python多进程运算multiprocessing包与并行计算举例
目录
- 案例
- 理论介绍(深入浅出)
-
- 1. 多进程是什么
- 2. 为什么需要多进程
- 3. 用Python执行多进程
- 4. 再举一例
- 5. 并行计算
案例
理论介绍(深入浅出)
1. 多进程是什么
多进程指的是操作系统同时支持多个处理器的能力。在支持多任务操作系统中,一个应用程序会被分解成多个独立运行的较小的程序。操作系统会将这些线程分配到多核处理器,以提升系统性能。
2. 为什么需要多进程
假设我们的计算机只有一个单核的处理器,然后同时被分配了几个任务,那么它就不得不在各个任务中来回切换,短暂地执行其中一个任务,然后中断,然后短暂地执行下一个任务,以保持所有的进程都在运行。这就像一个厨师在做面条,切几秒钟菜,跑去揉几下面,再赶紧查看下汤。
所以同时需要完成的任务越多,同时跟踪所有的任务就越困难。这就是多进程的必要性,也是多核处理器的威力所在。
一个支持多进程的操作系统可以做到:
- 同时指挥多个 CPU(多个核),即拥有一个以上的 CPU 的计算机
- 指挥多核 CPU,即拥有两个及以上的独立处理单元的 CPU
这样,计算机就可以轻松地同时执行多个任务,每个任务都可以使用自己的处理器。就像之前举的例子,现在厨房里有专门的揉面师傅,备菜师傅,煮汤师傅。事情就变得轻松多了。
3. 用Python执行多进程
学习Python的优势之一就是它拥有海量的第三方模块。
今天我们再来介绍一个能帮你轻松完成多进程并行的模块:multiprocessing
multiprocessing 模块支持使用类似于 threading 模块的 API 生成进程。multiprocessing 模块提供了本地和远程计算机的并行处理能力,并且通过使用创建子进程,有效地避开了全局解释器锁(GIL)。因此,multiprocessing 模块允许程序员充分利用机器上的多个处理器。目前,它可以在 Unix 和 Windows 上运行。
multiprocessing 的模块的 API 非常简单直观,可以让新手迅速上手在多个进程之间划分工作。我们现在看一个简单的例子:
# importing the multiprocessing module
import multiprocessing
def print_cube(num):
print("Cube: {}".format(num * num * num))
def print_square(num):
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating processes
p1 = multiprocessing.Process(target=print_square, args=(10, ))
p2 = multiprocessing.Process(target=print_cube, args=(10, ))
# starting process 1&2
p1.start()
p2.start()
# wait until process 1&2 is finished
p1.join()
p2.join()
# both processes finished
print("Done!")
运行结果是这样的:
Square: 100
Cube: 1000
Done!
其实代码的含义非常简单了,首先我们导入了 multiprocessing 模块,随后定义了两个函数,它们的功能分别是打印一个数的三次方和打印一个数的平方。
之后关键的步骤来了,要创建多个进程,首先需要创建 Process 类的对象。在这个例子中 Process 类接收了两个参数:
- target:在进程中被执行的函数
- args:向被执行函数传递的参数
当然,进程构造函数还可以接受许多其他参数,我们之后会更详细地介绍。
在上面的例子中,我们创建了两个具有不同目标函数的进程:
p1 = multiprocessing.Process(target=print_square, args=(10, ))
p2 = multiprocessing.Process(target=print_cube, args=(10, ))
随后的 start() 方法就是开始执行 p1,p2 两个进程。在进程开始执行后,主程序仍然会继续执行。为了让主程序暂停,我们就使用了**join()**方法。它的作用就是将主程序暂停,直到等待 p1 和 p2 完成。一旦它们都完成了,再执行之后的语句。
4. 再举一例
让我们再举一个例子,来理解 同一个脚本中运行不同进程 的概念。在下面的例子中,我们打印运行目标函数的进程 ID:
# importing the multiprocessing module
import multiprocessing
import os
def worker1():
# printing process id
print("ID of process running worker1: {}".format(os.getpid()))
def worker2():
# printing process id
print("ID of process running worker2: {}".format(os.getpid()))
if __name__ == "__main__":
# printing main program process id
print("ID of main process: {}".format(os.getpid()))
# creating processes
p1 = multiprocessing.Process(target=worker1)
p2 = multiprocessing.Process(target=worker2)
# starting processes
p1.start()
p2.start()
# process IDs
print("ID of process p1: {}".format(p1.pid))
print("ID of process p2: {}".format(p2.pid))
# wait until processes are finished
p1.join()
p2.join()
# both processes finished
print("Both processes finished execution!")
# check if processes are alive
print("Process p1 is alive: {}".format(p1.is_alive()))
print("Process p2 is alive: {}".format(p2.is_alive()))
上面这个程序的输出结果如下:
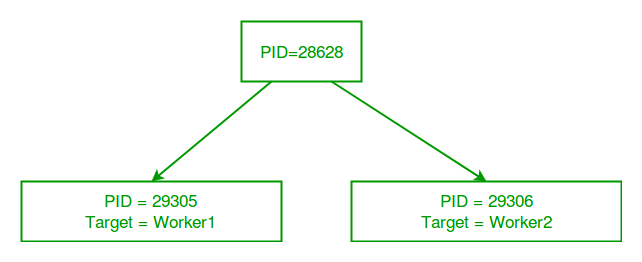
ID of main process: 28628
ID of process running worker1: 29305
ID of process running worker2: 29306
ID of process p1: 29305
ID of process p2: 29306
Both processes finished execution!
Process p1 is alive: False
Process p2 is alive: False
主 python 脚本有一个独立的进程 ID,当我们创建进程对象 p1 和 p2 时,multiprocessing 模块会生成具有不同进程 ID 的新进程。os.getpid() 函数是用来获取运行当前目标函数的进程的 ID。上述输出结果也可以看到,使用 os.getpid() 获取的进程 ID 与通过进程类的 pid 属性获得的 ID 是一致的。
上面的每个进程都是独立运行的,并且拥有自己独立的内存空间。
一旦目标函数执行完成,进程就会终止。在上面的程序中,我们使用了 Process 类的 is_alive() 方法来检查进程是否仍然处于活动状态。
最后用下面的图来帮助理解记忆 新进程 与主 Python 脚本的不同之处:
5. 并行计算
import os
import multiprocessing
def process_data(workdir, ens_str, outfile):
processes, ans = [], []
file_pattern = os.path.join(workdir, f"*.{ens_str}")
files = glob(file_pattern)
pool = multiprocessing.Pool(processes=4)
for file in tqdm(files, total=len(files)):
processes.append(pool.apply_async(process_file, args=(file, ens_str), ))
for process in processes:
data = process.get()
ans.append(data)
pool.close()
pool.join()
def process_file(file, ens_str): # ens_str 文件名后缀
xxx
参考资料:
[1] Python多进程运行——Multiprocessing基础教程1 2020.8;