MySQL进阶-索引(三)
目录
验证索引效率
针对字段创建索引
通过explain语句查询执行状况
最左前缀法则
概述
符合最左前缀法则情况
不符合最左前缀法则情况
范围查询
索引列运算
测试索引生效情况
测试查询phone尾数两位为15的数据
字符串不加引号
模糊查询
测试查找profession为软件工程的用户
or连接的条件
首先查看测试表的索引:
测试查找id为10或者年龄为23的用户
测试创建索引后是否符合条件
数据分布影响
测试查找phone>='1779990000'的数据
验证索引效率
在未建立索引之前,执行如下SQL语句,查看SQL的耗时
我们只需要关注执行的效率,返回1条数据,耗时20.78sec
针对字段创建索引

然后再执行相同的SQL语句,再次查看SQL的耗时

构建索引耗时1min11.20sec,为一千万条数据构建B+树(默认)
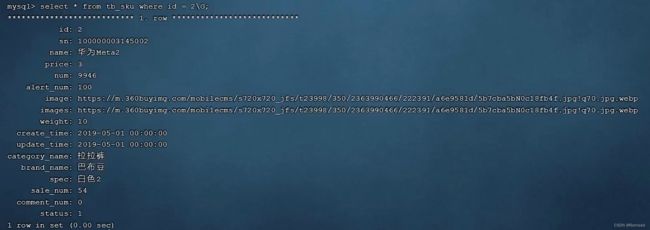
此时耗时0.00sec (后面还有数字0.00******)
通过explain语句查询执行状况
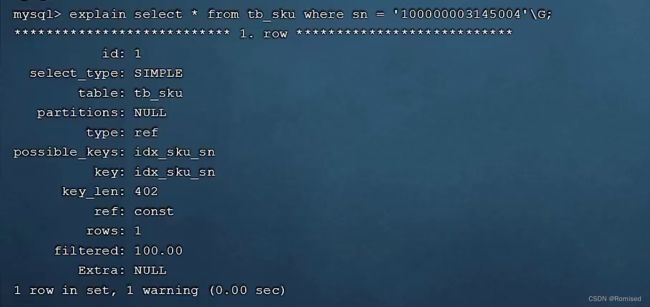
最左前缀法则
概述
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。
如果跳跃某一列,索引将部分失效(后面的字段索引失效)
案例:
准备一张tb_user表:
查看其索引
show index from tb_user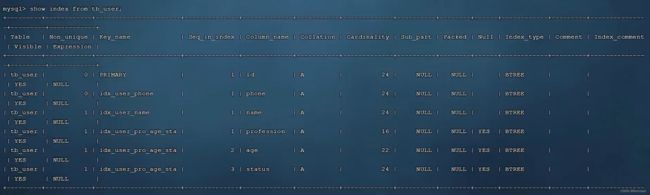
其中包含了一个主键索引(primary),两个单列索引(phone,name)和一个联合索引(profession,age,status)
其中联合索引的序号1,2,3分别对应profession,age,status
符合最左前缀法则情况
使用explain查看索引使用情况

可以看出使用了联合索引,并且索引的长度(key_len=54),符合最左前缀法则
这两个查询语句也符合最左前缀法则,可以推测出status的索引长度为5(54-49),name的索引长度为2(49-47)。

符合最左前缀法则,索引长度为54,虽然profession在最后面,但是只要存在, 就符合
不符合最左前缀法则情况
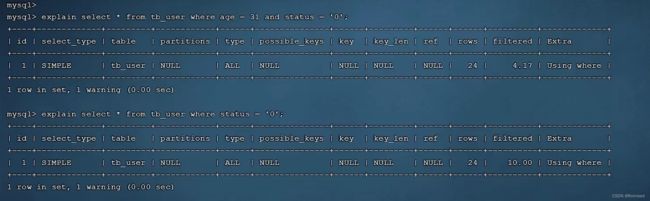
这两条语句不符合最左前缀法则,因为不包含最左边的变量profession!

这条语句也不符合最左前缀法则,跳过了中间的参数age,虽然用了联合索引,但是后面的status的索引失效
范围查询
联合索引中,出现范围查询(>,<),范围右侧的列索引失效

此时不符合最左前缀法则,key_len长度为49,status的索引失效

此时符合最左前缀法则,age使用>=,status的索引生效
通常在业务允许的情况下,最好使用>=,<=
索引列运算
不要再索引列上进行运算操作,索引将失效
数据准备:
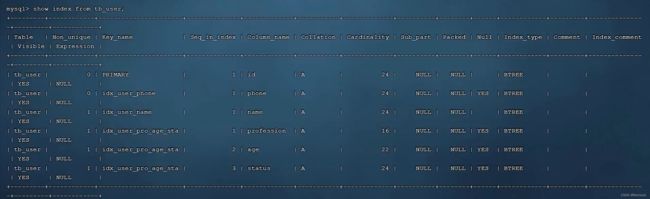
可以看出在phone字段上建立了单列索引
测试索引生效情况
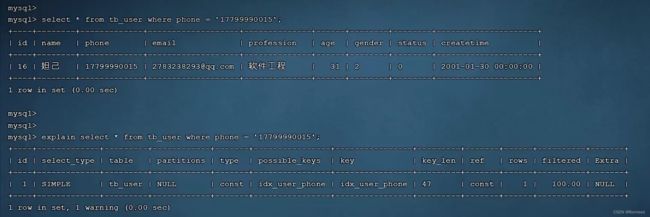
此时通过explain可以看出索引生效
测试查询phone尾数两位为15的数据
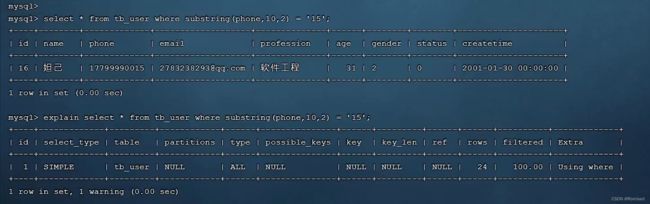
此时索引失效,因为在查询语句中使用了函数运算!
字符串不加引号
字符串类型字段使用时,不加引号,索引将失效
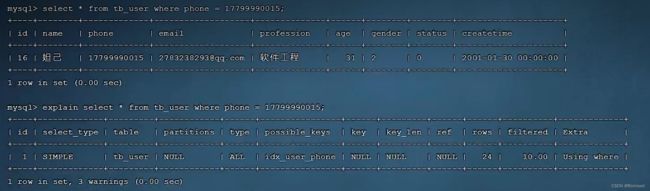
不加引号可以查询出来结果,但是没有使用索引
模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
测试查找profession为软件工程的用户
尾部模糊匹配:

头部模糊匹配:

前后模糊匹配:

可以看出尾部模糊匹配索引生效,而头部模糊匹配索引失效,前后都模糊匹配也失效!
or连接的条件
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到
首先查看测试表的索引:
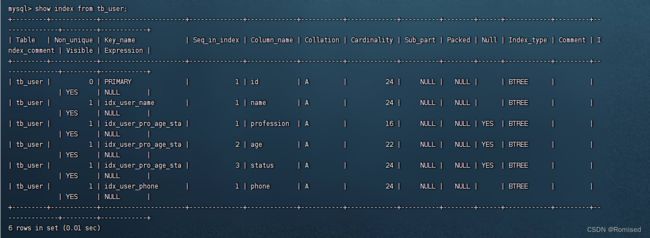
测试查找id为10或者年龄为23的用户
 其中id有主键索引,而age只有联合索引,如果不符合最左前缀法则的话,age不会被用到,
其中id有主键索引,而age只有联合索引,如果不符合最左前缀法则的话,age不会被用到,
索引不符合or连接的条件,因此两个索引都没被用到
测试创建索引后是否符合条件
create index idx_user_age on tb_user(age);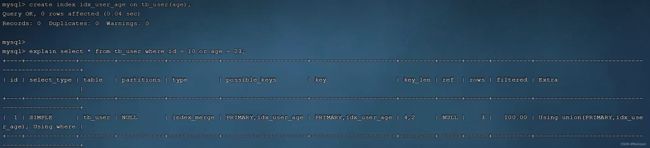
此时索引生效
数据分布影响
如果MySQL评估使用索引比全表更慢,则不适用索引
查询profession为空的时候使用了索引,而is not null的时候并未使用索引,因为profession不存在null值,绝大多数数据都满足条件,因此MySQL评估全表扫描比使用索引更快,因此不使用索引,而is null为极少数数值,所以MySQL评估使用索引更快,因此使用索引
测试查找phone>='1779990000'的数据

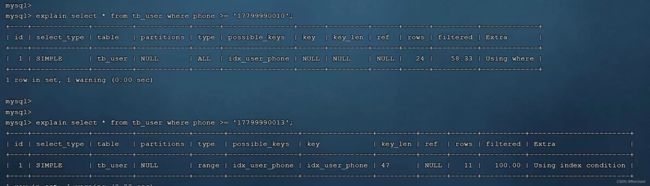
可以看出phone>='1779990000'和phone>='1779990010'时,MySQL评估后仍使用全表扫描,因为表中的大部分数据都满足查找条件,phone>='1779990013'时,使用索引,因为大部分数据不满足条件,MySQL评估使用索引会更快