大数据毕设 基于大数据住房数据分析与可视化 - python
文章目录
- 0 前言
- 分析展示
-
- 一、北上广租房房源分布可视化
- 二、北上广内区域租金分布可视化
- 三、房源距地铁口租金的关系可视化
- 四、房屋大小与租金关系可视化
- 结论
-
-
- 租个人房源好还是公寓好
- 北上广深租房时都看重什么
-
- 部分实现代码
0 前言
这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
基于大数据住房数据分析与可视化
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:2分
选题指导, 项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md
分析展示
一、北上广租房房源分布可视化
租房分布,也就是租房房源都在城市的哪个区域更多。
我们把北上广深四个城市的房源都以小点的形式投射在地图上,先来看看北京的。
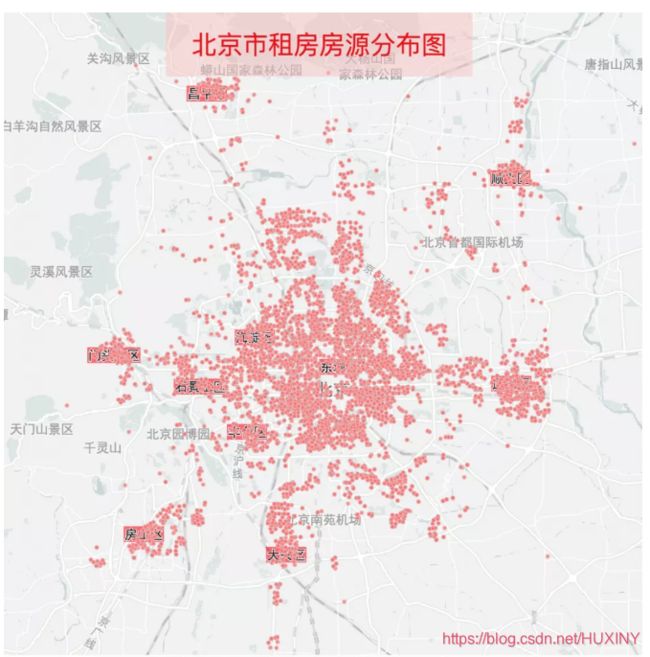
结论:
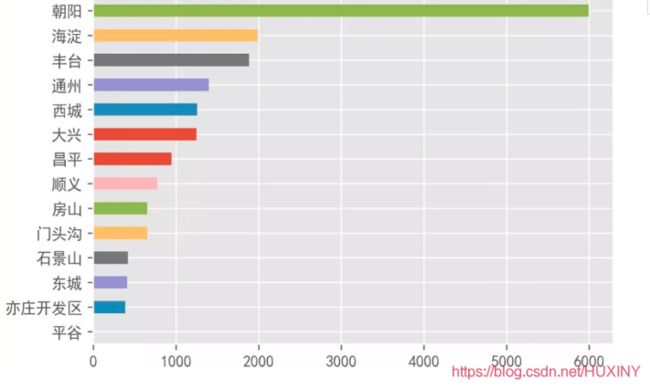
北京的租房房源有18012条,可以看到除了周边的昌平、顺义、通州、大兴、房山、门头沟等区中心有集中房源外,北京的房子主要集中在二环外四环内,当然这片区域也是最贵的。其中朝阳区的房源最多,占了整个北京房源的1/3,要不咋说朝阳群众666呢。海淀、丰台次之。


结论:
上海也一样,除了周边的宝山、嘉定、青浦、松江、奉贤等区中心有房源外,房源主要集中在中心城区+浦东(地铁网范围内)。总共27311条房源,浦东就有7000多条,比例超过1/4。
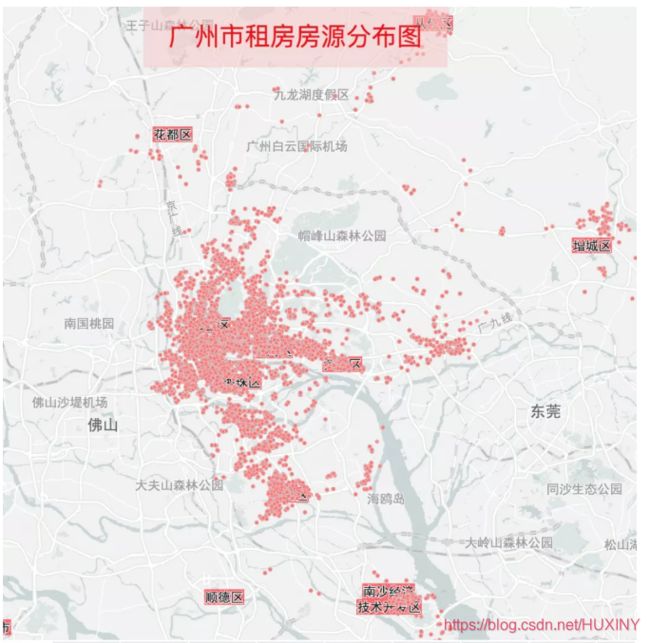
结论:
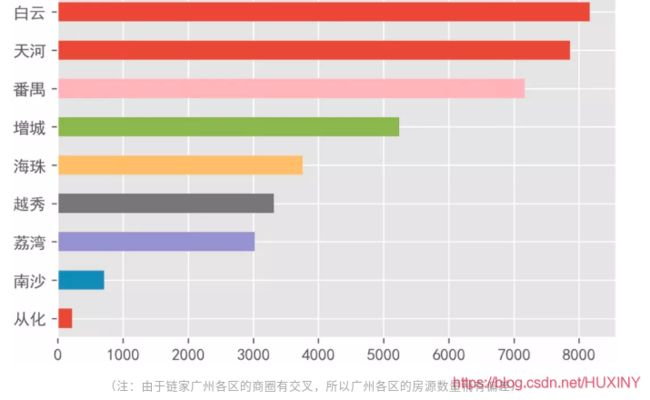
广州房源在四个城市中是最多的,共有39457条,主要集中在白云、天河、越秀、荔湾,以及海珠和番禺。其中白云、天河和番禺房源都超过6000条,选择丰富,不过看图也知道,3号线通勤压力巨大。
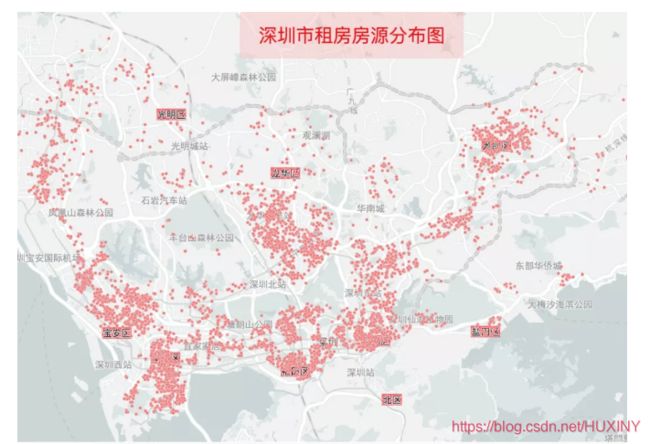

结论:
深圳的房源共有20054条,更集中在各区,除了四个新区零星分布的房源外,主要还是分布在宝安、南山(科技园)、福田、罗湖、龙岗区中心,以及坂田、布吉、3号线沿线,11号线沿线(是市中心的租金太贵了吧?)
二、北上广内区域租金分布可视化
租房房源分布透露出来的信息其实不多,我们更关心的是各区域的价格。为此我们计算了各房源每平米每月的租金,并绘制了热力地图,先来看北京的。

可以看到北京市每平米租金大于100元的房子集中在四环以内以及四环东北边。租金最贵的房子集中在西城区(金融街)、东城区(王府井)、朝阳区(朝阳公园)、海淀区(北大)。想要花2000块钱租一间20平的房子,要么去五环外,要么去西南边上。
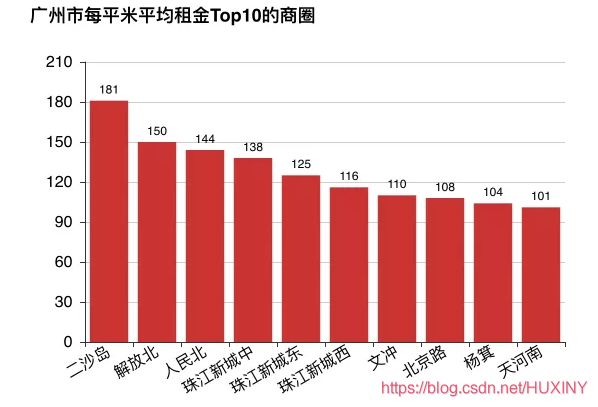
按商圈来看,每平米平均租金前50的商圈中,北京就占了27个,上海和深圳分别是11和10个,广州最少,只有2个。

北京每平米平均租金前10的商圈,租金在每平米200元左右徘徊。最贵的商圈东单,每平米要239元,也就意味着,在东单租一个30平的房子,一个月需要7170块钱,租一个80平的房子,一个月需要19120元。
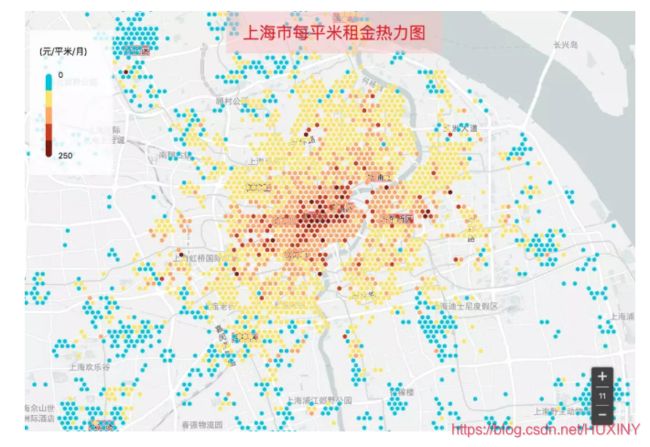
可见上海每平米租金大于100元的房源主要集中在静安、黄浦、长宁、徐汇和浦东。中心市区几乎没有每平米租金低于100元的。出了市区,房价低于100元可选择的区域还是比较多的。

上海每平米平均租金前10的商圈较北京要好一些,租金在170元左右徘徊。其中租金最高的商圈新天地,每平米租金为213元。
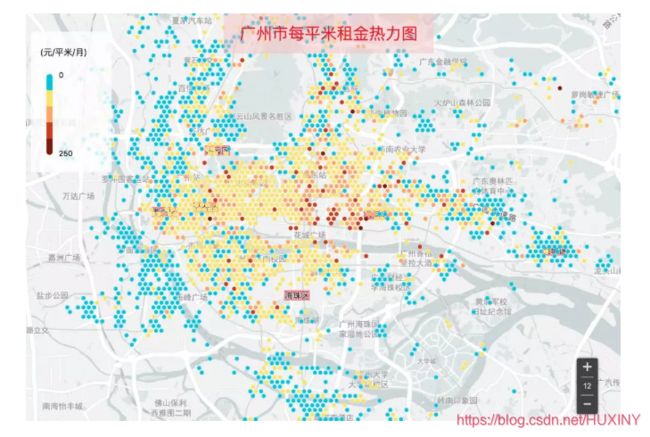
相较北京和上海,广州每平米月租金明显以100元以下的房源占主导。100元以上的比较零星,主要分布在体育中心、跑马场、以及岗顶站周围,荔湾、越秀中心也有一些。看来广州还是一个租房比较友好的城市啊。

另外可以看到位于南边的番禺区,房源多,而且基本每平米租金都在50元以内,2000元内能租一个40平的房子,番禺广场坐地铁到体育西只需半个小时,票价7元(6折4.2元),这也不失为一个选择,只是坐3号线可能被挤扁。
三、房源距地铁口租金的关系可视化
租房,其中一个终点考虑的因素就是距离地铁的远近。我们把个城市房源距离最近地铁站的距离跟每平米租金进行了回归分析,并且计算了相关系数。

可以看到,最近地铁距离和每平米租金之间当然是有相关性的,距离地铁越近,租金越贵。北上广深的相关系数分别是-0.13,-0.17,-0.12,-0.13,可见,上海地铁站的距离对租金的影响最大,广州最小。
我们还计算了各城市地铁距离每100米的租金均价。

可见,北京市只要地铁在900以内,每平米租金变化不大。900米和1000米租金差距为12.5元,也就是说,租一个20平的房子,距离地铁站900米和1000米的租金差距是250元。
上海市只要地铁在700以内,每平米租金变化不大,700以上租金开始明显下降。
广州市每平米租金明显比其它城市低。同样,只要地铁在900以内,租金变化不大。900米和1000米租金差距为12元。
深圳市只要地铁在400以内,租金变化不大。400米和500米租金差距为17.6元。也就是说,租一个20平的房子,距离地铁站400米和500米的租金差距是352元。
四、房屋大小与租金关系可视化
先来看这么一张图:

我们把各城市房源的面积和每平米均价绘制出关系图。可以看到,不管是哪个城市,出租面积在15平米以内的房子每平米租金都是最贵的,当然这里不排除租金贵的区域有更多单独出租的小房间这个原因。但是还是可以看出来,如果有认识的好友一起租大房子,不仅每平米的租金更便宜,而且还可以有一个大点的公用客厅。
结论
租个人房源好还是公寓好
现在公寓房越来越多,我们在面临选择的时候,都会想是租个人房源好还是公寓好呢?个人房源质量参差不齐,遇上好的真不容易。而公寓统一装修,风格现代,但是却有各种各样的问题(甲醛、隔音、乱收费等)。
这里给大家提供另一维度的思考:价格。

广州和深圳公寓数量占总房源数量的20%和51%(深圳怎么那么多公寓?)。可见广州和深圳公寓都要比个人房源贵一些,广州平均每平米贵12元,深圳贵2元。
北上广深租房时都看重什么
统计了北上广深各城市房源最多的3种户型。
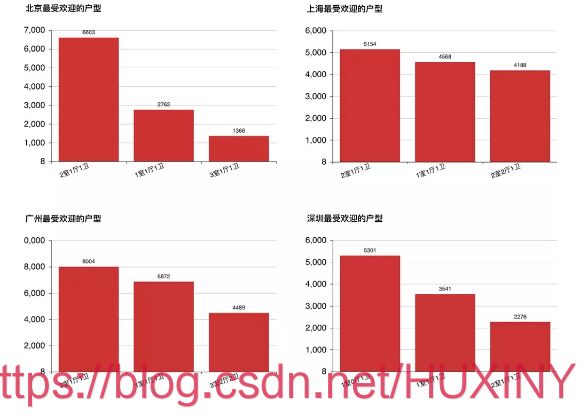
可见,北上广都偏爱2室1厅1卫的房子,而深圳却是1室0厅1卫的房子最多,看来,在深圳奋斗的人,能住带厅的房子已经不容易了。不过四个城市都是小户型出租的居多。
最后,我们对每个房源的标签进行了统计,并且绘制了词云图,可以看出各城市租房时思考的侧重点。
数据库爆炸图

部分实现代码
import os
import re
import time
import requests
from pymongo import MongoClient
from info import rent_type, city_info
class Rent(object):
"""
初始化函数,获取租房类型(整租、合租)、要爬取的城市分区信息以及连接mongodb数据库
"""
def __init__(self):
self.rent_type = rent_type
self.city_info = city_info
host = os.environ.get('MONGODB_HOST', '127.0.0.1') # 本地数据库
port = os.environ.get('MONGODB_PORT', '27017') # 数据库端口
mongo_url = 'mongodb://{}:{}'.format(host, port)
mongo_db = os.environ.get('MONGODB_DATABASE', 'Lianjia')
client = MongoClient(mongo_url)
self.db = client[mongo_db]
self.db['zufang'].create_index('m_url', unique=True) # 以m端链接为主键进行去重
def get_data(self):
"""
爬取不同租房类型、不同城市各区域的租房信息
:return: None
"""
for ty, type_code in self.rent_type.items(): # 整租、合租
for city, info in self.city_info.items(): # 城市、城市各区的信息
for dist, dist_py in info[2].items(): # 各区及其拼音
res_bc = requests.get('https://m.lianjia.com/chuzu/{}/zufang/{}/'.format(info[1], dist_py))
pa_bc = r"data-type=\"bizcircle\" data-key=\"(.*)\" class=\"oneline \">"
bc_list = re.findall(pa_bc, res_bc.text)
self._write_bc(bc_list)
bc_list = self._read_bc() # 先爬取各区的商圈,最终以各区商圈来爬数据,如果按区爬,每区最多只能获得2000条数据
if len(bc_list) > 0:
for bc_name in bc_list:
idx = 0
has_more = 1
while has_more:
try:
url = 'https://app.api.lianjia.com/Rentplat/v1/house/list?city_id={}&condition={}' \
'/rt{}&limit=30&offset={}&request_ts={}&scene=list'.format(info[0],
bc_name,
type_code,
idx*30,
int(time.time()))
res = requests.get(url=url, timeout=10)
print('成功爬取{}市{}-{}的{}第{}页数据!'.format(city, dist, bc_name, ty, idx+1))
item = {'city': city, 'type': ty, 'dist': dist}
self._parse_record(res.json()['data']['list'], item)
total = res.json()['data']['total']
idx += 1
if total/30 <= idx:
has_more = 0
# time.sleep(random.random())
except:
print('链接访问不成功,正在重试!')
def _parse_record(self, data, item):
"""
解析函数,用于解析爬回来的response的json数据
:param data: 一个包含房源数据的列表
:param item: 传递字典
:return: None
"""
if len(data) > 0:
for rec in data:
item['bedroom_num'] = rec.get('frame_bedroom_num')
item['hall_num'] = rec.get('frame_hall_num')
item['bathroom_num'] = rec.get('frame_bathroom_num')
item['rent_area'] = rec.get('rent_area')
item['house_title'] = rec.get('house_title')
item['resblock_name'] = rec.get('resblock_name')
item['bizcircle_name'] = rec.get('bizcircle_name')
item['layout'] = rec.get('layout')
item['rent_price_listing'] = rec.get('rent_price_listing')
item['house_tag'] = self._parse_house_tags(rec.get('house_tags'))
item['frame_orientation'] = rec.get('frame_orientation')
item['m_url'] = rec.get('m_url')
item['rent_price_unit'] = rec.get('rent_price_unit')
try:
res2 = requests.get(item['m_url'], timeout=5)
pa_lon = r"longitude: '(.*)',"
pa_lat = r"latitude: '(.*)'"
pa_distance = r"(\d*)米"
item['longitude'] = re.findall(pa_lon, res2.text)[0]
item['latitude'] = re.findall(pa_lat, res2.text)[0]
distance = re.findall(pa_distance, res2.text)
if len(distance) > 0:
item['distance'] = distance[0]
else:
item['distance'] = None
except:
item['longitude'] = None
item['latitude'] = None
item['distance'] = None
self.db['zufang'].update_one({'m_url': item['m_url']}, {'$set': item}, upsert=True)
print('成功保存数据:{}!'.format(item))
@staticmethod
def _parse_house_tags(house_tag):
"""
处理house_tags字段,相当于数据清洗
:param house_tag: house_tags字段的数据
:return: 处理后的house_tags
"""
if len(house_tag) > 0:
st = ''
for tag in house_tag:
st += tag.get('name') + ' '
return st.strip()
@staticmethod
def _write_bc(bc_list):
"""
把爬取的商圈写入txt,为了整个爬取过程更加可控
:param bc_list: 商圈list
:return: None
"""
with open('bc_list.txt', 'w') as f:
for bc in bc_list:
f.write(bc+'\n')
@staticmethod
def _read_bc():
"""
读入商圈
:return: None
"""
with open('bc_list.txt', 'r') as f:
return [bc.strip() for bc in f.readlines()]
if __name__ == '__main__':
rent = Rent()
rent.get_data()
选题指导, 项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md