max等聚合函数和group by搭配使用的注意事项
1 group by的特点
1.1 定义
group_by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组。
如果不在group by 后的分组中使用聚合函数,一般只会返回各个分组中的第一条数据,而且各分组内的数据是默认按照asc升序排列。
如果group by 和having后面接了order by,则这个order by 不会在得到分组的结果前,对分组内的数据进行排序,而是在组与组间的数据进行排序,
有人会问什么需要在group by得出最终结果前,对分组做一次排序呢,这是由上一个讲解的group by的特性决定的,因为它只会返回各个分组中的第一条数据,有的时候的需求是返回各个分组的最后一条数据,或者要求组内的数据按照某一个字段有序或者倒序,那么光group by 就满足不了需求。在2中的例子中就能碰到这种需求的解决方法。
1.2 例子(后续的案例都会用到这张表)
1 比如创建一个student表,插入相应的数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT '' COMMENT '姓名',
`age` int(3) NULL DEFAULT 0 COMMENT '年龄',
`class` int(4) NULL DEFAULT 0 COMMENT '班级',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = MyISAM AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '张三', 22, 1);
INSERT INTO `student` VALUES (2, '李四', 26, 1);
INSERT INTO `student` VALUES (3, '王五', 20, 2);
INSERT INTO `student` VALUES (4, '赵六', 20, 2);
INSERT INTO `student` VALUES (5, '孙七', 22, 3);
INSERT INTO `student` VALUES (6, '李八', 28, 3);
2 使用select * from student order by class,让大家都看到数据表的信息
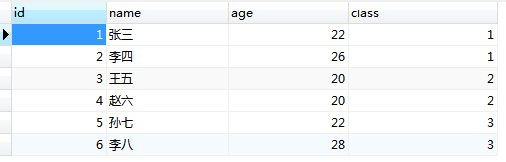
3 随后对class字段执行分组查询(class是关键字,所以需要插入反引号)
SELECT * FROM student GROUP BY
class;
| id | name | age | class |
|---|---|---|---|
| 1 | 张三 | 22 | 1 |
| 3 | 王五 | 20 | 2 |
| 5 | 孙七 | 22 | 3 |
可以看到其分组后查询结果默认为分组中的第一行
2 group by 配合 max等的聚合函数使用
常用的聚合函数:count() , sum() , avg() , max() , min()
2.1 case1
1 e.g1:查询每一个班级所拥有的学生人数
select `class` as 班级, count(*) as 学生人数 from student group by `class`
2 查询结果
| 班级 | 学生人数 |
|---|---|
| 1 | 2 |
| 2 | 2 |
| 3 | 2 |
2.2 case2
1 e.g2: 查询每一个班级中的最大的学生年龄是多少岁
select `class` as 班级, max(age) as 年龄 from student group by `class`
2 查询结果
| 班级 | 最大年龄 |
|---|---|
| 1 | 26 |
| 2 | 27 |
| 3 | 28 |
| 通过以上两个案例,可知当我们进行使用了group by函数的时候,通过在其结果集合中也会带上 group by 后面使用的字段。 |
3 group by 和 max 函数使用时,出现问题的案例
3.1 case3
1 e.g1:稍微在case2的基础上改为:查询每一个班级中的最大的学生年龄及其姓名
2 sql1
如果我们使用下面的sql语句:
select name as 姓名, max(age) as 年龄, , `class` as 班级 from student group by `class`
其查询结果为
| 姓名 | 年龄 | 班级 |
|---|---|---|
| 张三 | 26 | 1 |
| 王五 | 27 | 2 |
| 孙七 | 28 | 3 |
但是通过查总表可知,张三的年龄是22岁的,王五是20岁,孙七是22岁,可以看出,这里的查询出现了问题,这就是group by的特性(如果一个带查询的字段没有被聚合函数处理,则group by默认返回组内的第一行数据)在捣乱
3 sql2
select name as 姓名, max(age) as 年龄,
classas 班级 from ( select * from student order by age desc ) as b group byclass
其查询结果为
| 姓名 | 年龄 | 班级 |
|---|---|---|
| 张三 | 26 | 1 |
| 王五 | 27 | 2 |
| 孙七 | 28 | 3 |
会发现其结果仍然有问题,为什么呢?因为这少了一个derived的操作,数据库会自动忽略order by 操作
使用explain查询其执行计划(关于explain的作用和结果字段详细解析请查看此链接)
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using temporary |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+
4 sql2的改进
select name as 姓名, max(age) as 年龄,
classas 班级 from ( select * from student order by age desc) as b group byclass
查询结果为:
| 姓名 | 年龄 | 班级 |
|---|---|---|
| 李八 | 28 | 1 |
| 赵六 | 27 | 2 |
| 李四 | 26 | 3 |
| 执行时间为0.01s | ||
| 再核对刚开始的表格数据,发现没有任何问题 |
使用explain查看这条sql语句的执行计划,id = 2的行,其select_type = derived表明这是一个 生成子表的select(来自from子句的子查询),然后再看id = 1的行,其table字段(代表表名。有时不是真实的表名,看到的是,数字X是第几步执行的结果)
为derived2,可知其依赖于id = 2 的派生表。
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using temporary |
| 2 | DERIVED | student | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using filesort |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
3.2 现在有一张学生成绩表sc,有sno,class,grade,我现在想要一个sql找出每一个班级分数最高的学生的成绩,班级以及学号?(度小满金融信贷系统平台部三面)
3.2.1 方法一
SELECT s.sno, s.class, s.grade
FROM student_scores s
JOIN (
SELECT class, MAX(grade) as highest_grade
FROM student_scores
GROUP BY class
) as max_scores
ON s.class = max_scores.class AND s.grade = max_scores.highest_grade;
3.2.2 方法二
select s.sno,s.class,s.grade
from (
select class, grade as hg
from student_scores order by grade desc
) as tmp
group by class
3.2.3 方法一和二的比较
您提供了两种方法来查询每个班级分数最高的学生的成绩、班级和学号。让我们分析这两种方法:
方法一
这种方法使用了子查询和JOIN操作。子查询首先为每个班级找到最高的成绩,然后主查询通过JOIN操作将这些最高的成绩与原始表进行匹配,从而获取与这些最高成绩相对应的学号和班级。
优点:
- 这种方法在逻辑上很清晰,容易理解。
- 它能够处理每个班级有多个学生获得相同最高分的情况。
缺点:
- 使用JOIN操作可能会使查询的效率稍微降低,特别是当表很大时。
方法二
这种方法首先对学生成绩表进行排序,然后使用GROUP BY语句为每个班级选择一个记录。但是,这种方法有一个问题:它假设ORDER BY在GROUP BY之前执行,这在某些数据库中可能不是这样。
优点:
- 查询较为简洁。
缺点:
- 这种方法可能不会在所有数据库中都正常工作,因为它依赖于特定的执行顺序。
- 如果每个班级有多个学生获得相同的最高分,这种方法可能只会返回其中一个学生的记录。
结论:
如果您知道您的数据库支持方法二中的查询,并且您确定每个班级只有一个学生获得最高分,那么您可以使用方法二。否则,方法一可能是更安全、更通用的选择。
4 group by的复杂应用
聚合函数一般如max,avg,sum等配合group by 和having使用,having 查询的一般是对分组后的各个组的组内数据进行相同的筛选操作
4.1
题目:运动会比赛信息的数据库,有如下三个表: 运动员athlete(运动员编号 Ano,姓名Aname,性别Asex,所属系名 Adep), 项目 item (项目编号Ino,名称Iname,比赛地点Ilocation), 成绩score (运动员编号Ano,项目编号Ino,积分Score)。写出目前总积分最高的系名及其积分,SQL语句实现正确的是
步骤一:导入表结构和数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for athlete
-- ----------------------------
DROP TABLE IF EXISTS `athlete`;
CREATE TABLE `athlete` (
`Ano` bigint(0) NOT NULL,
`Aname` varchar(10) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`Adep` varchar(10) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
PRIMARY KEY (`Ano`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of athlete
-- ----------------------------
INSERT INTO `athlete` VALUES (123, '小米', '自动化院');
INSERT INTO `athlete` VALUES (223, '妲己', '计算机学院');
INSERT INTO `athlete` VALUES (225, '小兰', '化学院');
INSERT INTO `athlete` VALUES (226, '小明', '计算机学院');
INSERT INTO `athlete` VALUES (227, '小天', '计算机学院');
INSERT INTO `athlete` VALUES (228, '小绿', '软件学院');
INSERT INTO `athlete` VALUES (334, '小红', '软件学院');
-- ----------------------------
-- Table structure for item
-- ----------------------------
DROP TABLE IF EXISTS `item`;
CREATE TABLE `item` (
`Ino` bigint(0) NOT NULL,
`Iname` varchar(10) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`Ilocation` varchar(10) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
PRIMARY KEY (`Ino`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of item
-- ----------------------------
INSERT INTO `item` VALUES (1, '篮球', '体育馆');
INSERT INTO `item` VALUES (2, '足球', '体院馆');
INSERT INTO `item` VALUES (3, '跳远', '户外');
INSERT INTO `item` VALUES (4, '跳高', '户外');
INSERT INTO `item` VALUES (5, '多人运动', '室内');
-- ----------------------------
-- Table structure for score
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`Ano` bigint(0) NOT NULL,
`Ino` bigint(0) NOT NULL,
`Score` bigint(0) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES (123, 1, 12);
INSERT INTO `score` VALUES (123, 2, 12);
INSERT INTO `score` VALUES (223, 3, 12);
INSERT INTO `score` VALUES (334, 3, 22);
INSERT INTO `score` VALUES (223, 5, 22);
INSERT INTO `score` VALUES (227, 2, 12);
INSERT INTO `score` VALUES (227, 4, 44);
INSERT INTO `score` VALUES (228, 5, 55);
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(0) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT '' COMMENT '姓名',
`age` int(0) NULL DEFAULT 0 COMMENT '年龄',
`class` int(0) NULL DEFAULT 0 COMMENT '班级',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = MyISAM AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '张三', 22, 1);
INSERT INTO `student` VALUES (2, '李四', 26, 1);
INSERT INTO `student` VALUES (3, '王五', 20, 2);
INSERT INTO `student` VALUES (4, '赵六', 27, 2);
INSERT INTO `student` VALUES (5, '孙七', 22, 3);
INSERT INTO `student` VALUES (6, '李八', 28, 3);
SET FOREIGN_KEY_CHECKS = 1;
步骤二:分析并且编写查询sql
这里的重点是order by和limit 1的使用,所以能查询出要求的max值
注意,只有在使用了连接的时候(包括内连接和外连接),才会用到on,否则一般使用where
select
a.Adep,
sum(s.Score) total_score
from
athlete a,
score s
where
s.Ano = a.Ano
group by a.Adep order by total_score desc limit 1
步骤三:得到查询结果
+------------+-------------+
| Adep | total_score |
+------------+-------------+
| 计算机学院 | 90 |
+------------+-------------+