图像特征Vol.1:计算机视觉特征度量|第一弹:【纹理区域特征】
目录
- 一、前言
- 二、纹理区域度量
-
- 2.1:边缘特征度量
- 2.2:互相关和自相关特征
- 2.3:频谱方法—傅里叶谱
- 2.4:灰度共生矩阵(GLCM)
- 2.5:Laws纹理特征
- 2.6:局部二值模式(LBP)
一、前言
什么是计算机视觉特征?
简单来说就是图像特征,对于我们来说,看到一张图片,能很自然的说出和描述图像中的一些特征,但是同样的图片,丢给计算机,只是一个二维矩阵,计算机需要从这个图像中提取计算得到一些数值表示,来描述这个图像所具有的特征:颜色、形状、纹理等。
什么是计算机视觉特征度量?
就是研究:如何从图像中,计算得到这些特征的数值表示(如颜色直方图、梯度直方图、形状描述符),来表示、度量这个图像的特征,方便后续任务(如图像检索、目标跟踪、人脸识别、物体识别等)的完成。
根据描述图像数据中不同范围的特征信息,可以将特征度量分为这三类:
-
全局特征度量(Global Feature Measurement):
- 全局特征度量关注的是整个数据集或整个图像的特征,用于描述整体性质或全局统计信息。
- 全局特征通常基于整个数据集或整个图像的分布、统计、形状、颜色等特征进行计算。
- 全局特征度量具有以下特点:
- 考虑了整体信息,对整个数据集或图像进行分析。
- 对数据集或图像的整体变化具有一定的敏感性。
- 适用于整体分类、整体识别等任务,其中整个数据集或图像的特征可以用于区分不同的类别。
- 常见的全局特征度量方法:包括整体颜色直方图、整体纹理特征、整体形状描述子等。
-
全局特征度量(Global Feature Measurement):
- 局部特征度量关注的是数据中的局部区域,并提取该区域的特征来描述其内容或性质。
- 典型的局部特征包括角点、边缘、纹理等,通常通过在局部区域内进行局部分析和特征提取来捕捉这些特征。
- 局部特征度量具有以下特点:
- 仅关注数据的局部区域,忽略了全局信息。
- 对光照、尺度和旋转等变化具有一定的鲁棒性。
- 适用于目标检测、特征匹配等任务,其中目标通常可以通过其局部特征进行描述和识别
- 常见的局部特征度量方法包括 角点检测、边缘检测、尺度不变特征变换(SIFT)、加速稳健特征(SURF) 等。
-
区域特征度量(Regional Feature Measurement):
- 区域特征度量关注的是数据中的整个区域或全局范围,并提取该区域的特征来描述其整体性质。
- 典型的区域特征包括颜色直方图、纹理直方图、形状描述子等,通常通过对整个区域内的数据进行全局分析和特征提取来捕捉这些特征。
- 区域特征度量具有以下特点:
- 关注数据的全局信息,可以提供更全面和综合的描述。
- 对局部变化和噪声具有一定的鲁棒性。
- 适用于图像分类、目标识别等任务,其中整个区域的特征可以用于区分不同的类别。
- 常见的区域特征度量方法包括颜色直方图、纹理特征提取、形状描述子等。
特征度量的方法
视觉特征度量的方法,是本节的重点,我们将其分为三大类,每一个大类中有不同的方法,对于每一个方法的原理不会去深究,重点在于每种方法的应用而展开。
接下来,让我们逐个击破吧,GO,Go,Go!
二、纹理区域度量
什么是图像纹理?
纹理其实是一个很形象的特征表述,你可以想象成它是目标的表面,例如:一个麻布袋子和丝绸面料相比。对于图像来说,纹理是图像通道表面的描述,图像中每个像素点的颜色强度或者亮度,可以像地形图那样表示出来。
在计算机视觉中,纹理设计的目的是使用离散方法来描述纹理的感知属性。从感知层面用下面几个属性来描述纹理:
- 对比度
- 色彩
- 粗细度
- 定向性
- 直线相似性
- 粗糙度
- 恒定性
- 分组
- 分割
纹理度量的应用(部分)
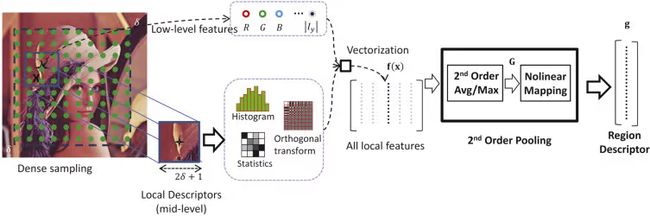
纹理可以表示为全局特征或者局部区域特征,通过区域内像素的统计关系表示局部性,通过区域内像素值汇总来表示全局性。局部区域的微纹理可以作为有用的特征描述子(实际上,特征描述子和纹理度量之间的区别很小);宏观纹理可以描述区域的均匀纹理(例如:湖面、草地),因此纹理可以自然地应用到图像分割上。
纹理区域度量的目的是衡量图像中纹理区域之间的相似性或差异性,以在图像检索、图像分类、目标跟踪等应用中进行区分和匹配。
纹理度量方法
接下来,我们将围绕这常见的7种纹理度量方法,简单进行介绍以及给出相关应用和示例。
- 边缘特征;
- 互相关特征;
- Fourier谱、小波谱特征;
- 共生矩阵、Haralick特征与扩展SDM特征;
- Laws纹理特征;
- 局部二值模式(Local Binary Pattern,LBP);
- 动态纹理。
2.1:边缘特征度量
所谓边缘特征度量,不仅仅是能把边缘给检测到(仅仅是检测到边缘,那只算是图像处理方面的内容),更要是基于边缘,把图像特征描述出来,即生成图像边缘特征的描述符,用来表示图像中的特征信息,使得图像在不同尺度、旋转、光照等情况下具有不变性,从而更好地进行匹配和识别。
特征描述符:
1.特征描述符是特征描述子的具体数值表示,它是特征描述子的向量形式。
2.特征描述符通常是一个固定长度的向量,其中每个元素代表了某个特征的某种度量或表示。此类特征向量往往具备比输入数据更小的维度,从而可以使用更高效简洁的分类器实现识别等任务
3.特征描述符的长度和具体特征的表示方法取决于所使用的特征提取算法和特征描述子的设计。
一般步骤:
- 在每个下高速处计算梯度g(d),选择适当的梯度算子g()(Sobel算子、Canny算子等)然后选择合适的核大小或者距离d,检测边缘
- 通过计算每个边缘的梯度方向,获得量化的微观或宏观的边缘特征
- 将边缘梯度特征根据方向分箱到直方图上,分析边缘特征值的分布和统计信息
2.2:互相关和自相关特征
互相关性是对两个信号之间相似性的度量,对于一维信号,两个信号之间可以有时间上的偏移,对于图像二维信号,两个信号之间可以有时间上的偏移(在信号处理文献中,互相关性也称为卷积、滑动内积)。而自相关性则是信号与自身时间偏移的互相关性性。
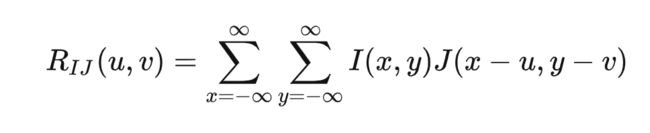
深度学习CNN卷积神经网络中的卷积层的卷积运算,其实就是利用的这种互相关性,当图像局部特征与卷积核(模板)越相似,卷积之后(其实就是互相关运算)得到的结果就越大。而这个卷积核(其实也就是一种特征描述子),就是利用这种互相关性来提取特征的,只不过,在CNN中,卷积核的参数是由网络学习得到的,也就是说,无需我们人为来设计特征!
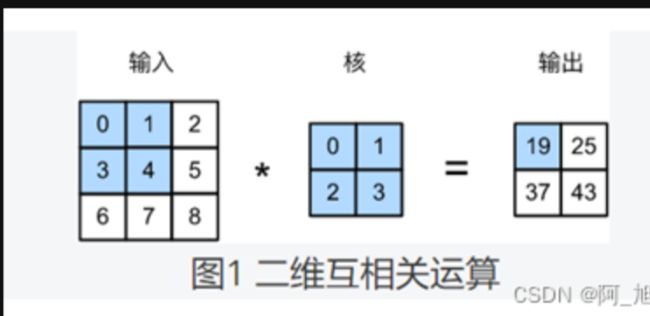
深度学习中的卷积为何能用互相关运算代替
现在大部分的深度学习教程中都把卷积定义为图像矩阵和卷积核的按位点乘。实际上,这种操作亦应该是互相关(cross-correlation),而卷积需要把卷积核顺时针旋转180度(即将卷积核上下翻转再左右翻转)然后再做点乘。卷积运算和互相关运算虽然类似,但如果它们使用相同的核数组,对于同一个输入,输出往往并不相同。
那么,你也许会好奇在深度学习中卷积层为何能使用互相关运算替代卷积运算。这主要原因在于,在深度学习中核数组都是学出来的:卷积层无论使用互相关运算或卷积运算都不会影响模型预测时的输出。假设卷积层使用互相关运算学出某一核数组。设其他条件不变,使用卷积运算学出的核数组即为互相关核数组按上下、左右翻转。也就是说原始输入与学出的已翻转的核数组再做卷积运算时,依然得到的是同样输出。因此大多数深度学习中提到的卷积运算均指互相关运算
2.3:频谱方法—傅里叶谱
关于傅里叶谱和傅里叶变换已经在上篇博客中详说,傅里叶变换和其图像处理中的应用,相信对傅里叶谱有一个很好的认识
基本原理:
傅里叶频谱可借助傅里叶变换得到,它有三个合适描述纹理的性质:
-
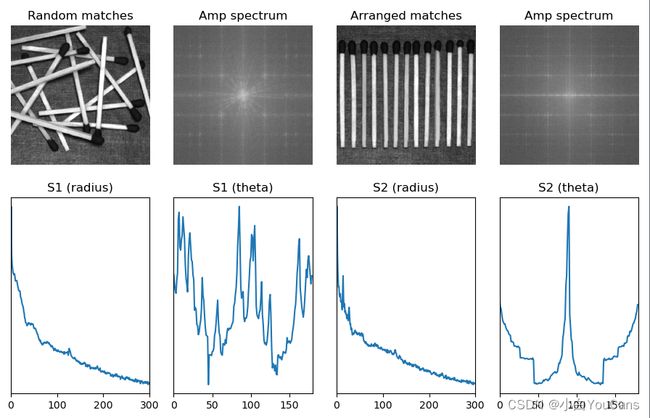
傅里叶频谱中突起的峰值对应纹理模式的主方向(FFT谱作为纹理度量或描述子时会具备旋转不变性,也就是说,原图像空间旋转多少,频率空间也会相应旋转多少,峰值不会改变)。
-
这些峰在频域平面的位置对应模式的基本周期
-
利用滤波把周期性成分除去,用统计方法描述剩下的非周期性部分
把傅里叶幅度谱转换到极坐标中表示为函数 S ( r , θ ),可以简化对频谱特性的解释。S 是频谱函数,r 和 θ是极坐标系的半径和角度坐标轴。(r代表频率,θ代表方向)
S 对于每一个方向 θ 可以简化为一维函数 S θ ( r )(θ固定的一个关于频率的一个函数)
S 对于每一个半径 r 也可以简化为一维函数 S r ( θ )(频率固定,关于周期纹理方向的一个函数)
分别对一维函数 S θ ( r ) 和 S r ( θ )积分,可以获得纹理频谱的全局描述:
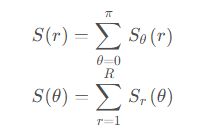
如果纹理具有空间的周期性或确定的方向性,则一维函数 S ( r ) 和 S ( θ ) 在对应的频率具有峰值。以这些峰为组建模式识别提供所需的特征。
OpenCV 例程:

# 14.13 特征描述之纹理谱分析
def halfcircle(radius, x0, y0): # 计算圆心(x0,y0) 半径为 r 的半圆的整数坐标
degree = np.arange(180, 360, 1) # 因对称性可以用半圆 (180,)
theta = np.float32(degree * np.pi / 180) # 弧度,一维数组 (180,)
xc = (x0 + radius * np.cos(theta)).astype(np.int) # 计算直角坐标,整数
yc = (y0 + radius * np.sin(theta)).astype(np.int)
return xc, yc
def intline(x1, x2, y1, y2): # 计算从(x1,y1)到(x2,y2)的线段上所有点的坐标
dx, dy = np.abs(x2-x1), np.abs(y2-y1) # x, y 的增量
if dx==0 and dy==0:
x, y = np.array([x1]), np.array([y1])
return x, y
if dx > dy:
if x1>x2:
x1, x2 = x2, x1
y1, y2 = y2, y1
m = (y2-y1) / (x2-x1)
x = np.arange(x1, x2+1, 1) #[x1,x2]
y = (y1 + m*(x-x1)).astype(np.int)
else:
if y1>y2:
x1, x2 = x2, x1
y1, y2 = y2, y1
m = (x2-x1) / (y2-y1)
y = np.arange(y1, y2+1, 1) # [y1,y2]
x = (x1 + m*(y-y1)).astype(np.int)
return x, y
def specxture(gray):
# cv2.dft 实现图像的傅里叶变换
height, width = gray.shape
x0, y0 = int(height / 2), int(width / 2) # x0=300, y0=300
rmax = min(height, width) // 2 - 1 # rmax=299
print(height, width, x0, y0, rmax)
# FFT 变换 (youcans)
gray32 = np.float32(gray) # 将图像转换成 float32
dft = cv2.dft(gray32, flags=cv2.DFT_COMPLEX_OUTPUT) # 傅里叶变换,(600, 600, 2)
dftShift = np.fft.fftshift(dft) # 将低频分量移动到频域图像的中心
sAmp = cv2.magnitude(dftShift[:, :, 0], dftShift[:, :, 1]) # 幅度谱,中心化 (600, 600)
sAmpLog = np.log10(1 + np.abs(sAmp)) # 幅度谱对数变换 (600, 600)
# FFT 频谱沿半径的分布函数
sRad = np.zeros((rmax,)) # (299,)
sRad[0] = sAmp[x0, y0]
for r in range(1, rmax):
xc, yc = halfcircle(r, x0, y0) # 半径为 r 的圆的整数坐标 (360,)
sRad[r] = sum(sAmp[xc[i], yc[i]] for i in range(xc.shape[0])) # (360,)
sRadLog = np.log10(1 + np.abs(sRad)) # 极坐标幅度谱 youcans 对数变换
# FFT 频谱沿角度的分布函数
xmax, ymax = halfcircle(rmax, x0, y0) # 半径为 xupt 的圆的整数坐标 (360,)
sAng = np.zeros((xmax.shape[0],)) # (360,)
for a in range(xmax.shape[0]): # xmax.shape[0]=(360,)
xr, yr = intline(x0, xmax[a], y0, ymax[a]) # 从(x0,y0)到(xa,ya)线段所有点的坐标 (300,)
sAng[a] = sum(sAmp[xr[i], yr[i]] for i in range(xr.shape[0])) # (360,)
return sAmpLog, sRadLog, sAng
# 纹理的傅里叶频谱分析
gray1 = cv2.imread("../images/Fig1135a.tif", flags=0) # flags=0 读取为灰度图像
gray2 = cv2.imread("../images/Fig1135b.tif", flags=0)
sAmpLog1, sRadLog1, sAng1 = specxture(gray1) # 图像纹理的频谱分析
sAmpLog2, sRadLog2, sAng2 = specxture(gray2)
print(sAmpLog1.shape, sRadLog1.shape, sAng1.shape)
plt.figure(figsize=(9, 6))
plt.subplot(241), plt.axis('off'), plt.title("Random matches"), plt.imshow(gray1, 'gray')
plt.subplot(242), plt.axis('off'), plt.title("Amp spectrum"), plt.imshow(sAmpLog1, 'gray')
plt.subplot(243), plt.axis('off'), plt.title("Arranged matches"), plt.imshow(gray2, 'gray')
plt.subplot(244), plt.axis('off'), plt.title("Amp spectrum"), plt.imshow(sAmpLog2, 'gray')
plt.subplot(245), plt.plot(sRadLog1), plt.title("S1 (radius)"), plt.xlim(0,300), plt.yticks([])
plt.subplot(246), plt.plot(sAng1), plt.title("S1 (theta)"), plt.xlim(0,180), plt.yticks([])
plt.subplot(247), plt.plot(sRadLog2), plt.title("S2 (radius)"), plt.xlim(0,300), plt.yticks([])
plt.subplot(248), plt.plot(sAng2), plt.title("S2 (theta)"), plt.xlim(0,180), plt.yticks([])
plt.tight_layout()
plt.show()
2.4:灰度共生矩阵(GLCM)
基本原理:通过对灰度图像进行计算,得到它的共生矩阵,然后根据共生矩阵计算得到图像的特征参数,来代表图像的某些纹理特征。
灰度共生矩阵的生成:
- 将图像转换为灰度图像(单通道图像),如果原图像已经是灰度图像,则可以直接跳过此步骤。
- 选择一个特定的方向(例如水平、垂直、45度、135度等)和距离(像素之间的间隔距离)来计算共生矩阵。这些选择会影响到纹理特征的提取效果。
- 对于每个像素,统计与指定方向、距离的邻居像素之间的灰度级别共生频数。邻居像素的选择可以是在特定方向上指定距离的像素。
- 构建灰度共生矩阵,其尺寸通常为 N x N,其中 N 为图像的灰度级别数量。共生矩阵中的元素 GLCM(i, j) 表示在指定方向、距离下,像素灰度级别 i 和 j 同时出现的次数。
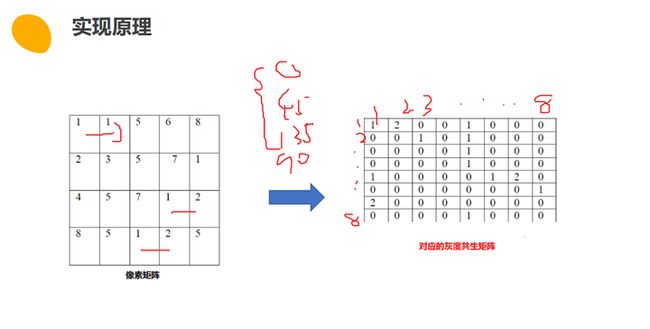
- 对共生矩阵进行归一化,得到共生概率矩阵。共生概率矩阵中的元素 GLCM_prob(i, j) 表示在指定方向、距离下,像素灰度级别 i 和 j 同时出现的概率。
- 根据共生概率矩阵,可以计算一些用于纹理特征描述的统计量,例如对比度、相关性、能量、熵等。这些统计量可以用于进一步分析图像的纹理特征。
特征参数:
-
角二阶矩(Angular Second Moment, ASM)
角二阶矩又称能量,是图像灰度分布均匀程度和纹理粗细的一个度量。若灰度共生矩阵的元素值相近,则能量较小,表示纹理细致;若其中一些值大,而其它值小,则能量值较大。能量值大表明一种较均一和规则变化的纹理模式。

-
熵(Entropy, ENT)
熵度量了图像包含信息量的随机性。当共生矩阵中所有值均相等或者像素值表现出最大的随机性时,熵最大;因此熵值表明了图像灰度分布的复杂程度,熵值越大,图像越复杂。
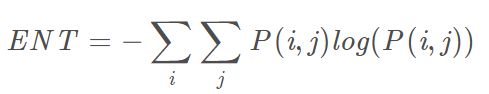
-
对比度(constrast)
度量图像中存在的局部变化。对比度反应了图像的清晰度和纹理的沟纹深浅。纹理越清晰反差越大对比度也就越大
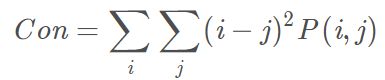
-
反差分矩阵(Inverse Differential Moment, IDM)
也叫做逆方差。反映了纹理的清晰程度和规则程度,纹理清晰、规律性较强、易于描述的,值较大。
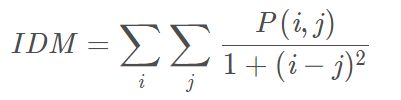
-
相关性(correlation)
用来度量图像的灰度级在行或列方向上的相似程度,因此值的大小反应了局部灰度相关性,值越大,相关性也越大。
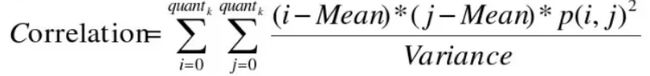
-
同质性(Homogeneity)
反映了图像纹理的同质性,度量图像纹理局部变化的程度。
OpenCV 例程:
skimage 的特征提取库 skimage.feature 提供了函数 greycomatrix 和 greycoprops,可以 计算灰度共生矩阵并提取特征统计量 。
-
函数说明:
skimage.feature.graycomatrix(image, distances, angles, levels=256, symmetric=False, normed=False)skimage.feature.graycoprops(P[, prop]) -
参数说明:
image:整型单通道图像,推荐使用 uint8 灰度图像
distances:像素对的距离偏移量的列表,计算列表中每个偏移量的 GLCM
angles:像素对扫描角度(弧度)列表,计算列表中每个角度值的 GLCM
levels:灰度级,默认值为 256
symmetric:对称性选项,默认值 False 表示将像素对 (i,j) 与 (j,i) 分别计算,True 表示忽略像素对顺序,将 (i,j) 与 (j,i) 视为相同
normed:归一化选项,默认值 False,True 表示对矩阵归一化。
prop:元组,灰度共生矩阵 P 的特征统计量, 包括:对比度 ‘contrast’、相异性 ‘dissimilarity’、同质性 ‘homogeneity’、能量 ‘energy’、相关性 ‘correlation’、能量的平方 ‘ASM’}
返回值是 4维数组,即不同偏移量、不同角度的 GLCM。P [ i , j , d , θ ] P[i,j,d,\theta]P[i,j,d,θ] 是灰度 j 在偏移量 d、角度 θ \thetaθ 处出现灰度 i 的次数。
# 14.11 特征描述之灰度共生矩阵 (skimage)
import cv2
import numpy as np
import matplotlib.pyplot as plt
from skimage.feature import greycomatrix, greycoprops
img = cv2.imread("6.jpg", flags=1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图像
height, width = gray.shape
table16 = np.array([(i // 16) for i in range(256)]).astype("uint8") # 16 levels
gray16 = cv2.LUT(gray, table16) # 灰度级压缩为 [0,15]
# 计算灰度共生矩阵 GLCM
dist = [1, 4] # 计算 2 个距离偏移量 [1, 2]
degree = [0, np.pi / 4, np.pi / 2, np.pi * 3 / 4] # 计算 4 个方向
glcm = greycomatrix(gray16, dist, degree, levels=16) # 灰度级 L=16
print(glcm.shape) # (16,16,2,4)
# 由灰度共生矩阵 GLCM 计算特征统计量
for prop in ['contrast', 'dissimilarity', 'homogeneity', 'energy', 'correlation', 'ASM']:
feature = greycoprops(glcm, prop).round(4) # (2,4)
print("{}: {}".format(prop, feature))
plt.figure(figsize=(9, 6))
plt.suptitle("GLCM by skimage, youcans")
for i in range(len(dist)):
for j in range(len(degree)):
plt.subplot(2, 4, i * 4 + j + 1), plt.axis('off')
plt.title(r"d={},$\theta$={:.2f}".format(dist[i], degree[j]))
plt.imshow(glcm[:, :, i, j], 'gray')
plt.tight_layout()
plt.show()
结果:
contrast: [[0.1284 0.2056 0.1544 0.1951]
[0.5156 0.5961 0.631 0.6285]]
dissimilarity: [[0.1079 0.1556 0.1257 0.1561]
[0.3011 0.3321 0.3453 0.3474]]
homogeneity: [[0.9478 0.9262 0.9395 0.9253]
[0.8661 0.8546 0.8499 0.8485]]
energy: [[0.3808 0.3664 0.3748 0.3654]
[0.33 0.3242 0.3213 0.3204]]
correlation: [[0.9818 0.9709 0.9781 0.9723]
[0.9269 0.9157 0.9108 0.9111]]
ASM: [[0.145 0.1342 0.1405 0.1335]
[0.1089 0.1051 0.1032 0.1027]]

ps.灰度共生矩阵,受图像光照等外部因素影响很大,灰度梯度共生矩阵,效果会好很多,能起到优化作用。用法差别不大,只是加了边缘信息。
2.5:Laws纹理特征
基本原理:
图像的Laws特征是一种基于图像滤波和能量统计的方法,用于描述图像的纹理特征。Laws纹理特征可以用于图像分类、识别、检索等任务中,具有较好的性能。Laws纹理特征的基本思想是将图像分解为不同的小块,然后对每个小块进行一组滤波器的卷积操作,得到一组滤波响应(滤波器可以是多种不同方案组合得到的)。在得到滤波响应后,可以通过计算其能量特征来描述图像的纹理特征。具体地,假设对于一幅图像 I,通过一组滤波器得到的滤波响应为 F i,j ,其中 i,j分别表示滤波器的编号和图像块的编号(这些块可以是 5x5、7x7 等等这一类的方形或者各种由研究人员指定的形状大小的图像子集),则Laws纹理特征可以通过以下公式计算:
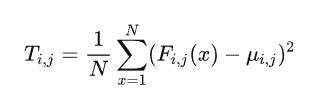
其中, μ i,j 是滤波响应的均值, N 是滤波响应的长度。Laws纹理特征 T 是一个向量,包含了所有图像块和滤波器组合的能量特征。
2.6:局部二值模式(LBP)
图像的局部二值模式(Local Binary Pattern,LBP)是一种基于图像灰度值的局部纹理特征描述子,常用于图像分类、识别和检索等应用中,具有良好的性能和鲁棒性。
基本原理:
对于一幅图像 I 中的每个像素点 x ,可以计算其对应的局部二值模式 LBP(x),表示其周围像素点与中心像素点的灰度值大小关系。具体地,对于一个半径为 r 的圆形邻域,以中心点的灰度值为阈值,将周围的 8 个像素点分别与中心点进行比较,得到一个 8 位二进制数。将这个二进制数转换为十进制数,即得到 x点的局部二值模式 LBP(x)。
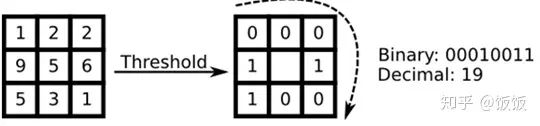
(图片注:然后讲19放入到中心,作为LBP值)

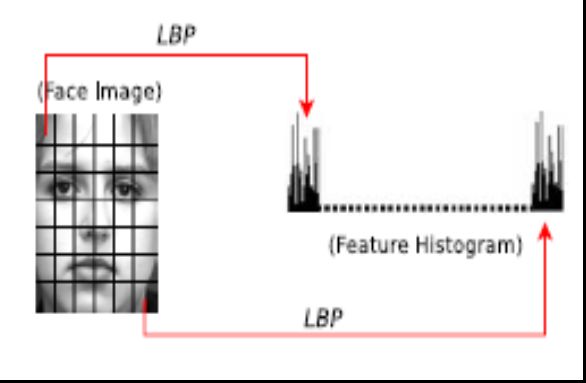
⭐LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
因为,从上面的分析我们可以看出,这个“特征”跟位置信息是紧密相关的。直接对两幅图片提取这种“特征”,并进行判别分析的话,会因为“位置没有对准”而产生很大的误差。后来,研究人员发现,可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成;
例如:一幅100100像素大小的图片,划分为1010=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为1010像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有1010个子区域,也就有了1010个统计直方图,利用这1010个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了;
对LBP特征向量进行提取的步骤:
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;然后便可利用SVM或者其他机器学习算法进行分类了。
改进的LBP
-
圆形可变半径模式(Extended LBP,Circular LBP)
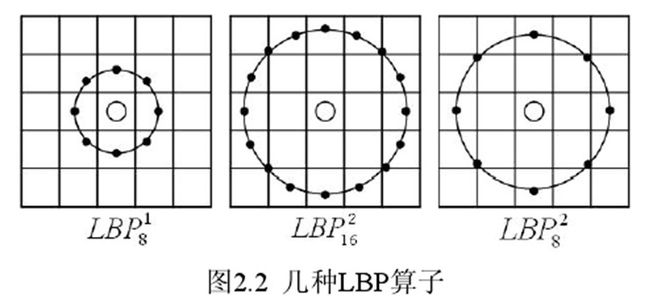
为了满足尺度、灰度和旋转不变性的要求,Ojala 等对 LBP 算子进行了改进,将 3×3 邻域扩展到任意邻域,并用圆形邻域代替了方形邻域。改进算子允许在半径为 R 的圆形邻域内有 P 个采样点,称为扩展 LBP 算子(Extended LBP,Circular LBP)。
-
LBP旋转不变模式
从 LBP 的定义可以看出,LBP 算子是灰度不变的,但却不是旋转不变的。图像的旋转就会得到不同的 LBP值。
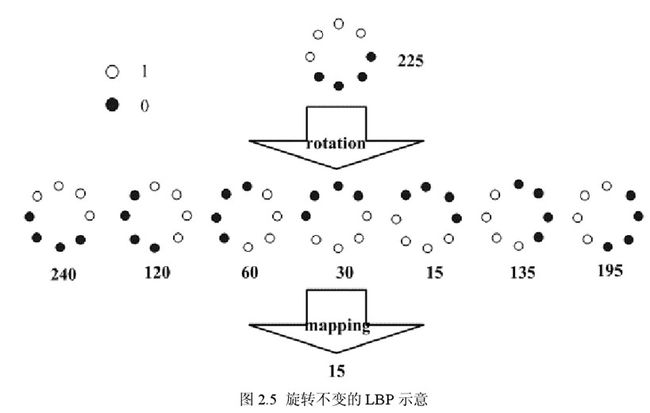
Maenpaa等人又将 LBP算子进行了扩展,提出了具有旋转不变性的 LBP 算子,即不断旋转圆形邻域得到一系列初始定义的 LBP值,取其最小值作为该邻域的 LBP 值。
下图给出了求取旋转不变的 LBP 的过程示意图,图中算子下方的数字表示该算子对应的 LBP值,图中所示的 8 种 LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的 LBP值为 15。也就是说,图中的 8种 LBP 模式对应的旋转不变的 LBP模式都是 00001111。
-
LBP等价模式(Uniform Pattern)
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生P^2种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有220=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。同时,过多的模式种类对于纹理的表达是不利的。例如,将LBP算子用于纹理分类或人脸识别时,常采用LBP模式的统计直方图来表达图像的信息,而较多的模式种类将使得数据量过大,且直方图过于稀疏。因此,需要对原始的LBP模式进行降维,使得数据量减少的情况下能最好的代表图像的信息。
为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类。如00000000(0次跳变),00000111(只含一次从0到1的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)(。
通过这样的改进,二进制模式的种类大大减少,而不会丢失任何信息。模式数量由原来的2^P种减少为 P ( P-1)+2种,其中P表示邻域集内的采样点数。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为58种,这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
OpenCV 例程:
# 14.10 特征描述之 LBP 直方图
def basicLBP(gray):
height, width = gray.shape
dst = np.zeros((height, width), np.uint8)
kernelFlatten = np.array([1, 2, 4, 128, 0, 8, 64, 32, 16]) # 从左上角开始顺时针旋转
for h in range(1, height-1):
for w in range(1, width-1):
LBPFlatten = (gray[h-1:h+2, w-1:w+2] >= gray[h, w]).flatten() # 展平为一维向量, (9,)
dst[h, w] = np.vdot(LBPFlatten, kernelFlatten) # 一维向量的内积
return dst
def calLBPHistogram(imgLBP, nCellX, nCellY): # 计算 LBP 直方图
height, width = gray.shape
# nCellX, nCellY = 4, 4 # 将图像划分为 nCellX*nCellY 个子区域
hCell, wCell = height//nCellY, width//nCellX # 子区域的高度与宽度 (150,120)
LBPHistogram = np.zeros((nCellX*nCellY, 256), np.int)
for j in range(nCellY):
for i in range(nCellX):
cell = imgLBP[j * hCell:(j + 1) * hCell, i * wCell:(i + 1) * wCell].copy() # 子区域 cell LBP
print("{}, Cell({}{}): [{}:{}, {}:{}]".format
(j*nCellX+i+1, j+1, i+1, j*hCell, (j+1)*hCell, i*wCell, (i+1)*wCell))
histCell = cv2.calcHist([cell], [0], None, [256], [0, 256]) # 子区域 LBP 直方图
LBPHistogram[(i+1)*(j+1)-1, :] = histCell.flatten()
print(LBPHistogram.shape)
return LBPHistogram
# 特征描述之 LBP 直方图
img = cv2.imread("4.jpg", flags=1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图像
height, width = gray.shape
nCellX, nCellY = 4, 4 # 将图像划分为 nCellX*nCellY 个子区域
hCell, wCell = height//nCellY, width//nCellX # 子区域的高度与宽度 (150,120)
print("img: h={},w={}, cell: h={},w={}".format(height, width, hCell, wCell))
basicLBP = basicLBP(gray) # 计算 basicLBP 特征算子
# LBPHistogram = calLBPHistogram(basicLBP, nCellX, nCellY) # 计算 LBP 直方图 (16, 256)
fig1 = plt.figure(figsize=(9, 8))
fig1.suptitle("basic LBP")
fig2 = plt.figure(figsize=(9, 8))
fig2.suptitle("LBP histogram")
for j in range(nCellY):
for i in range(nCellX):
cell = basicLBP[j*hCell:(j+1)*hCell, i*wCell:(i+1)*wCell].copy() # 子区域 cell LBP
histCV = cv2.calcHist([cell], [0], None, [256], [0, 256]) # 子区域 cell LBP 直方图
ax1 = fig1.add_subplot(nCellY, nCellX, j * nCellX + i + 1)
ax1.set_xticks([]), ax1.set_yticks([])
ax1.imshow(cell, 'gray') # 绘制子区域 LBP
ax2 = fig2.add_subplot(nCellY,nCellX,j*nCellX+i+1)
ax2.set_xticks([]), ax2.set_yticks([])
ax2.bar(range(256), histCV[:, 0]) # 绘制子区域 LBP 直方图
print("{}, Cell({}{}): [{}:{}, {}:{}]".format
(j * nCellX + i + 1, j + 1, i + 1, j * hCell, (j + 1) * hCell, i * wCell, (i + 1) * wCell))
plt.show()
运行结果
本节主要讲解了计算机视觉特征度量的第一类方法:纹理区域度量;此外还有统计区域度量和基空间变换的方法,将在下几篇进行讲解~
因为博主个人专业能力和知识还在提升中,若文章内容有错误或有失偏颇的地方,还请大家多多指出
本文的部分内容参考和整合自:
[1] Krig S . Computer Vision Metrics[J]. Apress, 2014.
[2] 第十三章 图像特征Vol.1:全局特征与区域特征
[3] 【OpenCV 例程 300篇】
[4] LBP(局部二值模式)特征提取原理
[5] 黄非非,基于 LBP 的人脸识别研究,重庆大学硕士学位论文,2009.5
在此表示感谢!