ChatGLM-6B的安装和使用最全面细节讲解
ChatGLM-6B是一个基于General Language Model (GLM)架构的开源对话语言模型,支持中英双语。该模型使用了和ChatGPT类似的技术进行优化,经过1T标识符的中英双语训练,同时辅以监督微调、反馈自助和人类反馈强化学习等技术,共有62亿参数。
ChatGLM-6B由清华大学 KEG 实验室和智谱AI共同开发,通过模型量化技术,用户可以在消费级显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。
ChatGLM-6B可以简单的理解为本地私有部署的弱化版ChatGPT。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性:
-
- 如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。
- 产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
- 英文能力不足:ChatGLM-6B 训练时使用的指示/回答大部分都是中文的,仅有极小一部分英文内容。因此,如果输入英文指示,回复的质量远不如中文,甚至与中文指示下的内容矛盾,并且出现中英夹杂的情况。
- 易被误导,对话能力较弱:ChatGLM-6B 对话能力还比较弱,而且 “自我认知” 存在问题,并很容易被误导并产生错误的言论。例如当前版本的模型在被误导的情况下,会在自我认知上发生偏差。
环境准备
硬件要求:
- CPU:AMD 3600
- 内存:DDR4 16GB
- 显卡:RTX 3050(8GB)
软件要求:
- 操作系统:Windows 10,也可以是其它操作系统
- 安装Git工具
- 安装Python,我的版本为3.11.3
- 安装英伟达驱动程序
1、首先判断环境是否安装了python,如果没有,则在机器上安装python
Python学习笔记:Python 详细安装步骤图解
tips:如果安装完成后,在cmd中启动python时失败,而是打开微软商店,可以参考如下解决方案:
方案1:Python的环境变量置于 windowsApps之前
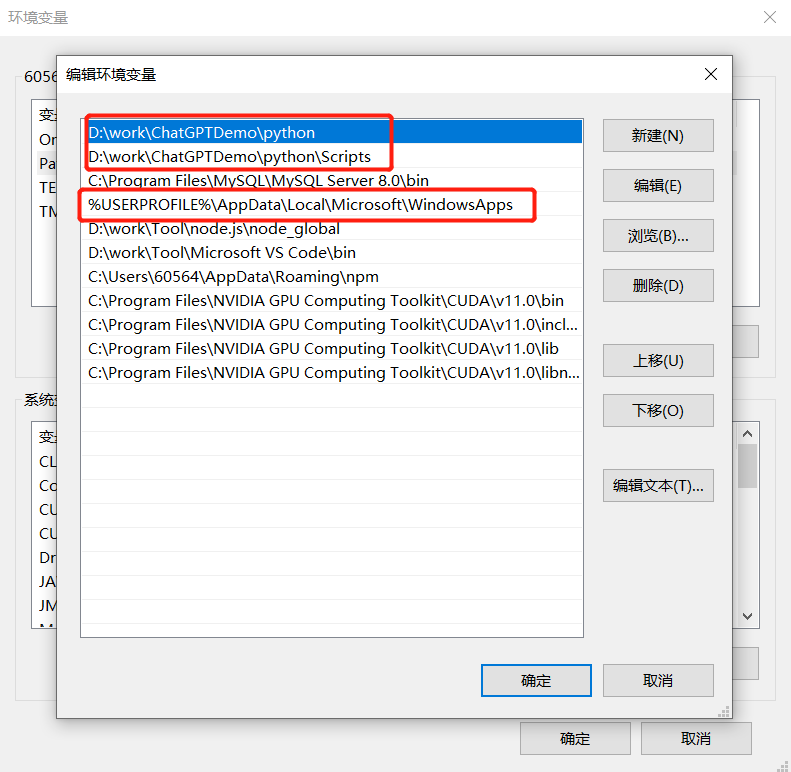
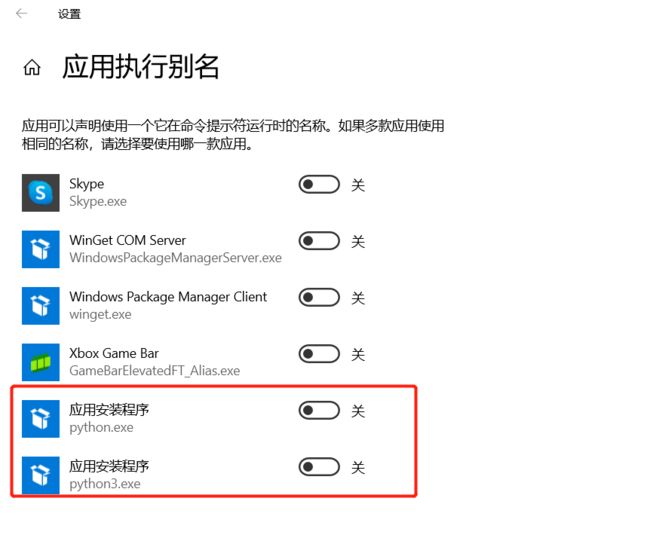
方案2:在系统软件搜索中,输入 “应用执行别名管理”,点击,然后关闭所有python相关程序
2、判断是否安装了 pip(python一般都自带 pip )

如果不是上图所示,则需要自己安装Pip:
一分钟学会Python中pip的安装与使用_pip安装_Python妙脆角的博客-CSDN博客
查看显存
到上一步基本环境已经安装完成。接下来需要判断训练模型是在GPU还是CPU上运行。
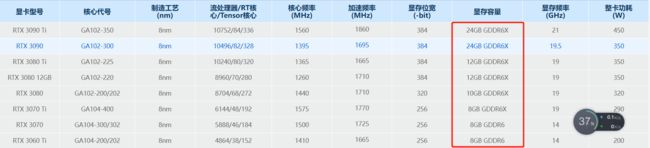
win+R 中输入 dxdiag 查看显存大小

| 量化等级 |
最低 GPU 显存(推理) |
最低 GPU 显存(高效参数微调) |
| FP16(无量化) |
13 GB |
14 GB |
| INT8 |
8 GB |
9 GB |
| INT4 |
6 GB |
7 GB |
如果你的显存大小<6G,那么你将无法使用GPU运行训练模型。这时候你就需要使用CPU(大概 32GB 内存)来进行运行。不过在CPU上运行的速度会大大降低,显存足够时,推荐在GPU上运行。
配置项目
1、从git仓库拉取项目代码
[email protected]:THUDM/ChatGLM-6B.git2、下载依赖
pip install -r requirements.txttips:如果下载速率比较慢,可以更换为国内的下载源
清华:Simple Index
阿里云:Simple Index
豆瓣:Simple Index
山东理工大学:Loading...
中国科技大学 Simple Index
华中科技大学:http://pypi.hustunique.com/
// 通过清华源下载
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple下载CUDA(GPU运行)
NVIDIA显卡必须安装CUDA才能满足 CHATGML-6B训练模型的高性能运算需求。
1、先判断是否安装CUDA

nvcc -V
若显示CUDA相关版本信息,表明已经安装,则可跳过第2步。
2、安装CUDA
CUDA安装教程(超详细)_Billie使劲学的博客-CSDN博客
安装PyTorch
PyTorch是一个针对深度学习,并且使用GPU和CPU来优化的tensor library(张量库)
进入官网: PyTorch
选择GPU运行
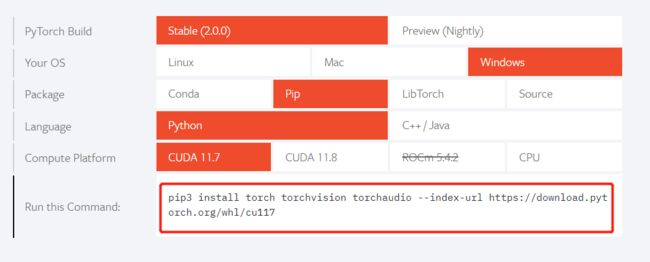
需要选择上一步下载的CUDA对应的版本
选择CPU运行
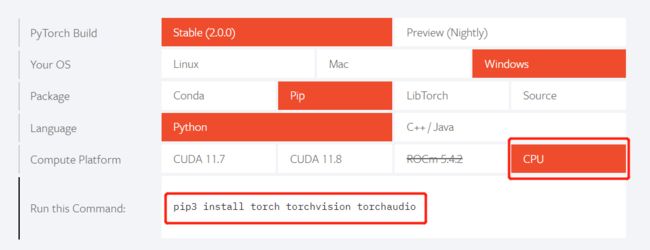
复制Run tis Command 里面的代码,通过pip下载, 正常下载速度会比较慢,建议使用清华源进行下载比较快。
安装TDM-GCC(CPU运行)
如果需要在 cpu 上运行量化后的模型,还需要安装 gcc 与 openmp
TDM-GCC官网下载: Download | tdm-gcc
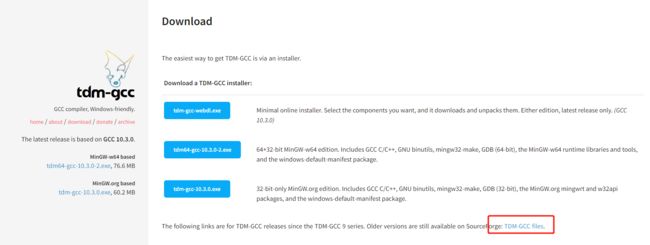

不要下载最新版本的,因为最新版本中没有集成openmp,点击TDM-GCC files 寻找历史版本,然后下载 tdm64-gcc-5.1.0-2.exe版本。
进行安装时,一定要勾选 gcc下的openmp,否则后续运行会报错。

手动下载训练模型(可选)
建议手动下载训练模型,因为文件体量比较大,如果网络不佳,自动下载的话很有可能会失败。
下载地址:THUDM/chatglm-6b at main

这里有两个可以选的下载版本 main 和 int4,对应不同的量化等级。
main: FP16(无量化) 和 INT8
int4: INT4
根据自己显存的大小进行下载所有文件。然后将文件放置到 “配置项目” 步骤下载的 CHATGLM-6B项目下。

启动CHATGLM-6B
1、命令启动
未手动下载训练模型
FP16(无量化)启动 GPU启动
python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval
response, history = model.chat(tokenizer, "你好", history=[])
print(response)INT8 量化启动
// 这句代码后面添加 quantize(8)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(8).cuda()INT4 量化启动
// THUDM/chatglm-6b 修改为 THUDM/chatglm-6b-int4
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
CPU启动
// 后面修改为float()
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()手动下载了训练模型
python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("D:\\work\\ChatGPTDemo\\ChatGLM6B\\chatglm6b", trust_remote_code=True)
model = AutoModel.from_pretrained("D:\\work\\ChatGPTDemo\\ChatGLM6B\\chatglm6b", trust_remote_code=True).half().cuda()
model = model.eval
response, history = model.chat(tokenizer, "你好", history=[])
print(response)运行效果如下
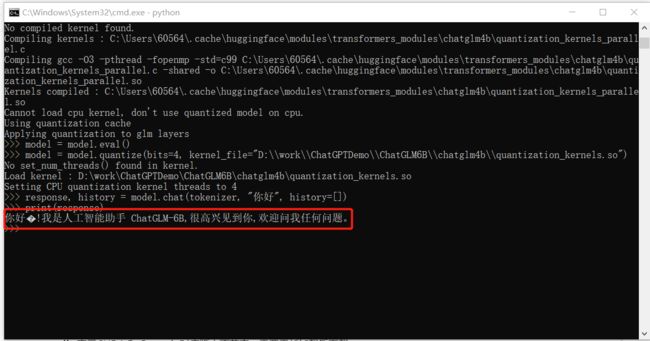
2、脚本启动
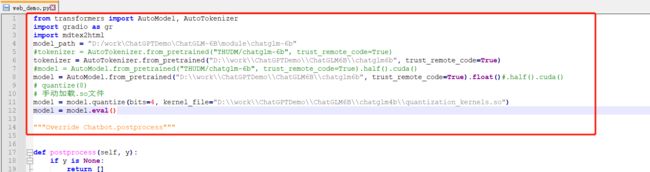
按照需求对改文件修改,然后点击启动即可。
启动效果
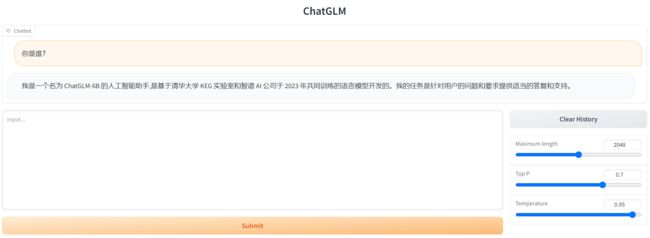
tips:
如果出现报错
Torch not compiled with CUDA enabled
表示CUDA 和 Pytorch 对应版本不兼容,需要重新卸载后下载
如果运行 INT4 量化模型时出现错误

文件中的quantization_kernels.c和quantization_kernels_parallel.c这两个文件编译存在问题,需要手动编译
// 进入下载的 INT4量化模型文件夹下
cd D:\work\ChatGPTDemo\ChatGLM6B\chatglm4b
gcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels.c -shared -o quantization_kernels.so
gcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels_parallel.c -shared -o quantization_kernels_parallel.so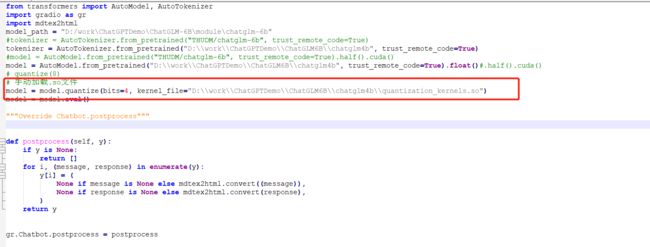
在启动前添加一句 手动加载文件
# 手动加载.so文件
model = model.quantize(bits=4, kernel_file="D:\\work\\ChatGPTDemo\\ChatGLM6B\\chatglm4b\\quantization_kernels.so")