Spring Boot笔记
1、什么是SpringBoot
1、简介
就是一个javaweb的开发框架
- 以前Spring的配置太多,太麻烦,为了提高开发效率,于是开始提倡“约定大于配置”,进而衍生出一些一站式的解决方案。
- Spring Boot 基于 Spring 开发,Spirng Boot 本身并不提供 Spring 框架的核心特性以及扩展功能,只是用于快速、敏捷地开发新一代基于 Spring 框架的应用程序。
- 也就是说,它并不是用来替代 Spring 的解决方案,而是和 Spring 框架紧密结合用于提升 Spring 开发者体验的工具。
- Spring Boot 以约定大于配置的核心思想,默认帮我们进行了很多设置,多数 Spring Boot 应用只需要很少的 Spring 配置。
简单来说就是SpringBoot其实不是什么新的框架,它默认配置了很多框架的使用方式,就像maven整合了所有的jar包,spring boot整合了所有的框架 。
2、优点
- 为所有Spring开发者更快的入门
- 开箱即用,提供各种默认配置来简化项目配置
- 内嵌式容器简化Web项目
- 没有冗余代码生成和XML配置的要求
3、微服务架构
微服务是一种架构风格,他要求我们在开发一个应用的时候,这个应用必须建成一系列小服务组合,可以通过http方式进行通信。
所谓微服务加购,就是打破之前all in one的架构方式,把每个功能元素独立出来,把独立出来的功能元素的动态组合,需要的功能元素才去拿来组合,需要多一些可以整合多个功能元素,所以微服务架构是对功能元素进行赋值,而没有对整个应用进行复制,这样做的好处是:
- 节省了调用资源
- 每个功能元素的服务都是一个可替换的,可独立升级的软件代码
程序核心:
- 高内聚(在划分模块时,要把功能关系紧密的放到一个模块中)
- 低耦合(模块之间的联系越少越好,接口越简单越好)
springboot:快速构建一个个功能独立的微服务应用单元
springcloud:大型分布式网络服务的调用
spring cloud data flow:在分布式中间,进行流式数据计算
2、第一个SpringBoot程序
2.1、项目创建
使用 IDEA 直接创建项目
- 创建一个新项目
- 选择spring initalizr , 可以看到默认就是去官网的快速构建工具那里实现
- 填写项目信息
- 选择初始化的组件(初学勾选 Web 即可)
- 填写项目路径
- 等待项目构建成功
2.2、项目结构分析
- 程序的主启动类(程序的主入口)
- 一个 application.properties 配置文件(SpringBoot的核心配置文件)
- 一个 测试类
- 一个 pom.xml
2.3、HelloWorld项目
引入依赖
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.2.5.RELEASEversion>
<relativePath/>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
创建主程序
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
}
编写业务
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@RequestMapping("/hello")
public String handle01(){
return "Hello, Spring Boot 2!";
}
}
运行&测试
- 运行
MainApplication类 - 浏览器输入
http://localhost:8888/hello,将会输出Hello, Spring Boot 2!。
设置配置
maven工程的resource文件夹中创建application.properties文件。
# 设置端口号
server.port=8888
打包部署
在pom.xml添加
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
在IDEA的Maven插件上点击运行 clean 、package,把helloworld工程项目的打包成jar包,
打包好的jar包被生成在helloworld工程项目的target文件夹内。
用cmd运行java -jar boot-01-helloworld-1.0-SNAPSHOT.jar,既可以运行helloworld工程项目。
将jar包直接在目标服务器执行即可。
2.4、SpringBoot特点
2.4.1、SpringBoot依赖管理特性
-
父项目做依赖管理
依赖管理 有一个父项目 <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.3.4.RELEASEversion> parent> 上面项目的父项目如下: <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-dependenciesartifactId> <version>2.3.4.RELEASEversion> parent> 几乎声明了所有开发中常用的依赖的版本号,自动版本仲裁机制 -
开发导入starter场景启动器
1、见到很多 spring-boot-starter-* : *就某种场景 2、只要引入starter,这个场景的所有常规需要的依赖我们都自动引入 3、SpringBoot所有支持的场景 https://docs.spring.io/spring-boot/docs/current/reference/html/using-spring-boot.html#using-boot-starter 4、见到的 *-spring-boot-starter: 第三方为我们提供的简化开发的场景启动器。 5、所有场景启动器最底层的依赖 <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starterartifactId> <version>2.3.4.RELEASEversion> <scope>compilescope> dependency> -
无需关注版本号,自动版本仲裁
1、引入依赖默认都可以不写版本 2、引入非版本仲裁的jar,要写版本号。 -
可以修改默认版本号
1、查看spring-boot-dependencies里面规定当前依赖的版本 用的 key。 2、在当前项目里面重写配置 <properties> <mysql.version>5.1.43mysql.version> properties>
2.4.2、自动配置
自动配好Tomcat
-
引入Tomcat依赖。
-
配置Tomcat
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-tomcatartifactId> <version>2.3.4.RELEASEversion> <scope>compilescope> dependency>
自动配好SpringMVC
- 引入SpringMVC全套组件
- 自动配好SpringMVC常用组件(功能)
自动配好Web常见功能,如:字符编码问题
- SpringBoot帮我们配置好了所有web开发的常见场景
public static void main(String[] args) { //1、返回我们IOC容器 ConfigurableApplicationContext run = SpringApplication.run(MainApplication.class, args); //2、查看容器里面的组件 String[] names = run.getBeanDefinitionNames(); for (String name : names) { System.out.println(name); } }
默认的包结构
-
主程序所在包及其下面的所有子包里面的组件都会被默认扫描进来
-
无需以前的包扫描配置
-
想要改变扫描路径
- @SpringBootApplication(scanBasePackages=“com.guo”)
- @ComponentScan 指定扫描路径
@SpringBootApplication 等同于 @SpringBootConfiguration @EnableAutoConfiguration @ComponentScan("com.guo.boot")
2.5、容器功能
2.5.1、组件添加
@Configuration
@Configuration用于定义配置类,可替换xml配置文件,这个时候在类里边不能写bean标签了需要使用@bean注解,被注解的类内部包含有一个或多个被@Bean注解的方法
@bean:给容器中添加组件,以方法名作为组件的id。返回类型为组件类型,返回的值,就是组件在容器中的实例
- Full模式(全配置)和Lite模式(轻量级配置)
#############################Configuration使用示例######################################################
/**
* 1、配置类里面使用@Bean标注在方法上给容器注册组件,默认也是单实例的
* 2、配置类本身也是组件
* 3、proxyBeanMethods:代理bean的方法
* Full(proxyBeanMethods = true)、【保证每个@Bean方法被调用多少次返回的组件都是单实例的】
* Lite(proxyBeanMethods = false)【每个@Bean方法被调用多少次返回的组件都是新创建的】
* 组件依赖必须使用Full模式默认,proxyBeanMethods = true。
其他默认是否Lite模式:proxyBeanMethods = flase
*
*
*
*/
@Configuration(proxyBeanMethods = true) //告诉SpringBoot这是一个配置类 == 配置文件
public class MyConfig {
/**
* Full:外部无论对配置类中的这个组件注册方法调用多少次获取的都是之前注册容器中的单实例对象
* @return
*/
@Bean //给容器中添加组件。以方法名作为组件的id。返回类型就是组件类型。返回的值,就是组件在容器中的实例
public User user01(){
User zhangsan = new User("zhangsan", 18);
//user组件依赖了Pet组件
zhangsan.setPet(tomcatPet());
return zhangsan;
}
@Bean("tom")
public Pet tomcatPet(){
return new Pet("tomcat");
}
}
################################@Configuration测试代码如下########################################
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan("com.atguigu.boot")
public class MainApplication {
public static void main(String[] args) {
//1、返回我们IOC容器
ConfigurableApplicationContext run = SpringApplication.run(MainApplication.class, args);
//2、查看容器里面的组件
String[] names = run.getBeanDefinitionNames();
for (String name : names) {
System.out.println(name);
}
//3、从容器中获取组件
Pet tom01 = run.getBean("tom", Pet.class);
Pet tom02 = run.getBean("tom", Pet.class);
System.out.println("组件:"+(tom01 == tom02));
//4、com.atguigu.boot.config.MyConfig$$EnhancerBySpringCGLIB$$51f1e1ca@1654a892
MyConfig bean = run.getBean(MyConfig.class);
System.out.println(bean);
//如果@Configuration(proxyBeanMethods = true)代理对象调用方法。SpringBoot总会检查这个组件是否在容器中有。
//保持组件单实例
User user = bean.user01();
User user1 = bean.user01();
System.out.println(user == user1);
User user01 = run.getBean("user01", User.class);
Pet tom = run.getBean("tom", Pet.class);
System.out.println("用户的宠物:"+(user01.getPet() == tom));
}
}
@Import
给容器中自动创建出这两个类型的组件、默认组件的名字就是全类名
@Import({User.class, DBHelper.class})
@Configuration(proxyBeanMethods = false) //告诉SpringBoot这是一个配置类 == 配置文件
public class MyConfig {
}
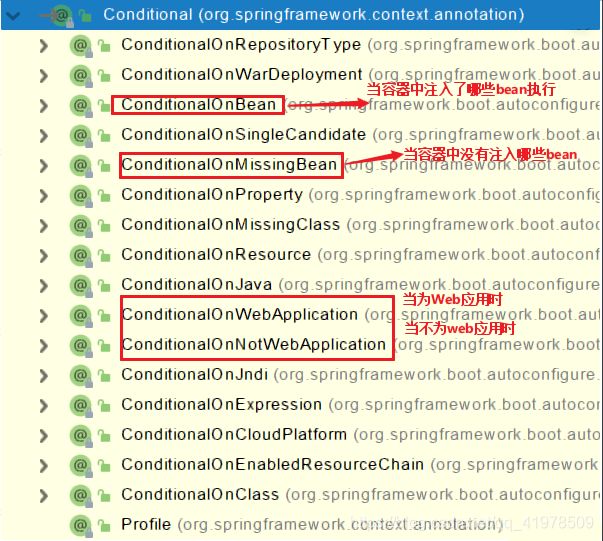
@Conditional(条件装配注解)
条件装配:当满足Conditional指定的条件,则进行组件注入
- 当这个注解配置在类上时,只有这个类内注入了响应名称的组件才会生成相应的实体,
- 当配置在部分方法时,只有相应的被注入才可以生成实体,否则就不生效
=====================测试条件装配==========================
@Configuration(proxyBeanMethods = false) //告诉SpringBoot这是一个配置类 == 配置文件
//@ConditionalOnBean(name = "tom")
@ConditionalOnMissingBean(name = "tom")
public class MyConfig {
/**
* Full:外部无论对配置类中的这个组件注册方法调用多少次获取的都是之前注册容器中的单实例对象
* @return
*/
@Bean //给容器中添加组件。以方法名作为组件的id。返回类型就是组件类型。返回的值,就是组件在容器中的实例
public User user01(){
User zhangsan = new User("zhangsan", 18);
//user组件依赖了Pet组件
zhangsan.setPet(tomcatPet());
return zhangsan;
}
@Bean("tom22")
public Pet tomcatPet(){
return new Pet("tomcat");
}
}
public static void main(String[] args) {
//1、返回我们IOC容器
ConfigurableApplicationContext run = SpringApplication.run(MainApplication.class, args);
//2、查看容器里面的组件
String[] names = run.getBeanDefinitionNames();
for (String name : names) {
System.out.println(name);
}
boolean tom = run.containsBean("tom");
System.out.println("容器中Tom组件:"+tom);
boolean user01 = run.containsBean("user01");
System.out.println("容器中user01组件:"+user01);
boolean tom22 = run.containsBean("tom22");
System.out.println("容器中tom22组件:"+tom22);
}
2.5.2、原生配置文件引入
@ImportResource
比如,公司使用bean.xml文件生成配置bean,然而你为了省事,想继续复用bean.xml,@ImportResource粉墨登场。
bean.xml:
<beans ...">
<bean id="haha" class="com.lun.boot.bean.User">
<property name="name" value="zhangsan">property>
<property name="age" value="18">property>
bean>
<bean id="hehe" class="com.lun.boot.bean.Pet">
<property name="name" value="tomcat">property>
bean>
beans>
使用方法:
@ImportResource("classpath:beans.xml")
public class MyConfig {
...
}
测试类:
public static void main(String[] args) {
//1、返回我们IOC容器
ConfigurableApplicationContext run = SpringApplication.run(MainApplication.class, args);
boolean haha = run.containsBean("haha");
boolean hehe = run.containsBean("hehe");
System.out.println("haha:"+haha);//true
System.out.println("hehe:"+hehe);//true
}
2.5.3、配置绑定
如何使用Java读取到properties文件中的内容,并且把它封装到JavaBean中,以供随时使用;
传统方法
public class getProperties {
public static void main(String[] args) throws FileNotFoundException, IOException {
Properties pps = new Properties();
pps.load(new FileInputStream("a.properties"));
Enumeration enum1 = pps.propertyNames();//得到配置文件的名字
while(enum1.hasMoreElements()) {
String strKey = (String) enum1.nextElement();
String strValue = pps.getProperty(strKey);
System.out.println(strKey + "=" + strValue);
//封装到JavaBean。
}
}
}
Spring Boot一种配置配置绑定:
@ConfigurationProperties + @Component
注意想要使用这个注解必须声明组件注解@Component
假设有配置文件application.properties
mycar.brand=BYD
mycar.price=100000
只有在容器中的组件,才会拥有SpringBoot提供的强大功能
@Component
@ConfigurationProperties(prefix = "mycar")
public class Car {
...
}
Spring Boot另一种配置配置绑定:
@EnableConfigurationProperties + @ConfigurationProperties
- 开启Car配置绑定功能
- 把这个Car这个组件自动注册到容器中
@EnableConfigurationProperties(Car.class)
public class MyConfig {
...
}
@ConfigurationProperties(prefix = "mycar")
public class Car {
...
}
3、自动配置原理初探
1、pom.xml
- Spring-boot-dependencies:核心依赖在父工程中
- 我们在写或者引入springboot依赖的时候,不需要指定版本,因为有这些版本仓库
启动器
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
- 启动器:说白了就是Springboot的启动场景
- 比如spring-boot-starter-web,他就会帮我们自动导入web环境所有的依赖
- springboot会将所有的功能场景,都变成一个个的启动器
- 我们要使用什么功能,就值需要找到对应的启动器starter
2、主程序
//标注这个类是一个springboot的应用
@SpringBootApplication
public class SpringbootStudyApplication {
public static void main(String[] args) {
//将springboot应用启动
SpringApplication.run(SpringbootStudyApplication.class, args);
}
}
分析下@SpringBootApplication
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(
excludeFilters = {@Filter(
type = FilterType.CUSTOM,
classes = {TypeExcludeFilter.class}
), @Filter(
type = FilterType.CUSTOM,
classes = {AutoConfigurationExcludeFilter.class}
)}
)
public @interface SpringBootApplication {
...
}
重点分析
@SpringBootConfiguration@EnableAutoConfiguration@ComponentScan
1、@SpringBootConfiguration
作用:SpringBoot的配置类 ,标注在某个类上 , 表示这是一个SpringBoot的配置类;
@Configuration 说明这是一个配置类 ,配置类就是对应Spring的xml 配置文件;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
@AliasFor(
annotation = Configuration.class
)
boolean proxyBeanMethods() default true;
}
2、@ComponentScan
指定扫描哪些Spring注解
作用:自动扫描并加载符合条件的组件或者bean , 将这个bean定义加载到IOC容器中
3、@EnableAutoConfiguration
@EnableAutoConfiguration :开启自动配置功能
以前我们需要自己配置的东西,而现在SpringBoot可以自动帮我们配置 ;
@EnableAutoConfiguration告诉SpringBoot开启自动配置功能,这样自动配置才能生效;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
重点分析
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
4、@AutoConfigurationPackage
翻译:自动配置包,指定了默认的包规则
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(Registrar.class)//给容器中导入一个组件
//利用Registrar导入一系列组件
//将指定的一个包下的所有组件导入进来?是主程序所在的包下
public @interface AutoConfigurationPackage {
}
- @import :Spring底层注解@import , 给容器中导入一个组件
- 利用Registrar给容器中导入一系列组件。将主启动类的所在包及包下面所有子包里面的所有组件扫描到Spring容器 ;
5、@Import({AutoConfigurationImportSelector.class})
给容器导入组件
- 利用getAutoConfigurationEntry(annotationMetadata);给容器中批量导入一些组件
- 调用List configurations = getCandidateConfigurations(annotationMetadata, attributes)获取到所有需要导入到容器中的配置类
- 利用工厂加载 Map
- 从META-INF/spring.factories位置来加载一个文件。
- 默认扫描我们当前系统里面所有META-INF/spring.factories位置的文件
- spring-boot-autoconfigure-2.3.4.RELEASE.jar包里面也有META-INF/spring.factories

# 文件里面写死了spring-boot一启动就要给容器中加载的所有配置类
# spring-boot-autoconfigure-2.3.4.RELEASE.jar/META-INF/spring.factories
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.springframework.boot.autoconfigure.admin.SpringApplicationAdminJmxAutoConfiguration,\
org.springframework.boot.autoconfigure.aop.AopAutoConfiguration,\
...
虽然我们127个场景的所有自动配置启动的时候默认全部加载,但是xxxxAutoConfiguration按照条件装配规则(@Conditional),最终会按需配置。
6、总结:
springboot所有的自动配置都是在启动的时候扫描并加载,扫描了spring.properties配置文件,所有的自动配置类都在这里面,但是不定生效,因为要判断条件是否成立,只要导入了对应的start,就有对应的启动器,有了启动器我们自动装配就会生效,然后就配置成功
- SpringBoot先加载所有的自动配置类 xxxxxAutoConfiguration
- 每个自动配置类按照条件进行生效,默认都会绑定配置文件指定的值。(xxxxProperties里面读取,xxxProperties和配置文件进行了绑定)
- 生效的配置类就会给容器中导入非常多的自动配置类@Bean,就是给容器中导入这个场景需要的所有组件 , 并配置好这些组件 @Configuration;
- 有了自动配置类 , 免去了我们手动编写配置注入功能组件等的工作;
- 只要容器中有这些组件,相当于这些功能就有了
- 定制化配置
- 用户直接自己@Bean替换底层的组件
- 用户去看这个组件是获取的配置文件什么值就去修改。
xxxxxAutoConfiguration —> 组件 —> xxxxProperties里面拿值 ----> application.properties
7、SpringApplication.run分析
分析该方法主要分两部分,一部分是SpringApplication的实例化,二是run方法的执行;
SpringApplication这个类主要做了以下四件事情:
- 推断应用的类型是普通的项目还是Web项目
- 查找并加载所有可用初始化器 , 设置到initializers属性中
- 找出所有的应用程序监听器,设置到listeners属性中
- 推断并设置main方法的定义类,找到运行的主类
8、关于springboot,谈谈你的理解
- springboot的自动装配
- run():
- 判断当前项目是普通项目还是web项目
- 推断并设置main方法的定义类,找到运行的主类
- run方法里面有一些监听器,这些监听器是全局存在的,它的作用是获取上下文处理一些bean,所有的bean无论是加载还是生产初始化多存在。

4、Springboot配置文件
1、配置文件
SpringBoot使用一个全局的配置文件 , 配置文件名称是固定的
-
application.properties
-
语法结构 :key=value
server.port=8081
-
-
application.yaml
- 语法结构 :key:空格value
server: port: 8081
- 语法结构 :key:空格value
2、yaml概述
YAML是 “YAML Ain’t a Markup Language” (YAML不是一种标记语言)的递归缩写。在开发的这种语言时,YAML 的意思其实是:“Yet Another Markup Language”(仍是一种标记语言)
这种语言以数据作为中心,而不是以标记语言为重点!
以前的配置文件,大多数都是使用xml来配置;比如一个简单的端口配置,我们来对比下yaml和xml
传统xml配置:
<server>
<port>8081<port>
server>
yaml配置:
server:
prot: 8080
yaml基础语法
说明:语法要求严格!
- 空格不能省略
- 以缩进来控制层级关系,只要是左边对齐的一列数据都是同一个层级的。
- 缩进不允许使用tab,只允许空格
- 缩进的空格数不重要,只要相同层级的元素左对齐即可
- 属性和值的大小写都是十分敏感的。
- ‘#’ 表示注释
字面量:普通的值 [ 数字,布尔值,字符串 ]
字面量直接写在后面就可以 , 字符串默认不用加上双引号或者单引号;
k: v
注意:
-
“ ” 双引号,不会转义字符串里面的特殊字符 , 特殊字符会作为本身想表示的意思;
比如 :name: “kuang \n shen” 输出 :kuang 换行 shen
-
‘’ 单引号,会转义特殊字符 , 特殊字符最终会变成和普通字符一样输出
比如 :name: ‘kuang \n shen’ 输出 :kuang \n shen
对象、Map(键值对)
#对象、Map格式
key:
value1:
value2:
在下一行来写对象的属性和值得关系,注意缩进;比如:
student:
name: qinjiang
age: 3
行内写法
student: {name: qinjiang,age: 3}
数组( List、set )
用 - 值表示数组中的一个元素,比如:
pets:
- cat
- dog
- pig
行内写法
pets: [cat,dog,pig]
修改SpringBoot的默认端口号
配置文件中添加,端口号的参数,就可以切换端口;
server:
port: 8082
3、yaml注入配置文件
yaml文件更强大的地方在于,他可以给我们的实体类直接注入匹配值!
1、原始的给实体对象赋值
- 在springboot项目中的resources目录下新建一个文件 application.yml
- 编写一个实体类 User;
@Component //注册bean到容器中,使得这个类可以被扫描到 public class Dog { private String name; private Integer age; //有参无参构造、get、set方法、toString()方法 } - 思考,我们原来是如何给bean注入属性值的!@Value,给User类测试一下:
@Component //注册bean public class Dog { @Value("阿黄") private String name; @Value("18") private Integer age; } - 在SpringBoot的测试类下注入user输出一下
@SpringBootTest class DemoApplicationTests { @Autowired //将狗狗自动注入进来 Dog dog; @Test public void contextLoads() { System.out.println(dog); //打印看下狗狗对象 } }
2、通过yaml文件赋值
-
我们在编写一个复杂一点的实体类:Person 类
@Component //注册bean到容器中 public class Person { private String name; private Integer age; private Boolean happy; private Date birth; private Map<String,Object> maps; private List<Object> lists; private Dog dog; //有参无参构造、get、set方法、toString()方法 } -
我们来使用yaml配置的方式进行注入,大家写的时候注意区别和优势,我们编写一个yaml配置!
person: name: qinjiang age: 3 happy: false birth: 2000/01/01 maps: {k1: v1,k2: v2} lists: - code - girl - music dog: name: 旺财 age: 1 -
我们刚才已经把person这个对象的所有值都写好了,我们现在来注入到我们的类中!
/* @ConfigurationProperties作用: 将配置文件中配置的每一个属性的值,映射到这个组件中; 告诉SpringBoot将本类中的所有属性和配置文件中相关的配置进行绑定 参数 prefix = “person” : 将配置文件中的person下面的所有属性一一对应 */ @Component //注册bean @ConfigurationProperties(prefix = "person") public class Person { private String name; private Integer age; private Boolean happy; private Date birth; private Map<String,Object> maps; private List<Object> lists; private Dog dog; }
-
IDEA 提示,springboot配置注解处理器没有找到,让我们看文档,我们可以查看文档,找到一个依赖!
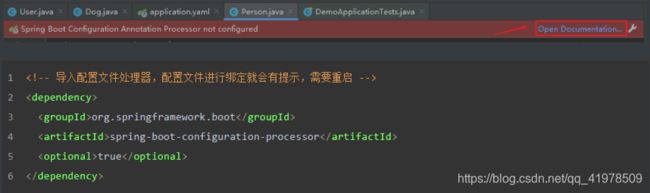
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-configuration-processorartifactId> <optional>trueoptional> dependency> -
确认以上配置都OK之后,我们去测试类中测试一下:
@SpringBootTest
class DemoApplicationTests {
@Autowired
Person person; //将person自动注入进来
@Test
public void contextLoads() {
System.out.println(person); //打印person信息
}
}
结果:所有值全部注入成功!
yaml配置注入到实体类完全OK!
课堂测试:
- 将配置文件的key 值 和 属性的值设置为不一样,则结果输出为null,注入失败
- 在配置一个person2,然后将 @ConfigurationProperties(prefix = “person2”) 指向我们的person2;
4、加载指定的配置文件
@PropertySource:加载指定的配置文件;
@configurationProperties:默认从全局配置文件中获取值;
-
我们去在resources目录下新建一个person.properties文件
注意在使用之前要去setting把字符集调整为UTF-8否则会乱码(在后面的回顾properties配置中有具体写到)
name=zhangyi -
然后在我们的代码中指定加载person.properties文件
@PropertySource(value = "classpath:person.properties") @Component //注册bean public class Person { @Value("${name}")//有点像jsp了哦,EL表达式 private String name; ...... }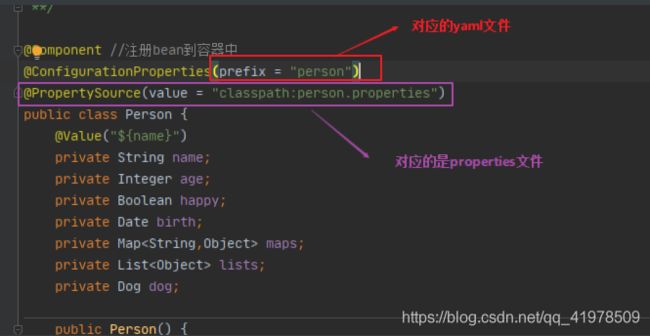
-
再次输出测试一下:指定配置文件绑定成功!

5、 配置文件占位符
配置文件还可以编写占位符生成随机数
person:
name: qinjiang${random.uuid} # 随机uuid
age: ${random.int} # 随机int
happy: false
birth: 2000/01/01
maps: {k1: v1,k2: v2}
lists:
- code
- girl
- music
dog:
name: ${person.hello:other}_旺财
age: 1
6、回顾properties配置
我们上面采用的yaml方法都是最简单的方式,开发中最常用的;也是springboot所推荐的!那我们来唠唠其他的实现方式,道理都是相同的;写还是那样写;配置文件除了yml还有我们之前常用的properties , 我们没有讲,我们来唠唠!
【注意】properties配置文件在写中文的时候,会有乱码 , 我们需要去IDEA中设置编码格式为UTF-8;
settings–>FileEncodings 中配置:

7、Properties和Yaml的对比小结
@Value这个使用起来并不友好!我们需要为每个属性单独注解赋值,比较麻烦;我们来看个功能对比图

- @ConfigurationProperties只需要写一次即可 , @Value则需要每个字段都添加
- 松散绑定:这个什么意思呢? 比如我的yaml中写的last-name,这个和lastName是一样的, - 后面跟着的字母默认是大写的。这就是松散绑定。可以测试一下
- JSR303数据校验 , 这个就是我们可以在字段是增加一层过滤器验证 , 可以保证数据的合法性
- 复杂类型封装,yaml中可以封装对象 , 使用value就不支持。
结论
- 配置yaml和配置properties都可以获取到值 , 但是强烈推荐 yaml;
- 如果我们在某个业务中,只需要获取配置文件中的某个值,可以使用一下 @value;
- 如果说,我们专门编写了一个JavaBean来和配置文件进行一一映射,就直接@configurationProperties,不要犹豫!
5、JSR303数据校验及多环境切换
1、JSR303
JSR303数据校验是用来校验输入内容的
Springboot中可以用@validated来校验数据,如果数据异常则会统一抛出异常,方便异常中心统一处理。我们这里来写个注解让我们的name只能支持Email格式;
@Component //注册bean
@ConfigurationProperties(prefix = "person")
@Validated //数据校验
public class Person {
@Email(message="邮箱格式错误") //name必须是邮箱格式
private String name;
}
如果@Email注解使用不了,需要在pom.xml文件中添加依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-validationartifactId>
dependency>
使用数据校验,可以保证数据的正确性
@NotNull(message="名字不能为空")
private String userName;
@Max(value=120,message="年龄最大不能查过120")
private int age;
@Email(message="邮箱格式错误")
private String email;
空检查
@Null 验证对象是否为null
@NotNull 验证对象是否不为null, 无法查检长度为0的字符串
@NotBlank 检查约束字符串是不是Null还有被Trim的长度是否大于0,只对字符串,且会去掉前后空格.
@NotEmpty 检查约束元素是否为NULL或者是EMPTY.
Booelan检查
@AssertTrue 验证 Boolean 对象是否为 true
@AssertFalse 验证 Boolean 对象是否为 false
长度检查
@Size(min=, max=) 验证对象(Array,Collection,Map,String)长度是否在给定的范围之内
@Length(min=, max=) string is between min and max included.
日期检查
@Past 验证 Date 和 Calendar 对象是否在当前时间之前
@Future 验证 Date 和 Calendar 对象是否在当前时间之后
@Pattern 验证 String 对象是否符合正则表达式的规则
.......等等
除此以外,我们还可以自定义一些数据校验规则
2、多环境切换
profile是Spring对不同环境提供不同配置功能的支持,可以通过激活不同的环境版本,实现快速切换环境;
我们在主配置文件编写的时候,文件名可以是 application-{profile}.properties/yml , 用来指定多个环境版本;
例如:
- application-test.properties 代表测试环境配置
- application-dev.properties 代表开发环境配置
- 但是Springboot并不会直接启动这些配置文件,它默认使用application.properties主配置文件;
- 我们需要通过一个配置来选择需要激活的环境:
#比如在配置文件中指定使用dev环境,我们可以通过设置不同的端口号进行测试;#我们启动SpringBoot,就可以看到已经切换到dev下的配置了; spring.profiles.active=dev
3、yaml的多文档块
和properties配置文件中一样,但是使用yml去实现不需要创建多个配置文件,更加方便了 !
通过—来分割模块
server:
port: 8081
#选择要激活那个环境块
spring:
profiles:
active: prod
---
server:
port: 8083
spring:
profiles: dev #配置环境的名称
---
server:
port: 8084
spring:
profiles: prod #配置环境的名称
注意:如果yml和properties同时都配置了端口,并且没有激活其他环境 , 默认会使用properties配置文件的!
配置文件加载位置
外部加载配置文件的方式十分多,我们选择最常用的即可,在开发的资源文件中进行配置!
官方外部配置文件说明参考文档

springboot 启动会扫描以下位置的application.properties或者application.yml文件作为Spring boot的默认配置文件:
优先级1:项目路径下的config文件夹配置文件
优先级2:项目路径下配置文件
优先级3:资源路径下的config文件夹配置文件
优先级4:资源路径下配置文件
优先级由高到底,高优先级的配置会覆盖低优先级的配置;
SpringBoot会从这四个位置全部加载主配置文件;互补配置;
4、拓展,运维小技巧
指定位置加载配置文件
我们还可以通过spring.config.location来改变默认的配置文件位置
项目打包好以后,我们可以使用命令行参数的形式,启动项目的时候来指定配置文件的新位置;这种情况,一般是后期运维做的多,相同配置,外部指定的配置文件优先级最高
java -jar spring-boot-config.jar --spring.config.location=F:/application.properties
6、自动配置原理
配置文件到底能写什么?怎么写?
SpringBoot官方文档中有大量的配置,我们无法全部记住
1、分析自动配置原理
我们以HttpEncodingAutoConfiguration(Http编码自动配置)为例解释自动配置原理;
@Configuration //表示这是一个配置类,和以前编写的配置文件一样,也可以给容器中添加组件;
//启动指定类的ConfigurationProperties功能;
//进入这个HttpProperties查看,将配置文件中对应的值和HttpProperties绑定起来;
//并把HttpProperties加入到ioc容器中
@EnableConfigurationProperties({HttpProperties.class})
//Spring底层@Conditional注解
//根据不同的条件判断,如果满足指定的条件,整个配置类里面的配置就会生效;
//这里的意思就是判断当前应用是否是web应用,如果是,当前配置类生效
@ConditionalOnWebApplication(type = Type.SERVLET)
//判断当前项目有没有这个类CharacterEncodingFilter;SpringMVC中进行乱码解决的过滤器;
@ConditionalOnClass({CharacterEncodingFilter.class})
//判断配置文件中是否存在某个配置:spring.http.encoding.enabled;
//如果不存在,判断也是成立的
//即使我们配置文件中不配置spring.http.encoding.enabled=true,也是默认生效的;
@ConditionalOnProperty(
prefix = "spring.http.encoding",
value = {"enabled"},
matchIfMissing = true
)
public class HttpEncodingAutoConfiguration {
//他已经和SpringBoot的配置文件映射了
private final Encoding properties;
//只有一个有参构造器的情况下,参数的值就会从容器中拿
public HttpEncodingAutoConfiguration(HttpProperties properties) {
this.properties = properties.getEncoding();
}
//给容器中添加一个组件,这个组件的某些值需要从properties中获取
@Bean
@ConditionalOnMissingBean //判断容器没有这个组件?
public CharacterEncodingFilter characterEncodingFilter() {
CharacterEncodingFilter filter = new OrderedCharacterEncodingFilter();
filter.setEncoding(this.properties.getCharset().name());
filter.setForceRequestEncoding(this.properties.shouldForce(org.springframework.boot.autoconfigure.http.HttpProperties.Encoding.Type.REQUEST));
filter.setForceResponseEncoding(this.properties.shouldForce(org.springframework.boot.autoconfigure.http.HttpProperties.Encoding.Type.RESPONSE));
return filter;
}
//。。。。。。。
}
一句话总结 :根据当前不同的条件判断,决定这个配置类是否生效!
- 一但这个配置类(例如:HttpEncodingAutoConfiguration)生效;这个配置类就会给容器中添加各种组件;
- 这些组件的属性是从对应的properties类中获取的,(@EnableConfigurationProperties({HttpProperties.class}) )
- 这些类里面的每一个属性又是和配置文件绑定的(采用yaml注入,@ConfigurationProperties(prefix = “person”));
- 这样就可以形成我们的配置文件可以动态的修改springboot的内容。
- 所有在配置文件中能配置的属性都是在xxxxProperties类中封装着;
- 配置文件能配置什么就可以参照某个功能对应的这个properties属性类
配置类—>对应一个properties类---->yaml配置文件注入
通俗理解:把我们原先需要在bean中手打的属性(property)封装成了一个类,然后通过yaml文件进行自动注入,而我们也可以在application.yaml文件中对这些property进行赋值。
2、精髓
- SpringBoot启动时会加载大量的自动配置类
- 我们看我们需要的功能有没有在SpringBoot默认写好的自动配置类当中
- 我们再来看这个自动配置类中到底配置了哪些组件;(只要我们要用的组件存在其中,我们就不需要再去手动配置了,如果不存在我们再手动配置)
- 给容器中自动配置类添加组件的时候,会从properties类中获取某些属性,我们只需要在配置文件中指定这些属性即可;
- XXXXAutoConfiguration:自动配置类:给容器添加组件,这些组件要赋值就需要绑定一个XXXXProperties类
- XXXXProperties:里面封装配置文件中相关属性;
- 我们修改yaml配置文件,然后属性值会自动注入到绑定的XXXXProperties
怎么去修改这些属性呢:说白了就是SpringBoot配置,---->.yaml、.properties这些文件
3、@Conditional
了解完自动装配的原理后,我们来关注一个细节问题,自动配置类必须在一定的条件下才能生效;
@Conditional派生注解(Spring注解版原生的@Conditional作用)
作用:必须是@Conditional指定的条件成立,才给容器中添加组件,配置类里面的所有内容才生效;
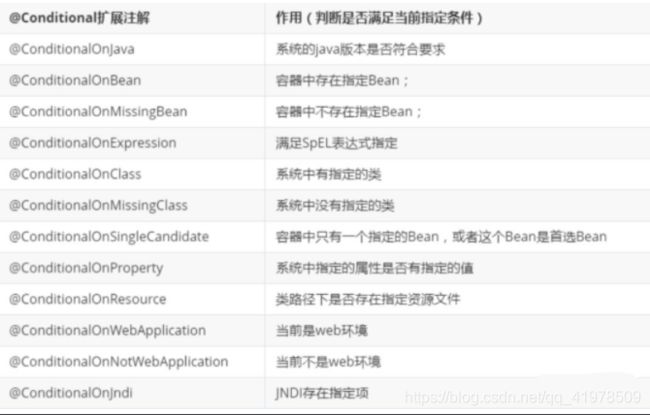
那么多的自动配置类,必须在一定的条件下才能生效;也就是说,我们加载了这么多的配置类,但不是所有的都生效了。
我们怎么知道哪些自动配置类生效?
我们可以通过启用 debug=true属性;来让控制台打印自动配置报告,这样我们就可以很方便的知道哪些自动配置类生效;
#开启springboot的调试类
debug=true
Positive matches:(自动配置类启用的:正匹配)
Negative matches:(没有启动,没有匹配成功的自动配置类:负匹配)
Unconditional classes: (没有条件的类)
【演示:查看输出的日志】
4、自定义Starter启动器
我们分析完毕了源码以及自动装配的过程,我们可以尝试自定义一个启动器来玩玩!
启动器模块是一个 空 jar 文件,仅提供辅助性依赖管理,这些依赖可能用于自动装配或者其他类库;
命名归约:
官方命名:
- 前缀:spring-boot-starter-xxx
- 比如:spring-boot-starter-web…
自定义命名:
- xxx-spring-boot-starter
- 比如:mybatis-spring-boot-starter
7、SpringBoot Web开发总览
在之前我们的项目都是以jar包结尾的,没有放webapp的地方。
springboot最大的特点:自动装配
- 创建应用,选择模块导入starter,只需要专注于业务代码
springboot到底帮我们配置了什么,我们能不能修改?能修改哪些东西?能不能扩展- xxxAutoConfiguration:向容器中自动配置组件
- xxxProperties:自动配置类,装配配置文件中自定义的一些内容
要解决的问题:
- 导入静态资源html,css,js
- 首页
- 写jsp的地方,模板引擎Thymeleaf
- 装配和扩展SpringMVC
- 增删改查
- 拦截器
1、Web开发静态资源处理
Web开发静态资源处理
首先,我们搭建一个普通的SpringBoot项目,回顾一下HelloWorld程序!
写请求非常简单,那我们要引入我们前端资源,我们项目中有许多的静态资源,比如css,js等文件,这个SpringBoot怎么处理呢?
如果我们是一个web应用,我们的main下会有一个webapp,我们以前都是将所有的页面导在这里面的,对吧!但是我们现在的pom呢,打包方式是为jar的方式,那么这种方式SpringBoot能不能来给我们写页面呢?当然是可以的,但是SpringBoot对于静态资源放置的位置,是有规定的!
我们先来聊聊这个静态资源映射规则:
SpringBoot中,SpringMVC的web配置都在 WebMvcAutoConfiguration 这个配置类里面;
我们可以去看看 WebMvcAutoConfigurationAdapter 中有很多配置方法;
有一个方法:addResourceHandlers 添加资源处理
SpringBoot中,SpringMVC的web配置都在 WebMvcAutoConfiguration 这个配置类里面;
我们可以去看看 WebMvcAutoConfigurationAdapter 中有很多配置方法;、
有一个方法:addResourceHandlers 添加资源处理
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
if (!this.resourceProperties.isAddMappings()) {
// 已禁用默认资源处理
logger.debug("Default resource handling disabled");
return;
}
// 缓存控制
Duration cachePeriod = this.resourceProperties.getCache().getPeriod();
CacheControl cacheControl = this.resourceProperties.getCache().getCachecontrol().toHttpCacheControl();
// webjars 配置
if (!registry.hasMappingForPattern("/webjars/**")) {
customizeResourceHandlerRegistration(registry.addResourceHandler("/webjars/**")
.addResourceLocations("classpath:/META-INF/resources/webjars/")
.setCachePeriod(getSeconds(cachePeriod)).setCacheControl(cacheControl));
}
// 静态资源配置
String staticPathPattern = this.mvcProperties.getStaticPathPattern();
if (!registry.hasMappingForPattern(staticPathPattern)) {
customizeResourceHandlerRegistration(registry.addResourceHandler(staticPathPattern)
.addResourceLocations(getResourceLocations(this.resourceProperties.getStaticLocations()))
.setCachePeriod(getSeconds(cachePeriod)).setCacheControl(cacheControl));
}
}
读一下源代码:比如所有的 /webjars/** , 都需要去 classpath:/META-INF/resources/webjars/ 找对应的资源;
什么是webjars 呢?
Webjars本质就是以jar包的方式引入我们的静态资源 , 我们以前要导入一个静态资源文件,直接导入即可。
使用SpringBoot需要使用Webjars,我们可以去搜索一下:
网站:https://www.webjars.org
要使用jQuery,我们只要要引入jQuery对应版本的pom依赖即可!
<dependency>
<groupId>org.webjarsgroupId>
<artifactId>jqueryartifactId>
<version>3.4.1version>
dependency>
导入完毕,查看webjars目录结构,并访问Jquery.js文件!
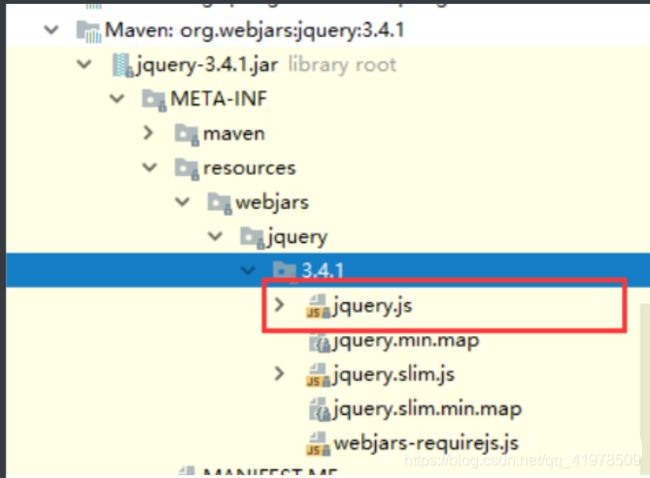
访问:只要是静态资源,SpringBoot就会去对应的路径寻找资源,我们这里访问:http://localhost:8080/webjars/jquery/3.4.1/jquery.js
第二种静态资源映射规则
那我们项目中要是使用自己的静态资源该怎么导入呢?我们看下一行代码;
我们去找staticPathPattern发现第二种映射规则 :/** , 访问当前的项目任意资源,它会去找 resourceProperties 这个类,我们可以点进去看一下分析:
// 进入方法
public String[] getStaticLocations() {
return this.staticLocations;
}
// 找到对应的值
private String[] staticLocations = CLASSPATH_RESOURCE_LOCATIONS;
// 找到路径
private static final String[] CLASSPATH_RESOURCE_LOCATIONS = {
"classpath:/META-INF/resources/",
"classpath:/resources/",
"classpath:/static/",
"classpath:/public/"
};
ResourceProperties 可以设置和我们静态资源有关的参数;这里面指向了它会去寻找资源的文件夹,即上面数组的内容。
所以得出结论,以下四个目录存放的静态资源可以被我们识别:
"classpath:/META-INF/resources/"
"classpath:/resources/"
"classpath:/static/"
"classpath:/public/"
我们可以在resources根目录下新建对应的文件夹,都可以存放我们的静态文件;
比如我们访问 http://localhost:8080/1.js , 他就会去这些文件夹中寻找对应的静态资源文件;
自定义静态资源路径
我们也可以自己通过配置文件来指定一下,哪些文件夹是需要我们放静态资源文件的,在application.properties中配置;
spring.resources.static-locations=classpath:/coding/,classpath:/kuang/
一旦自己定义了静态文件夹的路径,原来的自动配置就都会失效了!
8、Thymeleaf模板引擎
1、模板引擎
前端交给我们的页面,是html页面。如果是我们以前开发,我们需要把他们转成jsp页面,jsp好处就是当我们查出一些数据转发到JSP页面以后,我们可以用jsp轻松实现数据的显示,及交互等。
jsp支持非常强大的功能,包括能写Java代码,但是呢,我们现在的这种情况,SpringBoot这个项目首先是以jar的方式,不是war,像第二,我们用的还是嵌入式的Tomcat,所以呢,他现在默认是不支持jsp的。
那不支持jsp,如果我们直接用纯静态页面的方式,那给我们开发会带来非常大的麻烦,那怎么办呢?
SpringBoot推荐你可以来使用模板引擎:
模板引擎,我们其实大家听到很多,其实jsp就是一个模板引擎,还有用的比较多的freemarker,包括SpringBoot给我们推荐的Thymeleaf,模板引擎有非常多,但再多的模板引擎,他们的思想都是一样的,什么样一个思想呢我们来看一下这张图:
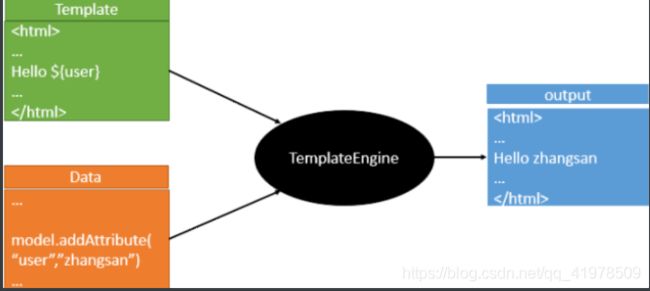
模板引擎的作用就是我们来写一个页面模板,比如有些值呢,是动态的,我们写一些表达式。而这些值,从哪来呢,就是我们在后台封装一些数据。然后把这个模板和这个数据交给我们模板引擎,模板引擎按照我们这个数据帮你把这表达式解析、填充到我们指定的位置,然后把这个数据最终生成一个我们想要的内容给我们写出去,这就是我们这个模板引擎,不管是jsp还是其他模板引擎,都是这个思想。
只不过呢,就是说不同模板引擎之间,他们可能这个语法有点不一样。其他的我就不介绍了,我主要来介绍一下SpringBoot给我们推荐的Thymeleaf模板引擎,这模板引擎呢,是一个高级语言的模板引擎,他的这个语法更简单。而且呢,功能更强大。
我们呢,就来看一下这个模板引擎,那既然要看这个模板引擎。首先,我们来看SpringBoot里边怎么用。
2、 引入Thymeleaf
怎么引入呢,对于springboot来说,什么事情不都是一个start的事情嘛,我们去在项目中引入一下。给大家三个网址:
- Thymeleaf 官网:https://www.thymeleaf.org/
- Thymeleaf 在Github 的主页:https://github.com/thymeleaf/thymeleaf
- Spring官方文档:找到我们对应的版本,https://docs.spring.io/spring-boot/docs/2.2.5.RELEASE/reference/htmlsingle/#using-boot-starter
找到对应的pom依赖:可以适当点进源码看下本来的包!
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
3、Thymeleaf分析
前面呢,我们已经引入了Thymeleaf,那这个要怎么使用呢?
我们首先得按照SpringBoot的自动配置原理看一下我们这个Thymeleaf的自动配置规则,在按照那个规则,我们进行使用。
我们去找一下Thymeleaf的自动配置类:ThymeleafProperties
@ConfigurationProperties(
prefix = "spring.thymeleaf"
)
public class ThymeleafProperties {
private static final Charset DEFAULT_ENCODING;
public static final String DEFAULT_PREFIX = "classpath:/templates/";
public static final String DEFAULT_SUFFIX = ".html";
private boolean checkTemplate = true;
private boolean checkTemplateLocation = true;
private String prefix = "classpath:/templates/";
private String suffix = ".html";
private String mode = "HTML";
private Charset encoding;
}
我们可以在其中看到默认的前缀和后缀!
我们只需要把我们的html页面放在类路径下的templates下,thymeleaf就可以帮我们自动渲染了。
使用thymeleaf什么都不需要配置,只需要将他放在指定的文件夹下即可!
测试
-
编写一个TestController
@Controller public class TestController { @RequestMapping("/t1") public String test1(){ //classpath:/templates/test.html return "test"; } } -
编写一个测试页面 test.html 放在 templates 目录下
DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Titletitle> head> <body> <h1>testh1> body> html> -
启动项目请求测试
4、Thymeleaf 语法学习
要学习语法,还是参考官网文档最为准确,我们找到对应的版本看一下;
Thymeleaf 官网:https://www.thymeleaf.org/ , 简单看一下官网!我们去下载Thymeleaf的官方文档!
我们做个最简单的练习 :我们需要查出一些数据,在页面中展示
-
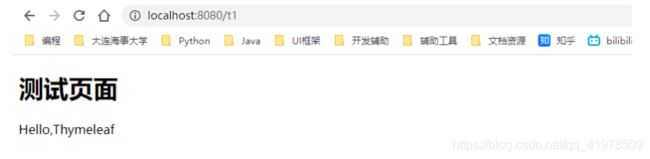
修改测试请求,增加数据传输;
@RequestMapping("/t1") public String test1(Model model){ //存入数据 model.addAttribute("msg","Hello,Thymeleaf"); //classpath:/templates/test.html return "test"; } -
我们要使用thymeleaf,需要在html文件中导入命名空间的约束,方便提示。
我们可以去官方文档的#3中看一下命名空间拿来过来:xmlns:th="http://www.thymeleaf.org" -
我们去编写下前端页面
DOCTYPE html> <html lang="en" xmlns:th="http://www.thymeleaf.org"> <head> <meta charset="UTF-8"> <title>Guotitle> head> <body> <h1>测试页面h1> <div th:text="${msg}">div> body> html>
OK,入门搞定,我们来认真研习一下Thymeleaf的使用语法!
-
我们可以使用任意的 th:attr 来替换Html中原生属性的值!
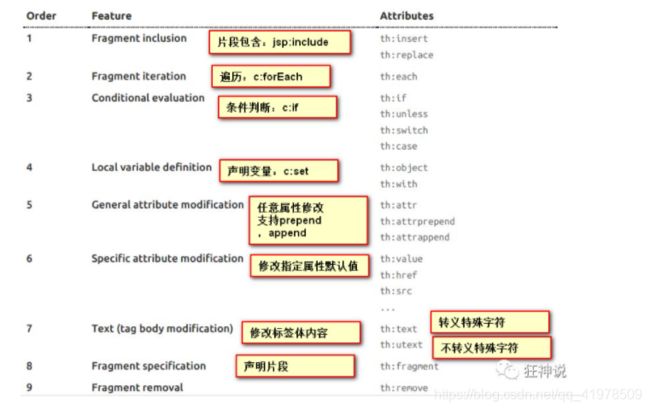
-
我们能写哪些表达式呢?
Simple expressions:(表达式语法) Variable Expressions: ${...}:获取变量值;OGNL; 1)、获取对象的属性、调用方法 2)、使用内置的基本对象:#18 #ctx : the context object. #vars: the context variables. #locale : the context locale. #request : (only in Web Contexts) the HttpServletRequest object. #response : (only in Web Contexts) the HttpServletResponse object. #session : (only in Web Contexts) the HttpSession object. #servletContext : (only in Web Contexts) the ServletContext object. 3)、内置的一些工具对象: #execInfo : information about the template being processed. #uris : methods for escaping parts of URLs/URIs #conversions : methods for executing the configured conversion service (if any). #dates : methods for java.util.Date objects: formatting, component extraction, etc. #calendars : analogous to #dates , but for java.util.Calendar objects. #numbers : methods for formatting numeric objects. #strings : methods for String objects: contains, startsWith, prepending/appending, etc. #objects : methods for objects in general. #bools : methods for boolean evaluation. #arrays : methods for arrays. #lists : methods for lists. #sets : methods for sets. #maps : methods for maps. #aggregates : methods for creating aggregates on arrays or collections. ================================================================================== Selection Variable Expressions: *{...}:选择表达式:和${}在功能上是一样; Message Expressions: #{...}:获取国际化内容 Link URL Expressions: @{...}:定义URL; Fragment Expressions: ~{...}:片段引用表达式 Literals(字面量) Text literals: 'one text' , 'Another one!' ,… Number literals: 0 , 34 , 3.0 , 12.3 ,… Boolean literals: true , false Null literal: null Literal tokens: one , sometext , main ,… Text operations:(文本操作) String concatenation: + Literal substitutions: |The name is ${name}| Arithmetic operations:(数学运算) Binary operators: + , - , * , / , % Minus sign (unary operator): - Boolean operations:(布尔运算) Binary operators: and , or Boolean negation (unary operator): ! , not Comparisons and equality:(比较运算) Comparators: > , < , >= , <= ( gt , lt , ge , le ) Equality operators: == , != ( eq , ne ) Conditional operators:条件运算(三元运算符) If-then: (if) ? (then) If-then-else: (if) ? (then) : (else) Default: (value) ?: (defaultvalue) Special tokens: No-Operation: _
9、SpringMVC自动配置原理
1、自动配置原理
在进行项目编写前,我们还需要知道一个东西,就是SpringBoot对我们的SpringMVC还做了哪些配置,包括如何扩展,如何定制。
只有把这些都搞清楚了,我们在之后使用才会更加得心应手。途径一:源码分析,途径二:官方文档!
Spring MVC Auto-configuration
// Spring Boot为Spring MVC提供了自动配置,它可以很好地与大多数应用程序一起工作。
Spring Boot provides auto-configuration for Spring MVC that works well with most applications.
// 自动配置在Spring默认设置的基础上添加了以下功能:
The auto-configuration adds the following features on top of Spring’s defaults:
// 包含视图解析器
Inclusion of ContentNegotiatingViewResolver and BeanNameViewResolver beans.
// 支持静态资源文件夹的路径,以及webjars
Support for serving static resources, including support for WebJars
// 自动注册了Converter:
// 转换器,这就是我们网页提交数据到后台自动封装成为对象的东西,比如把"1"字符串自动转换为int类型
// Formatter:【格式化器,比如页面给我们了一个2019-8-10,它会给我们自动格式化为Date对象】
Automatic registration of Converter, GenericConverter, and Formatter beans.
// HttpMessageConverters
// SpringMVC用来转换Http请求和响应的的,比如我们要把一个User对象转换为JSON字符串,可以去看官网文档解释;
Support for HttpMessageConverters (covered later in this document).
// 定义错误代码生成规则的
Automatic registration of MessageCodesResolver (covered later in this document).
// 首页定制
Static index.html support.
// 图标定制
Custom Favicon support (covered later in this document).
// 初始化数据绑定器:帮我们把请求数据绑定到JavaBean中!
Automatic use of a ConfigurableWebBindingInitializer bean (covered later in this document).
/*
如果您希望保留Spring Boot MVC功能,并且希望添加其他MVC配置(拦截器、格式化程序、视图控制器和其他功能),则可以添加自己
的@configuration类,类型为webmvcconfiguer,但不添加@EnableWebMvc。如果希望提供
RequestMappingHandlerMapping、RequestMappingHandlerAdapter或ExceptionHandlerExceptionResolver的自定义
实例,则可以声明WebMVCregistrationAdapter实例来提供此类组件。
*/
If you want to keep Spring Boot MVC features and you want to add additional MVC configuration
(interceptors, formatters, view controllers, and other features), you can add your own
@Configuration class of type WebMvcConfigurer but without @EnableWebMvc. If you wish to provide
custom instances of RequestMappingHandlerMapping, RequestMappingHandlerAdapter, or
ExceptionHandlerExceptionResolver, you can declare a WebMvcRegistrationsAdapter instance to provide such components.
// 如果您想完全控制Spring MVC,可以添加自己的@Configuration,并用@EnableWebMvc进行注释。
If you want to take complete control of Spring MVC, you can add your own @Configuration annotated with @EnableWebMvc.
我们来仔细对照,看一下它怎么实现的,它告诉我们SpringBoot已经帮我们自动配置好了SpringMVC,然后自动配置了哪些东西呢?
ContentNegotiatingViewResolver 内容协商视图解析器
自动配置了ViewResolver,就是我们之前学习的SpringMVC的视图解析器;
即根据方法的返回值取得视图对象(View),然后由视图对象决定如何渲染(转发,重定向)。
所以得出结论:ContentNegotiatingViewResolver 这个视图解析器就是用来组合所有的视图解析器的
2、转换器和格式化器
如果配置了自己的格式化方式,就会注册到Bean中生效,我们可以在配置文件中配置日期格式化的规则:

3、修改SpringBoot的默认配置
这么多的自动配置,原理都是一样的,通过这个WebMVC的自动配置原理分析,我们要学会一种学习方式,通过源码探究,得出结论;这个结论一定是属于自己的,而且一通百通。
SpringBoot的底层,大量用到了这些设计细节思想,所以,没事需要多阅读源码!得出结论;
SpringBoot在自动配置很多组件的时候,先看容器中有没有用户自己配置的(如果用户自己配置@bean),如果有就用用户配置的,如果没有就用自动配置的;
如果有些组件可以存在多个,比如我们的视图解析器,就将用户配置的和自己默认的组合起来!
扩展使用SpringMVC
我们要做的就是编写一个@Configuration注解类,并且类型要为WebMvcConfigurer,还不能标注@EnableWebMvc注解;我们去自己写一个;我们新建一个包叫config,写一个类MyMvcConfig;
//应为类型要求为WebMvcConfigurer,所以我们实现其接口
//可以使用自定义类扩展MVC的功能
@Configuration
public class MyMvcConfig implements WebMvcConfigurer {
@Override
public void addViewControllers(ViewControllerRegistry registry) {
// 浏览器发送/test , 就会跳转到test页面;
registry.addViewController("/test").setViewName("test");
}
}
我们去浏览器访问一下:

确实也跳转过来了!所以说,我们要扩展SpringMVC,官方就推荐我们这么去使用,既保SpringBoot留所有的自动配置,也能用我们扩展的配置!
4、全面接管SpringMVC
全面接管即:SpringBoot对SpringMVC的自动配置不需要了,所有都是我们自己去配置!
只需在我们的配置类中要加一个@EnableWebMvc。
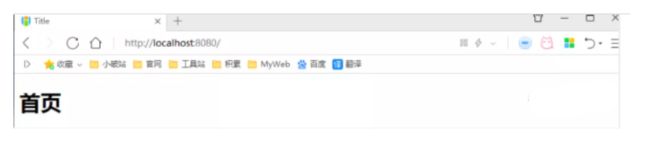
我们看下如果我们全面接管了SpringMVC了,我们之前SpringBoot给我们配置的静态资源映射一定会无效,我们可以去测试一下;
不加注解之前,访问首页:
给配置类加上注解:@EnableWebMvc
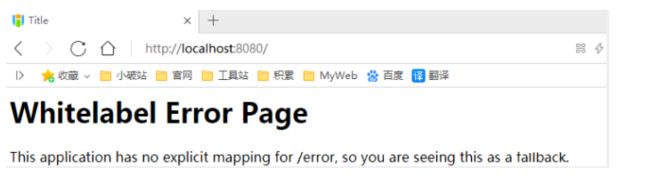
我们发现所有的SpringMVC自动配置都失效了!回归到了最初的样子;
当然,我们开发中,不推荐使用全面接管SpringMVC
总结一句话:@EnableWebMvc将WebMvcConfigurationSupport组件导入进来了;
而导入的WebMvcConfigurationSupport只是SpringMVC最基本的功能!
在SpringBoot中会有非常多的扩展配置,只要看见了这个,我们就应该多留心注意~
10、SpringBoot整合数据库操作
1、整合JDBC
1、SpringData简介
对于数据访问层,无论是 SQL(关系型数据库) 还是 NOSQL(非关系型数据库),Spring Boot 底层都是采用 Spring Data 的方式进行统一处理。
Spring Boot 底层都是采用 Spring Data 的方式进行统一处理各种数据库,Spring Data 也是 Spring 中与 Spring Boot、Spring Cloud 等齐名的知名项目。
2、整合JDBC
创建测试项目测试数据源
- 我去新建一个项目测试:springboot-data-jdbc ; 引入相应的模块!基础模块
- 项目建好之后,发现自动帮我们导入了如下的启动器
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-jdbcartifactId> dependency> <dependency> <groupId>mysqlgroupId> <artifactId>mysql-connector-javaartifactId> <scope>runtimescope> dependency> - 编写yaml配置文件连接数据库;
spring: datasource: username: root password: "000000" driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useSSL=false&useUnicode=true&characterEncoding=UTF-8 - 配置完这一些东西后,我们就可以直接去使用了,因为SpringBoot已经默认帮我们进行了自动配置;去测试类测试一下
@SpringBootTest class Springboot03JdbcApplicationTests { @Autowired DataSource dataSource; @Test void contextLoads() throws SQLException { System.out.println(dataSource.getClass()); Connection connection = dataSource.getConnection(); System.out.println(connection); connection.close(); }
执行结果:
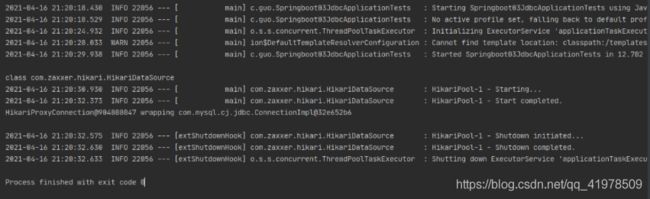
这里注意小坑,密码要用引号引起来,不引起来会报错:
java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)
结果:我们可以看到他默认给我们配置的数据源为 : class com.zaxxer.hikari.HikariDataSource , 我们并没有手动配置
我们来全局搜索一下,找到数据源的所有自动配置都在 :DataSourceAutoConfiguration文件:
@Import(
{Hikari.class, Tomcat.class, Dbcp2.class, Generic.class, DataSourceJmxConfiguration.class}
)
protected static class PooledDataSourceConfiguration {
protected PooledDataSourceConfiguration() {
}
}
这里导入的类都在 DataSourceConfiguration 配置类下,可以看出 Spring Boot 2.2.5 默认使用HikariDataSource 数据源,而以前版本,如 Spring Boot 1.5 默认使用 org.apache.tomcat.jdbc.pool.DataSource 作为数据源;
HikariDataSource 号称 Java WEB 当前速度最快的数据源,相比于传统的 C3P0 、DBCP、Tomcat jdbc 等连接池更加优秀;
可以使用 spring.datasource.type 指定自定义的数据源类型,值为 要使用的连接池实现的完全限定名。
关于数据源我们并不做介绍,有了数据库连接,显然就可以 CRUD 操作数据库了。但是我们需要先了解一个对象 JdbcTemplate
3、JDBCTemplate
- 有了数据源(com.zaxxer.hikari.HikariDataSource),然后可以拿到数据库连接(java.sql.Connection),有了连接,就可以使用原生的 JDBC 语句来操作数据库;
- 即使不使用第三方第数据库操作框架,如 MyBatis等,Spring 本身也对原生的JDBC 做了轻量级的封装,即JdbcTemplate。
- 数据库操作的所有 CRUD 方法都在 JdbcTemplate 中。
- Spring Boot 不仅提供了默认的数据源,同时默认已经配置好了 JdbcTemplate 放在了容器中,程序员只需自己注入即可使用
- dbcTemplate 的自动配置是依赖 org.springframework.boot.autoconfigure.jdbc 包下的 JdbcTemplateConfiguration 类
JdbcTemplate主要提供以下几类方法:
- execute方法:可以用于执行任何SQL语句,一般用于执行DDL语句;
- update方法及batchUpdate方法:update方法用于执行新增、修改、删除等语句;batchUpdate方法用于执行批处理相关语句;
- query方法及queryForXXX方法:用于执行查询相关语句;
- call方法:用于执行存储过程、函数相关语句。
4、测试
编写一个Controller,注入 jdbcTemplate,编写测试方法进行访问测试;
@RestController
@RequestMapping("/jdbc")
public class JdbcController {
/**
* Spring Boot 默认提供了数据源,默认提供了 org.springframework.jdbc.core.JdbcTemplate
* JdbcTemplate 中会自己注入数据源,用于简化 JDBC操作
* 还能避免一些常见的错误,使用起来也不用再自己来关闭数据库连接
*/
@Autowired
JdbcTemplate jdbcTemplate;
//查询employee表中所有数据
//List 中的1个 Map 对应数据库的 1行数据
//Map 中的 key 对应数据库的字段名,value 对应数据库的字段值
@GetMapping("/list")
public List<Map<String, Object>> userList(){
String sql = "select * from employee";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
return maps;
}
//新增一个用户
@GetMapping("/add")
public String addUser(){
//插入语句,注意时间问题
String sql = "insert into employee(last_name, email,gender,department,birth)" +
" values ('狂神说','[email protected]',1,101,'"+ new Date().toLocaleString() +"')";
jdbcTemplate.update(sql);
//查询
return "addOk";
}
//修改用户信息
@GetMapping("/update/{id}")
public String updateUser(@PathVariable("id") int id){
//插入语句
String sql = "update employee set last_name=?,email=? where id="+id;
//数据
Object[] objects = new Object[2];
objects[0] = "秦疆";
objects[1] = "[email protected]";
jdbcTemplate.update(sql,objects);
//查询
return "updateOk";
}
//删除用户
@GetMapping("/delete/{id}")
public String delUser(@PathVariable("id") int id){
//插入语句
String sql = "delete from employee where id=?";
jdbcTemplate.update(sql,id);
//查询
return "deleteOk";
}
}
2、整合Druid数据源
1、Druid简介
Java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池。
Druid 是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控。
Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
Spring Boot 2.0 以上默认使用 Hikari 数据源,可以说 Hikari 与 Driud 都是当前 Java Web 上最优秀的数据源,我们来重点介绍 Spring Boot 如何集成 Druid 数据源,如何实现数据库监控。
com.alibaba.druid.pool.DruidDataSource 基本配置参数如下:
2、配置数据源
-
添加上 Druid 数据源依赖
<dependency> <groupId>com.alibabagroupId> <artifactId>druidartifactId> <version>1.1.21version> dependency> -
切换数据源;之前已经说过 Spring Boot 2.0 以上默认使用 com.zaxxer.hikari.HikariDataSource 数据源,但可以 通过 spring.datasource.type 指定数据源。
spring: datasource: username: root password: "000000" driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true type: com.alibaba.druid.pool.DruidDataSource -
数据源切换之后,在测试类中注入 DataSource,然后获取到它,输出一看便知是否成功切换;
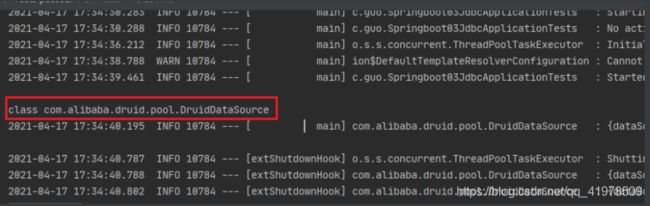
-
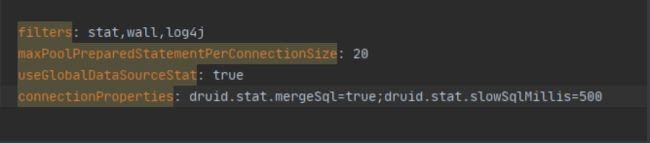
切换成功!既然切换成功,就可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等设置项;可以查看源码
#Spring Boot 默认是不注入这些属性值的,需要自己绑定 #druid 数据源专有配置 initialSize: 5 minIdle: 5 maxActive: 20 maxWait: 60000 timeBetweenEvictionRunsMillis: 60000 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 FROM DUAL testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: true #配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入 #如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority #则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4j filters: stat,wall,log4j maxPoolPreparedStatementPerConnectionSize: 20 useGlobalDataSourceStat: true connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500这些配置是核心:
-
看到需要用到log4j,所以需要在pom中导入log4j的依赖
<dependency> <groupId>log4jgroupId> <artifactId>log4jartifactId> <version>1.2.17version> dependency> -
现在需要程序员自己为 DruidDataSource 绑定全局配置文件中的参数,再添加到容器中,而不再使用 Spring Boot 的自动生成了;我们需要 自己添加 DruidDataSource 组件到容器中,并绑定属性;
@Configuration public class DruidConfig { /* 将自定义的 Druid数据源添加到容器中,不再让 Spring Boot 自动创建 绑定全局配置文件中的 druid 数据源属性到 com.alibaba.druid.pool.DruidDataSource从而让它们生效 @ConfigurationProperties(prefix = "spring.datasource"):作用就是将 全局配置文件中 前缀为 spring.datasource的属性值注入到 com.alibaba.druid.pool.DruidDataSource 的同名参数中 */ @ConfigurationProperties(prefix = "spring.datasource") @Bean public DataSource druidDataSource() { return new DruidDataSource(); } } -
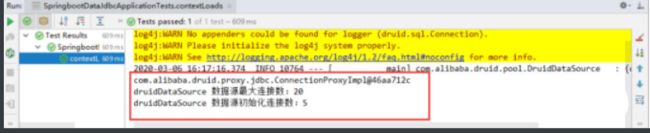
去测试类中测试一下;看是否成功!
@SpringBootTest class SpringbootDataJdbcApplicationTests { //DI注入数据源 @Autowired DataSource dataSource; @Test public void contextLoads() throws SQLException { //看一下默认数据源 System.out.println(dataSource.getClass()); //获得连接 Connection connection = dataSource.getConnection(); System.out.println(connection); DruidDataSource druidDataSource = (DruidDataSource) dataSource; System.out.println("druidDataSource 数据源最大连接数:" + druidDataSource.getMaxActive()); System.out.println("druidDataSource 数据源初始化连接数:" + druidDataSource.getInitialSize()); //关闭连接 connection.close(); } }
3、配置Druid数据源监控
//配置 Druid 监控管理后台的Servlet;
//内置 Servlet 容器时没有web.xml文件,所以使用 Spring Boot 的注册 Servlet 方式
@Bean
public ServletRegistrationBean statViewServlet() {
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
// 这些参数可以在 com.alibaba.druid.support.http.StatViewServlet
// 的父类 com.alibaba.druid.support.http.ResourceServlet 中找到
Map<String, String> initParams = new HashMap<>();
initParams.put("loginUsername", "admin"); //后台管理界面的登录账号
initParams.put("loginPassword", "123456"); //后台管理界面的登录密码
//后台允许谁可以访问
//initParams.put("allow", "localhost"):表示只有本机可以访问
//initParams.put("allow", ""):为空或者为null时,表示允许所有访问
initParams.put("allow", "");
//deny:Druid 后台拒绝谁访问
//initParams.put("kuangshen", "192.168.1.20");表示禁止此ip访问
//设置初始化参数
bean.setInitParameters(initParams);
return bean;
}
配置完毕后,我们可以选择访问 :http://localhost:8080/druid/login.html
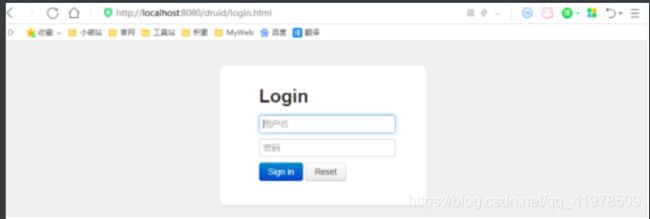
在访问http://localhost:8080/userList 后:

4、配置 Druid web 监控 filter 过滤器
//配置 Druid 监控 之 web 监控的 filter
//WebStatFilter:用于配置Web和Druid数据源之间的管理关联监控统计
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//exclusions:设置哪些请求进行过滤排除掉,从而不进行统计
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*,/jdbc/*");
bean.setInitParameters(initParams);
//"/*" 表示过滤所有请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
注意点:DruidConfig文件一定要添加配置注解,在里面配置的一些servlet和filter都要添加@Bean注解
3、整合Mybatis
1、整合测试
-
导入 MyBatis 所需要的依赖
<dependency> <groupId>org.mybatis.spring.bootgroupId> <artifactId>mybatis-spring-boot-starterartifactId> <version>2.1.1version> dependency> -
配置数据库连接信息(不变)
spring: datasource: username: root password: "000000" #?serverTimezone=UTC解决时区的报错 url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource #Spring Boot 默认是不注入这些属性值的,需要自己绑定 #druid 数据源专有配置 initialSize: 5 minIdle: 5 maxActive: 20 maxWait: 60000 timeBetweenEvictionRunsMillis: 60000 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 FROM DUAL testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: true #配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入 #如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority #则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4j filters: stat,wall,log4j maxPoolPreparedStatementPerConnectionSize: 20 useGlobalDataSourceStat: true connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500 mybatis: type-aliases-package: com.guo.pojo mapper-locations: classpath:mybatis/mapper/*.xml server: port: 8081 -
测试数据库是否连接成功!
-
创建实体类,导入 Lombok!
User.java@Data @AllArgsConstructor @NoArgsConstructor public class User { private Integer id; private String name; private String pwd; } -
创建mapper目录以及对应的 Mapper 接口
UserMapper.java

@Mapper @Repository public interface UserMapper { public static final int age=18; List<User> queryUserList(); User queryUserById(Integer id); int addUser(User user); int updateUser(User user); int deleteUserById(Integer id); }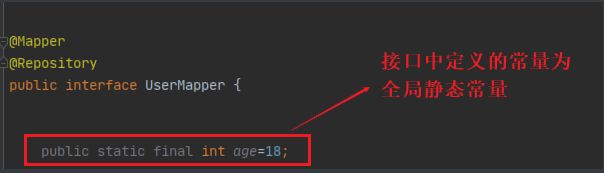
接下来该去配置mapper.xml文件了,这里建议创建在resources的目录下:

UserMapper.xml文件:DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.guo.mapper.UserMapper"> <select id="queryUserList" resultType="User"> select> mapper>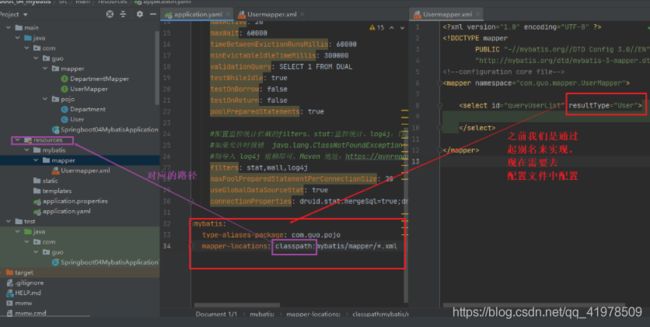
暂时先不写service层,直接写controller调用mapper
@RestController
public class UserController {
@Autowired
private UserMapper userMapper;
@RequestMapping("/list")
public List<User> List(){
return userMapper.queryUserList();
}
}
11、SpringSecurity(安全)
一个安全的框架,其实通过过滤器和拦截器也可以实现
Spring Security是一个功能强大且高度可定制的身份验证和访问控制框架。它实际上是保护基于spring的应用程序的标准。
Spring Security是一个框架,侧重于为Java应用程序提供身份验证和授权。与所有Spring项目一样,Spring安全性的真正强大之处在于它可以轻松地扩展以满足定制需求
在用户认证方面,Spring Security 框架支持主流的认证方式,包括 HTTP 基本认证、HTTP 表单验证、HTTP 摘要认证、OpenID 和 LDAP 等。在用户授权方面,Spring Security 提供了基于角色的访问控制和访问控制列表(Access Control List,ACL),可以对应用中的领域对象进行细粒度的控制。
1、认识SpringSecurity
Spring Security 是针对Spring项目的安全框架,也是Spring Boot底层安全模块默认的技术选型,他可以实现强大的Web安全控制,对于安全控制,我们仅需要引入 spring-boot-starter-security 模块,进行少量的配置,即可实现强大的安全管理!
记住几个类:
- WebSecurityConfigurerAdapter:自定义Security策略
- AuthenticationManagerBuilder:自定义认证策略
- @EnableWebSecurity:开启WebSecurity模式
Spring Security的两个主要目标是 “认证” 和 “授权”(访问控制)。
“认证”(Authentication)
身份验证是关于验证您的凭据,如用户名/用户ID和密码,以验证您的身份。
身份验证通常通过用户名和密码完成,有时与身份验证因素结合使用。
“授权” (Authorization)
授权发生在系统成功验证您的身份后,最终会授予您访问资源(如信息,文件,数据库,资金,位置,几乎任何内容)的完全权限。
这个概念是通用的,而不是只在Spring Security 中存在。
2、实战使用
1、配置页面的访问权限
-
首先导入需要的静态资源:
链接:https://pan.baidu.com/s/1oB9-VKrN4tzh61MtdW5Dow
提取码:clsq
-
引入 SpringSecurity 依赖
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-securityartifactId> dependency> -
新建一个配置文件,并且继承 WebSecurityConfigurerAdapter,并且要添加@EnableWebSecurity注解
@EnableWebSecurity public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http.authorizeRequests() .antMatchers("/").permitAll() .antMatchers("/level1/**").hasAnyRole("vip1") .antMatchers("/level2/**").hasAnyRole("vip2") .antMatchers("/level3/**").hasAnyRole("vip3"); } }注意这里用到了链式
-
测试一下:发现除了首页都进不去了!因为我们目前没有登录的角色,因为请求需要登录的角色拥有对应的权限才可以!
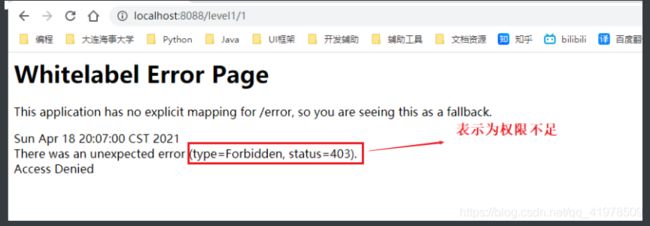
-
在configure()方法中加入以下配置,开启自动配置的登录功能!
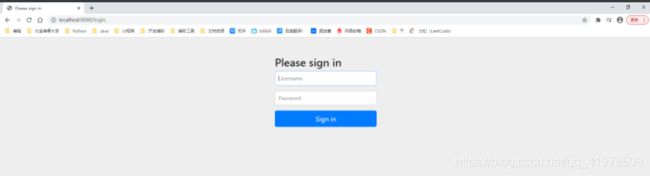
// 开启自动配置的登录功能 // /login 请求来到登录页 // /login?error 重定向到这里表示登录失败 http.formLogin();测试发现没有权限的时候,会跳转到登录的页面:
-
查看刚才登录页的注释信息;
我们可以定义认证规则,重写configure(AuthenticationManagerBuilder auth)方法
也可以去jdbc中去取
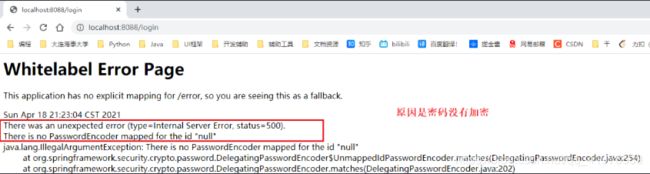
//定义认证规则 @Override protected void configure(AuthenticationManagerBuilder auth) throws Exception { //在内存中定义,也可以在jdbc中去拿.... auth.inMemoryAuthentication() .withUser("kuangshen").password("123456").roles("vip2","vip3") .and() .withUser("root").password("123456").roles("vip1","vip2","vip3") .and() .withUser("guest").password("123456").roles("vip1"); } -
测试,我们可以使用这些账号登录进行测试!发现会报错!
-
原因,我们要将前端传过来的密码进行某种方式加密,否则就无法登录,修改代码
//定义认证规则 @Override protected void configure(AuthenticationManagerBuilder auth) throws Exception { //在内存中定义,也可以在jdbc中去拿.... //Spring security 5.0中新增了多种加密方式,也改变了密码的格式。 //要想我们的项目还能够正常登陆,需要修改一下configure中的代码。我们要将前端传过来的密码进行某种方式加密 //spring security 官方推荐的是使用bcrypt加密方式。 auth.inMemoryAuthentication().passwordEncoder(new BCryptPasswordEncoder()) .withUser("admin").password(new BCryptPasswordEncoder().encode("123456")).roles("vip2","vip3") .and() .withUser("root").password(new BCryptPasswordEncoder().encode("123456")).roles("vip1","vip2","vip3") .and() .withUser("guest").password(new BCryptPasswordEncoder().encode("123456")).roles("vip1","vip2"); }测试,发现,登录成功,并且每个角色只能访问自己认证下的规则!搞定
受权从数据库里读数据:
2、权限控制和注销
-
开启自动配置的注销的功能
//定制请求的授权规则 @Override protected void configure(HttpSecurity http) throws Exception { //.... //开启自动配置的注销的功能 // /logout 注销请求 http.logout(); } -
我们在前端,增加一个注销的按钮,index.html 导航栏中
<a class="item" th:href="@{/logout}"> <i class="sign-out icon">i> 注销 a>
-
我们可以去测试一下,登录成功后点击注销,发现注销完毕会跳转到登录页面!
-
但是,我们想让他注销成功后,依旧可以跳转到首页,该怎么处理呢?
// .logoutSuccessUrl("/"); 注销成功来到首页 http.logout().logoutSuccessUrl("/"); -
测试,注销完毕后,发现跳转到首页OK
-
我们现在又来一个需求:用户没有登录的时候,导航栏上只显示登录按钮,用户登录之后,导航栏可以显示登录的用户信息及注销按钮!还有就是,比如kuangshen这个用户,它只有 vip2,vip3功能,那么登录则只显示这两个功能,而vip1的功能菜单不显示!这个就是真实的网站情况了!该如何做呢?
我们需要结合thymeleaf中的一些功能
sec:authorize=“isAuthenticated()”:是否认证登录!来显示不同的页面
导入thymeleaf和security结合的Maven依赖:
<dependency> <groupId>org.thymeleaf.extrasgroupId> <artifactId>thymeleaf-extras-springsecurity5artifactId> <version>3.0.4.RELEASEversion> dependency> -
修改我们的 前端页面
导入命名空间
xmlns:sec="http://www.thymeleaf.org/thymeleaf-extras-springsecurity5"修改导航栏,增加认证判断
<div class="right menu"> <div sec:authorize="!isAuthenticated()"> <a class="item" th:href="@{/login}"> <i class="address card icon">i> 登录 a> div> <div sec:authorize="isAuthenticated()"> <a class="item"> <i class="address card icon">i> 用户名:<span sec:authentication="principal.username">span> 角色:<span sec:authentication="principal.authorities">span> a> div> <div sec:authorize="isAuthenticated()"> <a class="item" th:href="@{/logout}"> <i class="address card icon">i> 注销 a> div> div> -
重启测试,我们可以登录试试看,登录成功后确实,显示了我们想要的页面;
-
如果注销404了,就是因为它默认防止csrf跨站请求伪造,因为会产生安全问题,我们可以将请求改为post表单提交,或者在spring security中关闭csrf功能;我们试试:在 配置中增加 http.csrf().disable();
SecurityConfig.java
http.csrf().disable();//关闭csrf功能:跨站请求伪造,默认只能通过post方式提交logout请求到目前为止已近实现了权限的访问资源不同,接下来还想实现对不同用户的页面显示内容不同:
关键代码:sec:authorize=“hasRole()//判断当前的权限是否有这个权限直接加在想要设置权限的标签内即可
3、记住我及首页定制
现在的情况,我们只要登录之后,关闭浏览器,再登录,就会让我们重新登录,但是很多网站的情况,就是有一个记住密码的功能,这个该如何实现呢?很简单
-
开启记住我功能
//定制请求的授权规则 @Override protected void configure(HttpSecurity http) throws Exception { //... //记住我 http.rememberMe(); }我们再次启动项目测试一下,发现登录页多了一个记住我功能,我们登录之后关闭 浏览器,然后重新打开浏览器访问,发现用户依旧存在!
思考:如何实现的呢?其实非常简单
我们可以查看浏览器的cookie
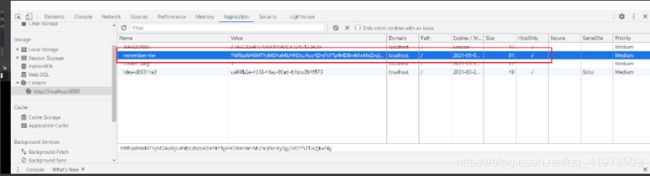
并且可以知道这个cookie的保存日期默认为14天 -
我们点击注销的时候,可以发现,spring security 帮我们自动删除了这个 cookie
结论:登录成功后,将cookie发送给浏览器保存,以后登录带上这个cookie,只要通过检查就可以免登录了。如果点击注销,则会删除这个cookie,具体的原理我们在JavaWeb阶段都讲过了,这里就不在多说了!
4、定制登录页
现在这个登录页面都是spring security 默认的,怎么样可以使用我们自己写的Login界面呢?
- 在刚才的登录页配置后面指定 loginpage
http.formLogin().loginPage("/toLogin"); - 然后前端也需要指向我们自己定义的 login请求
<a class="item" th:href="@{/toLogin}"> <i class="address card icon">i> 登录 a> - 我们登录,需要将这些信息发送到哪里,我们也需要配置,login.html 配置提交请求及方式,方式必须为post:
<form th:action="@{/toLogin}" method="post">
图示解析:

-
这个请求提交上来,我们还需要验证处理,怎么做呢?我们可以查看formLogin()方法的源码!我们配置接收登录的用户名和密码的参数!
例子:比如下列就会出现报错:
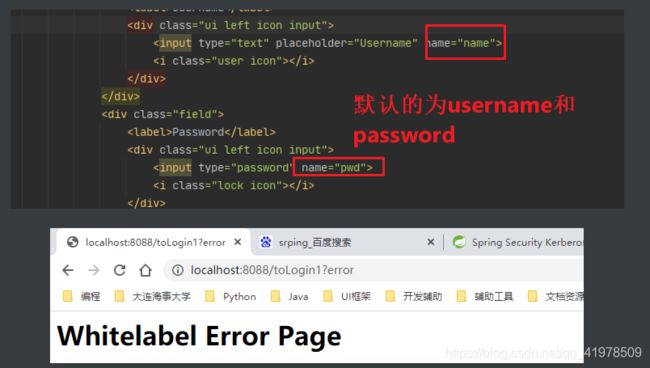
这时就需要去config中设置一下,将对应的字段进行连接
http.formLogin().usernameParameter("name").passwordParameter("pwd").loginPage("/toLogin1"); -
在登录页增加记住我的选择框
<input type="checkbox" name="remember"> 记住我http.rememberMe().rememberMeParameter("remember");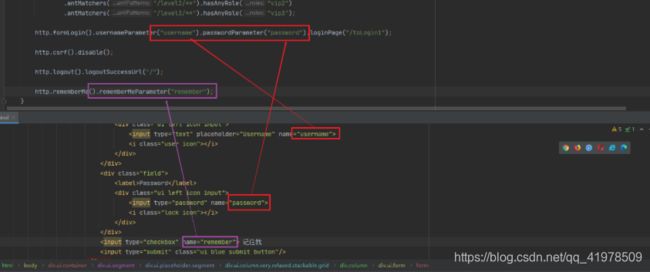
13、Swagger
1、Swagger简介
前后端分离
- 前端 -> 前端控制层、视图层
- 后端 -> 后端控制层、服务层、数据访问层
- 前后端通过API进行交互
- 前后端相对独立,且松耦合
产生的问题
- 前后端集成,前端或者后端无法做到“及时协商,尽早解决”,最终导致问题集中爆发
解决方案
- 首先定义schema [ 计划的提纲 ],并实时跟踪最新的API,降低集成风险
- 早些年制定word计划文档
- 前后端分离:前端测试后端接口:postman
后端提供接口,需要实时更新最新的消息及改动!
Swagger
-
号称世界上最流行的API框架
-
Restful Api 文档在线自动生成器 => API 文档 与API 定义同步更新
-
直接运行,在线测试API接口(其实就是controller requsetmapping)
-
官网:https://swagger.io/
2、Springboot集成Swagger
1、使用Swagger
SpringBoot集成Swagger => springfox,两个jar包
- Springfox-swagger2
- swagger-springmvc
要求:jdk 1.8 + 否则swagger2无法运行
步骤:
-
新建一个SpringBoot-web项目
-
添加Maven依赖
<dependency> <groupId>io.springfoxgroupId> <artifactId>springfox-swagger2artifactId> <version>2.9.2version> dependency> <dependency> <groupId>io.springfoxgroupId> <artifactId>springfox-swagger-uiartifactId> <version>2.9.2version> dependency> -
编写HelloController,测试确保运行成功!
-
要使用Swagger,我们需要编写一个配置类-SwaggerConfig来配置 Swagger
@Configuration //配置类 @EnableSwagger2// 开启Swagger2的自动配置 public class SwaggerConfig { } -
访问测试 :http://localhost:8080/swagger-ui.html ,可以看到swagger的界面;
2、配置Swagger
-
Swagger实例Bean是Docket,所以通过配置Docket实例来配置Swagger,通过Docket对象接管了原来默认的配置
@Bean //配置docket以配置Swagger具体参数 public Docket docket() { return new Docket(DocumentationType.SWAGGER_2); } -
可以通过apiInfo()属性配置文档信息
//配置文档信息 private ApiInfo apiInfo() { Contact contact = new Contact("联系人名字", "http://xxx.xxx.com/联系人访问链接", "联系人邮箱"); return new ApiInfo( "Swagger学习", // 标题 "学习演示如何配置Swagger", // 描述 "v1.0", // 版本 "http://terms.service.url/组织链接", // 组织链接 contact, // 联系人信息 "Apach 2.0 许可", // 许可 "许可链接", // 许可连接 new ArrayList<>()// 扩展 ); } -
Docket 实例关联上 apiInfo()
@Bean public Docket docket() { return new Docket(DocumentationType.SWAGGER_2).apiInfo(apiInfo()); }
15、SpringBoot整合Redis
SpringData 也是和 SpringBoot 齐名的项目!
说明 :在 SpringBoot2.x之后, 原来使用的jedis 被替换为了 lettuce ?
jedis :采用的直连, 多个线程操作的话 ,是不安全的, 如果想要避免不安全, 使用jedis pool 连接池 ! 更像 BIO模式.
lettuce : 采用netty , 实例可以再多个线程中进行共享,不存在线程不安全的情况 ! 可以减少线程数据了, 更像NIO模式.
1、整合Redis
-
新建一个Module
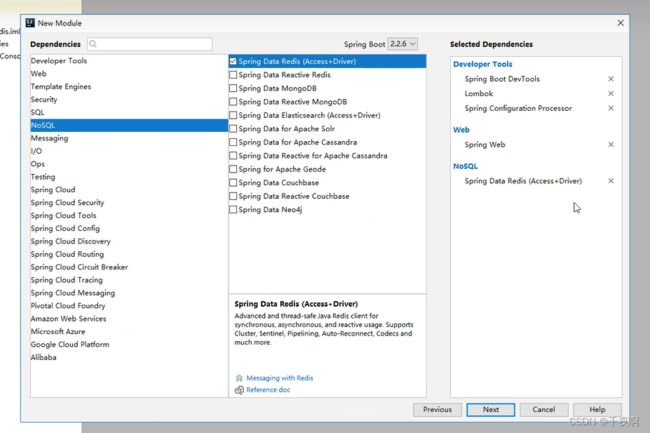
-
在NoSQL 中勾选 Spring Data Redis
-
导入依赖
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-redisartifactId> dependency> -
application.properties配置连接
# 配置redis spring.redis.host=192.168.189.128 spring.redis.port=6379 spring.redis.password=123456 -
测试
测试test@SpringBootTest class RedisSpringbootApplicationTests { // 在企业中,80%,不会使用原生的方式去编码 //用RedisUtil 工具类 @Autowired @Qualifier("redisTemplate") private RedisTemplate redisTemplate; @Autowired private RedisUtil redisUtil; @Test void contextLoads() { //redisTemplate 操作不同的数据类型 , API和我们的指令一样 //opsForValue 操作字符串 类似Spring //opsForList 操作List //opsForSet 操作Set //opsForHash //opsForvZset //opsForGeo //opsForHyperLogLog //除了基本的操作,我们常用的方法都可以直接通过redisTemplate操作, 比如事务 ,和基本的CRUD //获取redis的操作对象 // RedisConnection connection = redisTemplate.getConnectionFactory().getConnection(); // connection.flushDb(); // connection.flushAll(); redisTemplate.opsForValue().set("mykey","hello yuaiiao"); System.out.println(redisTemplate.opsForValue().get("mykey")); } } -
测试结果
此时我们回到Redis查看数据时候,惊奇发现全是乱码,可是程序中可以正常输出:
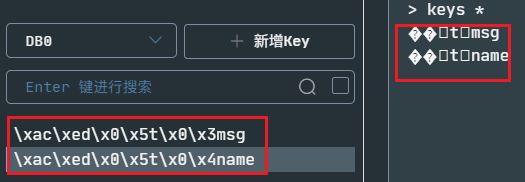
这时候就关系到存储对象的序列化问题,在网络中传输的对象也是一样需要序列化,否者就全是乱码。我们转到看那个默认的RedisTemplate内部什么样子:

在最开始就能看到几个关于序列化的参数。默认的序列化器是采用JDK序列化器

而默认的RedisTemplate中的所有序列化器都是使用这个序列化器: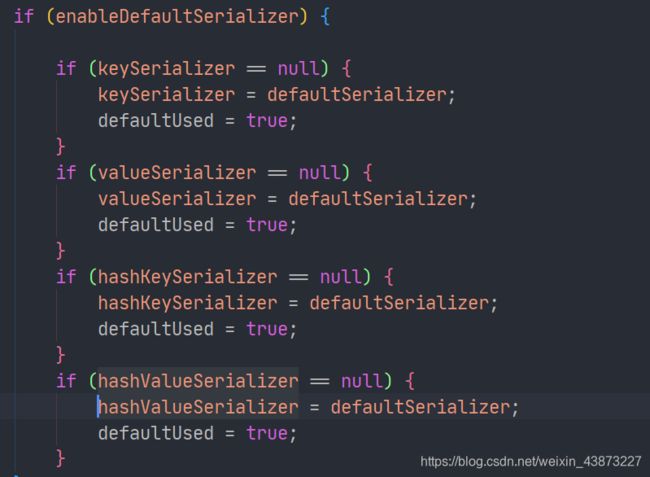
后续我们定制RedisTemplate就可以对其进行修改。RedisSerializer提供了多种序列化方案:
1 直接调用RedisSerializer的静态方法来返回序列化器,然后set

2 自己new 相应的实现类,然后set
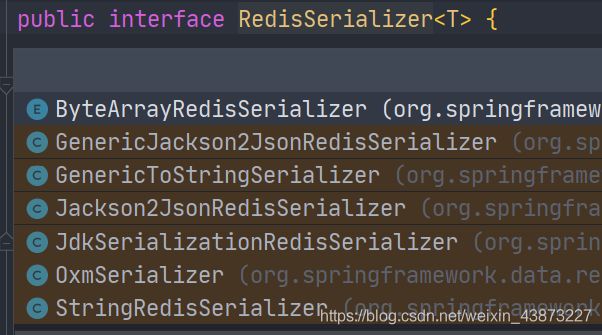
2、编写一个自己的redisTemplate
RedisConfig
// RedisConfig
@Configuration
public class RedisConfig {
public RedisConfig() {
}
//固定模板,在企业中,可以直接使用
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 我们为了自己开发方便,一般直接使用这样一来,只要实体类进行了序列化,我们存什么都不会有乱码的担忧了。
3、自定义Redis工具类
使用RedisTemplate需要频繁调用.opForxxx然后才能进行对应的操作,这样使用起来代码效率低下,工作中一般不会这样使用,而是将这些常用的公共API抽取出来封装成为一个工具类,然后直接使用工具类来间接操作Redis,不但效率高并且易用。
工具类参考博客:
https://www.cnblogs.com/zeng1994/p/03303c805731afc9aa9c60dbbd32a323.html
https://www.cnblogs.com/zhzhlong/p/11434284.html
16、Dubbo和Zookeeper集成
1、分布式理论
在《分布式系统原理与范型》一书中有如下定义:“分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统”;
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
分布式系统(distributed system)是建立在网络之上的软件系统。
首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。(所以分布式不应该在一开始设计系统时就考虑到)因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。。。
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,急需一个治理系统确保架构有条不紊的演进。
在Dubbo的官网文档有这样一张图

单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。
 适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。、
适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。、
缺点:
- 性能扩展比较难
- 协同开发问题
- 不利于升级维护
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
通过切分业务来实现各个模块独立部署,降低了维护和部署的难度,团队各司其职更易管理,性能扩展也更方便,更有针对性。
缺点:公用模块无法重复利用,开发性的浪费
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的**分布式服务框架(RPC)**是关键。
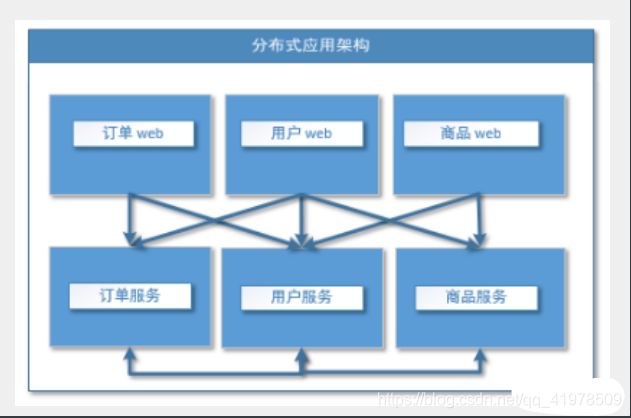
流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)[ Service Oriented Architecture]是关键。
2.2、什么是RPC
RPC【Remote Procedure Call】是指远程过程调用,是一种进程间通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。为什么要用RPC呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如不同的系统间的通讯,甚至不同的组织间的通讯,由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用。RPC就是要像调用本地的函数一样去调远程函数;
推荐阅读文章:https://www.jianshu.com/p/2accc2840a1b
说白了就是不同于调用本地的而是调用远程资源和方法
RPC原理:
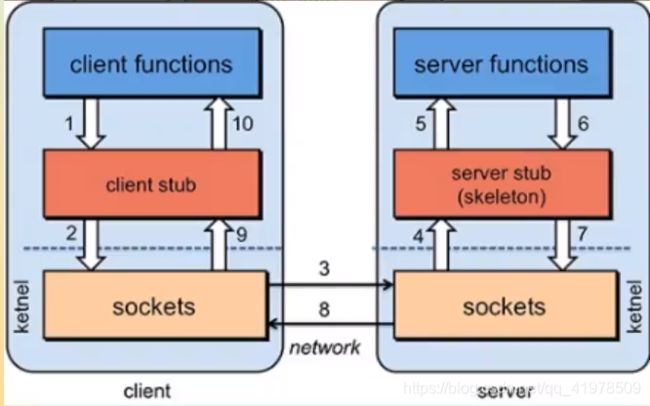
步骤分析:
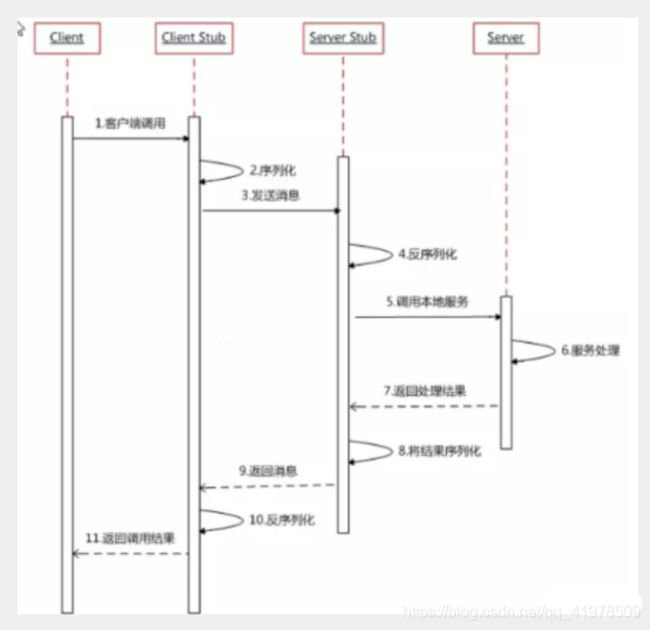
RPC两个核心模块:通讯,序列化。
15.2、Dubbo的概念和介绍
1、Dubbo是什么
Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需要用的,只有在分布式的时候,才有dubbo这样的分布式服务框架的需求,并且本质上是个服务调用的东东,说白了就是个远程服务调用的分布式框架
其核心部分包含:
- 远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。
- 集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持。
- 自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
2、Dubbo能做什么
- 透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
- 软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
- 服务自动注册与发现,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
15.3、搭建测试环境
1、说明
Apache Dubbo |ˈdʌbəʊ| 是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
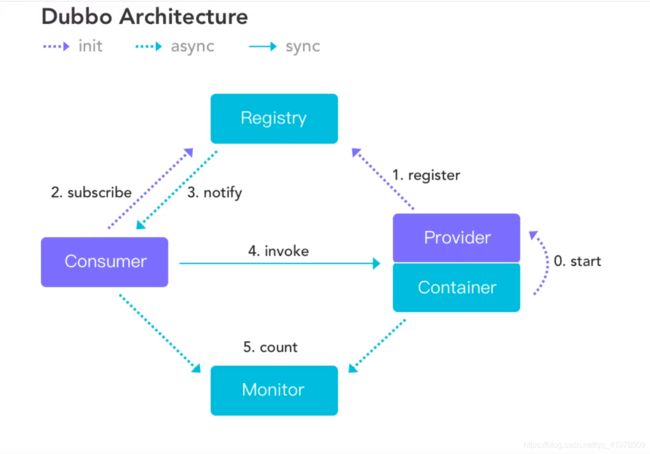
服务提供者(Provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者(Consumer):调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
注册中心(Registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者
监控中心(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
调用关系说明
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
2、Zookeeper介绍
Zoookeeper是什么?
官方文档上这么解释zookeeper,它是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
上面的解释有点抽象,简单来说zookeeper=文件系统+监听通知机制。
文件系统
Zookeeper维护一个类似文件系统的数据结构
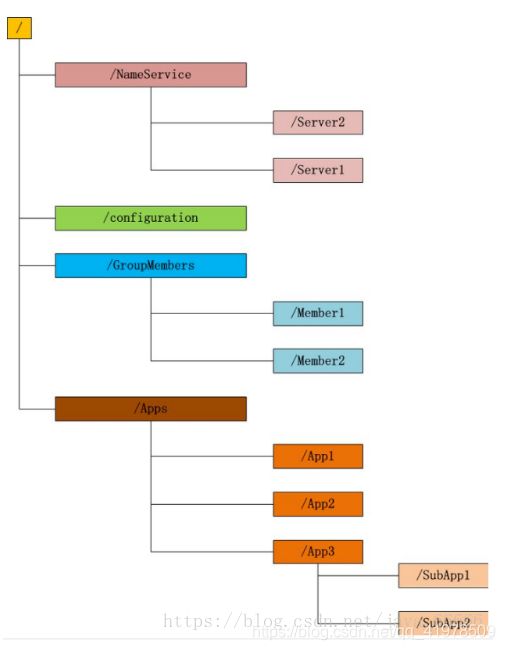
每个子目录项如 NameService 都被称作为 znode(目录节点),和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
- PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在 - PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号 - EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除 - EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
监听通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
就这么简单,下面我们看看Zookeeper能做点什么呢?
Zookeeper能做什么’
zookeeper功能非常强大,可以实现诸如分布式应用配置管理、统一命名服务、状态同步服务、集群管理等功能,我们这里拿比较简单的分布式应用配置管理为例来说明。
假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。
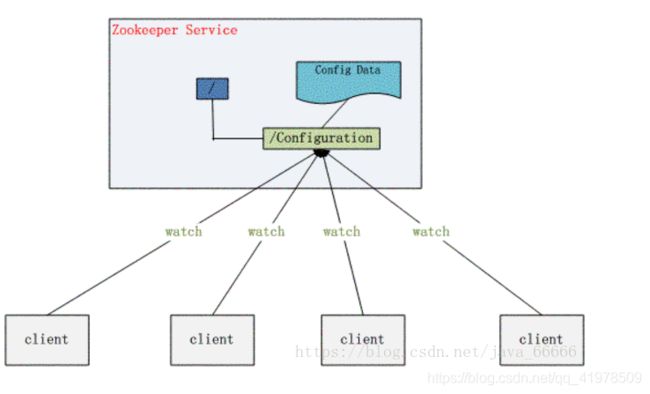
如上,你大致应该了解zookeeper是个什么东西,大概能做些什么了,我们马上来学习下zookeeper的安装及使用