【代码随想录】总结篇
常用数据结构及相关算法
- Array 数组
- Linked List 链表
-
-
- 与数组的比较
- 单链表定义
-
- Hash Table 哈希表
-
-
- 常见哈希结构
- 选择策略
-
- String 字符串
-
-
- KMP算法: 避免从头做匹配
-
- Stack & Queue 堆 & 栈
- 二叉树
- 回溯
- 贪心
- 动态规划
- 单调栈
- 图论
Array 数组
数组是存放在连续内存空间上的相同类型数据的集合。数组索引从零开始,增删需将元素移动覆盖。
- 二分法区间定义: 左闭右闭
[left, right]在left == right时有意义,需要判断left <= right - 双指针法时间复杂度一般为
O(n):快慢双指针和相向双指针 - 滑动窗口
- 最大窗口:不满足条件时才收缩
- 最小窗口:满足条件时收缩
- 模拟过程
Linked List 链表
链表是通过指针域的指针链接的内存中的各个节点,并非连续分布。C++中最好手动释放内存。
与数组的比较
| 数据结构 | 内存分布 | 查询复杂度 | 增删复杂度 |
|---|---|---|---|
| 数组 | 连续分布 | O(1) |
O(n) |
| 链表 | 离散分布 | O(n) |
O(1) |
单链表定义
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};
- 使用虚拟头节点dummyHead能方便对链表的操作,不用考虑特殊情况
- 遍历链表
while (index--) { cur = cur->next; } - 快慢双指针,如寻找环入口
Hash Table 哈希表
哈希表是根据关键码的值 (Key-Value) 而直接进行访问的数据结构。一般用来快速判断一个元素是否出现集合里。牺牲了空间换取了时间。
常见哈希结构
- 数组就是哈希表,关键码就是数组的索引下标。
- Set 集合
| 集合 | 底层实现 | 是否有序 | 是否能重复 | 是否能修改 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 是 | 否 | 是 | O(log n) |
O(log n) |
| std::multiset | 红黑树 | 是 | 是 | 是 | O(log n) |
O(log n) |
| std::unordered_set | 哈系表 | 否 | 否 | 是 | O(1) |
O(1) |
- Map 映射
| 集合 | 底层实现 | 是否有序 | 是否能重复 | 是否能修改 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不能 | key不能 | O(log n) |
O(log n) |
| std::multimap | 红黑树 | key有序 | key能 | key不能 | O(log n) |
O(log n) |
| std::unordered_map | 哈系表 | key无序 | key不能 | key不能 | O(1) |
O(1) |
选择策略
- 键值连续且数量较少时可用数组作哈希表 (a-z) ,空间占用少且更快
- 键比较少、特别分散、跨度非常大,考虑用set:优先使用unordered_set,因为它的查询和增删效率是最优的;如果需要集合是有序的,那么就用set;如果要求不仅有序还要有重复数据的话,那么就用multiset
- 需要额外存储value时考虑用map,需要去重时如三数之和较麻烦,考虑用双指针
String 字符串
字符数组,有字符串处理的相关接口如
size,substr,split,reverse
- 双指针法:翻转(花式)、替换(resize)…
KMP算法: 避免从头做匹配
- 文本串,模式串
- 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串,后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
- 前缀表prefix table: 记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀,作用是找到匹配失败的位置前的后缀子串,以及与其相同的前缀后面的地方重新匹配
next数组:前缀表或前缀表统一减1,初始j = -1- 经典问题:匹配,重复字串
Stack & Queue 堆 & 栈
栈先进后出,队列先进先出。是容器适配器 Container adapter:不允许遍历,不提供迭代器,对外提供统一的接口(push, pop, top),底层容器(deque, vector, list)可插拔。SGI STL默认以deque(内存非连续)为底层结构。
std::stack<int, std::vector<int> > third; // 使用vector为底层容器的栈
std::queue<int, std::list<int>> third; // 定义以list为底层容器的队列
class comp { // 自定义类型的排序
public:
bool operator() (const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
}
std::priority_queue<pair<int, int>, vector<pair<int, int>>, comp> pri_que;
- 递归通过栈实现:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中。递归返回的时候,从栈顶弹出上一次递归的各项参数,所以递归可以返回上一层位置。
- 匹配问题是栈的强项,如逆波兰表达式的后缀表达式对计算机非常友好
- 优先级队列是披着队列外表的堆,默认大顶堆是vector实现的完全二叉树,pop弹出最顶部元素,greater 小顶堆 less 大顶堆
- 单调队列维护窗口内部分元素顺序
O(n)vs 优先级队列维护窗口内所有元素顺序O(nlogn)
二叉树
- 种类:满二叉树,完全二叉树,二叉搜索树,平衡二叉搜索树AVL
- 存储方式:链式,顺序(数组)
// 链式储存二叉树定义 struct TreeNode { int val; TreeNode* left; TreeNode* right; TreeNode() : val(0), left(nullptr), right(nullptr) {} TreeNode(int val) : val(val), left(nullptr), right(nullptr) {} TreeNode(int val, TreeNode* left, TreeNode* right) : val(val), left(left), right(right) {} } - 遍历方式:
- 深度优先 DFS:前序(中左右),中序(左中右), 后序(左右中)-> 递归,迭代(栈)
- 广度优先 BFS:层序 -> 迭代(队列)
- 递归和迭代法的时间复杂度差不多,但是递归的空间复杂度更大,因为需要系统堆栈存参数返回值等,易于人理解但难为机器
- 递归三部曲
- 递归函数的输入参数和返回类型
- 终止条件
- 单层递归逻辑
- 二叉树深度对应前序(中左右),高度对应后序(左右中)。根节点的高度就是二叉树的最大深度
// 最大深度 // 前序求深度(回溯) int mdepth; void getDepth(TreeNode* node, int depth) { mdepth = depth > mdepth ? depth : mdepth; if (node->left == nullptr && node->right == nullptr) return; if (node->left) getDepth(node->left, depth + 1); if (node->right) getDepth(node->right, depth + 1); } // 后序求高度 int getHeight(TreeNode* root) { if (root == nullptr) return 0; return max(maxDepth(root->left), maxDepth(root->right)) + 1; } // 最小深度 // 前序求深度(回溯) int mdepth; void getDepth(TreeNode* node, int depth) { if (node->left == nullptr && node->right == nullptr) { mdepth = min(mdepth, depth); return; } if (node->left && mdepth > depth) getDepth(node->left, depth + 1); if (node->right && mdepth > depth) getDepth(node->right, depth + 1); } // 后序求高度 int getHeight(TreeNode* root) { if (root == nullptr) return 0; if (root->left == nullptr && root->right == nullptr) return 1; if (root->left == nullptr) return 1 + minDepth(root->right); if (root->right == nullptr) return 1 + minDepth(root->left); return min(minDepth(root->left), minDepth(root->right)) + 1; } - 递归函数返回值
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(113.路径总和II)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (236. 二叉树的最近公共祖先)
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(112.路径总和)
- 不同问题选择遍历顺序
- 二叉树构造:前序先构造中节点
- 普通二叉树属性:后序对返回值做计算(求深度可用前序)
- 二叉搜索树属性:中序利用有序性
回溯
本质是穷举,可通过剪枝提高效率。可以抽象为树形结构,在集合中递归查找子集, 集合的大小构成树的宽度,递归的深度构成树的深度(高度有限)。可以解决组合问题、切割问题、子集问题、排列问题、棋盘问题等。

// 回溯模板
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
- 组合求和问题:收集叶子节点结果
- 一个集合求组合:startIndex控制for循环起始位置
- 多个集合求组合:不需要startIndex
- 排序剪枝(元素数量、和、元素不可重复);树枝去重or数层去重
- 切割问题
- 子集问题:收集所有节点结果,遍历整棵树不需剪枝
- 排列问题:used数组记录使用过的元素,从零开始for循环搜索
- 棋盘问题
贪心
本质:每一阶段局部最优,从而达到全局最优。想不到反例时可以考虑用贪心,将问题分解为若干子问题,用贪心策略求解子问题最优解,堆叠成全局最优解。
- 两维问题:两个维度分开考虑
- 区间问题:排序+更新区间(交集or并集)
动态规划
本质:重叠子问题,当前状态由上一状态推导出来。
五部曲:
1. 确定dp数组(dp table)以及下标的含义
2. 确定递推公式
3. dp数组如何初始化
4. 确定遍历顺序
5. 举例推导dp数组
(打印数组debug)
-
背包问题
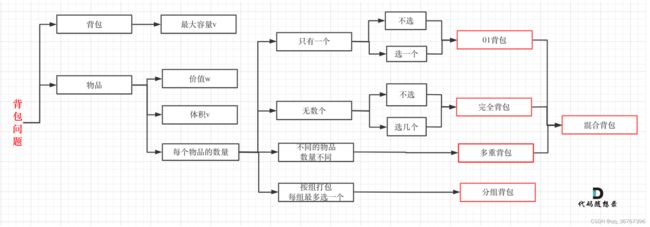
- 01背包:有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i]。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
// 二维数组 略 // 一维滚动数组 int maxValue1D(int bagweight, vector<int>& weights, vector<int>& values) { vector<int> dp(bagweight + 1, 0); for (int i = 0; i < weights.size(); i++) { // for (int j = 1; j <= bagweight; j++) { // 会重复添加同一物品->完全背包 // if (j >= weights[i]) // dp[j] = max(dp[j], dp[j - weights[i]] + values[i]); // } // 倒序确保物品只加入一次 for (int j = bagweight; j >= weights[i]; j--) { // 如果能放下 dp[j] = max(dp[j], dp[j - weights[i]] + values[i]); // 放不放 } } return dp[bagweight]; // 如果先遍历背包容量,相当于每个dp[j]只放入一个物品 // for (int j = bagweight; j >= 1; j--) { // for (int i = 0; i < weights.size(); i++) { // if (j >= weights[i]) // dp[j] = max(dp[j], dp[j - weights[i]] + values[i]); // } // } // return dp[bagweight]; }- 完全背包:有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i]。
每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。
// 一维滚动数组 int maxValue1D(int bagweight, vector<int>& weights, vector<int>& values) { vector<int> dp(bagweight + 1, 0); // 先遍历物品,再遍历背包 => 求组合数 for (int i = 0; i < weights.size(); i++) { for (int j = 1; j <= bagweight; j++) { // 可重复添加同一物品 if (j >= weights[i]) dp[j] = max(dp[j], dp[j - weights[i]] + values[i]); // 求最大价值 } } // 先遍历背包,再遍历物品 => 求排列数 // for (int j = 0; j <= bagweight; j++) { // 遍历背包容量 // for (int i = 0; i < weights.size(); i++) { // 遍历物品 // // 递推公式 // } // } // 求最小数目等情况,两种遍历顺序都行 return dp[bagweight]; }- 多重背包:有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。
=> 每件物品最多有Mi件可用,把Mi件摊开,其实就是一个01背包问题!
int maxValue1D(int bagweight, vector<int>& weights, vector<int>& values, vector<int>& nums) { // 一维滚动数组 vector<int> dp(bagweight + 1, 0); for (int i = 0; i < weights.size(); i++) { for (int j = bagweight; j >= weights[i]; j--) { // 如果能放下 // 遍历物品个数 for (int k = 1; k <= nums[i] && j >= k * weights[i]; k++) { dp[j] = max(dp[j], // 不放 dp[j - k * weights[i]] + k * values[i]); // 放k个 } } } return dp.back();- 常见递推公式
dp[j] = max(dp[j], dp[j - weights[i]] + values[i]); // 求最大价值 dp[j] += dp[j - nums[i]]; // 求组合或排列数 dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]); // 求能否装满或最多装多少 dp[j] = min(dp[j - coins[i]] + 1, dp[j]); // 求装满背包最小物品数目 -
打家劫舍
-
股票问题
-
子序列问题 (编辑距离、回文字串、回文子序列)
单调栈
栈里元素递增或递减,通常是一维数组,用于寻找任一个元素的右边/左边第一个比自己大/小的元素的位置
图论
-
深度优先搜索DFS:深搜三部曲
void dfs(参数) { if (终止条件) { 存放结果; return; } for (选择:本节点所连接的其他节点) { 处理节点; dfs(图,选择的节点); // 递归 回溯,撤销处理结果 } } -
广度优先搜索BFS:用队列记录同层节点,加入队列就需要标记,防止重复访问