一、响应式编程基本介绍
基本介绍
背景:响应式编程是一种新的编程技术,其目的是构建响应式系统。对于响应式系统而言,任何时候都需要确保具备即时响应性,这是大多数日常业务场景所需要的,但却是一项非常复杂而有挑战性的任务。
说明:所谓的“响应式”并不是一件颠覆式的事情,而只是一种新型的编程模式。它不局限于某种开发框架,也并非解决分布式环境下所有问题的银弹,而是随着技术的发展自然而然诞生的一种技术体系。
原因
传统 Web 请求
在服务 A(服务消费者)调用服务 B(服务提供者)场景中,当服务 A 向服务 B 发送 HTTP 请求时,线程 A 只有在发起请求和响应结果的一小部分时间内在有效使用 CPU,而更多的时间则只是在 阻塞式 地等待来自服务 B 中线程的处理结果。显然,整个过程的 CPU 利用效率是很低的,很多时间线程被浪费在了 I/O 阻塞上,无法执行其他的处理过程,如下图所示:

同理,在一个服务内部(以经典的 Web 分层服务为例),也存在着这种阻塞的情况, Controller 层访问 Service 层,Service 层访问 Repository 数据层,数据层访问数据库,然后再依次返回。在这个过程中,每一步的操作过程都存在着前面描述的线程等待问题。也就是说,整个技术栈中的每一个环节都可能是同步阻塞的。
处理方式
针对上面提到的阻塞问题,在 Java 中,为了实现异步非阻塞,常用的方式有两种:回调和 Future,但是这两种方式,都存在一些局限性。
- 回调
回调体现的是一种双向的调用方式,实现了服务间的解耦,服务调用方会提供一个 callback 回调方法。在这个 callback 回调方法中,回调的执行是由任务的结果(服务提供方)来触发的,所以我们就可以异步来执行某项任务,从而使得调用链路不发生任何的阻塞。
回调的最大问题是复杂性,一旦在执行流程中包含了多层的异步执行和回调,那么就会形成一种嵌套结构,给代码的开发和调试带来很大的挑战。所以回调很难大规模地组合起来使用,因为很快就会导致代码难以理解和维护,从而造成所谓的“回调地狱”问题。
- Future
Future 模式简单理解为这样一种场景:我们有一个需要处理的任务,然后把这个任务提交到 Future,Future 就会在一定时间内完成这个任务,而在这段时间内我们可以去做其他事情。
但从本质上讲,Future 以及由 Future 所衍生出来的 CompletableFuture 等各种优化方案就是一种多线程技术。多线程假设一些线程可以共享一个 CPU,而 CPU 时间能在多个线程之间共享,这一点就引入了“上下文切换”的概念。
如果想要恢复线程,就需要涉及加载和保存寄存器等一系列计算密集型的操作。因此,大量线程之间的相互协作同样会导致资源利用效率低下。
响应式编程实现方法
观察者模式和发布-订阅模式
了解响应式编程技术之前,我们先回顾一下两种设计模式:观察者模式和发布-订阅模式。
-
观察者模式和发布
观察者模式拥有一个主题(Subject),其中包含其依赖者列表,这些依赖者被称为观察者(Observer)。主题可以通过一定的机制将任何状态变化通知到观察者。 -
发布-订阅模式
发布-订阅模式,可以认为是对观察者模式的一种改进。因为观察者模式,容易和场景绑定(如:一个场景一个观察者模式),而发布-订阅模式具有更强的通用性。
在这一模式中,发布者和订阅者之间可以没有直接的交互,而是通过发送事件到事件处理平台的方式来完成整合,如下图所示:
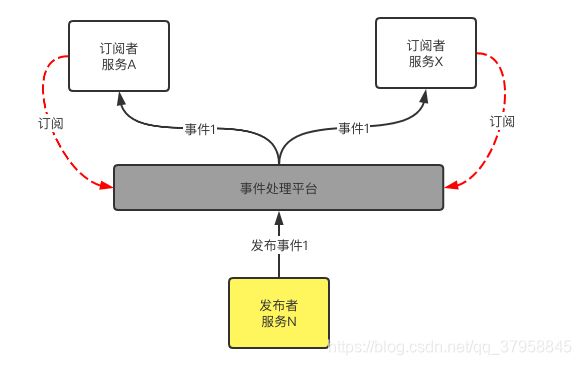
了解了这两种模式,我们再来看有什么方式可以处理前面提到的阻塞问题?
如果将获取数据这件事情,通过发布订阅来实现,是不是就可以处理阻塞问题?在一个服务的内部,从 Web 服务层到数据访问层,再到数据库的整个调用链路,同样可以采用发布-订阅模式进行重构。这时候,我们希望当数据库中的数据一有变化(事件)就通知上游组件(通知机制),而不是上游组件通过主动拉取数据的方式来获取数据(阻塞)。
调用方不再阻塞等待,而是订阅事件,当事件发生变化的时候,调用方再来处理。
数据流与响应式
基于上面的实现,那么在一个系统中,就会存在很多很多的 事件,每一种事件会基于用户的操作或者系统自身的行为而被触发,并形成了一个事件的集合。针对事件的集合,我们可以把它们看成是一串串联起来的数据流,而系统的响应能力就体现在对这些数据流的即时响应过程上。
数据流对于技术栈而言是一个全流程的概念。也就是说,无论是从底层数据库,向上到达服务层,最后到 Web 服务层,抑或是在这个流程中所包含的任意中间层组件,整个数据传递链路都应该是采用事件驱动的方式来进行运作的。
这样,我们就可以不采用传统的同步调用方式来处理数据,而是由处于数据库上游的各层组件自动来执行事件。这就是响应式编程的核心特点。
相较传统开发所普遍采用的“拉”模式,在响应式编程下,基于事件的触发和订阅机制,这就形成了一种类似“推”的工作方式。这种工作方式的优势就在于,生成事件和消费事件的过程是异步执行的,所以线程的生命周期都很短,也就意味着资源之间的竞争关系较少,服务器的响应能力也就越高。
背压机制
基本概念
(1)流
所谓的流就是由生产者生产并由一个或多个消费者消费的元素序列。这种生产者/消费者模型也可以被称为发布者/订阅者模型。
(2)流的处理模型
流的处理,存在两种基本的实现机制:一种就是传统开发模式下的“拉”模式,即消费者主动从生产者拉取元素;而另一种就是上面提到的“推”模式。
在“推”模式下,生产者将元素推送给消费者。相较于“拉”模式,该模式下的数据处理的资源利用率更好。但是,这也引入了流量控制的问题,即如果数据的生产者和消费者处理数据的速度是不一致的,我们应该如何确保系统的稳定性呢?
流量控制
(1)生产者生产数据的速率小于消费者的场景
在这种情况下,因为消费者消费数据没有任何压力,也就不需要进行流量的控制。
(2)生产者生产数据的速率大于消费者消费数据的场景
这种情况比较复杂,因为消费者可能因为无法处理过多的数据而发生崩溃。针对这种情况的一种常见解决方案是在生产者和消费者之间添加一种类似于消息队列的机制。我们知道队列具有存储并转发的功能,所以可以由它来进行一定的流量控制,效果如下图所示。
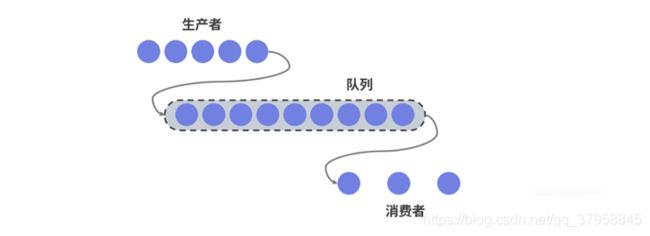
那么流量控制问题的关键就转变为了如何设计一种合适的队列?通常,我们可以选择三种不同类型的队列来分别支持不同的功能特性。
-
无界队列(Unbounded Queue)
这种队列原则上拥有无限大小的容量,可以存放所有生产者所生产的消息;同样,因为无界,但系统资源确是有限的,容易出现内存耗尽情况,导致系统崩溃。 -
有界丢弃队列
与无界队列相对的,更合适的方案是选择一种有界队列。它避免内存溢出的情况,但可能会出现消息丢失的情况,因此,它比较适合用于允许丢消息的业务场景,但在消息重要性很高的场景显然不可能采取这种队列。 -
有界阻塞队列
如果需要确保消息不丢失,则需要引入有界阻塞队列。在这种队列中,我们会在队列消息数量达到上限后阻塞生产者,而不是直接丢弃消息。显然,这种阻塞行为是不可能实现异步操作的,即:有界阻塞队列都不是我们想要的解决方案。
背压机制
通过对流量控制的分析,可以明确,纯“推”模式下的数据流量会有很多不可控制的因素,并不能直接应用,而是需要在“推”模式和“拉”模式之间考虑一定的平衡性,从而优雅地实现流量控制。这就需要引出响应式系统中非常重要的一个概念——背压机制(Backpressure)。
什么是背压?简单来说就是下游能够向上游反馈流量请求的机制。我们知道,如果消费者消费数据的速度赶不上生产者生产数据的速度时,它就会持续消耗系统的资源,直到这些资源被消耗殆尽。
这个时候,就需要有一种机制使得消费者可以根据自身当前的处理能力通知生产者来调整生产数据的速度,这种机制就是背压。采用背压机制,消费者会根据自身的处理能力来请求数据,而生产者也会根据消费者的能力来生产数据,从而在两者之间达成一种动态的平衡,确保系统的即时响应性。
实现
为了实现这种动态的平衡,出现了一套响应式流规范,而针对流量控制的解决方案以及背压机制都包含在响应式流规范中,其中包含了响应式编程的各个核心组件。
响应式流规范
核心接口
在 Java 的世界中,响应式流规范只定义了四个核心接口,即 Publisher、Subscriber、Subscription 和 Processor
- Publisher
Publisher 代表的就是一种可以生产无限数据的发布者,该接口定义如下所示:
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
可以看到,Publisher 根据收到的请求向当前订阅者 Subscriber 发送元素。
- Subscriber
Subscriber 代表的是一种可以从发布者那里订阅并接收元素的订阅者。Subscriber 接口定义如下所示:
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
Subscriber 接口包含了一组方法,这些方法构成了数据流请求和处理的基本流程。
onSubscribe() 方法:
从命名上看就是一个回调方法,当发布者的 subscribe() 方法被调用时就会触发这个回调。而在该方法中有一个参数 Subscription,可以把这个 Subscription 看作是一种用于订阅的上下文对象。Subscription 对象中包含了这次回调中订阅者想要向发布者请求的数据个数。
onNext() 方法:
当订阅关系已经建立,那么发布者就可以调用订阅者的 onNext() 方法向订阅者发送一个数据。这个过程是持续不断的,直到所发送的数据已经达到 Subscription 对象中所请求的数据个数。
onComplete() 方法:
当所发送的数据已经达到 Subscription 对象中所请求的数据个数时,这时候 onComplete() 方法就会被触发,代表这个数据流已经全部发送结束。
onError() 方法:
一旦在在数据流发送过程中出现了异常,那么就会触发 onError() 方法,我们可以通过这个方法捕获到具体的异常信息进行处理,而数据流也就自动终止了。
- Subscription
Subscription 代表的就是一种订阅上下文对象,它在订阅者和发布者之间进行传输,从而在两者之间形成一种契约关系。Subscription 接口定义如下所示:
public interface Subscription {
public void request(long n);
public void cancel();
}
这里的 request() 方法用于请求 n 个元素,订阅者可以通过不断调用该方法来向发布者请求数据;而 cancel() 方法显然是用来取消这次订阅。请注意,Subscription 对象是确保生产者和消费者针对数据处理速度达成一种动态平衡的基础,也是流量控制中实现背压机制的关键所在。
Publisher、Subscriber 和 Subscription 接口是响应式编程的核心组件,响应式流规范也只包含了这些接口,因此是一个非常抽象且精简的接口规范。响应式流规范实际上提供了一种“推-拉”结合的混合数据流模型。
当然,响应式流规范非常灵活,还可以提供独立的“推”模型和“拉”模型。如果为了实现纯“推”模型,我们可以考虑一次请求足够多的元素;而对于纯“拉”模型,相当于就是在每次调用 Subscriber 的 onNext() 方法时只请求一个新元素。