ChatGLM2-6b小白部署教程(windows系统,16G内存即可,对显卡无要求,CPU运行)
一.前言
近期清华KEG和智谱AI公司一起发布了中英双语对话模型ChatGLM2-6B(小尺寸LLM),开源在https://github.com/THUDM/ChatGLM2-6B,可单机部署推理和fine-tune。虽然默认程序是GPU运行且对显卡要求不高,官方也说默认需要13G的显存,使用量化模型貌似只需要6G显存,但对于我这种平民玩家,不租云服务器的话,单靠我这GTX3050 4G的卡怕是跑不动了,所以就尝试CPU部署量化后的ChatGLM2-6b-int4模型(不同版本的ChatGLM2部署方法基本一致,只是加载的模型和需要的硬件环境有区别)
二.机器配置&环境
本人机器配置: 系统WIN10 CPU R5-5600H GPU GTX3050 4G 内存16G
环境:python 3.11(>=3.8即可),需要科学上网(需要访问git和huggingface)
三.代码下载&项目所需python环境安装
git源码下载
#创建目录并进入
mkdir ChatGLM2-6b-int4
cd ChatGLM2-6b-int4
# git源码下载
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
git过程如果使用下载报错,需要配置git代理
git config --global https.proxy http://127.0.0.1:10809 & git config --global https.proxy https://127.0.0.1:10809(具体ip端口号可在 网络和Internet>代理 中查看)
如需取消代理设置如下
git config --global --unset http.proxy & git config --global --unset https.proxy
python虚拟环境创建并切换(conda创建环境切换也ok)
#创建虚拟环境(pip安装的包仅在此环境下,相关的依赖都在chatglm2b项目下)
python -m venv glm_env
#切换环境
glm_env\Scripts\activate
安装项目依赖包(指定阿里云镜像源)
torch下载时间相对较长
#安装项目依赖并指定镜像源
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
安装成功喽
四.模型相关文件下载&加载
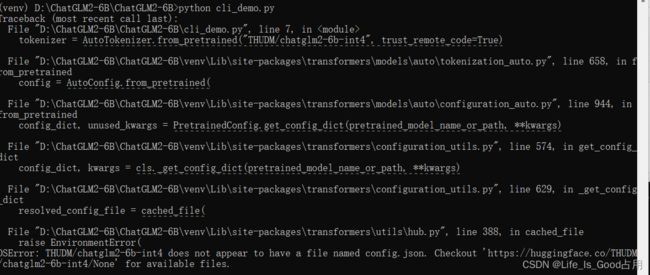
chatglm2-6b-int4模型地址(huggingface) 也可以在清华国内模型地址(不需要科学上网,chatglm2-6b-int4一共三个文件)下载,但是后者少了一些模型文件以外的配置文件(推理时需要),文件较小,也可以单独下载(文章顶部),如果只下载了模型的三个文件,在推理时会报错如下
然后我们开始下载模型了

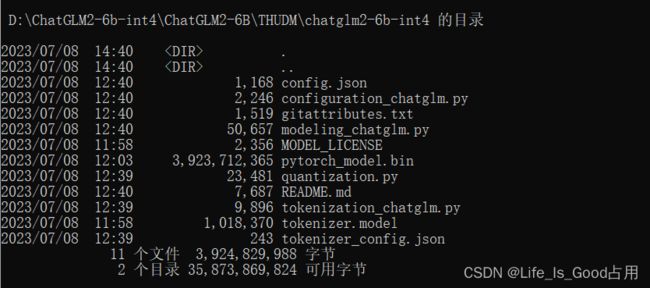
量化后的int4模型文件接近4G,不过也看出来出租屋这100M宽带不止100M呀。。。,很给力一会就下完了。在项目目录下面创建THUDM\chatglm2-6b-int4两级目录,将模型相关文件放置文件夹,文件目录如下
回到项目根目录下在cli_demo.py web_demo.py web_demo2.py api.py内修改部分代码,cli_demo为例,其他相同(主要修改模型加载路径以及改为CPU运行).
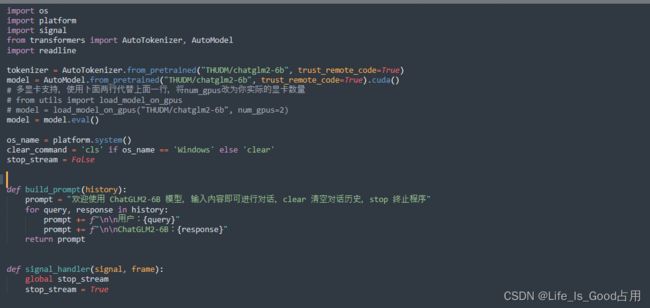
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
修改成
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True).float()四.命令端|web 端推理
然后在项目目录下执行cli_demo.py,提示没有安装readline

尝试pip安装readline一直失败(试了各种镜像源),最后pip install pyreadline3解决,但又报了其他错误

这时候发现自己的路径用 / (THUDM/chatglm2-6b-int4), 赶紧替换为 \,我估计经常在linux下开发的同学都会犯这个错误,然后我们继续执行 python cli_demo.py,发现没有GCC命令,百度了下发现在CPU上运行量化后的int4模型,需要安装gcc和openmp,正好TDM-GCC可以顺带安装openmp,于是下载了TDM-GCC,安装过程中需要勾选安装openmp
最终,我们和chatglm2对上了话,但回复速度实在太慢,而且好像介绍自己都有问题(毕竟是量化后的模型),简单的快排更尬了。。。。。。有条件的还是用显卡,或者google colab、阿里云之类的云服务器
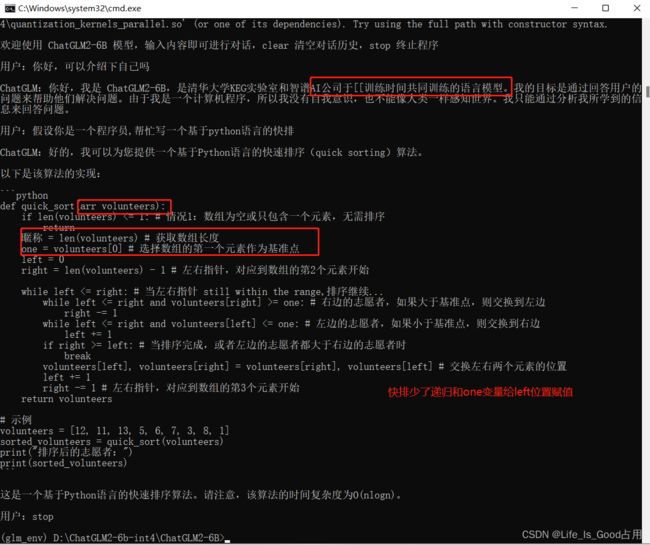
推理过程中使用的资源情况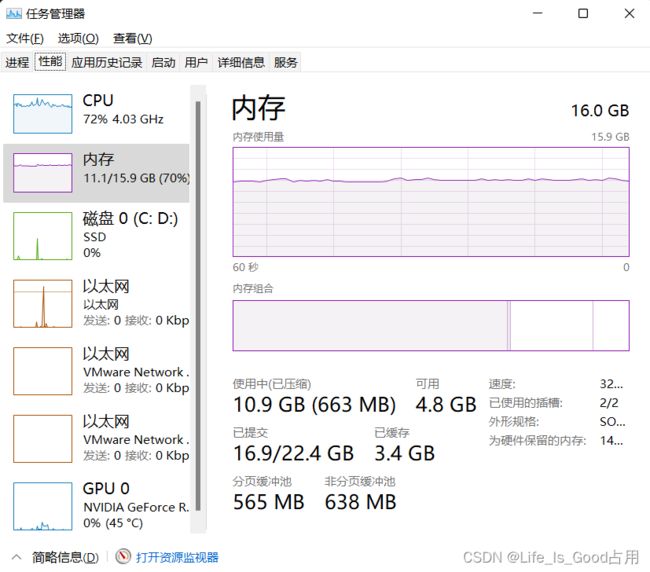
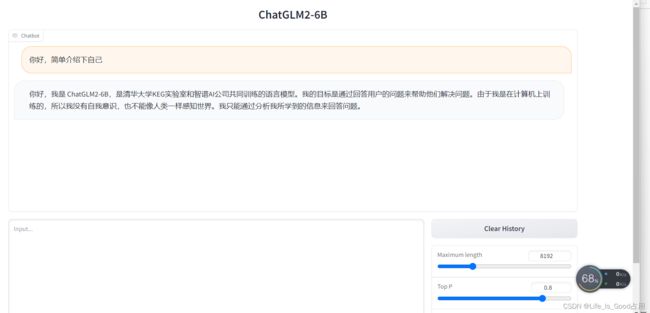
网页版的话直接执行python web_demo.py即可(web_demo2也一样,只是ui页面不同),程序会运行一个 Web Server,然后启动浏览器输入对话内容即可
五.api部署
安装fast等相关依赖包,然后curl本地默认端口即可得到回复
#安装fastapi等包,以上包在install requirements文件时应该已经安装过了,uvicorn是python 轻量级 ASGI web服务器框架
pip install fastapi uvicorn -i https://mirrors.aliyun.com/pypi/simple
#项目根目录下执行 api.py
python api.py
#程序默认部署在本地8000端口,通过curl post直接调用
curl -X POST "http://127.0.0.1:8000" -H 'Content-Type: application/json' -d '{"prompt": "你好,请介绍下自己", "history": []}'