linux环境Mechanize安装,Python 爬虫:Mechanize 安装与测试
原标题:Python 爬虫:Mechanize 安装与测试
Mechanize是Python的一个模块,用于模拟浏览器。Mechanize的易用性和实用性比较平衡,功能强大而又简单易用。
1、安装Mechanize模块
Mechanize在官网中给出了3种安装方法:easy_install安装、源码安装和git安装。实际安装时根据平台特性选择最简单的安装方法即可。
(1)Windows下安装Mechanize
在中安装的第三方模块,最简单的方法莫过于pip了(前提条件是已经配置过pip源了,使用初始源会比较慢)。打开cmd.exe,执行命令:
pip install mechanize
执行结果如图1所示。

图1 Windows安装mechanize
已经把Mechanize安装到Windows上,可以直接使用了。
(2)Linux下安装Mechanize
在下找安装软件最简单的方法还是apt-get,感谢“万能”的Debian软件库,即使是模块也可以用apt-get一键安装。不必介意Mechanize官网上的安装建议,怎么简单怎么来就可以了。执行命令:
apt-get install python-mechanize
执行结果如图2所示。

图2 Linux安装Mechanize
2、Mechanize测试
Mechanize模块常用的命令、方法并不多,作为普通使用者,无须追求掌控所有细节,只需要能使用、会使用即可。它只是一个很简单的模块,多试几次就能熟练掌握。
(1)Mechanize百度
先试一下最简单的用法,以最常用的网站百度为例。使用Mechanize访问百度搜索站点,并使用百度搜索“Python”得到返回结果。如果不使用Mechanize,就只能在浏览器中输入搜索的关键字,再观察URL的变化规律,最后将所有的URL注入列表中,一个个地返回结果爬取数据。下面演示如何使用Mechanize模拟浏览器,搜索关键字。
使用Putty连接到,运行程序,并导入Mechanize模块,如图3所示。

图3 Mechanize环境
在Python环境下,执行命令:
br=mechanize.Browser
br.set_handle_equiv(True)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
br.set_handle_gzip(False)
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor,max_time=1)
br.addheaders=[('User-Agent','Mozilla/5.0(X11;U;Linux i686;en-US;rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1')]
执行结果如图4所示。

图4 Browser环境设置
使用Mechanize浏览器打开百度搜索的主页,并查看网页中的框架。执行命令:
br.open('https://www.baidu.com'):
for form in br.forms:
print form
执行结果如图5所示。
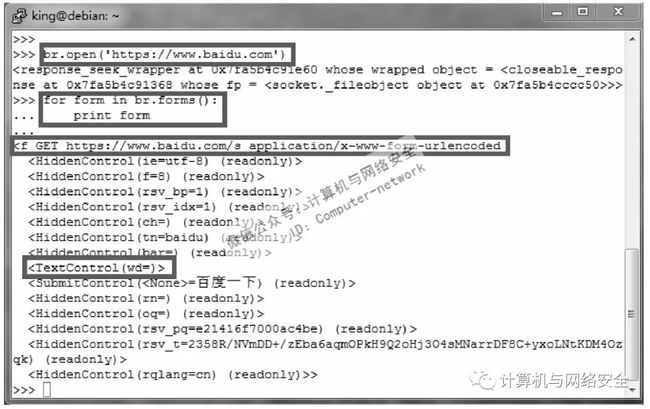
图5 显示网页框架
从图5中可以看出,只有一个名字为f的框架(有时候框架没有名字,只能用它们的顺序来选择,比如第一个框架是nr=0,第二个是nr=1,以此类推)。输入文字的位置为文本输入框。选择框架,在框架内输入数据后提交数据。以搜索“Python”为例,执行命令:
br.select_form(name='f')
br.form['wd']='Python 网络爬虫'
br.submit
执行结果如图6所示。

图6 搜索关键字
返回搜索的结果,执行命令:
print br.response.read
执行结果如图7所示。
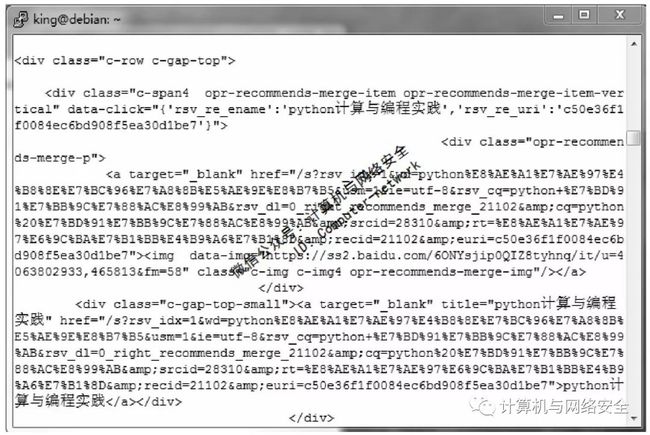
图7 返回搜索结果
查看返回页面的所有链接,执行命令:
for link in br.links:
print("%s:%s" %(link.url,link.text))
执行结果如图8所示。

图8 返回链接
使用Mechanize浏览器打开指定链接,执行命令:
newLink=br.click_link(text='自己动手写网络爬虫')
br.open(newLink)
执行结果如图9所示。

图9 打开链接
如果觉得打开的链接不对,还可以使用br.back命令返回上一个页面。Mechanize的基本操作就是这些了。
(2)Mechanize光猫F460
Mechanize可以模拟登录,只是现在几乎所有的站点登录都需要输入。虽然也有开源的解决方案,可以解决什么的,但是有更简单的解决方案,没必要在这里与死磕。最简单的方法就是最合适的方法,宁愿多敲几行,也要选择最简单的。
如今无须验证码就可以登录的站点不好找。好在身边有一个现成的Web符合要求,F460光猫的配置页面,而且正好是动态回复数据的,简直是为Mechanize量身定做的。
在浏览器中打开光猫F460的配置页面http://192.168.1.1,执行结果如图10所示。
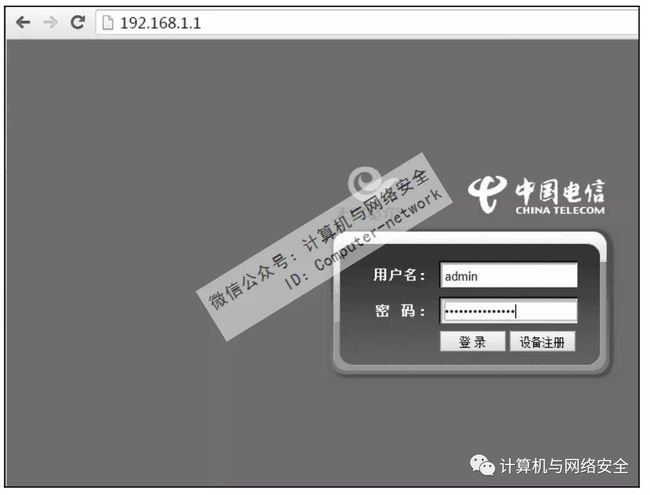
图10 F460光猫登录
填写用户名和后单击“登录”按钮(用户名是admin,要么直接问电信,要么在百度里搜索一下“hack f460光猫”),进入配置界面,结果如图11所示。

图11 获取光猫F460信息
先用模拟测试一次。打开Putty,登录到,进入环境。执行命令:
import mechanize
cj=mechanize.CookieJar
br=mechanize.Browser
br.set_handle_equiv(True)
br.set_handle_gzip(False)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
br.set_handle_refresh(mechanize._http.HTTPRefreshPorcessor,max_time=1)
br.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/43.0.2357.81 Safair/537.36')]
br.set_cookiejar(cj)
br.open('http://192.168.1.1')
执行结果如图12所示。

图12 模拟浏览器打开光猫F460主页
查看网页上的框架,执行命令:
for form in br.forms:
print form
执行结果如图13所示。

图13 查看主页框架
从图13可以得知,主页框架的名字是fLogin,框架内文本框变量名是Username,密码框的变量名是Password。进入文本框,给变量赋值后,发送数据。执行命令:
br.select_form(name='fLogin')
br.form['Username']='admin'
br.form['Password']='******' #这里输入光猫F460的密码
br.submit
print br.response.read.decode('gb2312')
其中,在选择框架时,可以用框架名字,也可以用框架的序列号,序列号从0开始。例如,在这里选择框架时就可以用br.select_form(nr=0)。如果需要选择第二个框架,则是br.select_form(nr=1)。执行结果如图14所示。

图14 获取框架URL
这里显示了框架的链接。根据链接的地址template.gch,直接使用Mechanize创建的浏览器打开这个链接就可以了。执行命令:
br.open('http://192.168.1.1/template.gch')
print br.response.read.decode('gb2312')
执行结果如图15所示。

责任编辑: