05 高性能网络设计专栏-网络原理
以下是在零声教育的听课记录。
如有侵权,请联系我删除。
链接:零声教育官网
还有很大一部是是借鉴了这个博客的总结:CSDN博主「cheems~」的原创文章
目录
- 1. websocket协议与服务器实现
-
- 1.1 websocket介绍
-
- 1.1.1 websocket是什么
- 1.1.2 websocket的优点
- 1.1.3 websocket应用场景
- 1.2 websocket协议剖析
-
- 1.2.1 握手协议
- 1.2.2 传输协议
- 1.3 websocket四问
-
- 1.3.1 websocket协议格式
- 1.3.2 websocket如何验证客户端合法
- 1.3.3 明文与密文如何传输
- 1.3.4 websocket如何断开
- 1.4 基于reactor模型的websocket服务器
- 1.5 程序运行测试结果
- 1.6 完整代码
- 2. redis,memcached,nginx网络组件
-
- 2.1 网络编程需要关注的问题
-
- 2.1.1.连接的建立
- 2.1.2.连接的断开
- 2.1.3.消息到达
- 2.1.4.消息发送完毕
- 2.2 网络 IO 职责
-
- 2.2.1 检测 IO
- 2.2.2 操作 IO
- 2.2.3 阻塞 IO 和 非阻塞 IO
- 2.2.4 IO 多路复用
- 2.3 epoll
-
- 2.3.1 结构以及接口
- 2.3.2 epoll 编程
-
- 连接建立
- 连接断开
- 数据到达
- 数据发送完毕
- 2.4 reactor常见疑问
-
- 2.4.1 epoll惊群
- 2.4.2 水平触发和边沿触发
- 2.4.3 reactor为什么要搭配非阻塞IO?
- 2.4.4 reactor优点:
- 2.5 redis,ngnix,memcached 中reactor具体使用
-
- 2.5.1 单reactor——redis
- 2.5.2 多 reactor (多线程)——memcached
- 2.5.3 多 reactor (多进程)——nginx
- 2.6 总结
- 3. Posix API与网络协议栈
-
- 3.1 Posix API 有哪些
-
- 3.2.1 socket
- 3.3.2 bind
- 3.2 三次握手建立连接的过程
-
- 3.2.1 connect
- 3.2.2 listen
- 3.2.3 accept
- 3.3 数据传输 发送与接收
-
- 3.3.1 send & recv
- 3.3.2 滑动窗口
- 3.3.3 粘包 & 分包
- 3.3.4 延迟确认(延迟ACK)
- 3.3.5 udp场景
- 3.4 四次挥手 断开连接的过程
-
- 3.4.1 正常情况
- 3.4.2 特殊情况
- 3.4.3 回收fd和tcb
- 3.5 一些面试问题
- 3.6 面试中协议栈常问的点?
- 4. UDP的可靠传输协议QUIC
-
- 4.1 UDP与 TCP的区别
- 4.2 TCP和 UDP 格式对比
-
- 4.2.1 ARQ(自动重传请求) 协议
- 4.2.2 什么是滑动窗口
- 4.3 UDP如何可靠, KCP 协议在哪些方面有优势
-
- 4.3.1 名词说明
- 4.4 使用方式
-
- 4.4.1 kcp 源码流程图
- 4.5 QUIC协议
-
- 4.5.1 QUIC的特点
- 4.5.2 连接建立低时延 典型 TCP+TLS 连接
- 4.5.3 连接建立低时延 QUIC 首次连接
- 4.5.3 连接建立低时延 QUIC 再次连接
1. websocket协议与服务器实现
1.1 websocket介绍
1.1.1 websocket是什么
**websocket是基于tcp协议的应用层协议,**也就是建立在tcp协议之上的自定义协议。这个协议比http协议更加的简单,因为websocket只对协议的格式做要求,只要符合数据格式就可以使用。
websocket一般用来服务器主动推送消息给客户端,反观HTTP,HTTP是请求响应的模式,客户端来一个请求,服务器响应一个请求,服务器无法主动发送数据给客户端;并且使用websocket,客户端和服务器只需要一次“握手”,两者之间就成功建立了长连接,可以双向传输数据。
现在有很多网站都有推送功能,比如现在有个人关注了我的CSDN号,或者给我点了赞,只要我这个浏览器在CSDN界面,就能立刻收到提醒,这就是推送功能,一般都是按照时间间隔轮询;如果我们使用HTTP去做的话,浏览器需要不断的向服务器发请求,而HTTP请求头又有很多无用数据,显而易见的是浪费带宽等资源。
而websocket不一样,websocket的开销很小,并且主要是由服务器主动推送消息给客户端,不再需要轮询了,所以实时性很高。
1.1.2 websocket的优点
- websocket协议简单
- 可以基于websocket自定义协议
- websocket一般用来服务器主动推送消息给客户端(实时性很高)
- 客户端和服务器建立连接只需要一次“握手”就可以保持长连接(开销很小)
1.1.3 websocket应用场景
举个登陆CSDN的例子:
1. 用户选择微信扫码登陆,浏览器发送HTTP请求给CSDN服务器
2. 服务器返回一个二维码给浏览器
3. 用户通过微信扫码登陆
4. 微信扫码成功,将消息传给微信服务器进行处理
5. 微信服务器触发回调给CSDN服务器发一个通知
6. CSDN服务器给浏览器发送一个websocket通知浏览器登陆成功
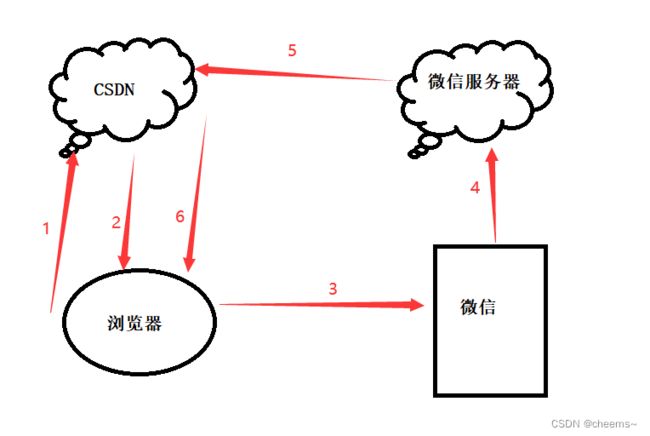
1.比如我网页登入了QQ,有人给我发信息马上就会有消息提示 -滴滴滴-
1.2 websocket协议剖析
1.2.1 握手协议
websocket握手是HTTP的GET请求的升级版,现在假设客户端连接服务器,服务器返回一次握手信息,连接即可建立,具体步骤如下:
- 客户端使用
ws://192.168.109.100:8081连接服务器,实际上是采用HTTP的GET请求来进行握手
# http协议
GET /x/space/wbi/acc/info?mid=****&token=&platform=web&w_rid=****&wts=**** HTTP/2
Host: api.bilibili.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Referer: https://space.bilibili.com/379746059/favlist
Origin: https://space.bilibili.com
Connection: keep-alive
Cookie: ********************************
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-site
TE: trailers
# websocket协议(这一部分是为了兼容http)
GET / HTTP/1.1
# 对端主机
Host: 192.168.109.100:8081
# 协议书升级
Connection: Upgrade
Pragma: no-cache
Cache-Control: no-cache
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36
# 升级的websocket
Upgrade: websocket
Origin: http://www.websocket-test.com
# websocket版本号
Sec-WebSocket-Version: 13
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
# 客户端随机生成的一个16字节随机数,作为简单的认证标识
Sec-WebSocket-Key: 9jEz8msH1BBH9H43adEMZQ==
Sec-WebSocket-Extensions: permessage-deflate; client_max_window_bits
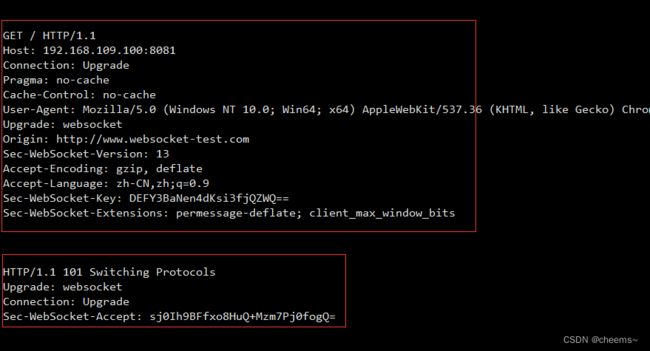
- 服务器接收到对应的GET请求后,发现协议需要升级,返回响应,其中需要注意的是
Sec-WebSocket-Accept
# 101 表示切换协议
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: 9oFmMWgFISY8DBlo5xq1L1rc0+0=
Sec-WebSocket-Accept验证
Sec-WebSocket-Accept需要做3次计算得出,主要是为了验证客户端合法性。客户端收到服务器发来的响应后,同样会进行下面的操作,然后将收到的结果与自身算的结果进行对比,如果一样则说明合法,握手成功(WebSocket建立成功)。后续数据传输不再使用HTTP协议,而是使用websocket自定义的一套协议规范。
# GUID是websocket规定好的全局唯一的不变的字符串
#define GUID "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"
# 将客户端发来的GET请求中的Sec-WebSocket字段的字符串与全局唯一的GUID拼接
1. key=(Sec-WebSocket-Key)+GUID //即9jEz8msH1BBH9H43adEMZQ==258EAFA5-E914-47DA-95CA-C5AB0DC85B11
# 对这个新字符串做SHA1运算(内部就是个哈希运算),得到20B长的字符串sha_key
2. sha_key=SHA1(key)
# 对sha_key做base64_encode编码,就能得到Sec-WebSocket-Accept了
3. sec_key=base64_encode(sha_key)
1.2.2 传输协议
 这个协议分成两部分,一部分是有填充的字体那是携带的数据信息,另一部分是协议头的信息。其中紫色和蓝色的部分(密文传输和扩展长度)是根据箭头指向的决定。
这个协议分成两部分,一部分是有填充的字体那是携带的数据信息,另一部分是协议头的信息。其中紫色和蓝色的部分(密文传输和扩展长度)是根据箭头指向的决定。
参数介绍
- FIN:1bit,当FIN值为0的时候代表,消息还没完整,只是其中的一个数据包;当值为1的时候代表这段消息已经完全发送了。
- RSV 1 / 2 / 3:1bit,这个默认为 0 ,如果一定要启用,就得和服务端协商好,才具有意义。
- opcode:4bit,该数据包类型。
0 代表数据不完整,这只是其中的一个,不是最后的那个数据包。(Continuation Frame)
1 代表数据包内容的类型为 文本类型(Text Frame)
2 代表数据内容类型为 二进制类型 (Binary Frame)
8 代表连接断开 (Connection Close Frame)
9 和 10 是心跳检测,如果服务端发出 Ping Frame 那么客户端就得发回 Pong Frame ,如果服务端接受不到 Pong Frame 就代表客户端可能已经下线了。
0 - 15 中现在除了这 6 个,都为保留帧。
- MASK: 1bit,是否开启掩码。1开0关。如果开启了,下面的Masking-key就有意义了,一般是发送消息的数据包会开启,返回响应的数据包不开启,并且也没有Masking-key这4个bit。
// 如果Mask为1,则Payload Data 就需要通过 Mask 掩码解密(这里指接收消息)
void umask(char *payload, int length, char *mask_key) {
int i = 0;
for (i = 0; i < length; i++) {
payload[i] ^= mask_key[i % 4];
}
}
- Payload len:7bit,内容数据(Payload Data)的长度
如果Payload len<126,则data len=Payload len
如果Payload len=126,则启用Extended payload length,多加了16bit,并且data len=Extended payload length
如果Payload len=127,则启用Extended payload length和Extended payload length continued,多加了16+48bit,并且data len=Extended payload length continued
- Masking-key:32bit,掩码数据,如果 Mask 为 1 就启用,否则不启用
- Payload Data:数据 0-127Byte,由上面3个如果决定大小
协议中前面2Byte固定存在,后面的 Extended payload length 这2Byte和 Extended payload length continued 这6Byte存不存在由 Payload len决定。
如果MASK=1,则后面有4Byte的Masking-key,则MASK=0则没有这4Byte,再后面就是Payload Data了,多长就是前面Payload len的三种情况了。
1.3 websocket四问
1.3.1 websocket协议格式
websocket协议格式一共有两种:
- 一种是握手的GET请求
- 一种是数据传输协议格式
1.3.2 websocket如何验证客户端合法
Sec-WebSocket-Accept需要做3次计算得出,主要是为了验证客户端合法性。客户端收到服务器发来的响应后,同样会进行下面的操作,然后将收到的结果与自身算的结果进行对比,如果一样则说明合法,握手成功(WebSocket建立成功)。
# GUID是websocket规定好的全局唯一的不变的字符串
#define GUID "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"
# 将客户端发来的GET请求中的Sec-WebSocket字段的字符串与全局唯一的GUID拼接
1. key=Sec-WebSocket-Key+GUID
# 对这个新字符串做SHA1运算,得到20B长的字符串sha_key
2. sha_key=SHA1(key)
# 对sha_key做base64_encode编码,就能得到Sec-WebSocket-Accept了
3. sec_key=base64_encode(sha_key)
1.3.3 明文与密文如何传输
使用参数 MASK: 1bit,是否开启掩码。1开0关。
- 如果是要发送密文,首先将MASK置1,然后将明文数据与Masking-key进行异或操作
- 如果是要解码成明文,将密文数据与Masking-key进行异或操作
- 如果是要发送明文,MASK置0即可
for (i = 0; i < length; i++) {
payload[i] ^= mask_key[i % 4];
}
1.3.4 websocket如何断开
我们知道websocket是建立在TCP之上的,直接close不就好了吗,为什么还要规定opcode=8的时候代表断开连接呢?
客户端在调用close之前,先发送一个断开连接的包给服务器;服务器接收到这个包后,把对应的fd连接数据(相关联的用户数据,业务数据)做清空,然后再调用close断开TCP,这样就是优雅的断开连接,close流畅,不会出现大量的close_wait的情况
1.4 基于reactor模型的websocket服务器
握手代码介绍
websocket有3个状态,握手,传输与关闭。所以我们定义一个状态机。
在读完数据后,将数据交由 websocket_request(ev);管理;其会判断当前连接处于哪个状态,第一次就是握手状态;
handshake(ev);对GET请求解析出Sec-WebSocket-Key,然后计算Sec-WebSocket-Accept,组装响应。
这里就对着上面介绍的握手协议写代码即可
struct ntyevent {
//...略
int state_machine;
};
//state_machine
enum {
WS_HANDSHAKE = 0,
WS_TRANSMISSION = 1,
WS_END = 2
};
int websocket_request(struct ntyevent *ev) {
if (ev->state_machine == WS_HANDSHAKE) {
handshake(ev);
ev->state_machine = WS_TRANSMISSION;
}
else if (ev->state_machine == WS_TRANSMISSION) {
transmission(ev);
}
else {
}
}
int recv_cb(int fd, int events, void *arg) {
struct ntyreactor *reactor = (struct ntyreactor *) arg;
struct ntyevent *ev = ntyreactor_find_event_idx(reactor, fd);
memset(ev->buffer, 0, BUFFER_LENGTH);
#if 0
long len = recv(fd, ev->buffer, BUFFER_LENGTH, 0); //
#elif 1
int len = 0;
int n = 0;
while (1) {
n = recv(fd, ev->buffer + len, BUFFER_LENGTH - len, 0);
printf("[recv data len = %d]\n", n);
if (n != -1) {
len += n;
}
else {
break;
}
}
#endif
nty_event_del(reactor->epfd, ev);
printf("[recv buffer total len=%d]\n", len);
printf("buffer:[%s]\n", ev->buffer);
if (len > 0) {
ev->length = len;
ev->buffer[len] = '\0';
websocket_request(ev);
nty_event_set(ev, fd, send_cb, reactor);
nty_event_add(reactor->epfd, EPOLLOUT, ev);
}
else if (len == 0) {
close(ev->fd);
}
else {
close(ev->fd);
}
return len;
}
int base64_encode(char *in_str, int in_len, char *out_str) {
BIO *b64, *bio;
BUF_MEM *bptr = NULL;
size_t size = 0;
if (in_str == NULL || out_str == NULL)
return -1;
b64 = BIO_new(BIO_f_base64());
bio = BIO_new(BIO_s_mem());
bio = BIO_push(b64, bio);
BIO_write(bio, in_str, in_len);
BIO_flush(bio);
BIO_get_mem_ptr(bio, &bptr);
memcpy(out_str, bptr->data, bptr->length);
out_str[bptr->length - 1] = '\0';
size = bptr->length;
BIO_free_all(bio);
return size;
}
int readline(char *all_buffer, int idx, char *line_buffer) {
int len = strlen(all_buffer);
for (; idx < len; idx++) {
if (all_buffer[idx] == '\r' && all_buffer[idx + 1] == '\n') {
return idx + 2;
}
else {
*(line_buffer++) = all_buffer[idx];
}
}
return -1;
}
int handshake(struct ntyevent *ev) {
char line_buffer[1024] = {0};
char sha_key[32] = {0};//实际只需20B
char sec_key[32] = {0};//实际只需28B
int idx = 0;
//找到Sec-WebSocket-Key这一行
while (!strstr(line_buffer, "Sec-WebSocket-Key")) {
memset(line_buffer, 0, 1024);
idx = readline(ev->buffer, idx, line_buffer);
if (idx == -1)return -1;
}
//1. key=KEY+GUID
//2. sha_key=SHA1(key)
//3. sec_key=base64_encode(sha_key)
strcpy(line_buffer, line_buffer + strlen("Sec-WebSocket-Key: "));
//1. key=KEY+GUID
strcat(line_buffer, GUID);
//2.sha_key = SHA1(key)
SHA1(line_buffer, strlen(line_buffer), sha_key);
//3. sec_key=base64_encode(sha_key)
base64_encode(sha_key, strlen(sha_key), sec_key);
//set head
memset(ev->buffer, 0, BUFFER_LENGTH);
ev->length = sprintf(ev->buffer, "HTTP/1.1 101 Switching Protocols\r\n"
"Upgrade: websocket\r\n"
"Connection: Upgrade\r\n"
"Sec-WebSocket-Accept: %s\r\n\r\n", sec_key);
printf("[handshake response]\n%s\n", ev->buffer);
return 0;
}
传输代码介绍
transmission函数会调用decode_packet对数据包进行解析,将有效数据长度和数据读取出来。
之后再调用encode_packet对数据包进行封装回发回去(这里做的是echo)。
这里就对着上面介绍的传输协议写代码即可
//大端
typedef struct _ws_ophdr {
unsigned char opcode: 4,
rsv3: 1,
rsv2: 1,
rsv1: 1,
fin: 1;
unsigned char payload_len: 7,
mask: 1;
} ws_ophdr;
typedef struct _ws_ophdr126 {
unsigned short payload_len;
char mask_key[4];
} ws_ophdr126;
typedef struct _ws_ophdr127 {
long long payload_len;
char mask_key[4];
} ws_ophdr127;
void umask(char *payload, int length, char *mask_key) {
int i = 0;
for (i = 0; i < length; i++) {
payload[i] ^= mask_key[i % 4];
}
}
char *decode_packet(struct ntyevent *ev, int *real_len, int *virtual_len) {
ws_ophdr *hdr = (ws_ophdr *) ev->buffer;
printf("decode_packet fin:%d rsv1:%d rsv2:%d rsv3:%d opcode:%d mark:%d\n",
hdr->fin,
hdr->rsv1,
hdr->rsv2,
hdr->rsv3,
hdr->opcode,
hdr->mask);
char *payload = NULL;
*virtual_len = hdr->payload_len;
if (hdr->opcode == 8) {
ev->state_machine = WS_END;
close(ev->fd);
return NULL;
}
if (hdr->payload_len < 126) {
payload = ev->buffer + sizeof(ws_ophdr) + 4; // 6 payload length < 126
if (hdr->mask) {
umask(payload, hdr->payload_len, ev->buffer + 2);
}
*real_len = hdr->payload_len;
}
else if (hdr->payload_len == 126) {
payload = ev->buffer + sizeof(ws_ophdr) + sizeof(ws_ophdr126);
ws_ophdr126 *hdr126 = (ws_ophdr126 *) (ev->buffer + sizeof(ws_ophdr));
hdr126->payload_len = ntohs(hdr126->payload_len);
if (hdr->mask) {
umask(payload, hdr126->payload_len, hdr126->mask_key);
}
*real_len = hdr126->payload_len;
}
else if (hdr->payload_len == 127) {
payload = ev->buffer + sizeof(ws_ophdr) + sizeof(ws_ophdr127);
ws_ophdr127 *hdr127 = (ws_ophdr127 *) (ev->buffer + sizeof(ws_ophdr));
if (hdr->mask) {
umask(payload, hdr127->payload_len, hdr127->mask_key);
}
*real_len = hdr127->payload_len;
}
printf("virtual len=%d real_len=%d\n", hdr->payload_len, *real_len);
return payload;
}
int encode_packet(struct ntyevent *ev, int real_len, int virtual_len, char *buf) {
ws_ophdr head = {0};
head.fin = 1;
head.opcode = 1;
head.payload_len = virtual_len;
memcpy(ev->buffer, &head, sizeof(ws_ophdr));
int head_offset = 0;
if (virtual_len < 126) {
head.payload_len = real_len;
head_offset = sizeof(ws_ophdr);
}
else if (virtual_len == 126) {
ws_ophdr126 hdr126 = {0};
hdr126.payload_len = htons(real_len);
memcpy(ev->buffer + sizeof(ws_ophdr), &hdr126, sizeof(unsigned short));//返回不需要mask,中间去掉4B
head_offset = sizeof(ws_ophdr) + sizeof(unsigned short);
}
else if (virtual_len == 127) {
ws_ophdr127 hdr127 = {0};
hdr127.payload_len = real_len;
memcpy(ev->buffer + sizeof(ws_ophdr), &hdr127, sizeof(long long));//返回不需要mask,中间去掉4B
head_offset = sizeof(ws_ophdr) + sizeof(long long);
}
printf("encode_packet fin:%d rsv1:%d rsv2:%d rsv3:%d opcode:%d mark:%d \n",
head.fin,
head.rsv1,
head.rsv2,
head.rsv3,
head.opcode,
head.mask);
memcpy(ev->buffer + head_offset, buf, real_len);
return head_offset + real_len;//头+payload
}
int transmission(struct ntyevent *ev) {
char *payload_buffer = NULL;
int real_len = 0, virtual_len;
payload_buffer = decode_packet(ev, &real_len, &virtual_len);
printf("real_len=[%d] , buf=[%s]\n", real_len, payload_buffer);
ev->length = encode_packet(ev, real_len, virtual_len, payload_buffer);
}
1.5 程序运行测试结果
我自己比较懒,没去做测试
1.6 完整代码
#include 2. redis,memcached,nginx网络组件
2.1 网络编程需要关注的问题
这里主要以TCP连接实现server为例,主要介绍网络编程中需要关注的问题,以及在每个状态下,io函数的作用。下面也主要从以下四个问题讲述
1、连接建立
2、连接断开
3、消息到达
4、消息发送
2.1.1.连接的建立
连接的建立分为两种:服务端处理接收客户端的连接,服务端作为客户端连接第三方服务;
主动连接就是server作为客户端调用connect函数去连接数据库获取数据;
被动连接就是被动接受处理客户端的链接请求**。
主动连接: 当server调用connect函数之后,此时就会开始TCP三次握手,因为设置了fd是非阻塞,此时connect返回值是-1,errno是EINPROGRESS,表示套接字为非阻塞套接字,且连接请求没有立即完成。此时TCP正在进行连接。
我们需要通过epoll去注册读事件就可以判断连接是否可以建立成功了,建立成功后,connect返回-1,errno为EISCONN表示已经连接套接字了。
所以通过这里我们可以看出我们可以通过判断设置的errno来判断io是否建立连接。
被动连接:发生之前,server需要进行socket、bind、listen操作,并将listenfd放到epoll树上注册读事件,此时就等待客户端连接了。当连接来临时,server端需要等待三次握手结束后accept返回值才不为-1,此时accept返回的值就是通信的fd。
// 4.接收客户端连接
struct sockaddr_in clientInfo;
socklen_t len=sizeof(clientInfo);
int cfd = accept(lfd,(struct sockaddr *) &clientInfo,&len); // communication file description
if(cfd==-1){ perror("accept"); exit(-1);}
// (请求连接)举例为非阻塞io,阻塞io成功直接返回0;
int connectfd = socket(AF_INET, SOCK_STREAM, 0);
int ret = connect(connectfd, (struct sockaddr *)&addr, sizeof(addr));
// ret == -1 && errno == EINPROGRESS 正在建立连接
// ret == -1 && errno = EISCONN 连接建立成功
clientfd == -1 && errno == EWOULDBLOCK(全链接队列没有数据)
在linux中 listen(fd,listenblock);中的listenblock设置的是全链接队列的大小
mac中listenblock设置的是全链接队列和半链接队列的和
2.1.2.连接的断开
分为两种:主动断开和被动断开;
主动断开:
当server端调用shutdown函数时会关闭读端或写端,那对应就会关闭客户端的写端或读端。比如server端shutdown掉读端,那客户端的写端就会被关闭,也就是客户端无法将数据发送到server端了,但是服务端依旧可以将数据发送给客户端,因为TCP通信是全双工的,关闭了读端是不会影响到另一端的。还有就是调用close,此时是全部关闭,既不能读也不能写。
被动断开:
什么时候是被动断开呢?就是当server段调用read函数时,返回值是0,此时表明客户端的写端,服务端的读端关闭了。此时是可以继续调用write将未发送完的数据继续发送出去,然后根据返回值,和设置的errno判断,如果是EPIPE,这说明断开了连接。
// 主动关闭
close(fd);
shutdown(fd, SHUT_RDWR);
// 主动关闭本地读端,对端写段关闭
shutdown(fd, SHUT_RD);
// 主动关闭本地写端,对端读段关闭
shutdown(fd, SHUT_WR);
// 被动:读端关闭
int n = read(fd, buf, sz);
if (n == 0) {
close_read(fd);
// close(fd);
}
// 被动:写端关闭
//有的网络编程需要支持半关闭状态
int n = write(fd, buf, sz);
if (n == -1 && errno == EPIPE) { //这说明断开了连接。
close_write(fd);
// close(fd);
}
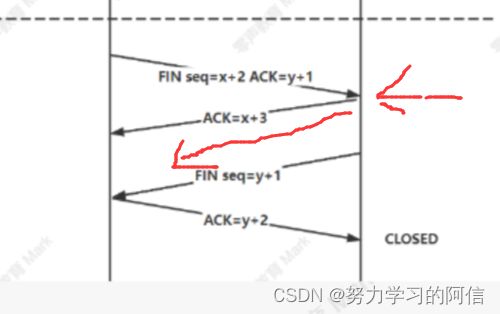
图片中红线所在的地方是调用的read返回0,但是在下一次发送FIN,也就是调用close之前,这段时间是科技继续发送数据的。但如果调用write返回-1,并且errno为EPIPE表示服务端写端(客户的读端)关闭。
2.1.3.消息到达
消息到达表明我们需要调用read从内核的read buffer中读取数据,那么此时如果read返回-1
且errno设置为EWOULDBLOCK 表示此时read buffer中没有数据,调用失败,
如果errno设置为EINTR表示read调用被其他中断打断,调用失败。那如果返回值大于0,就表示read成功。
int n = read(fd, buf, sz);//将读缓冲区中的数据从内核态读取到用户态中来
if (n < 0) { // n == -1 EINTR是被信号打断了 EINTR和EWOULDBLOCK都是正向积极的错误
if (errno == EINTR || errno == EWOULDBLOCK)
break;
close(fd);
} else if (n == 0) {
close(fd);
} else {
// 处理 buf
}
2.1.4.消息发送完毕
往写缓冲区中写数据;
消息发送就是server端调用write函数,此时根据设置的errno判断,如果是EWOULDBLOCK表示表示客户端的read buffer无法读,原因就是客户端调用shutdown关闭了读端,如果返回EINTR表示write调用失败,被其他中断打断,如果返回大于0,表示写成功,返回值是指真正写入缓冲区的字节数,而不是调用write时传入的参数
int n = write(fd, buf, dz); //n == -1 或者 n==dz
if (n == -1) {//EWOULDBLOCK 写缓冲区满了 EINTR :信号打断 两者都是正向积极的
if (errno == EINTR || errno == EWOULDBLOCK) {
return;
}
close(fd);
}
2.2 网络 IO 职责
2.2.1 检测 IO
io 函数本身可以检测 io 的状态;但是只能检测一个 fd 对应的状态;io 多路复用可以同时检测多
个io的状态;区别是:io函数可以检测具体状态;io 多路复用只能检测出可读、可写、错误、断开等笼统的事件;
io多路复用(epoll)是如何做到io检测的呢?
首先我们要明白,io多路复用知识把io检测出来而不去操作io,也就是io检测和操作io是分开的。首先需要socket、bind、listen,然后epoll_create、epoll_wait函数,然后遍历epoll_wait的返回值,这时大致的流程,我们来看看这个过程具体发生了什么。
当程序执行到epoll_wait这个函数时,会根据timeout参数决定是否阻塞、阻塞多长时间,如果此时客户端调用connect函数发起三次握手,在三次握手结束之后,这个节点会被放进accept队列,此时通过注册的写事件就可以检测io了,那为什么需要注册写事件而不是读事件呢?
当作为客户端主动连接时,此时服务器关注最后一次握手也就是客户端最后一次发送的ack包,此时会同时发送一个信号触发epoll树注册的写事件,这时候就说明该连接成功建立了。此时调用accept从accept队列取出节点进行处理,最后再将节点添加到epoll树上(调用epoll_ctl函数)。此时在下一次返回时就可以根据具体的读写事件进行io到的操作了。这就是当服务端作为客户端主动连接时发生的情况。
那如果是服务端被动连接呢,此时我们主要注册监听的就是读事件了,因为,此时服务器是需要拿到第三次握手的数据的,也就是需要客户端主动将数据发送到服务器的read buffer,此时我们只要检测到读事件就表示连接建立成功了,这就是被动建立。
被动断开:
我们根据epoll返回的errno, 如果errno是EPOLLRDHUP,说明服务端的读端已经关闭了,
如果是EPOLLHUP说明读写段全部关闭,这样我们就可以通过判断epoll的返回值和errno来检测io了
消息到达:
消息到达需要服务端通过epoll监听客户端fd的读事件,如果read buffer有数据,此时就会发送信号给epoll触发EPOLLIN事件,
接下来就可以调用read函数,此时read函数执行的就是操作io的功能了。
消息发送:
消息发送我们通常检测的是fd的写事件,因为如果write buffer有空间,
epoll就会检测出来然后出发写事件,此时调用write就会将数据写write buffer。
2.2.2 操作 IO
只能使用 io 函数来进行操作;分为两种操作方式:阻塞 io 和非阻塞 io;
2.2.3 阻塞 IO 和 非阻塞 IO
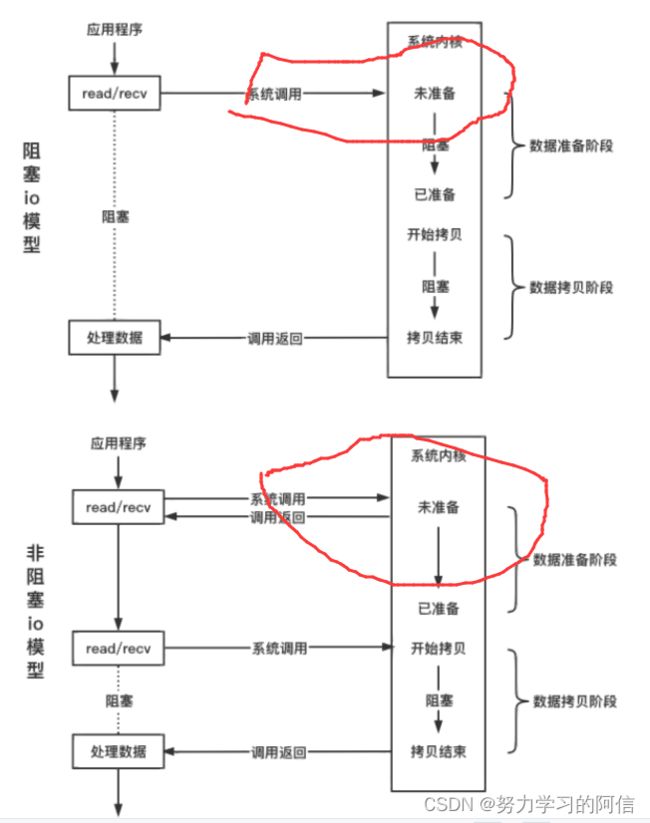
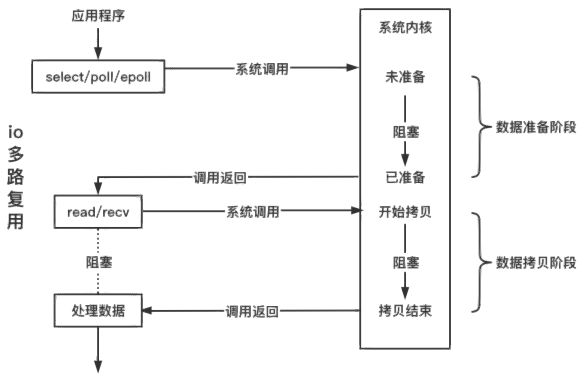
请注意途中红圈圈出来的部分,当阻塞io调用read/recv函数时,此时如果内核缓冲区的数据还没有准备好,也就是协议栈还未收到数据或者是协议栈收到数据,但数据还没copy到内核缓冲区中,那么此时就会阻塞等待,直到内核中的read_buffer中有数据才会返回,返回值代表的是实际返回的字节数,而不是我们在调用函数时传入的参数。
非阻塞io中调用read/recv函数时,如果内核read buffer没有数据,此时函数会直接返回并设置errno,errno为EWOULDBLOCK,如果有数据就是返回实际读取到的字节数,所以我们可以看到,阻塞io和非阻塞io的区别就在于数据的准备阶段。
阻塞在网络线程;
连接的 fd 阻塞属性决定了 io 函数是否阻塞;
具体差异在:io 函数在数据未到达时是否立刻返回;
// 默认情况下,fd 是阻塞的,设置非阻塞的方法如下;
int flag = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
2.2.4 IO 多路复用
io 多路复用只负责检测io,不负责操作io;
int n = epoll_wait(epfd, evs, sz, timeout);
timeout = -1 一直阻塞直到网络事件到达;
imeout = 0 不管是否有事件就绪立刻返回;
timeout = 1000 最多等待 1 s,如果1 s内没有事件触发则返回;
2.3 epoll
2.3.1 结构以及接口
struct eventpoll {
// ...
struct rb_root rbr; // 管理 epoll 监听的事件 //红黑树
struct list_head rdllist; // 保存着 epoll_wait 返回满⾜条件的事件 //双向链表
// ...
};
struct epitem {
// ...
struct rb_node rbn; // 红⿊树节点
struct list_head rdllist; // 双向链表节点
struct epoll_filefd ffd; // 事件句柄信息
struct eventpoll *ep; // 指向所属的eventpoll对象
struct epoll_event event; // 注册的事件类型
// ...
};
struct epoll_event { //重点关注************
__uint32_t events;
epoll_data_t data; // 保存 关联数据
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
}epoll_data_t;
int epoll_create(int size);
/**
op:
EPOLL_CTL_ADD
EPOLL_CTL_MOD
EPOLL_CTL_DEL
event.events:
EPOLLIN 注册读事件
EPOLLOUT 注册写事件
EPOLLET 注册边缘触发模式,默认是水平触发
*/
int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event);
/**
events[i].events:
EPOLLIN 触发读事件
EPOLLOUT 触发写事件
EPOLLERR 连接发生错误
EPOLLRDHUP 连接读端关闭
EPOLLHUP 连接双端关闭
*/
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int
timeout);

调用 epoll_create 会创建一个 epoll 对象;调用epoll_ctl 添加到 epoll 中的事件都会与网
卡驱动程序建立回调关系,相应事件触发时会调用回调函数 ( ep_poll_callback ),将触发的
事件拷贝到 rdlist 双向链表中;调用 epoll_wait 将会把 rdlist 中就绪事件拷贝到用户态中;
2.3.2 epoll 编程
连接建立
// 一、处理客户端的连接
// 1. 注册监听 listenfd 的读事件
struct epoll_event ev;
ev.events |= EPOLLIN;
epoll_ctl(efd, EPOLL_CTL_ADD, listenfd, &ev);
// 2. 当触发 listenfd 的读事件,调用 accept 接收新的连接
int clientfd = accept(listenfd, addr, sz);
struct epoll_event ev;
ev.events |= EPOLLIN; // 刚开始这里不能注册写事件,写缓冲为空。会一直触发
epoll_ctl(efd, EPOLL_CTL_ADD, clientfd, &ev);
// 二、处理连接第三方服务
// 1. 创建 socket 建立连接
int connectfd = socket(AF_INET, SOCK_STREAM, 0);
connect(connectfd, (struct sockaddr *)&addr, sizeof(addr));
// 2. 注册监听 connectfd 的写事件
struct epoll_event ev;
ev.events |= EPOLLOUT;
epoll_ctl(efd, EPOLL_CTL_ADD, connectfd, &ev);
// 3. 当 connectfd 写事件被触发,连接建立成功
if (status == e_connecting && e->events & EPOLLOUT) {
status == e_connected;
// 这里需要把写事件关闭
epoll_ctl(epfd, EPOLL_CTL_DEL, connectfd, NULL);
}
连接断开
if (e->events & EPOLLRDHUP) { //服务器的读端关闭了,对应就是客户端的写端关闭了
// 读端关闭
close_read(fd);
close(fd);
}
if (e->events & EPOLLHUP) { //服务器的读写端关闭了
// 读写端都关闭
close(fd);
}
数据到达
/*rector 为什么要用非阻塞IO
//数据到达如果经过一个错误的校验,epoll发送一个数据可读的信号,
但实际上读缓冲区是没有数据可以读的,那么如果用的是阻塞IO,
则会一直阻塞在IO的操作函数上面,会对业务的处理或者说的代码的正常执行上面造成效率降低的影响,
如果用的是非阻塞的IO 那么就不会存在这样的问题。
*/
if (e->events & EPOLLIN) {
while (1) {
int n = read(fd, buf, sz);
if (n < 0) {
if (errno == EINTR) //被信号打断
continue;
if (errno == EWOULDBLOCK) //读缓存没有数据
break;
close(fd);
} else if (n == 0) {
close_read(fd);
// close(fd);
}
// 业务逻辑了
}
}
数据发送完毕
int n = write(fd, buf, dz);
if (n == -1) {
if (errno == EINTR) //被信号打断
continue;
if (errno == EWOULDBLOCK) { //写缓冲已满,暂时不能写数据
struct epoll_event ev;
ev.events = EPOLLOUT;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev); //注册写事件 然后写成功后,就可以把这个写事件给删除
}
close(fd);
}
// ...
if (e->events & EPOLLOUT) {
int n = write(fd, buf, sz);
//...
if (n > 0) {
epoll_ctl(epfd, EPOLL_CTL_DEL, fd, NULL);
}
}
2.4 reactor常见疑问
2.4.1 epoll惊群
何为”惊群“?
网络编程经常使用多线程、多进程模型,每个线程或进程中都有一个epoll对象,通过socket()、bind()、listen()生成的listenfd可能会给多个epoll对象管理,当一个accept到来时所有的epoll都收到通知,所有进程或线程同时响应这一事件,然而最终只有一个accept成功。这就是”惊群“。
2.4.2 水平触发和边沿触发
水平触发:当读缓冲区中有数据时,一直触发,直到数据被读完。
边沿触发:来一次事件触发一次。读写操作一般需要配合循环才能全部读写完成。
2.4.3 reactor为什么要搭配非阻塞IO?
主要是三方面原因:
(1)多线程环境下,一个listenfd会被多个epoll(IO多路复用器)对象管理,当一个连接到来时所有的epoll都收到通知,所有的epoll都会去响应,但最终只有一个accept成功;如果使用阻塞,那么其他的epoll将一直被阻塞着。所以最好使用非阻塞IO及时返回。
(2)边沿触发下,事件触发才会读事件,那么需要在一次事件循环中把缓冲区读空;如果使用阻塞模式,那么当读缓冲区的数据被读完后,就会一直阻塞住无法返回。
(3)select bug。当某个socket接收缓冲区有新数据分节到达,然后select报告这个socket描述符可读,但随后,协议栈检查到这个新分节检验和错误,然后丢弃了这个分节,这时调用recv/read则无数据可读;如果socket没有设置成nonblocking,此recv/read将阻塞当前线程。
(4)IO多路复用一定要搭配非阻塞IO吗?
不是,也可以使用阻塞模式。比如MySQL使用select接收连接,然后一个连接使用一个线程进行处理;也可以使用一个系统调用先获取读缓冲区的字节数,然后读一次就把数据读完,但是这样就导致效率比较低。
int n=EVBUFFER_MAX_READ_DEFAULT;
ioctl(fd,FIONREAD,&n);//获取读缓冲区的数据字节数
2.4.4 reactor优点:
1、rector将io检测和处理解耦出来,分离了io的职责。
2、epoll的惊群会在协议栈通过加锁处理,不需要关注。
3、reactor是一个线程执行一次事件循环。
2.5 redis,ngnix,memcached 中reactor具体使用
2.5.1 单reactor——redis
redis是一种key-value结构、有丰富的数据结构、对内存进行操作的网络数据库组件。redis的命令处理是单线程的。
(1)redis为什么使用单reactor?
要理解redis为什么只使用单个reactor,需要明白redis的命令处理是单线程的。
1.redis提供丰富的数据结构,对这些数据结构进行加锁非常复杂,所以redis使用单线程进行处理;
2.因为使用单线程进行命令处理,核心业务逻辑是单线程,那么使用再多的reactor是无法处理过来的,但在6.0版本之后也支持了多线程;
3.redis操作具体命令的时间复杂度比较低,更加没有必要使用多个reactor。
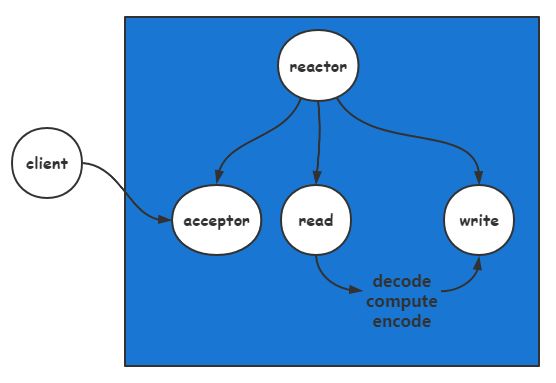
(2)redis对reactor的优化
对业务逻辑进行了优化,引入IO线程:
接收完数据后,将数据抛到IO线程进行处理;发送数据之前,将打包数据放在IO线程进行处理,再发送出去。参考上图,就是将(read+decode)放到线程中处理,将(encode+write)放在线程中处理。
原因:
对于单线程而言,当接收的数据或发送的数据过大时,会造成线程负载过大,需要引用多线程做IO数据处理。特别是解协议过程,数据庞大而且耗时,需要开一个IO线程进行处理。
场景例子:
客户端上传日志记录;客户端获取排行榜记录。
(3)从reactor角度看redis源码
- 创建一个epoll对象:

- 创建套接字,绑定监听:

- listenfd放到epoll管理:
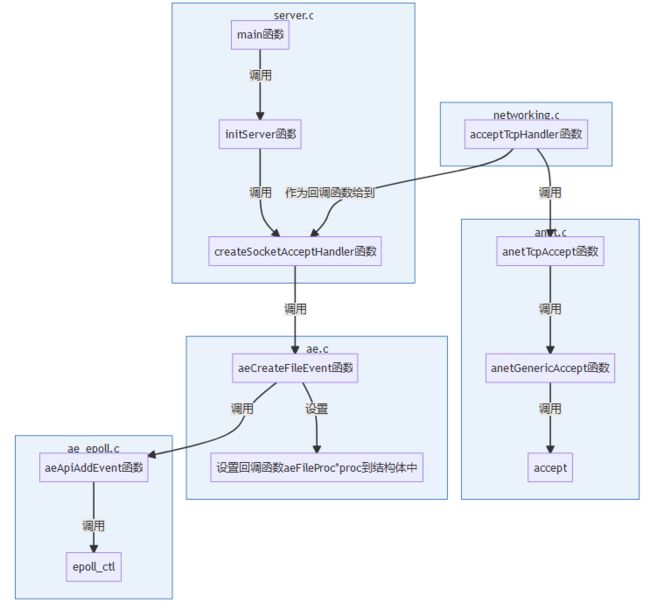
- 监听事件:


- 处理事件:

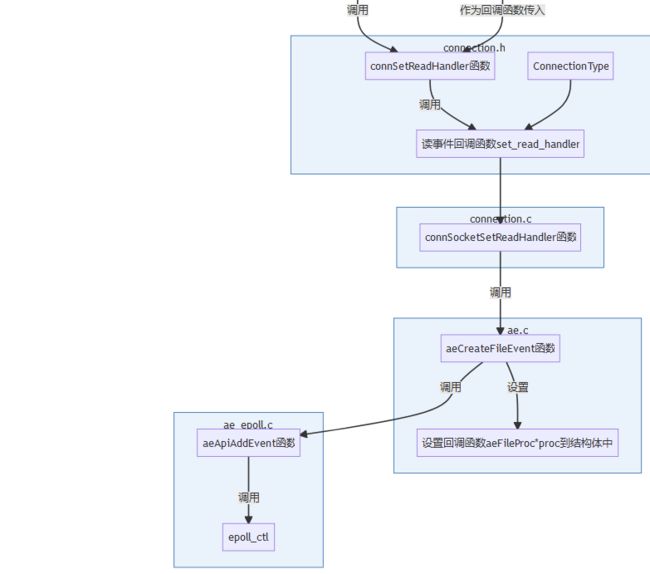
- 为clientfd注册读事件:

2.5.2 多 reactor (多线程)——memcached

(1)memcached为什么使用单reactor?
memcached的key-value结构不像redis支持丰富的数据结构,它的value使用的数据结构相对简单,加锁也就相对容易。因此,可以引入多线程,提高效率。
(2)memcached如何处理reactor?
memcached主线程会有一个reactor,主要负责接收连接;接收完连接后,经过负载均衡,通过pipe(管道)告诉子线程的reactor,将客户端的fd交由该线程的reactor管理;每个线程处理相对应的业务逻辑。
2.5.3 多 reactor (多进程)——nginx
 nginx可以反向代理,利用多进程处理业务。
nginx可以反向代理,利用多进程处理业务。
master会创建listenfd,并bind和listen;fork出多个进程,每个进程都有一个自己的epoll对象,listenfd交由多个epoll对象管理。这时会有惊群现象,需要处理;通过负载均衡处理事件。
(1)解决"惊群"问题
加锁方式。nginx会开辟一个共享内存,把锁放在共享内存当中,多个进程去争夺这把锁,争夺到锁的才能进行接受连接。
(2)负载均衡
定义一个进程最大的连接数,当连接数量超过总连接数量的7/8时,该进程就会暂停接受连接,将机会留个其他进程。
这样不会让一个进程拥有过多的连接,而其他进程连接数量过少;从而使每个进程的连接数量相对平衡。
当所有的进程接受连接的数量都达到总连接数量的7/8时,这是nginx接受连接将变得很缓慢。
2.6 总结
1、网络编程需要关注建立、断开、消息到达和发送四个问题。
2、主动连接、被动连接、主动断开、被动断开时,相应的函数具体做了什么。
3、io函数是具有检测和操作两种功能的。
4、reactor的实现由单线程、多线程、多进程版本的
参考:
「努力学习的阿信」的原创文章:https://blog.csdn.net/qq_43717446/article/details/126684435
「拾荒叶」的原创文章:https://blog.csdn.net/qq_39329062/article/details/122920409
「Lion Long」的原创文章:https://blog.csdn.net/Long_xu/article/details/126393177
3. Posix API与网络协议栈
这部分我是完全照搬这位兄弟的笔记,感觉他的最详细。感谢「cheems~」
3.1 Posix API 有哪些
哪些是Posix API呢,就是Linux网络编程的这些API,本文介绍下列8种。
Tcp Server
1.socket 2.bind 3.listen 4.accept 5.recv 6.send 7.close
Tcp Client
1.socket 2.bind(option可选) 3.connect 4.send 5.recv 6.close
设置socket参数
1.setsockopt 2.getsockopt 3.shudown 4.fcntl

3.2.1 socket
socket 是什么东西?中文翻译过来是插座的意思,那插座有两个部分,一个插一个座。
socket也是由两部分组成,一个是fd(文件系统的文件描述符,是插头),任何我们能对 socket 进行操作的地方都是对这个 fd 进行操作。
那插到什么地方呢,插头插到插座上,对于TCP而言,每个连接背后都有一个TCB(tcb控制块,tcp control block)。什么是TCB呢,服务器和客户端建立TCP连接,先建立了socket,那么socket底层看不到的东西,就是tcp控制块TCB,而能够看到的,就是文件描述符fd。
我们操作fd,调用send,其实就是将数据放到TCB里面。调用recv,就是从TCB里拷贝出来。这个fd是我们用户操作的,而TCB是tcp协议栈里面的。一个fd对应一个TCB,这就是socket。

3.3.2 bind
刚开始创建socket的时候,其底层的TCB是没有被初始化的,没有任何数据,TCB里面的状态机的状态也是close的,发送不了数据,也接收不了数据。
下面介绍一个新的概念:五元组,当连接有很多很多的时候,哪个包到底是哪个连接的呢,这个时候就需要五元组。也就是说,通过五元组来确定一个TCB。五元组 < 源IP地址 , 源端口 , 目的IP地址 , 目的端口 , 协议 >
bind的作用就是绑定本地的ip和端口,还有协议。也就是将TCB的五元组填充 <目的IP地址,目的端口,协议> ,注意客户端可以不使用bind函数,但其会默认分配。
3.2 三次握手建立连接的过程
3.2.1 connect
三次握手发生在协议栈和协议栈之间,而posix api connect 只是一个导火索,我们写的代码里面是没有写三次握手的。
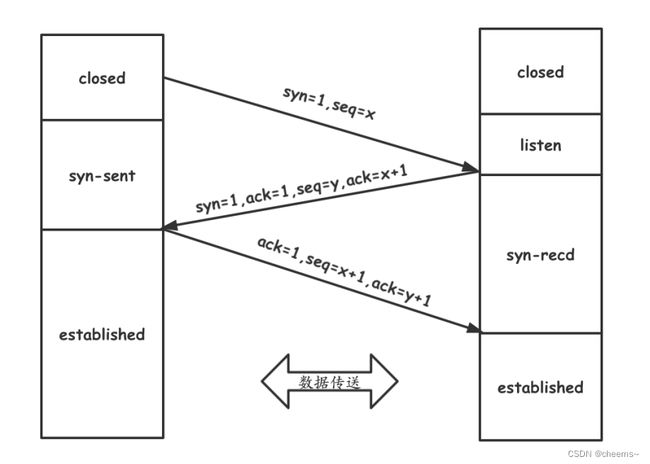
首先客户端先发三次握手的第一次数据包,这时候里面带有一个同步头syn,seq=x,这是由客户端内核协议栈发送的数据包。
服务端接收到之后,返回三次握手的第二个数据包,syn=1,ack=1,seq=y,ack=x+1 。其中ack=x+1代表确认了x+1以前的都收到了,也就是说告诉对端,你发送的数据包,序号在x+1之前的我都收到了。同样也携带自己的一个同步头给对端。
再往下面走,就是三次握手的第三次,返回一个ack确认包给服务器。
这就反应了一个现象,tcp是双向的。双向怎么体现的呢,客户端发送一个数据包告诉服务器我现在发送的数据包序号是多少,服务端返回的时候也告诉客户端我这个数据包的序号是多少。这就是双向。
有人会问三次握手为什么是三次?因为tcp是双向的,A给B发syn,B回一个ack,这里确定了B是存在的,这里两次。B给A发syn,A回一个ack,这里确定了A是存在的,这里两次,而中间的两次可以合到一起,那就是三次了。客户端发送一次syc,服务器返回一个ack并且携带自己的syn,这时候能确定服务器存在,客户端再返回一个ack,这时候能确定客户端存在,这时候就确定了这个双向通道是ok了。
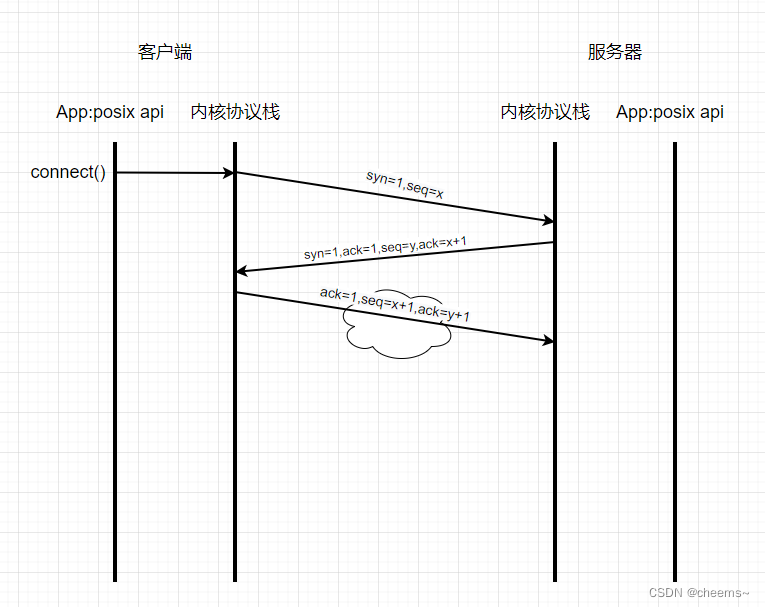
调用connect之后,协议栈开始三次握手。那么connect函数到底阻不阻塞呢,取决于传进去的fd,如果fd是阻塞,那么直到第三次握手包发送之后就会返回。如果fd是非阻塞,那么返回-1的时候说明连接建立中,返回0代表连接建立成功。
// (请求连接)举例为非阻塞io,阻塞io成功直接返回0;
int connectfd = socket(AF_INET, SOCK_STREAM, 0);
int ret = connect(connectfd, (struct sockaddr *)&addr, sizeof(addr));
// ret == -1 && errno == EINPROGRESS 正在建立连接
// ret == -1 && errno = EISCONN 连接建立成功
3.2.2 listen
服务器内核协议栈在接收到三次握手的第一次syn包的时候,从这个sync包里面可以解析出来源IP地址 , 源端口 , 目的IP地址 , 目的端口 , 协议 ,那么五元组 < 源IP地址 , 源端口 , 目的IP地址 , 目的端口 , 协议 > 就可以确定下来了,从而构建出来一个TCB,只不过目前这个TCB还不能用,因为还没有分配socket,还没有分配fd。这时候会将TCB加入到半连接队列(sync队列)里面。
同样当第三次握手收到ACK之后,也有一个队列,叫做全连接队列。所以在第一次收到syn包的时候,服务端做两件事,1返回ACK,2创建一个TCB结点,加入半连接队列里面。在第三次握手的时候,先查找半连接队列。那么怎么查找呢,通过五元组查找。

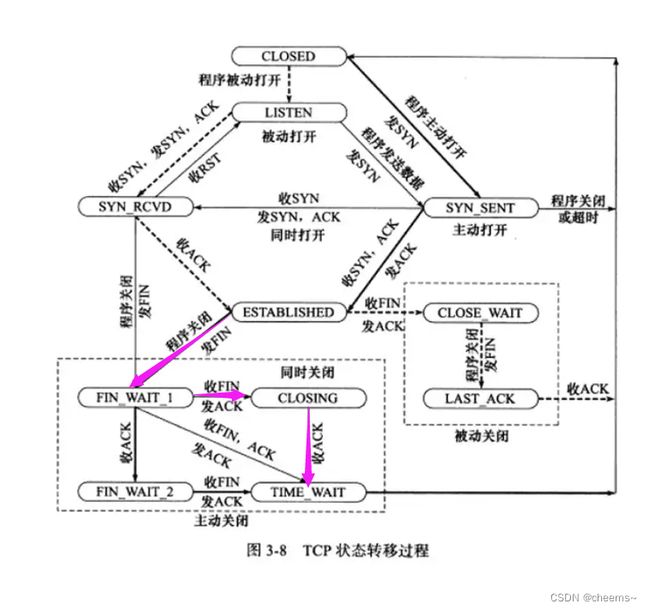
那这个半连接队列和全连接队列的建立有没有前提?难道是想建立就建立吗,建立的前提就是服务端必须先进入listen状态。我们来看一下TCP状态转移过程。
服务器首先进入Listen状态,收SYN,发SYN和ACK,然后就进入了SYN_RCVD的状态。注意,这里进入SYN_RCVD的状态是刚才新创建的那个TCB,改变的是新创建的TCB的状态,而不是被动监听fd的状态。SYN_RCVD这个状态就暗示这TCB已经进入了半连接队列里面,也就是说半连接队列里面所有的TCB的状态都是SYN_RCVD。
客户端首先发收SYN包,则客户端进入SYN_SENT状态

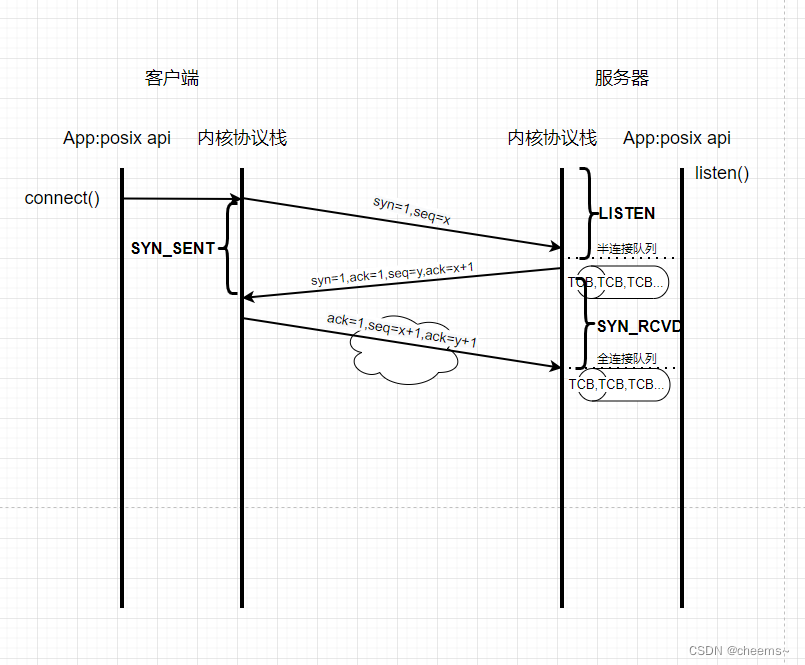
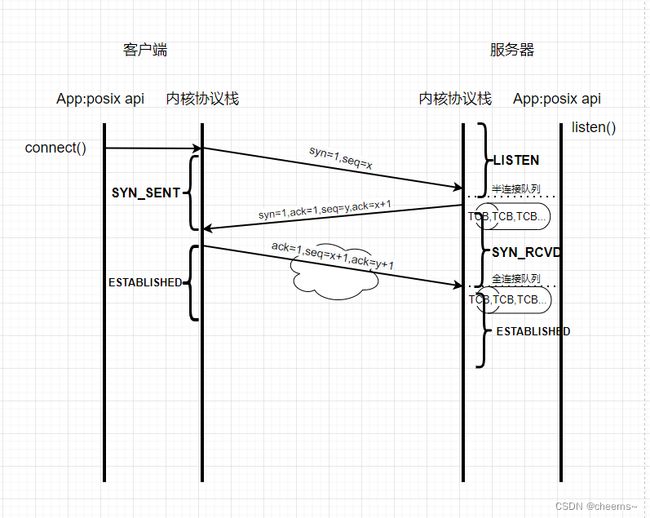
服务器当收到第三次握手的ACK的时候,会将对应的在半连接队列里面的TCB移到全连接队列里面,这个时候TCB的状态由SYN_RCVD变成ESTABLISHED状态。
客户端发送第三次握手的ACK的时候,也会进入ESTABLISHED状态。

现在有一个问题,listen这个函数有两个参数,这个backlog是什么意思?
listen(fd,backlog);
backlog有两种理解情况
- 在unix,mac系统里面,半连接队列与全连接队列的总和 <= backlog
- 在Linux系统里面, 全连接队列<=backlog
ddos攻击:客户端不断的模拟三次握手的第一次,发syn包
如果在Linux系统中,backlog无论设置多少都是没用的。如果是在unix,mac系统中,设置backlog还是有一定作用的。
3.2.3 accept
这个时候连接已经建立完了,双方都知道对方的存在了,现在就可以调用accept了,accept函数只做两件事情
int clientfd=accept()
- 从全连接队列里面取出一个TCB结点
- 为这个TCB结点分配一个fd,把fd和TCB做一个一对一对应的关系。
直到现在,应用程序才可以操作这个tcp的会话。
3.3 数据传输 发送与接收
3.3.1 send & recv
我们知道发送用send,接收用recv。
send只是了将用户态的数据拷贝到内核协议栈对应的TCB里面。至于真正数据发送的时机,什么时候发送的,发送的数据有没有与之前的数据粘在一起,都不是由应用程序决定的,应用程序只能将数据拷贝到内核buffer缓冲区里面。 然后协议栈将sendbuffer的数据,加上TCP的头,加上IP的头,加上以太网的头,一起打包发出去。所以调用send将buffer拷贝到内核态缓冲区,与tcp发送数据到对端,是异步的过程。
对端网络协议栈接收到数据,同样开始解析,以太网的头mac地址是谁,ip地址从哪里来的,源端口是多少,目的端口是发到哪个进程里面,然后将数据写进对应的TCB里。recv只是将内核态的缓冲区数据拷贝到用户态里面,所以tcp数据到达TCP的recv buffer缓冲区里,与调用recv将缓冲区buffer拷贝到用户态,这两个过程也是异步的。


3.3.2 滑动窗口
如果客户端不断的send,服务器对应的tcb的recvbuffer缓冲区满了怎么办?
首先,如果不停的send,直到sendbuffer缓冲区满了,这个时候send会返回-1,代表内核缓冲区满了,send的copy失败。而如果recvbuffer缓冲区满了而应用程序没有去接收,这时候TCP协议栈会告诉对端,我的缓冲区空间还有多大,超过这个大小就不要发(滑动窗口),也就是说recvbuffer缓冲区会通知对端,我能接收多少数据,而对端发送的数据量一定要在这个范围内才行。
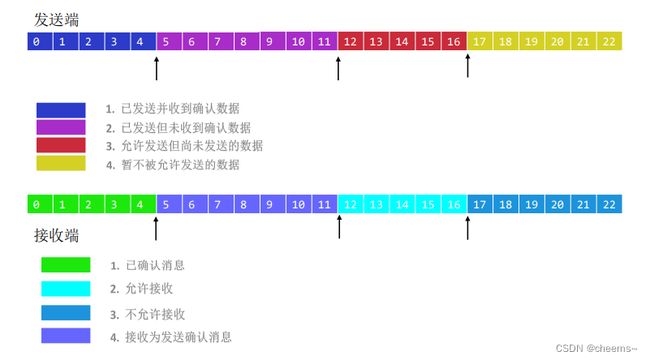
一般send的时候,在TCP协议头里面有一个push的标志位,置1代表立即通知应用程序来读取。
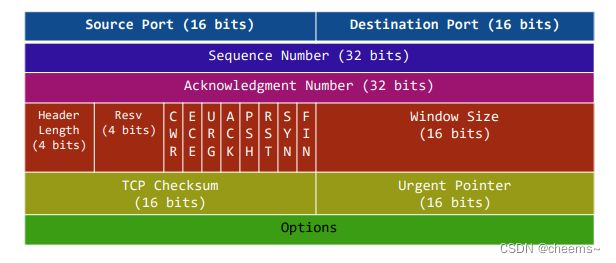
3.3.3 粘包 & 分包
假设我们连续send 1k的数据三次,那么在内核tcb的缓冲区里面,就有3k的数据,这3k的数据是1次tcp发走,还是分2次,分3次,都不是由应用程序控制的。这就出现了 粘包 和 分包 的问题。
假设send 了3次,而协议栈只发送了2次,那么在recv的时候读两次,就避免不了数据包合在一起的现象。
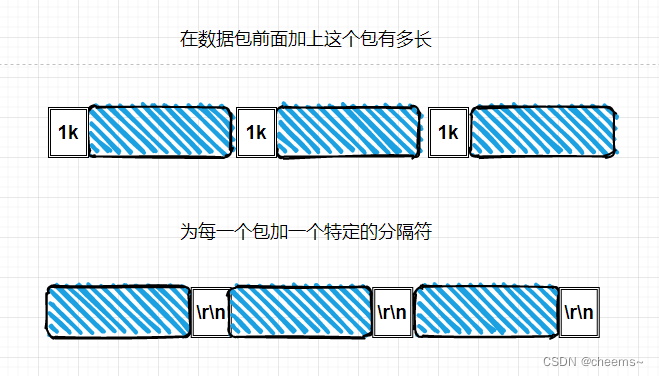
解决的方法有两种:
第一种:在数据包前面加上这个包有多长
第二种:为每一个包加一个特定的分隔符
3.3.4 延迟确认(延迟ACK)
上面两种解决方法有一个很大的前提,就是这个数据包是顺序的。先发的先到,后发的后到,这就是顺序。那TCP是怎么保证顺序的?
在TCP发送的时候,数据包都是确定的,第一个包发完之后,对端等待一会,再确认这个包。假设现在发5个包,A到了,B到了,每收到一个包,对端都会重置延迟定时器200ms。
现在假设B包第一个到,现在启动定时器200ms,然后C包到了,重置定时器,在200ms以内A包也到了,再重置,E包到了,重置,最后200ms超时了,D包没到。这时候就会ACK=D,代表D之前的都收到了。接下来D以及D后面的数据包都会重发。
这样就解决了包的无序的问题,这里的操作都是TCP协议栈来做的。


3.3.5 udp场景
延迟ACK确认时间长,超时重传的时候,重传的包较多,很费带宽。这就有了udp的使用空间。
随着带宽越来越高,udp的使用场景在不断弱化,但是在弱网的环境下,做大量数据传输的时候,TCP就不合适了,因为一旦出现丢包的情况,后面的包都要重传了。
并且TCP也没有办法保证实时性,虽然可以关闭延迟ACK来解决这个问题。但是实时性也会用到udp。
**udp场景:**1弱网的环境下(电梯里网就很烂) 2实时性要求高的环境下(游戏打团,秒人只在一瞬间)。
3.4 四次挥手 断开连接的过程
这6个状态就是四次挥手的过程,对于TCP而言建立连接时间很短,断开连接时间很短,中间传输数据是绝大部分时间,但是中间传输数据的状态只有一个,就是ESTABLISHED。断开连接的过程只有一个函数,就是close。

3.4.1 正常情况
在四次挥手的过程中,没有客户端和服务器之分,只有主动方和被动方之分。主动方首先发送一个fin,被动方返回一个ack。被动方再发送一个fin,主动方返回一个ack。这就是4次挥手
第一次的fin是哪来的呢,调用close这个函数,协议栈会将最后一个包fin位置1,被动方接收之后,会触发一个可读事件,recv=0。被动方会做两件事情,第一件事情推给应用程序一个空包,第二件事情直接返回一个ack的包返回给对端。然后被动方recv=0读到之后,应用程序会调用close,这时候被动方也会发送一个fin,对端收到fin会回复一个ack,至此四次挥手完毕。
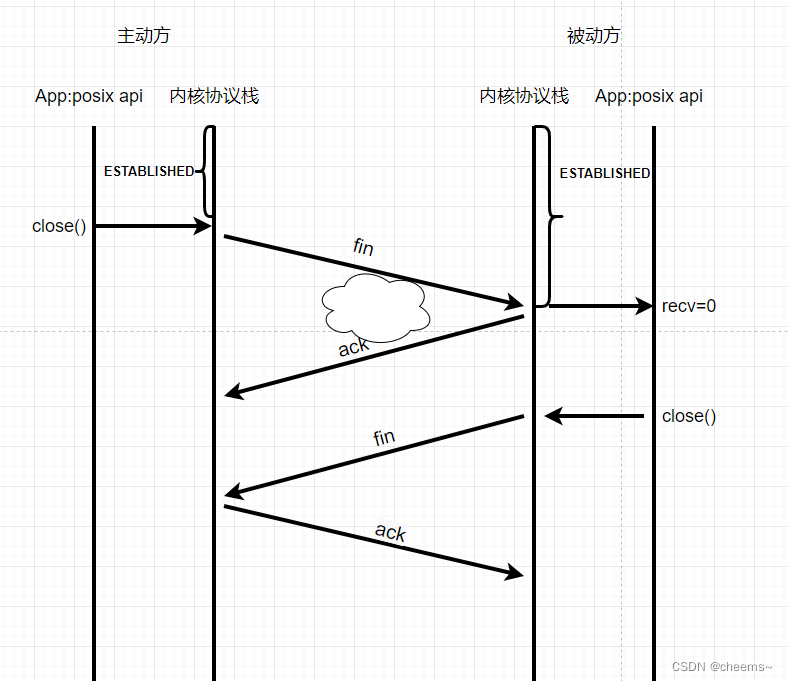
四次挥手为什么要有四次?因为tcp是双向的,就跟两个人分手一样,女的跟男的分手,男的说我知道了,那我也跟你分手吧。第一对fin和ack就是女方终止与男方交往,第二对fin和ack就是男方终止与女方交往。这个过程就形成断开了。四次是因为女方跟男方分手之后,男方需要缓和一段时间,中间间隔一段时间(因为这个时候被动方的数据可能还没有发完,在缓和期要把数据都发过去)。
主动方在调用close之前它的状态是确定的ESTABLISHED状态,发送fin后,进入FIN_WAIT_1状态,收到ack以后进入FIN_WAIT_2状态。如果中间两次ack和fin一起的话,那就没有这个状态,直接进入TIME_WAIT状态。也就是说收到fin后进入TIME_WAIT状态。在等待2MSL后,进入CLOSED状态。TIME_WAIT存在的原因避免最后一个ack丢失,而对端一直超时重发fin,导致连接得不到释放。
被动方在接收到fin后,进入CLOSE_WAIT状态,之后调用close发送fin后,进入LAST_ACK状态,收到ack之后,进入CLOSED状态。
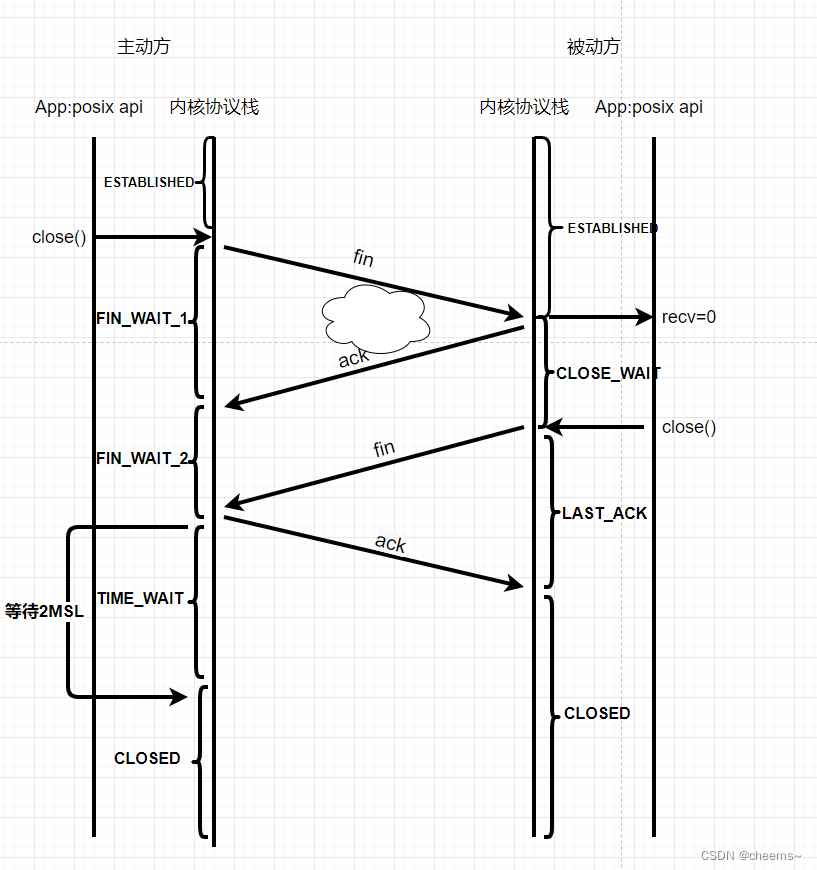
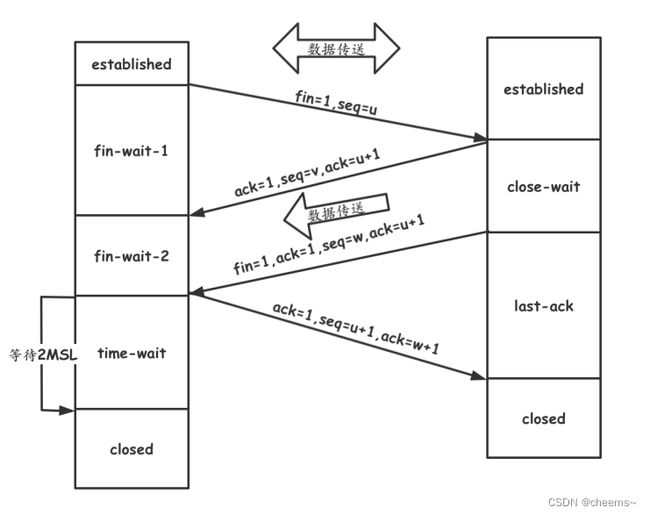

3.4.2 特殊情况
有没有一种可能,主动方调用close,被动方也调用close。也就是说一对情侣同时提出分手。在FIN_WAIT1状态期间接收到fin,这时候就进入CLOSING状态,之后收到ack就进入TIME_WAIT状态。

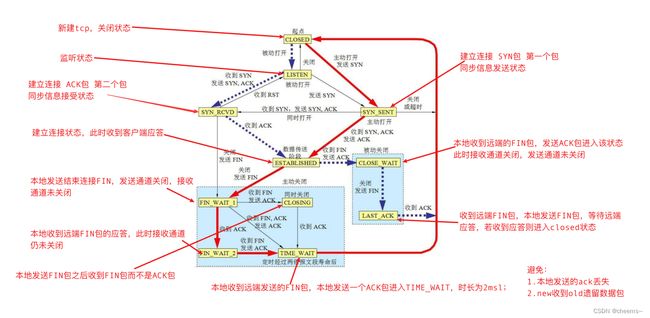
3.4.3 回收fd和tcb
被动方调用close之后,fd被回收。在接收到ack以后进入CLOSED后,TCB被回收
主动方调用close之后,fd被回收,在time_wait时间到了进入CLOSED后,TCB被回收
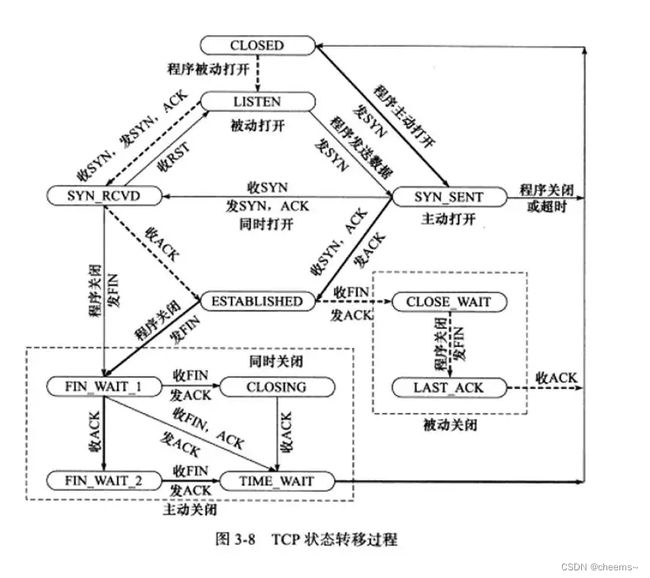
3.5 一些面试问题
现在假设客户端连接进入FIN_WAIT_1状态,会在这个状态很久吗?不会,因为即使没有收到ack,也会超时重传fin,进入FIN_WAIT_2状态。
如果连接停在FIN_WAIT_2状态的时间很久怎么办呢?既然客户端停在FIN_WAIT_2状态,那也就是说服务器停在CLOSE_WAIT状态。服务器出现大量CLOSE_WAIT状态,造成这一现象是因为对方调用关闭,而服务器没有调用close,再去分析,其实就是业务逻辑的问题。
recv=0,但是没有调用close,原因在哪呢。也就是说从recv到调用close这个过程中间,时间太长,为什么时间太长呢,可能在调用close之前,有去关闭一些fd相关联的业务信息,造成比较耗时的情况。假设现在是一款即时通讯的程序,现在客户端掉线调用了close,服务器接收到recv=0后,服务器需要把这个客户端对应的临时数据同步到数据库里面,会出现一个很耗时的操作,那么这个时间内就是出现CLOSE_WAIT的状态。
那么如何解决呢,1. 要么先调用close 2. 要么把业务信息抛到消息队列里面交给线程池进行处理。把业务的清理当成一个任务交给另一个线程处理。 原来的线程把网络这一层处理好。
作为客户端去连第三方服务,长时间卡在FIN_WAIT_2状态,有没有办法去终止它?从FIN_WAIT_2是不能直接到CLOSED状态的,所以这个问题要么再起一个连接,要么就杀死进程,要么就等待FIN_WAIT_2定时器超时。
如果服务器在调用close之前宕机了,fin是肯定发不到客户端的,那么客户端一直在FIN_WAIT_2状态,这个时候怎么办呢,如果开启了keepalive,检测到是死链接后会被终止掉。那没有开启keepalive呢?
FIN_WAIT_2 状态的一端一直等不到对端的FIN。如果没有外力的作用,连接两端会一直分别处于 FIN_WAIT_2 和 CLOSE_WAIT 状态。这会造成系统资源的浪费,需要对其进行处理。(内核协议栈就有参数提供了对这种异常情况的处理,无需应用程序操作),也就是说,等着就行。
如果应用程序调用的是完全关闭(而不是半关闭),那么内核将会起一个定时器,设置最晚收到对端FIN报文的时间。如果定时器超时后仍未收到FIN,且此时TCP连接处于空闲状态,则TCP连接就会从 FIN_WAIT_2 状态直接转入 CLOSED 状态,关闭连接。在Linux系统中可以通过参数 net.ipv4.tcp_fin_timeout 设置定时器的超时时间,默认为60s。
3.6 面试中协议栈常问的点?
TCP三次握手过程?
TCP四次挥手过程?
为什么建立连接需要三次握手,断开连接需要四次挥手?
time_wait状态持续时间及原因?
大量的time_wait和close_wait?
超时重传和快速重传?
TCP首部长度有哪些字段?
TCP在listen时的参数backlog的意义?
Accept发生在三次握手的哪一步?
三次握手过程中有哪些不安全性?
TCP和UDP的区别?
参考:
————————————————
「牛奶好烫」的原创文章:https://blog.csdn.net/CSJIN123/article/details/114962533
「cheems~」的原创文章:ttps://blog.csdn.net/qq_42956653/article/details/125727563
4. UDP的可靠传输协议QUIC
4.1 UDP与 TCP的区别
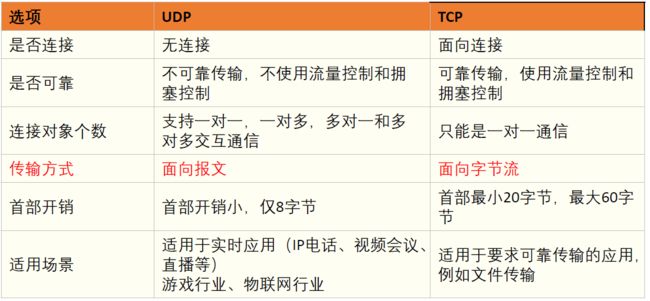
4.2 TCP和 UDP 格式对比

4.2.1 ARQ(自动重传请求) 协议
在网络中,我们认为传输是不可靠的,而在很多场景下我们需要的是可靠的数据,所谓的可靠,指的是数据能够正常收到,且能够顺序收到,于是就有了 ARQ 协议(自动重传请求),TCP 之所以可靠就是基于此。
ARQ协议 (Automatic Repeat reQuest )),即自动重传请求
是传输层的错误纠正协议之一,它通过使用确认和超时两个机制,在不可靠的网络上实现可靠的信息传输。
ARQ协议主要有 3 种模式:
- 即停等式 (stop and wait)ARQ
- 回退 n 帧 (go back n)ARQ
- 选择性重传 (selective repeat)ARQ
4.2.2 什么是滑动窗口
发送方和接收方都会维护一个数据帧的序列,这个序列被称作窗口。 发送方的窗口大小由接收方确定 ,目的在于控制发送速度,以免接收方的缓存不够大,而导致溢出,同时控制流量也可以避免网络拥塞。协议中规定,对于窗口内未经确认的分组需要重传。
4.3 UDP如何可靠, KCP 协议在哪些方面有优势
以10% 20% 带宽浪费的代价换取了比 TCP 快 30% 40% 的传输速度。
RTO翻倍 vs 不翻倍:
TCP超时计算是 RTOx2 ,这样连续丢三次包就变成 RTOx8 了 ,十分恐怖,而 KCP 启动快速模式后不 x2 ,只是 x1.5 (实验证明 1.5 这个值相对比较好),提高了传输
速度。 200 300 450 675 200 400 800 1600
选择性重传vs 全部重传:
TCP丢包时会全部重传从丢的那个包开始以后的数据, KCP 是选择性重传,只重传真正丢失的数据包。
快速重传(跳过多少个包马上重传 )(如果使用了快速重传,可以不考虑RTO
发送端发送了1,2,3,4,5 几个包,然后收到远端的 ACK: 1, 3, 4, 5 ,当收到 ACK3 时,KCP 知道 2 被跳过 1 次,收到 ACK4 时,知道 2 被跳过了 2 次,此时可以认为 2 号丢失,不用等超时,直接重传 2 号包,大大改善了丢包时的传输速度。 fastresend=2
延迟ACK vs 非延迟 ACK
TCP为了充分利用带宽,延迟发送 ACK (NODELAY 都没用),这样超时计算会算出较大 RTT 时间 ,延长了丢包时的判断过程。 KCP 的 ACK 是否延迟发送可以调节 。
UNA vs ACK+UNA
ARQ模型响应有两种, UNA (此编号前所有包已收到,如 TCP )和 ACK (该编号包已收到),光用 UNA 将导致全部重传,光用 ACK 则丢失成本太高,以往协议都是二选其一,而 KCP 协议中, 除去单独的 ACK 包外,所有包都有 UNA 信息 。
非退让流控
KCP正常模式同 TCP 一样使用 公平退让法则 ,即发送窗口大小由:发送缓存大小、接收端剩余接收缓存大小、丢包退让及慢启动这四要素决定。但传送及时性要求很高的小数据时,可选择通过配置跳过后两步,仅 用前两项来控制发送频率 。以牺牲部分公平性及带宽利用率之代价,换取了开着 BT 都能流畅传输的效果。
4.3.1 名词说明
用户数据:应用层发送的数据,如一张图片2Kb 的数据
- MTU:最大传输单元。即每次发送的最大数据 1500 实际使用 1400左右
- RTO Retransmission TimeOut ,重传超时时间。
- cwnd:congestion window ,拥塞窗口,表示发送方可发送多少个 KCP 数据包。与接收方窗口有关,与网络状况(拥塞控制)有关,与发送窗口大小有关。
- rwnd:receiver window, 接收方窗口大小,表示接收方还可接收多少个 KCP 数据包
- snd_queue待发送 KCP 数据包队列
- snd_nxt下一个即将发送的 kcp 数据包序列号
- snd_una下一个待确认的序列号
4.4 使用方式
- 创建 KCP对象:
ikcpcb *kcp = ikcp_create(conv, user); - 设置传输回调函数(如UDP的send函数):
kcp->output = udp_output;
真正发送数据需要调用sendto - 循环调用 update:
ikcp_update(kcp, millisec); - 输入一个应用层数据包(如UDP收到的数据包):
ikcp_input(kcp,received_udp_packet,received_udp_size);我们要使用recvfrom接收,然后扔到kcp里面做解析 - 发送数据:
ikcp_send(kcp1, buffer, 8); 用户层接口 - 接收数据:
hr = ikcp_recv(kcp2, buffer, 10);
发送窗口和接收窗口
发送窗口有最大值,默认是32个分片(IKCPSEG)
发送窗口又是变动的
命令
IKCP_CMD_PUSH:普通用户数据包
IKCP_CMD_ACK:应答分片
IKCP_CMD_WASK:窗口询问
IKCP_CMD_WINS:回复窗口大小
问题
- sendto 每次发送多长的数据?
- ikcp_send 可以发送多大长度的数据?
- 如何进行 ack
- 窗口机制如何实现?
4.4.1 kcp 源码流程图

4.5 QUIC协议
QUIC协议,Quick UDP Internet Connections,谷歌发明的新传输协议
主要目的 为了整合tcp协议的可靠性和udp协议的速度和效率。
QUIC可以在1到2个数据包内完成连接的建立(取决于连接的服务器是新的还是已知),包括TLS
QUIC 非常类似于在 UDP 上实现的 TCP + TLS + HTTP/2
是在用户态基于udp实现的传输层
为什么不再内核统一级别quic、tcp、udp?
- quic还是一个草案,还在更新
- 放在内核影响大,所有系统都要更新
- 路由器,还有很多中间设备、防火墙也要改动
1)小地方,路由封杀UDP 443端口( 这正是QUIC 部署的端口);
2)UDP包过多,由于QS限定,会被服务商误认为是攻击,UDP包被丢弃;
3)无论是路由器还是防火墙目前对QUIC都还没有做好准备。

4.5.1 QUIC的特点
- 连接建立低时延
- 多路复用
- 无队头阻塞
- 灵活的拥塞控制机制
- 连接迁移
- 数据包头和包内数据的身份认证和加密
- FEC 前向纠错
- 可靠性传输
- 其他
QUIC 与现有 TCP + TLS + HTTP/2 方案相比,有以下几点主要特征:
利用缓存,显著减少连接建立时间;
改善拥塞控制,拥塞控制从内核空间到用户空间;
没有 head of line 阻塞的多路复用;
前向纠错,减少重传;
连接平滑迁移,网络状态的变更不会影响连接断线。
4.5.2 连接建立低时延 典型 TCP+TLS 连接

- 首先,执行三次握手,建立 TCP 连接 蓝色部分
- 然后,执行 TLS 握手,建立 TLS 连接 黄色部分
- 此后开始传输业务数据;
客户端和服务器之间要进行多 轮协议交互,才能建立 TLS 连接,延迟相当严重。
平时访问 https 网站明显比 http 网站慢,三次握手和 TLS 握手难辞其咎。
4.5.3 连接建立低时延 QUIC 首次连接
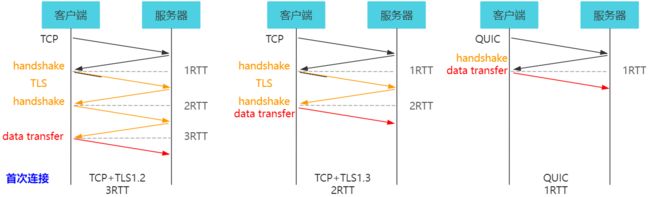
- 共 3 RTT TCP+TLS 1 2 中 TCP 三次握手建立连接需要 1 个 RTT TLS 需要 2 个 RTT 完成身份验证;传输数据
- 共 2 RTT TCP+TLS 1 3 中 TCP 三次握手建立连接需要 1 个 RTT TLS 需要 1 个 RTT 完成身份验证;传输数据
- 共 1 RTT 首次 QUIC 连接中 Client 向 Server 发送消息 请求传输配置参数和加密相关参数; Server 回复其配置参数;传输数据
注解
注意到,三次握手中的 ACK 包与 handshake 合并在一起发送。 这是 TCP 实现中使用的 延迟确认 技术,旨在减少协议开销,改善网络性能。
4.5.3 连接建立低时延 QUIC 再次连接
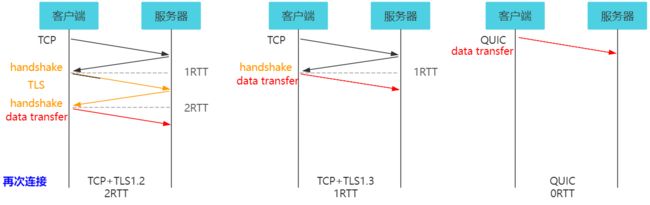
- 再次连接的概念 Client 已经访问过 Server 在本地存放了 Cookie 。
- 2 RTT TCP+TLS 1.2 中 TCP 三次握手建立连接需要 1 个 RTT TLS 需要 1 个 RTT 完成身份验证 由于缓存的存在 减少 1 RTT 传输数据
- 1 RTT TCP+TLS 1.3 中 TCP 三次握手建立连接需要 1 个 RTT 传输数据
- 0 RTT :在客户端与服务端的再次 QUIC 连接中 Client 本地已有 Server 的全部配置参数 缓存 据此计算出初始密钥 直接发送加密的数据包 。
剩下没讲到的看这些补充吧。
4.2 TCP 重传、滑动窗口、流量控制、拥塞控制:
4.17 如何基于 UDP 协议实现可靠传输?
3.7 HTTP/3 强势来袭