使用YOLOv5的backbone网络识别图像天气 - P9
目录
- 环境
- 步骤
-
- 环境设置
-
- 包引用
- 声明一个全局的设备
- 数据准备
-
- 收集数据集信息
- 构建数据集
- 在数据集中读取分类名称
- 划分训练、测试数据集
- 数据集划分批次
- 模型设计
-
- 编写维持卷积前后图像大小不变的padding计算函数
- 编写YOLOv5中使用的卷积模块
- 编写YOLOv5中使用的Bottleneck模块
- 编写YOLOv5中使用的C3模块
- 编写YOLOv5中使用SPPF模块
- 基于以上模块编写本任务需要的网络结构
- 模型训练
-
- 编写训练函数
- 开始模型的训练
- 训练过程图表展示
- 模型效果展示
-
- 载入最佳模型
- 编写预测函数
- 执行预测并展示
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
步骤
环境设置
包引用
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
import pathlib, random, copy
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from torchinfo import summary
声明一个全局的设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
收集数据集信息
# 图像数据的路径
image_path = 'weather_photos'
# 所有图像的列表
image_list = list(pathlib.Path(image_path).glob('*/*'))
# 随机打印几张图像的信息
for _ in range(5):
image = random.choice(image_list)
print(f"{str(image)}, shape is: {np.array(Image.open(str(image))).shape}")
# 查看随机的20张图像
plt.figure(figsize=(20, 4))
for i in range(20):
plt.subplot(2, 10, i+1)
plt.axis('off')
image = random.choice(image_list)
plt.title(image.parts[-2])
plt.imshow(Image.open(str(image)))


通过图像信息的获取可以发现图像的尺寸并不一致,因此需要在构建数据集的时候对图像做一些伸缩处理。
构建数据集
img_transform = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
dataset = datasets.ImageFolder(image_path, transform=img_transform)
在数据集中读取分类名称
class_names = [k for k in dataset.class_to_idx]
print(class_names)
划分训练、测试数据集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
数据集划分批次
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
编写维持卷积前后图像大小不变的padding计算函数
def pad(kernel_size, padding=None):
if padding is None:
return kernel_size // 2 if isinstance(kernel_size, int) else [item //2 for item in kernel_size]
return padding
编写YOLOv5中使用的卷积模块
class Conv(nn.Module):
def __init__(self, ch_in, ch_out, kernel_size, stride=1, padding=None, groups=1, activation=True):
super().__init__()
self.conv = nn.Conv2d(ch_in, ch_out, kernel_size, stride, pad(kernel_size, padding), groups=groups, bias=False)
self.bn = nn.BatchNorm2d(ch_out)
self.act = nn.SiLU() if activation is True else (activation if isinstance(activation, nn.Module) else nn.Identity())
def forward(self, x):
x = self.act(self.bn(self.conv(x)))
return x
编写YOLOv5中使用的Bottleneck模块
class Bottleneck(nn.Module):
def __init__(self, ch_in, ch_out, shortcut=True, groups=1, factor=0.5):
super().__init__()
hidden_size = int(ch_out*factor)
self.conv1 = Conv(ch_in, hidden_size, 1)
self.conv2 = Conv(hidden_size, ch_out, 3)
self.add = shortcut and ch_in == ch_out
def forward(self, x):
return x + self.conv2(self.conv1(x)) if self.add else self.conv2(self.conv1(x))
编写YOLOv5中使用的C3模块
class C3(nn.Module):
def __init__(self, ch_in, ch_out, n=1, shortcut=True, groups=1, factor=0.5):
super().__init__()
hidden_size = int(ch_out*factor)
self.conv1 = Conv(ch_in, hidden_size, 1)
self.conv2 = Conv(ch_in, hidden_size, 1)
self.conv3 = Conv(2*hidden_size, ch_out, 1)
self.m = nn.Sequential(*(Bottleneck(hidden_size, hidden_size) for _ in range(n)))
def forward(self, x):
return self.conv3(torch.cat((self.conv1(x), self.m(self.conv2(x))), dim=1))
编写YOLOv5中使用SPPF模块
class SPPF(nn.Module):
def __init__(self, ch_in, ch_out, kernel_size=5):
super().__init__()
hidden_size = ch_in // 2
self.conv1 = Conv(ch_in, hidden_size, 1)
self.conv2 = Conv(4*hidden_size, ch_out, 1)
self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size//2)
def forward(self, x):
x = self.conv1(x)
y1 = self.m(x)
y2 = self.m(y1)
y3 = self.m(y2)
return self.conv2(torch.cat([x, y1, y2, y3], dim=1))
基于以上模块编写本任务需要的网络结构
class Network(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv1 = Conv(3, 64, 3, 2, 2)
self.conv2 = Conv(64, 128, 3, 2)
self.c3_1 = C3(128, 128)
self.conv3 = Conv(128, 256, 3, 2)
self.c3_2 = C3(256, 256)
self.conv4 = Conv(256, 512, 3, 2)
self.c3_3 = C3(512, 512)
self.conv5 = Conv(512, 1024, 3, 2)
self.c3_4 = C3(1024, 1024)
self.sppf = SPPF(1024, 1024, 5)
self.classifier = nn.Sequential(
nn.Linear(65536, 100),
nn.ReLU(),
nn.Linear(100, num_classes)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.c3_1(x)
x = self.conv3(x)
x = self.c3_2(x)
x = self.conv4(x)
x = self.c3_3(x)
x = self.conv5(x)
x = self.c3_4(x)
x = self.sppf(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model = Network(len(class_names)).to(device)
print(model)
summary(model, input_size=(32, 3, 224, 224))
直接打印出的模型结构如下:
Network(
(conv1): Conv(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(c3_1): C3(
(conv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(conv1): Conv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(conv3): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(c3_2): C3(
(conv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(conv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(conv4): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(c3_3): C3(
(conv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(conv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(conv5): Conv(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(c3_4): C3(
(conv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv3): Conv(
(conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(conv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(sppf): SPPF(
(conv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(conv2): Conv(
(conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=65536, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)
torchinfo库中的summary函数打印的结果如下:
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Network [32, 4] --
├─Conv: 1-1 [32, 64, 113, 113] --
│ └─Conv2d: 2-1 [32, 64, 113, 113] 1,728
│ └─BatchNorm2d: 2-2 [32, 64, 113, 113] 128
│ └─SiLU: 2-3 [32, 64, 113, 113] --
├─Conv: 1-2 [32, 128, 57, 57] --
│ └─Conv2d: 2-4 [32, 128, 57, 57] 73,728
│ └─BatchNorm2d: 2-5 [32, 128, 57, 57] 256
│ └─SiLU: 2-6 [32, 128, 57, 57] --
├─C3: 1-3 [32, 128, 57, 57] --
│ └─Conv: 2-7 [32, 64, 57, 57] --
│ │ └─Conv2d: 3-1 [32, 64, 57, 57] 8,192
│ │ └─BatchNorm2d: 3-2 [32, 64, 57, 57] 128
│ │ └─SiLU: 3-3 [32, 64, 57, 57] --
│ └─Conv: 2-8 [32, 64, 57, 57] --
│ │ └─Conv2d: 3-4 [32, 64, 57, 57] 8,192
│ │ └─BatchNorm2d: 3-5 [32, 64, 57, 57] 128
│ │ └─SiLU: 3-6 [32, 64, 57, 57] --
│ └─Sequential: 2-9 [32, 64, 57, 57] --
│ │ └─Bottleneck: 3-7 [32, 64, 57, 57] 20,672
│ └─Conv: 2-10 [32, 128, 57, 57] --
│ │ └─Conv2d: 3-8 [32, 128, 57, 57] 16,384
│ │ └─BatchNorm2d: 3-9 [32, 128, 57, 57] 256
│ │ └─SiLU: 3-10 [32, 128, 57, 57] --
├─Conv: 1-4 [32, 256, 29, 29] --
│ └─Conv2d: 2-11 [32, 256, 29, 29] 294,912
│ └─BatchNorm2d: 2-12 [32, 256, 29, 29] 512
│ └─SiLU: 2-13 [32, 256, 29, 29] --
├─C3: 1-5 [32, 256, 29, 29] --
│ └─Conv: 2-14 [32, 128, 29, 29] --
│ │ └─Conv2d: 3-11 [32, 128, 29, 29] 32,768
│ │ └─BatchNorm2d: 3-12 [32, 128, 29, 29] 256
│ │ └─SiLU: 3-13 [32, 128, 29, 29] --
│ └─Conv: 2-15 [32, 128, 29, 29] --
│ │ └─Conv2d: 3-14 [32, 128, 29, 29] 32,768
│ │ └─BatchNorm2d: 3-15 [32, 128, 29, 29] 256
│ │ └─SiLU: 3-16 [32, 128, 29, 29] --
│ └─Sequential: 2-16 [32, 128, 29, 29] --
│ │ └─Bottleneck: 3-17 [32, 128, 29, 29] 82,304
│ └─Conv: 2-17 [32, 256, 29, 29] --
│ │ └─Conv2d: 3-18 [32, 256, 29, 29] 65,536
│ │ └─BatchNorm2d: 3-19 [32, 256, 29, 29] 512
│ │ └─SiLU: 3-20 [32, 256, 29, 29] --
├─Conv: 1-6 [32, 512, 15, 15] --
│ └─Conv2d: 2-18 [32, 512, 15, 15] 1,179,648
│ └─BatchNorm2d: 2-19 [32, 512, 15, 15] 1,024
│ └─SiLU: 2-20 [32, 512, 15, 15] --
├─C3: 1-7 [32, 512, 15, 15] --
│ └─Conv: 2-21 [32, 256, 15, 15] --
│ │ └─Conv2d: 3-21 [32, 256, 15, 15] 131,072
│ │ └─BatchNorm2d: 3-22 [32, 256, 15, 15] 512
│ │ └─SiLU: 3-23 [32, 256, 15, 15] --
│ └─Conv: 2-22 [32, 256, 15, 15] --
│ │ └─Conv2d: 3-24 [32, 256, 15, 15] 131,072
│ │ └─BatchNorm2d: 3-25 [32, 256, 15, 15] 512
│ │ └─SiLU: 3-26 [32, 256, 15, 15] --
│ └─Sequential: 2-23 [32, 256, 15, 15] --
│ │ └─Bottleneck: 3-27 [32, 256, 15, 15] 328,448
│ └─Conv: 2-24 [32, 512, 15, 15] --
│ │ └─Conv2d: 3-28 [32, 512, 15, 15] 262,144
│ │ └─BatchNorm2d: 3-29 [32, 512, 15, 15] 1,024
│ │ └─SiLU: 3-30 [32, 512, 15, 15] --
├─Conv: 1-8 [32, 1024, 8, 8] --
│ └─Conv2d: 2-25 [32, 1024, 8, 8] 4,718,592
│ └─BatchNorm2d: 2-26 [32, 1024, 8, 8] 2,048
│ └─SiLU: 2-27 [32, 1024, 8, 8] --
├─C3: 1-9 [32, 1024, 8, 8] --
│ └─Conv: 2-28 [32, 512, 8, 8] --
│ │ └─Conv2d: 3-31 [32, 512, 8, 8] 524,288
│ │ └─BatchNorm2d: 3-32 [32, 512, 8, 8] 1,024
│ │ └─SiLU: 3-33 [32, 512, 8, 8] --
│ └─Conv: 2-29 [32, 512, 8, 8] --
│ │ └─Conv2d: 3-34 [32, 512, 8, 8] 524,288
│ │ └─BatchNorm2d: 3-35 [32, 512, 8, 8] 1,024
│ │ └─SiLU: 3-36 [32, 512, 8, 8] --
│ └─Sequential: 2-30 [32, 512, 8, 8] --
│ │ └─Bottleneck: 3-37 [32, 512, 8, 8] 1,312,256
│ └─Conv: 2-31 [32, 1024, 8, 8] --
│ │ └─Conv2d: 3-38 [32, 1024, 8, 8] 1,048,576
│ │ └─BatchNorm2d: 3-39 [32, 1024, 8, 8] 2,048
│ │ └─SiLU: 3-40 [32, 1024, 8, 8] --
├─SPPF: 1-10 [32, 1024, 8, 8] --
│ └─Conv: 2-32 [32, 512, 8, 8] --
│ │ └─Conv2d: 3-41 [32, 512, 8, 8] 524,288
│ │ └─BatchNorm2d: 3-42 [32, 512, 8, 8] 1,024
│ │ └─SiLU: 3-43 [32, 512, 8, 8] --
│ └─MaxPool2d: 2-33 [32, 512, 8, 8] --
│ └─MaxPool2d: 2-34 [32, 512, 8, 8] --
│ └─MaxPool2d: 2-35 [32, 512, 8, 8] --
│ └─Conv: 2-36 [32, 1024, 8, 8] --
│ │ └─Conv2d: 3-44 [32, 1024, 8, 8] 2,097,152
│ │ └─BatchNorm2d: 3-45 [32, 1024, 8, 8] 2,048
│ │ └─SiLU: 3-46 [32, 1024, 8, 8] --
├─Sequential: 1-11 [32, 4] --
│ └─Linear: 2-37 [32, 100] 6,553,700
│ └─ReLU: 2-38 [32, 100] --
│ └─Linear: 2-39 [32, 4] 404
===============================================================================================
Total params: 19,987,832
Trainable params: 19,987,832
Non-trainable params: 0
Total mult-adds (G): 64.43
===============================================================================================
Input size (MB): 19.27
Forward/backward pass size (MB): 2027.63
Params size (MB): 79.95
Estimated Total Size (MB): 2126.85
===============================================================================================
模型训练
编写训练函数
def train(train_loader, model, loss_fn, optimizer):
model.train()
train_loss, train_acc = 0, 0
num_batches = len(train_loader)
size = len(train_loader.dataset)
for x, y in train_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_loss, train_acc
def test(test_loader, model, loss_fn):
model.eval()
test_loss, test_acc = 0, 0
num_batches = len(test_loader)
size = len(test_loader.dataset)
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
test_loss += loss.item()
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
test_acc /= size
return test_loss, test_acc
开始模型的训练
epochs = 60
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
best_acc = 0
best_model_path = 'best_p9_model.pth'
train_loss, train_acc = [], []
test_loss, test_acc = [], []
for epoch in range(epochs):
epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)
epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)
if best_acc < epoch_test_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_loss.append(epoch_train_loss)
train_acc.append(epoch_train_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
lr = optimizer.state_dict()['param_groups'][0]['lr']
print(f"Epoch: {epoch+1}, TrainLoss: {epoch_train_loss:.3f}, TrainAcc: {epoch_train_acc*100:.1f},TestLoss: {epoch_test_loss:.3f}, TestAcc: {epoch_test_acc*100:.1f}, learning_rate: {lr}")
print(f"training finished, save best model to : {best_model_path})")
torch.save(best_model.state_dict(), best_model_path)
print("done")
训练过程打印日志如下
Epoch: 1, TrainLoss: 0.986, TrainAcc: 57.2,TestLoss: 2.137, TestAcc: 25.3, learning_rate: 0.0001
Epoch: 2, TrainLoss: 0.725, TrainAcc: 76.2,TestLoss: 0.486, TestAcc: 87.6, learning_rate: 0.0001
Epoch: 3, TrainLoss: 0.368, TrainAcc: 84.7,TestLoss: 0.310, TestAcc: 87.6, learning_rate: 0.0001
Epoch: 4, TrainLoss: 0.295, TrainAcc: 89.9,TestLoss: 0.329, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 5, TrainLoss: 0.407, TrainAcc: 87.2,TestLoss: 0.288, TestAcc: 88.9, learning_rate: 0.0001
Epoch: 6, TrainLoss: 0.316, TrainAcc: 89.4,TestLoss: 0.354, TestAcc: 89.8, learning_rate: 0.0001
Epoch: 7, TrainLoss: 0.347, TrainAcc: 92.1,TestLoss: 0.244, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 8, TrainLoss: 0.206, TrainAcc: 93.1,TestLoss: 0.313, TestAcc: 94.2, learning_rate: 0.0001
Epoch: 9, TrainLoss: 0.204, TrainAcc: 92.4,TestLoss: 0.227, TestAcc: 90.2, learning_rate: 0.0001
Epoch: 10, TrainLoss: 0.151, TrainAcc: 95.4,TestLoss: 0.242, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 11, TrainLoss: 0.146, TrainAcc: 95.6,TestLoss: 0.314, TestAcc: 88.9, learning_rate: 0.0001
Epoch: 12, TrainLoss: 0.223, TrainAcc: 91.7,TestLoss: 0.769, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 13, TrainLoss: 0.155, TrainAcc: 95.2,TestLoss: 0.223, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 14, TrainLoss: 0.267, TrainAcc: 93.9,TestLoss: 0.280, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 15, TrainLoss: 0.194, TrainAcc: 93.3,TestLoss: 0.345, TestAcc: 89.3, learning_rate: 0.0001
Epoch: 16, TrainLoss: 0.283, TrainAcc: 91.3,TestLoss: 0.267, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 17, TrainLoss: 0.183, TrainAcc: 94.3,TestLoss: 1.779, TestAcc: 84.4, learning_rate: 0.0001
Epoch: 18, TrainLoss: 0.161, TrainAcc: 95.7,TestLoss: 0.279, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 19, TrainLoss: 0.100, TrainAcc: 95.7,TestLoss: 0.249, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 20, TrainLoss: 0.134, TrainAcc: 97.0,TestLoss: 0.252, TestAcc: 91.1, learning_rate: 0.0001
Epoch: 21, TrainLoss: 0.236, TrainAcc: 94.0,TestLoss: 0.264, TestAcc: 88.0, learning_rate: 0.0001
Epoch: 22, TrainLoss: 0.199, TrainAcc: 93.1,TestLoss: 0.251, TestAcc: 94.7, learning_rate: 0.0001
Epoch: 23, TrainLoss: 0.243, TrainAcc: 95.2,TestLoss: 0.425, TestAcc: 88.0, learning_rate: 0.0001
Epoch: 24, TrainLoss: 0.181, TrainAcc: 94.8,TestLoss: 0.390, TestAcc: 86.7, learning_rate: 0.0001
Epoch: 25, TrainLoss: 0.138, TrainAcc: 97.4,TestLoss: 0.337, TestAcc: 91.1, learning_rate: 0.0001
Epoch: 26, TrainLoss: 0.212, TrainAcc: 96.6,TestLoss: 0.358, TestAcc: 90.2, learning_rate: 0.0001
Epoch: 27, TrainLoss: 0.289, TrainAcc: 92.4,TestLoss: 0.239, TestAcc: 94.2, learning_rate: 0.0001
Epoch: 28, TrainLoss: 0.220, TrainAcc: 95.6,TestLoss: 0.280, TestAcc: 88.4, learning_rate: 0.0001
Epoch: 29, TrainLoss: 0.177, TrainAcc: 95.6,TestLoss: 0.216, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 30, TrainLoss: 0.116, TrainAcc: 96.3,TestLoss: 0.240, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 31, TrainLoss: 0.065, TrainAcc: 98.0,TestLoss: 0.230, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 32, TrainLoss: 0.097, TrainAcc: 98.0,TestLoss: 0.261, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 33, TrainLoss: 0.084, TrainAcc: 97.9,TestLoss: 0.262, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 34, TrainLoss: 0.113, TrainAcc: 96.2,TestLoss: 0.257, TestAcc: 95.1, learning_rate: 0.0001
Epoch: 35, TrainLoss: 0.071, TrainAcc: 97.8,TestLoss: 0.284, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 36, TrainLoss: 0.238, TrainAcc: 95.2,TestLoss: 0.210, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 37, TrainLoss: 0.175, TrainAcc: 96.9,TestLoss: 0.259, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 38, TrainLoss: 0.129, TrainAcc: 95.8,TestLoss: 0.315, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 39, TrainLoss: 0.077, TrainAcc: 98.0,TestLoss: 0.233, TestAcc: 91.6, learning_rate: 0.0001
Epoch: 40, TrainLoss: 0.092, TrainAcc: 97.3,TestLoss: 0.266, TestAcc: 89.3, learning_rate: 0.0001
Epoch: 41, TrainLoss: 0.064, TrainAcc: 98.0,TestLoss: 0.248, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 42, TrainLoss: 0.062, TrainAcc: 99.2,TestLoss: 0.211, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 43, TrainLoss: 0.098, TrainAcc: 97.2,TestLoss: 0.359, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 44, TrainLoss: 0.153, TrainAcc: 97.0,TestLoss: 0.411, TestAcc: 89.3, learning_rate: 0.0001
Epoch: 45, TrainLoss: 0.234, TrainAcc: 96.9,TestLoss: 0.198, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 46, TrainLoss: 0.042, TrainAcc: 98.6,TestLoss: 0.191, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 47, TrainLoss: 0.033, TrainAcc: 98.9,TestLoss: 0.141, TestAcc: 96.9, learning_rate: 0.0001
Epoch: 48, TrainLoss: 0.012, TrainAcc: 99.7,TestLoss: 0.202, TestAcc: 94.7, learning_rate: 0.0001
Epoch: 49, TrainLoss: 0.016, TrainAcc: 99.1,TestLoss: 0.171, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 50, TrainLoss: 0.011, TrainAcc: 99.6,TestLoss: 0.274, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 51, TrainLoss: 0.014, TrainAcc: 99.8,TestLoss: 0.233, TestAcc: 94.2, learning_rate: 0.0001
Epoch: 52, TrainLoss: 0.263, TrainAcc: 98.7,TestLoss: 0.233, TestAcc: 91.6, learning_rate: 0.0001
Epoch: 53, TrainLoss: 0.284, TrainAcc: 92.7,TestLoss: 0.680, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 54, TrainLoss: 0.334, TrainAcc: 90.9,TestLoss: 0.332, TestAcc: 91.1, learning_rate: 0.0001
Epoch: 55, TrainLoss: 0.261, TrainAcc: 94.4,TestLoss: 0.498, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 56, TrainLoss: 0.144, TrainAcc: 95.9,TestLoss: 0.376, TestAcc: 88.4, learning_rate: 0.0001
Epoch: 57, TrainLoss: 0.080, TrainAcc: 97.3,TestLoss: 0.296, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 58, TrainLoss: 0.033, TrainAcc: 99.2,TestLoss: 0.226, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 59, TrainLoss: 0.023, TrainAcc: 99.0,TestLoss: 0.327, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 60, TrainLoss: 0.073, TrainAcc: 98.0,TestLoss: 0.347, TestAcc: 90.7, learning_rate: 0.0001
training finished, save best model to : best_p9_model.pth)
done
训练过程图表展示
epoch_ranges = range(epochs)
plt.figure(figsize=(20, 4))
plt.subplot(121)
plt.plot(epoch_ranges, train_loss, label='train loss')
plt.plot(epoch_ranges, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.subplot(122)
plt.plot(epoch_ranges, train_acc, label='train accuracy')
plt.plot(epoch_ranges, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
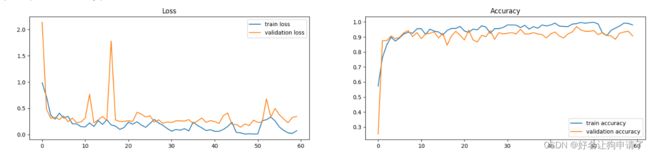
模型效果展示
载入最佳模型
model.load_state_dict(torch.load(best_model_path))
model.to(device)
编写预测函数
def predict(model, image_path):
image = Image.open(image_path)
image = img_transform(image)
image = image.unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
pred = model(image)
return class_names[pred.argmax(1).item()]
执行预测并展示
评估应当只用测试集中的数据,这里没有再使用数据集进行反归一化,会有一部分训练集中的数据参与其中,导致预测的结果非常好(可能是假象)
plt.figure(figsize=(20, 4))
for i in range(20):
plt.subplot(2, 10, i+1)
image = random.choice(image_list)
real_label = image.parts[-2]
pred_label = predict(model, str(image))
plt.title(f"R:{real_label}, P:{pred_label}")
plt.axis('off')
plt.imshow(Image.open(str(image)))

总结与心得体会
- YOLOv5的骨干网络中大量使用了1x1卷积,只用来将特征图重新映射到不同通道的特征图中,执行效率比执行大核卷积快
- 骨干网络中特征图大小的缩减并没用像普通的卷积网络一样使用池化层,而是使用卷积通过调整stride和padding属性来实现,这样做会比直接使用池化层多一些可训练参数,可能会增加一些模型的拟合能力
- 通过本次任务学习到了跳跃连接应该怎样编写代码,还有SPPF模块的实现
- 模型的评估应该不包含训练集中的数据,不然展示的结果并不真实