机器学习特征工程:处理缺失值填充的5大技巧
大家好,本文分享Pandas中缺失值填充的5大技巧:
-
填充具体数值,通常是0
-
填充某个统计值,比如均值、中位数、众数等
-
填充前后项的值
-
基于SimpleImputer类的填充
-
基于KNN算法的填充
数据
import pandas as pd
import numpy as np
df = pd.DataFrame({
"A":list(range(1,9)),
"B":list(range(5,13)),
"C":list(range(9,17))})
df
设置空值
df.iloc[0,2] = np.nan
df.iloc[2,0] = np.nan
df.iloc[3,1] = np.nan
df.iloc[6,1] = np.nan
df.iloc[7,2] = np.nan
df

统计空值个数
# 统计每列下空值的个数
df.isnull().sum()
A 1
B 2
C 2
dtype: int64
df[(df.isnull()).any(axis=1)]

技术提升
文中详细代码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
方法1:填充具体数值
df.fillna(0) # 一般是填充0

df.fillna(33) # 填充其他数值

方法2:填充统计值
df1 = df.copy() # 方便演示,生成副本
df1["A"].mean()
4.714285714285714
(1+2+4+5+6+7+8) / 7
4.714285714285714
# 每列的空值填充各自的均值
for column in df1.columns.tolist():
m = df1[column].mean() # 列均值:mean可以改成max、min、mode等
df1[column] = df1[column].fillna(m) # 填充每个列
df1

方法3:前后项填充
df2 = df.copy() # 生成副本
df2 # 替换前
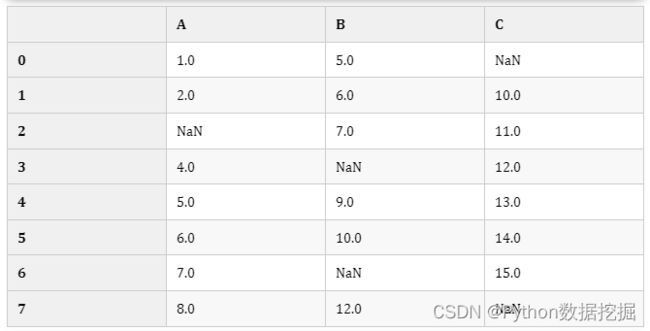
# 1、前项填充 f-forward
df2.fillna(method="ffill",axis=0, inplace=True) # 原地替换
df2

# 2、后项填充 b-back
df2.fillna(method="bfill",axis=0, inplace=True)
df2 # 替换后
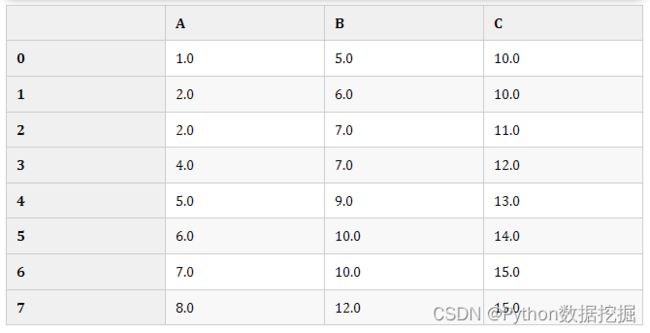
方法4:SimpleImputer类填充(单变量)
sklearn.impute.SimpleImputer (missing_values=nan,
strategy=’mean’,
fill_value=None,
verbose=0,
copy=True)
-
missing_values:int, float, str, (默认)np.nan或是None, 指明缺失值长什么样子
-
strategy:空值填充的方法
-
mean:均值,默认
-
median:中位数
-
most_frequent:众数
-
constant:自定义的值,必须通过fill_value来定义。
-
fill_value:str或数值,默认为Zone。当strategy == “constant"时,fill_value被用来替换所有出现的缺失值(missing_values)。fill_value为Zone,当处理的是数值数据时,缺失值(missing_values)会替换为0,对于字符串或对象数据类型则替换为"missing_value” 这一字符串。
-
verbose:int,(默认)0,控制imputer的冗长。
-
copy:boolean,(默认)True,表示对数据的副本进行处理(原数据不改变),False对数据直接原地修改。
-
add_indicator:boolean,(默认)False,True则会在数据后面加入n列由0和1构成的同样大小的数据,0表示所在位置非缺失值,1表示所在位置为缺失值。
from sklearn.impute import SimpleImputer
# 案例1
df3 = df.copy() # 副本
# 使用impute.SimpleImputer类进行缺失值填充前,将其实例化
df3_mean = SimpleImputer(missing_values=np.nan, strategy='mean') # 均值
df3_mean.fit_transform(df3) # 结果是numpy数组
array([[ 1. , 5. , 12.5 ],
[ 2. , 6. , 10. ],
[ 4.71428571, 7. , 11. ],
[ 4. , 8.16666667, 12. ],
[ 5. , 9. , 13. ],
[ 6. , 10. , 14. ],
[ 7. , 8.16666667, 15. ],
[ 8. , 12. , 12.5 ]])
df3 # 不是原地修改,df3不会改变

# 案例2
df3_mean = SimpleImputer(
missing_values=np.nan,
strategy='median', # 中位数
copy=False # 直接原地修改
)
df3_mean.fit_transform(df3)
array([[ 1. , 5. , 12.5],
[ 2. , 6. , 10. ],
[ 5. , 7. , 11. ],
[ 4. , 8. , 12. ],
[ 5. , 9. , 13. ],
[ 6. , 10. , 14. ],
[ 7. , 8. , 15. ],
[ 8. , 12. , 12.5]])
df3 # df3已经改变
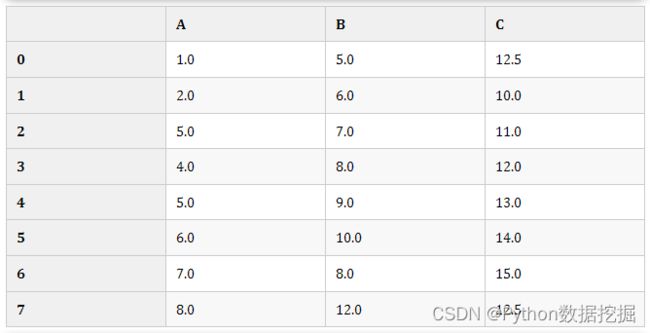
# 案例3:不同的列采取不同策略填充
df4 = df.copy()
#均值
df_mean = SimpleImputer(missing_values=np.nan, strategy='mean',copy=False)
#中位数
df_median = SimpleImputer(missing_values=np.nan, strategy='median',copy=False)
#常数0
df_0 = SimpleImputer(strategy="constant",fill_value=0,copy=False)
#众数
df_most_frequent = SimpleImputer(missing_values=np.nan, strategy='most_frequent',copy=False)
df4["A"] = df_mean.fit_transform(df4["A"].values.reshape(-1,1)) # 均值
df4["B"] = df_median.fit_transform(df4["B"].values.reshape(-1,1)) # 中位数
df4["C"] = df_most_frequent.fit_transform(df4["C"].values.reshape(-1,1)) # 众数
df4 # 原地修改

方法5:基于KNN填充
from sklearn.impute import KNNImputer
df5 = df.copy()
df5 # 填充前

# 最近的3个邻居,使用的是3者的均值
impute = KNNImputer(n_neighbors=3)
impute.fit_transform(df5)
array([[ 1. , 5. , 11. ],
[ 2. , 6. , 10. ],
[ 2.33333333, 7. , 11. ],
[ 4. , 7.33333333, 12. ],
[ 5. , 9. , 13. ],
[ 6. , 10. , 14. ],
[ 7. , 10.33333333, 15. ],
[ 8. , 12. , 14. ]])
填充值如何计算得来:
print((1 + 2 + 4) / 3)
print((6 + 7 + 9) / 3)
print((9 + 10 + 12) / 3)
print((10 + 11 + 12) / 3)
print((13 + 14 + 15) / 3)
2.3333333333333335
7.333333333333333
10.333333333333334
11.0
14.0