应用实践 | 10 亿数据秒级关联,货拉拉基于 Apache Doris 的 OLAP 体系演进
分享人|货拉拉大数据引擎负责人 杨秋吉,张斌
业务背景
货拉拉成立于 2013 年,成长于粤港澳大湾区,是一家从事同城、跨城货运、企业版物流服务、搬家、汽车销售及车后市场服务的互联网物流公司。截至 2022 年 4 月,货拉拉的业务范围已经覆盖了国内 352 座城市,月活司机达到 58 万,月活用户达到 760 万,包含 8 条以上的业务线。
货拉拉大数据体系为支撑公司业务,现在已经成立三个 IDC 集群、拥有上千台规模的机器数量,存储量达到了 20PB、日均任务数达到了 20k 以上,并且还处在快速增长的过程中。
大数据体系
货拉拉大数据体系从下往上分为 5 层,最下面的是基础层和接入层,这两层主要会提供基础数据的存储、计算以及集群的管理功能。在基础层和接入层之上是平台层和数仓。在平台层之中包含了数据研发平台和数据治理平台,基于平台层的能力和数据仓库的数据体系,在这之上面包含了含有业务属性的服务层和应用层。整个体系自下而上相互支持,实现支持业务和赋能业务的能力。

图1.1 货拉拉大数据体系>>>数据处理流货拉拉典型的数据处理流,可以分成数据集成、采集、数据的存储计算、数据服务四部分,同时也包含了实时、离线以及在线三大业务场景。
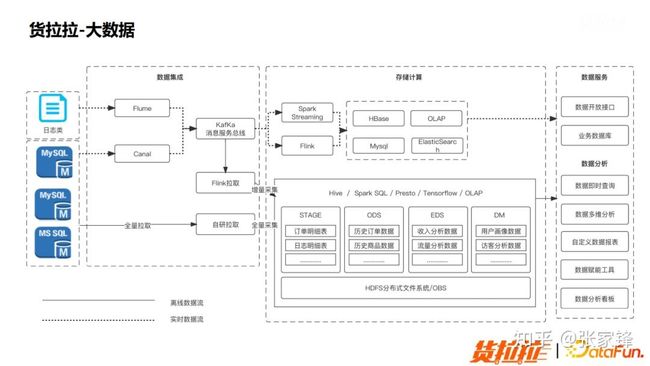
图1.2 货拉拉大数据数据流在数据采集阶段会存在实时采集和离线采集两条路线。
- 实时采集比较典型的场景为用户端上埋点会直接同步到大数据平台做存储,供后续的在线和离线计算使用。
- 离线的数据主要是来自于业务方的数据库,会通过天或者是小时定期采集到大数据存储中,以供后续使用。
中间是数据的存储和计算阶段。在离线场景中会通过对数据 ETL 之后转换为构造数仓的分层体系。实时比较典型的场景为数据在经过 Flink 的处理后会直接落在线存储系统,类似于 HBase 和 OLAP 等等,为后续的业务系统提供数据服务。
OLAP 演进概览
货拉拉从 2021 年开始进行 OLAP 的技术研究,截至目前已经经历 3 个阶段:
- 2021 年上半年为货拉拉的 OLAP1.0 阶段,这个阶段我们主要是支持公司的罗盘业务,我们引入的是能够提供较好的单表依据和查询能力的 Apache Druid 引擎。
- 2021 年下半年为货拉拉的 OLAP2.0 阶段,我们支持了智能定位工具,这个阶段引入了够提供单表明细查询,并且还有较高的压缩率 ClickHouse。
- 今年为货拉拉的 OLAP3.0 阶段,伴随着公司业务需求的不断增多,我们也会需要用到多数据源的关联分析。基于此,由于 Apache Doris 具备大表关联分析的能力,我们引入了 Apache Doris 引擎。

图2.1 货拉拉OLAP体系演进过程
OLAP1.0 孕育期
>>>业务需求分析先看下没有引入 OLAP 之前的业务数据流:
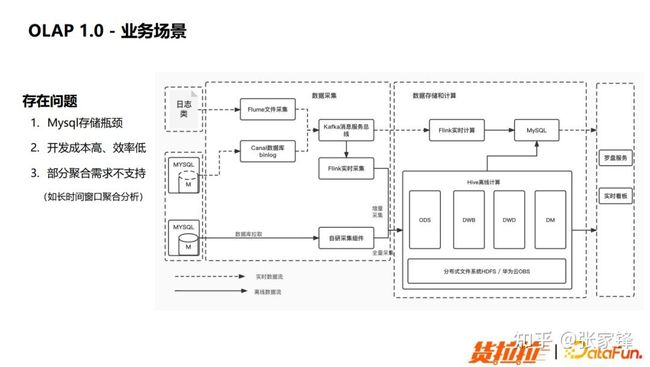
图3.1 OLAP1.0业务场景
根据该图可以看到业务的数据通过实时和离线处理之后会落在 MySQL,MySQL 之中储存了维度聚合之后的结果数据,这也意味着会在 Flink 之中做大量的聚合分析,根据业务需要的相应维度所做的一系列组合都是在Flink之中做实时聚合,最后将结果储存到 MySQL。
存在的问题:
- 存在存储瓶颈,类似于 Kylin 之中的维度爆炸的问题。
- 开发成本、高效率低。当业务侧需要新增维度的时候会需要对 Flink 中的所有作业都做一定的修改,然后再重新上线。
- 无法支持部分聚合需求。
对于存在的这些问题,我们经过分析之后,总结出了 3 个背后存在的需求点:
- 业务侧希望能够横向扩容,解决存储瓶颈。
- 希望能够自由组合维度做分析,提升业务侧开发效率。
- 希望能够支持任意维度实现跨度的分析。
>>> 解决方案
根据业务需求,并通过调研,我们决定使用 OLAP 引擎来支持业务需求。那我们如何选择一款 OLAP 引擎,并把它稳定的应用到生产之中呢?我们总结了如下的 4 个步骤作为解决思路:
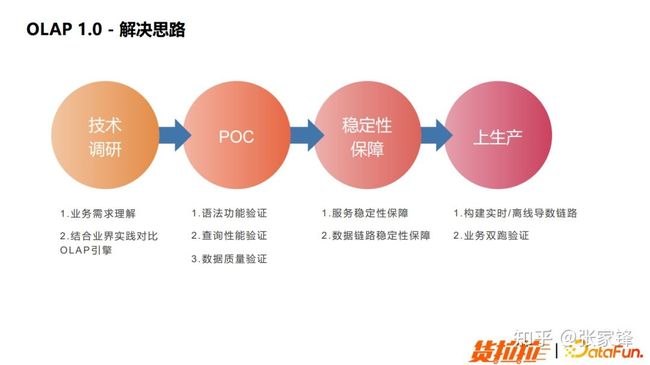
图3.2 OLAP 1.0 解决思路
技术调研
技术调研阶段,我们对比了 Durid、ClickHouse、Kylin、Presto 和 Doris 等等引擎。结合我们上述的 3 个业务需求,最终我们选择了 Druid 引擎。
原因是 Druid 除了能够满足我们的业务需求之外,还有一个比较重要的影响因素是 Druid 引擎是纯 Java 开发,与我们的技术栈比较吻合,可控性更高。

图3.3 OLAP1.0技术调研
POC 阶段
POC 过程中,从以下 3 个步骤着手:
- 功能验证。在功能验证中,我们会收集业务侧的 SQL,之后提取 SQL Pattern,然后再根据 Druid 引擎的 Rollup 语义做 SQL 的改写,涉及到大量 UDF 的改写、Rollup 语义兼容以及 Count Distinct 语义兼容等等。
- 性能验证。我们会直接采用业务真实的数据和业务真实的 SQL 来执行。验证过程中我们会将 Cache 关闭,分别统计 P75、P90、P99 的查询耗时。在这过程中,我们会发现有部分查询的性能没有达到要求,之后我们会做性能分析。Druid 引擎本身没有比较完善的性能分析工具,不能够很好的打印出它的执行计划以及各个算子的耗时,所以我们采用了第三方的 Arthas 火焰图进行分析。定位了相应的算子后,最终我们通过优化我们建表导数的逻辑以及索引构建的逻辑,并主要通过调整 Segment 大小的同时加入物化视图的方法,进行一些参数的调整以此来优化性能。
- 准确性验证。我们将业务真实数据同时写 Hive 表和 Druid,之后跑 Hive SQL和 Druid SQL,来进行数据质量的校对。在这个过程中我们会发现例如 StringLast 函数等一些函数会在特定的场景下出现计算值不稳定的问题。
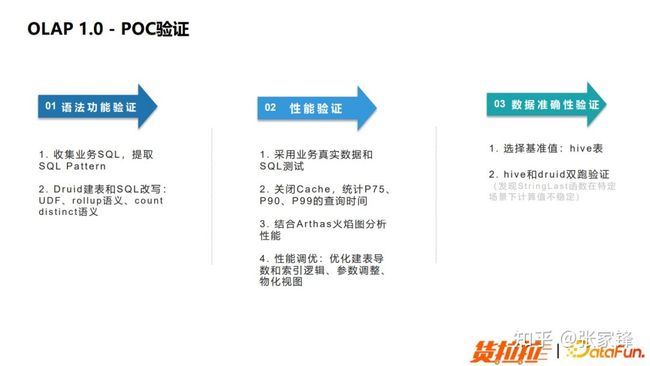
图3.4 OLAP1.0 POC 验证
稳定性保障
当 POC 验证完成之后,接下来我们会进行稳定性的保障。我们将稳定性保障分为事前、事中、事后 3 个阶段:
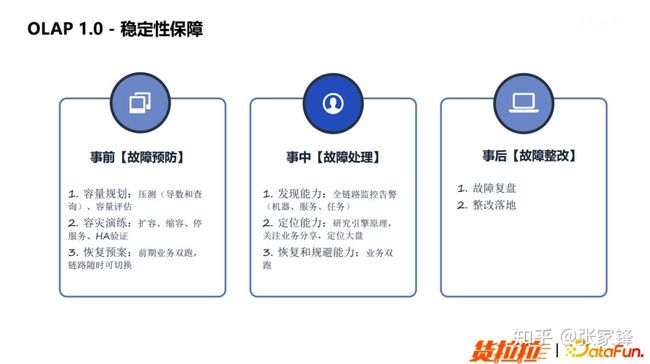
图3.5 OLAP1.0 稳定性保障
上线阶段
当稳定性保障建立完成之后就会进入到上线阶段。上线过程我们同样分成了 3 个阶段:
- OLAP测试阶段。在这个阶段中,业务的数据会接入到 Druid 之中,但是业务的真实查询还是通过原来的 MySQL 库。这个阶段主要会验证 Druid 引擎的数据质量和 Druid 集群的稳定性。
- 上线观察阶段。在这个阶段,业务的查询会切回到 Druid。同时旧的 MySQL 链路还没有下线,业务侧能够随时切回 MySQL 链路。
- OLAP运行稳定阶段。我们会把 MySQL 旧的链路下线,做资源的回收。
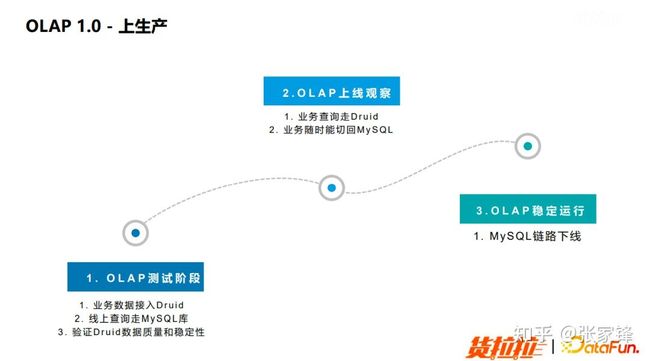
图3.6 OLAP1.0 上生产
>>> 问题总结
下面总结了 1.0 阶段时遇到的问题:
- 数据导入部分中,实时数据乱序为典型问题。
- 在数据准确性验证阶段发现 StringLast 的函数值不稳定。
- Durid 没有一个高效的精准去重的函数。

图3.7 OLAP1.0 问题总结
OLAP2.0 完善期
>>> 业务需求分析
在 OLAP2.0 阶段主要有以下 4 个业务需求:

图4.1 OLAP2.0 业务需求分析下图是简单的业务工具的截图,从图中可以看到,OLAP2.0 需要能够支持汇总与明细,同时基于这些能力能够做一个快速的问题定位。
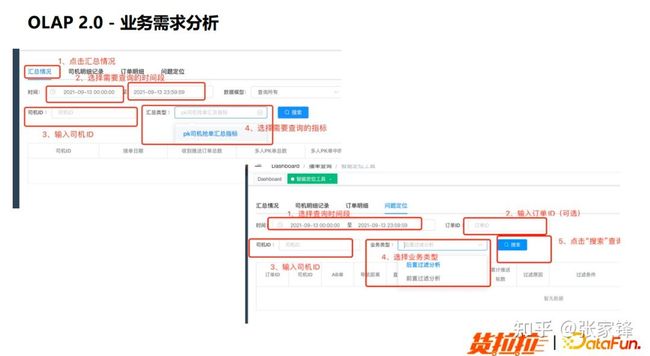
图4.2 OLAP2.0 业务需求分析骤去实现。
>>> 解决方案
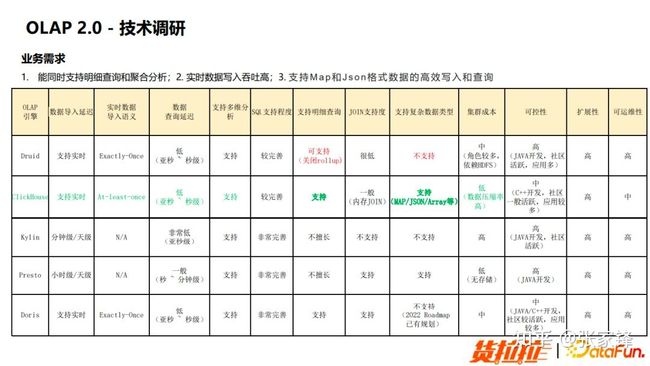
图4.3 OLAP2.0 技术调研OLAP2.0 我们引入了 CliclkHouse。ClickHouse 能够比较好地支持复杂的数据类型,同时因为业务侧是埋点数据,所以对于实时导入语义要求并没有那么高。没有采用 Druid 主要是有 2 个原因:
- Druid 对于复杂的数据结构支持度并不是很好。
- Druid 虽然能够支持明细查询,但是 Druid 的明细查询和聚合查询得分成不同的表,这样就会额外的引入一系列的存储成本。
剩下的部分就是 POC 、上生产的步骤,这两个步骤和 OLAP1.0 阶段比较类似,所以在这里就不过多展开介绍。
OLAP3.0 成熟期
>>>业务需求分析2022 年随着公司业务的发展,更多的产品线对于多数据源关联场景下的在线分析需求也会变得越来越迫切。比如说 AB 实验场景与实时数仓场景,这两个场景对于多表关联需求,尤其是大表的多表关联需求也变得越来越迫切。

图5.1 OLAP3.0 需求分析
举一个 AB 实验的例子。从下图可以看到,例子中是需要把 AB 实验的一个数据和后面相应的司机与用户的埋点数据关联到一起并做分析。在这种情况下,我们就会发现之前的两种工具都会存在一系列的弊端。
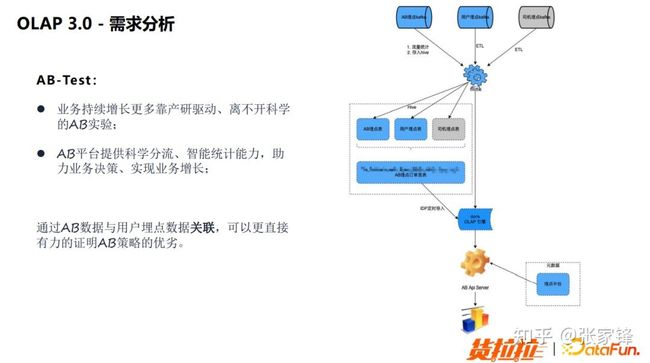
图5.2 OLAP3.0 需求分析
>>> 解决方案
技术调研
在技术调研阶段我们观察了 Druid 和 ClickHouse。Druid 引擎可以支持一些维表的简单 Join,ClickHouse 则能够支持 Broadcast 这种基于内存的 Join,但是对于大数据量千万级甚至亿级的一些表的 Join 而言,ClickHouse 的性能表现不是很好。

图5.3 OLAP3.0 技术调研
接下来我们对 Doris 进行了调研,我们发现 Doris 是能够支持小表的 Join,对大表的话也同样能够支持基于 Shuffle 的 Join,对于复杂数据类型(Array、JSon)的支持,经过跟 Apache Doris 社区沟通,预计将在 2022 年 7 月份的新版本中发布。通过在多个维度和需求满足度上进行对比,我们最终选择了 Apache Doris,也是因为 Apache Doris 的 SQL 支持度非常的完善。
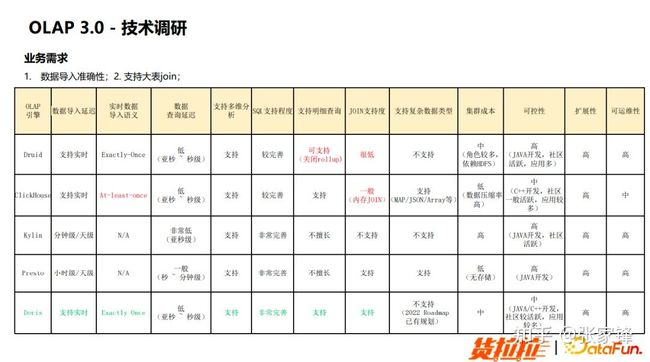
图5.4 OLAP3.0 技术调研
POC 阶段
我们除了引用业务真实的数据和场景做验证以外,还引入了 TPC-DS 的数据集做了验证。在多表关联的场景下对单天数据进行查询,对 5 亿左右的数据量进行 Join,TP75 大概是 9 秒左右。在数据质量阶段我们也是把 TPC- DS 的数据集以及业务真实数据集,分别在 Hive 和 Doris 里面做了双跑验证,发现两者都是能够完全对得上的。
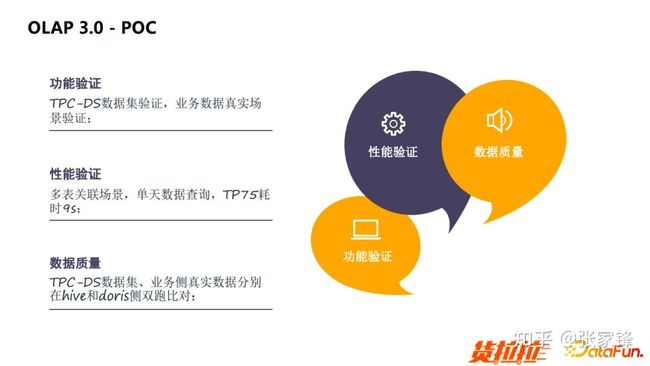
图5.5 OLAP3.0 POC
稳定性保障
与之前一样依然是从事前的容量评估和压测、事中的监控和定位来进行。
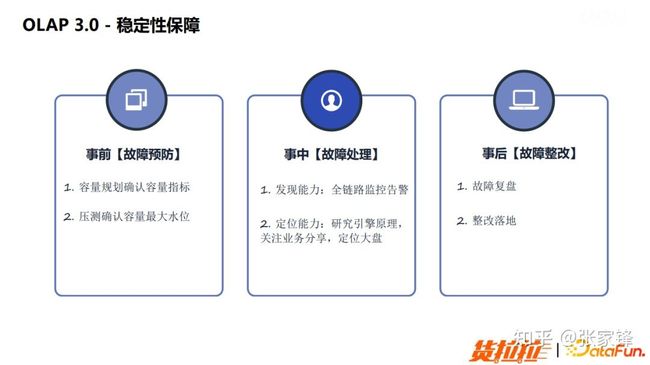
图5.6 OLAP3.0 稳定性测试
下面是我们的监控图,主要是关于 Compaction 相关的一些监控,感兴趣的同学可以看看。(文末 QA 环节有部分讲解)
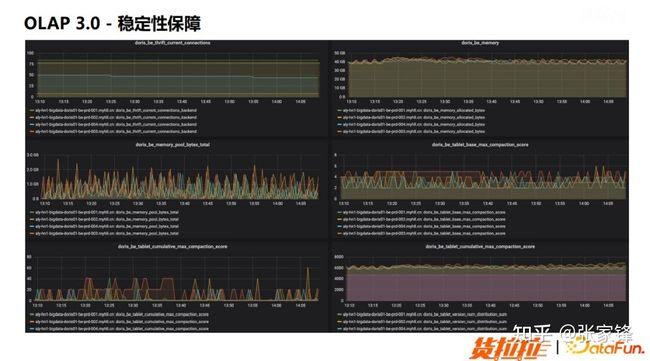
图5.7 OLAP3.0 稳定性监控
>>> 问题总结
第一个问题是查询性能的优化。业务侧的需求为 7 天的查询 RT 需要在 5 秒内完成,在优化前,我们发现 7 天的查询 RT 是在 30 秒左右。对于这个问题,我们的主要优化策略是把小表 Join 大表改成了大表 Join 小表,主要原理是因为 Doris 默认会使用右表的数据去构建一个 Hashtable。还有类似下图中的情况:union all 是在子查询中,然后再和外层的另外一张大表做 Join 的查询方式。这种查询方式没有用到 Runtime Filter 的特性,因此我们将 union all 提到子查询外,这样就能够用到 Runtime Filter,这应该是由于这里的条件下没有推下去所导致的。同时运行时采用的 Bloom Filter 是可以将 HashKey 条件下推到大表 Scan 阶段做过滤。在经过对这两者优化之后便能够满足我们的查询性能需求了。

图5.8 OLAP3.0 问题1第二个问题是 UnhealthyTablet 不下降,并且在查询阶段会出现 -230 的报错。这个问题的场景是我们在没有停 FIink 写任务的时候,对 BE 机器交替重启,重启完会出现很多 UnhealthyTablet。经过我们后续的分析发现,其中一个原因主要是在 Coordinator BE 在做二阶段提交的时候比较巧合,Coordinator BE 的二阶段提交 Commit 后,也就是大部分的副本是已经 Commit 后且在 Publish 前,在这短短的时间范围内 BE 机器被重启,这也导致会出现 Tablet 状态不一致的情况。同时由于我们当时把参数调整的过大,导致了 Compaction 压力过大。最后的解决办法:与 Aapache Doris 社区的同学经过互助排查,引入了社区 1.1.0的 Patch,同时对相应的数据做了恢复。

图5.9 OLAP3.0 问题2
>>> 参数优化
- 打开 Profile。Doris 对于查询的性能分析具有非常好的 Profile 文件,这一点是非常赞的!我们可以看到各个算子在每一个阶段查询耗时以及数据处理量,这方面相比于 Druid 来说是非常便捷的!
- 调大单个查询的内存限制,同时把 BE 上的执行个数由 1 个调整成为 8 个,并且增加了 Compaction 在单个磁盘下的数据量。对于 Stream Load,我们把 Json 格式的最大的内存由 100 兆调整成为 150 兆,增大了 Rowset 内 Segment 的数量,并且开启了 SQL 级和 Partition 级的缓存。

图5.10 OLAP3.0 参数优化>>>数据流下图是使用 Doris 之后的数据流图:
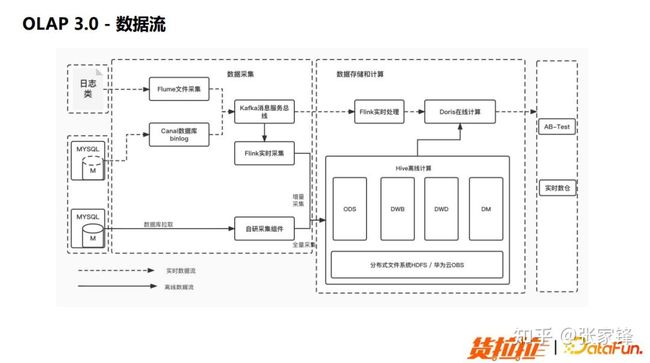
图5.11 OLAP3.0 数据流
数据流中,我们在 Flink 中做的事情已经很少了,经过数据简单的 ETL 后就可以把数据直接灌入到 Doris。经过 Doris 一系列的聚合计算、union 计算以及多表关联计算之后,业务侧就可以直接查询 Doris 来获取相关数据。
总结与思考
总结:我们 OLAP 的引进主要还是从业务需求的角度出发来匹配合适的引擎,为业务精细化运维提供技术支持。在这之后,我们也思考了一套较为完善的上线流程及稳定性保证方案,为业务的平稳运行提供能力保障。
思考:我们认为很难有单个引擎能够富含各种场景。因此在技术选型时,需要针对于需求特点和引擎特点进行合理选择。
后续规划
我们希望可以向 OLAP 平台化发展,通过实现自助化建模的同时在这方面做一些多引擎的路由,使其能够支持各类聚合、明细以及关联等场景。
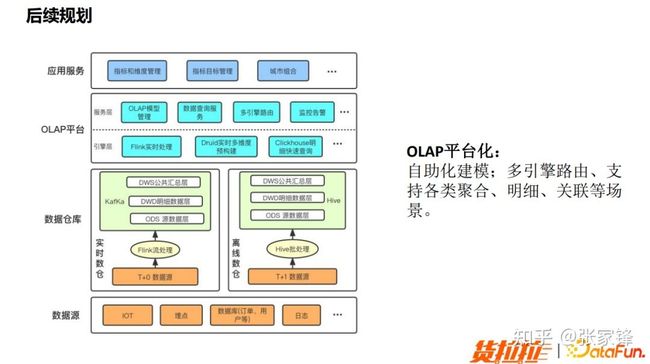
图6.1 后续规划 OLAP 平台化除 OLAP 平台化之外,后续我们的引擎演进计划从高效、稳定和内核演进三部分来进行。

图6.2 后续规划 引擎演进稳定性方面:对 Doris 还要继续深入内核理解,提供一定的二次开发。另外 Doris 社区的相关原理以及代码级别的教程数量十分丰富,这也间接性降低了我们深入 Doris 原理的难度。
内核演进方面:我们发现 Doris 基本能够覆盖 Druid 所有场景,因此后续计划以 Doris 引擎为主,Clickhous 引擎为辅,逐渐将 Druid 的相关业务向 Doris 迁移。
Q&A 环节
Q:刚才讲到了后续要从 Druid 引擎迁移到 Doris,要实现迁移的成本有多大呢?
A:迁移成本方面和我们之前的成本是一样的。我们上线的时候也会采用以下方式:先把业务的数据同时往 Druid 和 Doris 之中写,写完之后的业务迁移会涉及一些 SQL 改造。因为 Doris 更加接近MySQL的协议,比起 Druid SQL 会更加便捷,所以这部分的迁移成本不是很大。
Q:刚才介绍的第二个场景之中的监控图都看了哪些指标呢?
A:关于监控图,我们会比较关注 Doris 的数据导入。而在数据导入部分,我们最关注的就是 Compaction 的效率,是否有 Compaction 的堆积。我们现在还是采用的默认参数,也就是 Compaction 的分数就代表它的版本号,所以我们监控的更多的是它的版本。对于这方面的监控,社区也已经有了比较完善的相应技术方案,我们也是参考了社区的技术方案来进行了监控的指标搭建。
Q:从指标上看,Doris 的实时服务在线查询性能怎么样?在数据导入情况下性能损耗可以从这些指标上看出来吗?
A:实时导入方面主要是从 Compaction 的效率来看。结合到我们这边的业务场景,最多的一张表,单表一天也有 6 亿到 10 亿的数据量的导入,也是一张埋点。另外关于峰值,它的 QPS 也是能达到千到万的,所以导入这一块压力不是很大。
Q:SQL 缓存和分区缓存实际效果怎么样?
A:SQL 缓存方面效果还好,对于很多离线场景,尤其是首页这种查询的数据量而言。比如以昨天或者是过去一个小时之前的这种情况来说,SQL 缓存命中率会非常高。分区级缓存方面,我们分区的时间还是设的是小时级,这意味着如果这个查询里面涉及到的一些分区在一个小时内没有数据更新的话,那么就会走 SQL 缓存;如果有更新的话就会走分区级缓存。总体来看效果还好,但是我们这边命中比较多的还是 SQL 级的缓存。
Q:Doris 的查询导入合并和缓存的 BE 节点的内存一般怎么分配?
A:缓存方面我们分配的不大,还是采用的偏默认的 1G 以内。导入方面我们设计的是 parallel_fragment_exec_instance_num 这个参数,大概在 8G 左右。
Q:可以解释一下 OLAP3.0 的解决思路吗?
A:对于 OLAP3.0 方面来说,业务的主要诉求就是大表Join。除此之外,还有一些类似于导入的进度一致等等。在大表Join方面,我们也对比了很多的引擎。Druid 这方面就是偏维表;Clickhouse这方面还是偏基于内存方面的 Broadcast。正因如此,主要是基于大表Join的出发点,我们选择引入了在Join这方面能力更强的 Doris。
Q:Druid、ClickHouse 和 Doris 应该都是近实时的,就是 Near Real-time,他们的写入不是立刻可见的,是这样吗?
A:是这样的。像 Doris 和 ClickHouse 之前的写入都是 Flink 直接去写,我们也没有完全做到来一条数据就写一条,都是一个微批次。一个批次最大可以达到 150 兆的数据堆积,写入一次的时间间隔也是到 10 秒左右,没有做到完全的实时写入。
Q:方便透露一下货拉拉目前 Doris 的集群的使用情况,比如机器的数量和数据量吗?
A:我们的集群数量还不算很多,10 多台。
Q:对于 Doris 的运维方面,它的便捷性和 Druid、ClickHouse、Kylin、Presto 这些相比,有很好的扩展性吗?
A:我们觉得是有的。第一个是在我们 Druid 方面碰到了一个比较大的痛点,就是它的角色特别多,有 6 种角色,所以需要部署的机器会非常多。另外一点是 Druid 的外部依赖也非常多,Druid 依赖于 HDFS、离线导入还需要有 Hadoop 集群。第二个是 ClickhHouse 方面,我们当时使用的版本对于 Zookeeper 也是有比较大的依赖。另外,ClickHouse 也是偏伪分布式的,有点类似于数据库的一种分表。Doris 自身就只有 FE、BE,外部依赖会非常少,所以我们从部署的角度同时考虑到 Doris 的横向扩展方面,Doris 的扩缩容也能够做到自平衡,所以相比而言 Doris 会更好一些。
Q:在实时特征场景下,分钟级的数据更新对服务性能要求比较高,可以用 Doris 吗?能达到 TP99 200 毫秒以下吗?
A:TP99 能够否达到200毫秒以下主要和你查询 SQL 相关。
例如我们这边的很多涉及到大表 Join 的查询,涉及的分区数据量大概在 10 亿量别,业务侧对于查询性能要求是 5 秒以内,通过 Doris 是可以满足我们需求的。如果是实时特征这种业务,是否能达到 200 毫秒可能需要经过一轮实际测试才能得到结果。