ChatGLM2 6B 本地部署
学习GAI已经有两个多月,迎来最后的一个课题,就是本地部署大模型。我们选用的是清华的ChatGLM2-6B的模型。发现在3070 8G显卡上,运行FP16的还是慢,完全不能接受,一句问好要30秒生成结果。最后还是选用INT4量化的算了。速度上比较好,示例完全可以运行,且返回时间比较接受。
ChatGLM2-6B的Github是这,克隆后,按文档去玩就可以了。可是,从huggingface下载模型文件好慢,又易断(不舍得用高速梯子,模型文件FP16的是11.6GB)。同时文档提供了方便的来源, 清华大学云盘https://github.com/THUDM/ChatGLM2-6B https://github.com/THUDM/ChatGLM2-6B
https://github.com/THUDM/ChatGLM2-6B
Demo中的代码是直接从HUGGINGFACE下载,如下:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
model = model.eval()如果改用只检出huggingface的模型实现,命令:
#Mac / Linux
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
#Windows
set GIT_LFS_SKIP_SMUDGE=1
git clone https://huggingface.co/THUDM/chatglm2-6b如果在Windows下,要用一个没有横杠的文件夹名称,如"THUMDCHATGLM2",如果路径名称中有下划线,短横线,加载模型时会有错误提示,所以在本地加载模型时,文件夹名或路径中不要用这些符号。
所以完成克隆模型实现,再从清华云盘下载模型参数文件(11.6GB),然后复制到HUGGINGFace的克隆路径下。就可以修改demo实现代码。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("D:\THUDM", trust_remote_code=True)
model = AutoModel.from_pretrained("D:\THUDM", trust_remote_code=True).cuda()
model = model.eval()
我是用THUDM做FP16的文件夹路径。在JUPYTER NOTEBOOK下加载模型,花了17.9s。

内存消耗:

然后试一个简单的推理:
response, history = model.chat(tokenizer, "你好", history=[])
print(response) 
哈哈,用了2分种 29秒。推理过程中,消耗如下:

此时,部机已经卡到出汁了,每键入小小都在等待回显。然后,第二个问题根本没法推理出来。已经用12分钟了。

从上面代码可见chatGLM2是自己维护了对话记录,第三个参数,history,就是了。用INT4后,运行三个问题,打印出来的history, 如下:
[('你好', '你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'),
('晚上睡不着应该怎么办', '睡眠是恢复身体和大脑功能的重要过程,如果晚上睡不着,可以尝试以下一些方法来帮助自己入睡:\n\n1. 改善睡眠环境:确保睡眠环境安静、舒适、凉爽、黑暗、纹理清晰,可以选择合适的床垫、枕头和床单。\n\n2. 放松身心:使用放松技巧,如深呼吸、自我按摩、听轻柔的音乐或进行冥想,可以帮助缓解紧张和焦虑。\n\n3. 规律作息:保持规律的作息时间,每天晚上大约在同一时间入睡,并尽量在同一时间起床,有助于调节身体的生物钟。\n\n4. 避免刺激:避免在睡觉前看电子屏幕、吃油腻或辛辣的食物、喝咖啡或饮料,以免刺激身体和大脑。\n\n5. 暂时离开床铺:如果躺在床上30分钟后仍然无法入睡,可以离开床铺做一些轻松的活动,如阅读或听轻柔的音乐,然后再返回床上。\n\n如果这些方法无效,可以尝试寻求医生或睡眠专家的帮助,找到更好的解决方案。'),
('写一个关于科学家突发奇想漫游太空的故事。', '一个著名的科学家突然有了一个奇怪的想法,他突然决定要漫游太空。这个想法让他的同事们感到非常惊讶,因为他们知道这位科学家一直以来都是一个非常理性和谨慎的人。\n\n科学家们开始研究这个想法的可行性,他们需要制造出一艘能够飞行的飞船。在经过多年的研究和努力后,科学家们终于有了一个可以飞行的飞船。\n\n科学家们登上了飞船,开始了他们的太空之旅。他们看到了地球上从未见过的美丽景色,也体验了太空中的自由和无拘束感。在飞船的飞行中,科学家们进行了一系列的实验,研究了不同的天体和宇宙现象。\n\n然而,他们的这次太空之旅并不顺利。在飞船的途中,他们突然遭遇了一次磁暴,导致飞船的控制系统失灵。科学家们必须手动控制飞船,但这使得他们的行程变得更加危险。\n\n在飞船抵达太空的边缘时,科学家们决定放弃返回地球的计划。他们开始在太空中自由飘荡,享受着太空中的孤独和神秘。这次经历给了科学家们极大的启发,也让他们更加珍视他们的工作和研究成果。\n\n回家后,科学家们开始将这次经历和他们的研究成果分享给了其他人。这次经历也让他们对太空探索充满了热情和动力,他们更加坚信,太空探索将会带来更多的未知和挑战。')]
接下来,取消FP16的推理,重新加载INT4量化后的。量化后的模型参数文件只有3.9GB,小很多。
我用的路径是THUDMINT4, 从hugging face 的 https://huggingface.co/THUDM/chatglm2-6b-int4
获取后,从清华网盘下载参数文件和tokenizer文件,替换到克隆的目录中。不能直接使用 原6B的那个克隆路径。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("D:\THUDMINT4", trust_remote_code=True)
model = AutoModel.from_pretrained("D:\THUDMINT4", trust_remote_code=True).cuda()
model = model.eval()加载INT4后的,只用6.9s
然后执行第一个问题:

可见,第一个问好用了5.0s就生成结果。 带上history, 尝试第二个问题生成:

如图,用了8.1s,能生成结果,已经比运行FP16的要爽。当然,某些问题的生成精度肯定没FP16的好,但至少在我这里能用,能做测试。
加载模型后的内存占用如下:
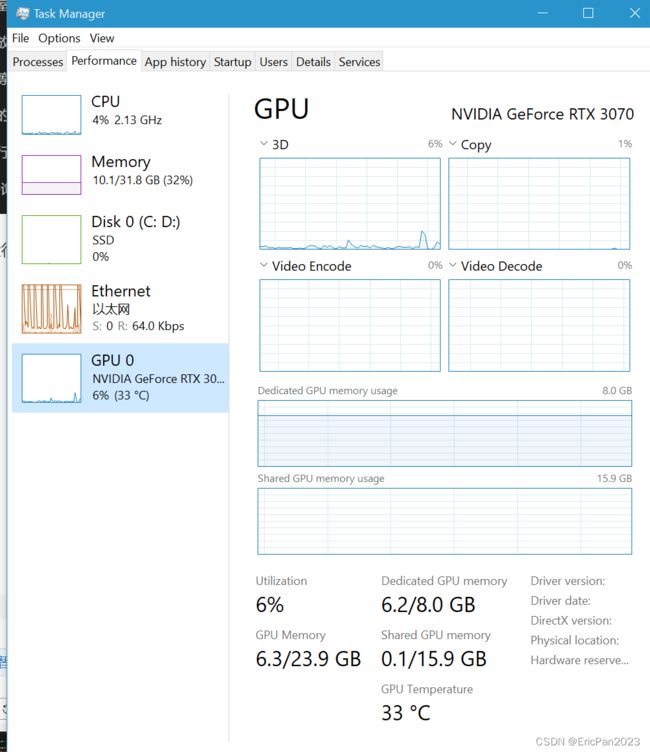
虽然也用了6.2GB显存,但也比较好。机器在推理过程中, 不会很卡,打字也不会很慢,不会出现一个一个字蹦出来。
最后一个问题是生成一个小故事:

其中红框住的是打印出聊天历史。
至此,ChatGLM6B模型的本地部署运行就基本完成, 接下来就是用这个INT4后的模型做一些小功能。如翻译AI Translator。
以上就是极客时间- 《AI 大模型应用开发实战营》的最尾一个课题,大模型的本地部署和应用实战。实战部份,下次聊吧。