &=\frac{m-1}{m}\sigma^2(1-\frac{m-1}{N-1})\neq \sigma^2 \end{aligned} E(σ^2)=m1i=1∑mE(x^i2)−E(x2)=m1i=1∑m(μ2+σ2)−[μ2+mσ2(1−N−1m−1)]=(μ2+σ2)−[μ2+mσ2(1−N−1m−1)]=mm−1σ2(1−N−1m−1)=σ2
同样,此时 σ ^ 2 \hat\sigma^2 σ^2也是 σ 2 \sigma^2 σ2有偏估计,当然也不难推得, m m − 1 N − 1 N − m σ ^ 2 = 1 m − 1 N − 1 N − m ∑ i = 1 m ( x ^ i − x ‾ ) 2 \frac{m}{m-1}\frac{N-1}{N-m}\hat\sigma^2=\frac{1}{m-1}\frac{N-1}{N-m}\sum_{i=1}^m(\hat x_i-\overline x)^2 m−1mN−mN−1σ^2=m−11N−mN−1∑i=1m(x^i−x)2是 σ 2 \sigma^2 σ2的无偏估计。